第二十节:Python内存管理
自动垃圾回收
Python 使用引用计数和周期性地运行的循环垃圾收集器来自动管理内存。每当一个对象不再被使用时(即它的引用计数降为零),该对象占用的内存就会被释放。对于循环引用的对象,Python 有一个额外的垃圾收集机制来处理这种情况。
对象分配
Python 在堆上分配对象,并通过栈上的指针来引用这些对象。小整数、短字符串等常量会被缓存,以提高性能并减少内存使用。
内存池管理
CPython 实现了私有的内存池管理,用于优化小对象的分配。当程序请求分配小块内存时,Python 不会直接向操作系统请求,而是从预先分配的内存池中获取,这可以显著提升效率。
用户控制
虽然大多数情况下 Python 的垃圾收集器能很好地工作,但在某些特殊场景下,开发者也可以手动干预,例如使用 gc 模块调整垃圾收集的行为或强制进行垃圾收集。
一、Python对象引用计数
在Python中,每个对象都有存有指向该对象的引用总数,即引用计数(reference count)。容器类型放的都是引用
from sys import getrefcount
a = [1,2,3]
print(getrefcount(a))
b = a
print(getrefcount(a))
c = [a,a]
print(getrefcount(a))
print(getrefcount(b))
print(getrefcount(c))a = [1,2,3]
b = a
c = [a,a]
print(getrefcount(a))
print(getrefcount(b))
print(getrefcount(c))
del c[0]
print(c)
print(getrefcount(a))
b = 2
print(getrefcount(a))循环引用情况
x = []
y = []
x.append(y)
y.append(x)
对于上面相互引用的情况,删除x,y引用计数都减1,但是没有归0在内存中就不会释放,程序又不能访问这片空间,造成内存泄露。
二、垃圾回收(GC)
Python程语言的自动内存管理机制,当Python的某个对象的引用计数降为0时, 可以被垃圾回收。
-
GC的作用:
- 找到内存中无用的垃圾资源
- 清除这些垃圾并把内存让出来给其他对象使用。
-
GC的效率:
- 垃圾回收时,Python不能进行其它的任务。频繁的垃圾回收将大大降低Python的工作效率。
-
GC的启动:
- 当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的 次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
# import gc
# 常用函数:
gc.get_count()
# 获取当前自动执行垃圾回收的计数器,返回一个长度为3的列表gc.get_threshold()
# 获取gc模块中自动执行垃圾回收的频率gc.set_threshold(threshold0[,threshold1,threshold2])
# 设置自动执行垃圾回收的频率gc.disable()
# python3默认开启gc机制,可以使用该方法手动关闭gc机制gc.collect()
# 手动调用垃圾回收机制回收垃圾>>> import gc
>>> print(gc.get_threshold())
(700, 10, 10)
>>>gc.collect()
2
>>>gc.collect()
0
GC触发
- 主动调用gc.collect()
- GC达到阈值时自动触发
- 程序退出时
自动GC机制一:引用计数
引用计数也是一种垃圾收集机制,而且也是一种最直观、最简单的垃圾收集技术。当Python的某个对象的引用计数降为0时,该对象就成为要被回收的垃圾了。不过如果出现循环引用的话,引用计数机制就不再起有效的作用了。
问题:循环引用
自动GC机制一:标记清除
标记-清除原理:当应用程序可用的内存空间被耗尽时,就会停止整个程序,然后进行两项工作,标记和清除
标记:通俗的讲就是,栈区相当于“根”,凡是通过根出发可以直接访问或者间接访问到的都是“有根之人”,有跟之人当活,无根之人当死;具体的讲,标记的过程其实就是遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以称之为GC Roots对象),然后将其中可以直接或者间接访问到的对象都标记为可以存活的对象,其余的为非存活对象,应该清除掉
清除:清除所有没有被标记的非存活对象
总结
- 标记:活动(有被引用), 非活动(可被删除)
- 清除:清除所有非活动的对象
当我们解除掉变量名l1和l2与两个列表的引用的时候,两个列表会被标记为非存活对象,等待清除,无需我们手动去清除
问题:效率问题
标记-清除需要遍历堆区中所有的对象,每次回收内存,都要遍历一遍,这个工作量是非常庞大的,因此即为耗时,于是引入了“分代回收”算法,分代回收采用了以空间换时间的策略。
自动GC机制三:分代(generation)回收
这一策略的基本假设是:存活时间越久的对象,越不可能在后面的程序中变成垃圾。
• Python将所有的对象分为0,1,2三代。
• 所有的 新建对象都是0代对象 。
• 当某一代对象经历过垃圾回收,依然存活,那么它就被归入下一代对象。
• 垃圾回收启动时,一定会扫描所有的0代对象。
• 如果0代经过一定次数垃圾回收,那么就启动对0代和1代的扫描清理。 • 当1代也经历了一定次数的垃圾回收后,那么会启动对0,1,2,即对所有对象进行扫描。
总结:python采用的是引用计数机制为主,标记清除和隔代回收机制为辅的策略
三、Python内存池
Python整数内存池
整数缓冲区是在(-5~256)之间,系统已经初始化好,可以直接拿来用。而对于其他的大整数,系统则提 前申请了一块内存空间,等需要的时候在这上面创建大整数对象。
>>> a = 1
>>> b = 1
>>> id(a)
140552326182816
>>> id(b)
140552326182816
>>> a = 257
>>> b = 257
>>> id(a)
140552326841040
>>> id(b)
140552326841360
>>> b = 256
>>> a = 256
>>> id(a)
140552326190976
>>> id(b)
140552326190976
>>> a = -5
>>> b = -5
>>> id(a)
140552326182624
>>> id(b)
140552326182624
>>> b = -6
>>> a = -6
>>> id(a)
140552326841200
>>> id(b)
140552326841040
>>>
Python字符缓存(字符串驻留区 )
为了检验两个引用指向同一个对象,我们可以用is关键字。is用于判断两个引用所指的对象是否相同。
当触发缓存机制时,只是创造了新的引用,而不是对象本身。
>>>a = "xxx"
>>> b = "yyy"
>>> id(a)
140552327032424
>>> id(b)
140552327032480
>>> b = "xxx"
>>> id(b)
140552327032424
>>>>>> b = "xxx"
>>> id(b)
140552327032424
>>> a = "xxx "
>>> id(a)
140552327032536
>>> b = "xxx "
>>> id(b)
140552327032424
>>> a = "xxx_"
>>> b = "xxx_"
>>> id(a)
140552327032480
>>> id(b)
140552327032480
>>>
is:比较的是两个对象的id值是否相等,也就是比较俩对象是否为同一个实例对象。是否指向同一个内存地址
== : 比较的两个对象的内容/值是否相等,默认会调用对象的eq()方法
>>> a = 777
>>> b = 777
>>> a is b
False
>>> a == b
True
>>>
四、Python的浅深拷贝问题
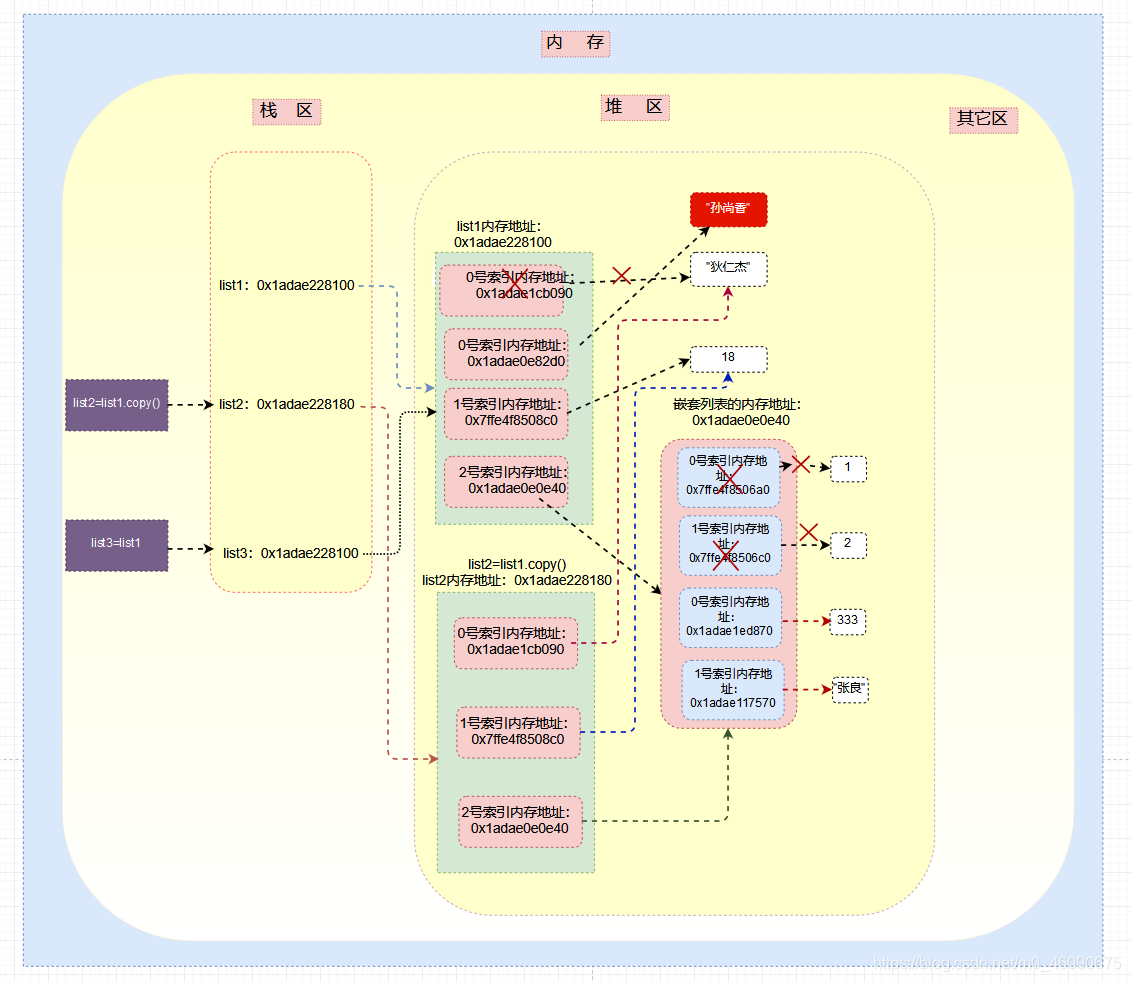
1、浅拷贝
把原对象第一层的内存地址不加区分(不区分可变类型还是不可变类型)完全copy一份给新对象。
>>> list1=["狄仁杰",18,[1,2]]
>>> list2=list1.copy() # 浅拷贝
>>> print(id(list1))
1845462466816
>>> print(id(list2))
1845462466944
>>>
>>> print(id(list1[0]),id(list1[1]),id(list1[2]))
1845462085776 140730232539328 1845461126720
>>> print(id(list2[0]),id(list2[1]),id(list2[2]))
1845462085776 140730232539328 1845461126720
>>>
# 可见浅拷贝只拷贝第一层的内存地址,第一层的内存地址与旧列表指向相同的内存空间
修改操作对浅拷贝的影响:
>>> list1[0]="孙尚香"
>>> list1[2][0]=333 # 修改嵌套列表第一个元素
>>> list1[2][1]="张良" # 修改嵌套列表第二个元素
>
>>> list1
['孙尚香', 18, [333, '张良']]
>>> list2
['狄仁杰', 18, [333, '张良']]
>>>
2、深拷贝
就是完整拷贝:copy.deepcopy(list1)
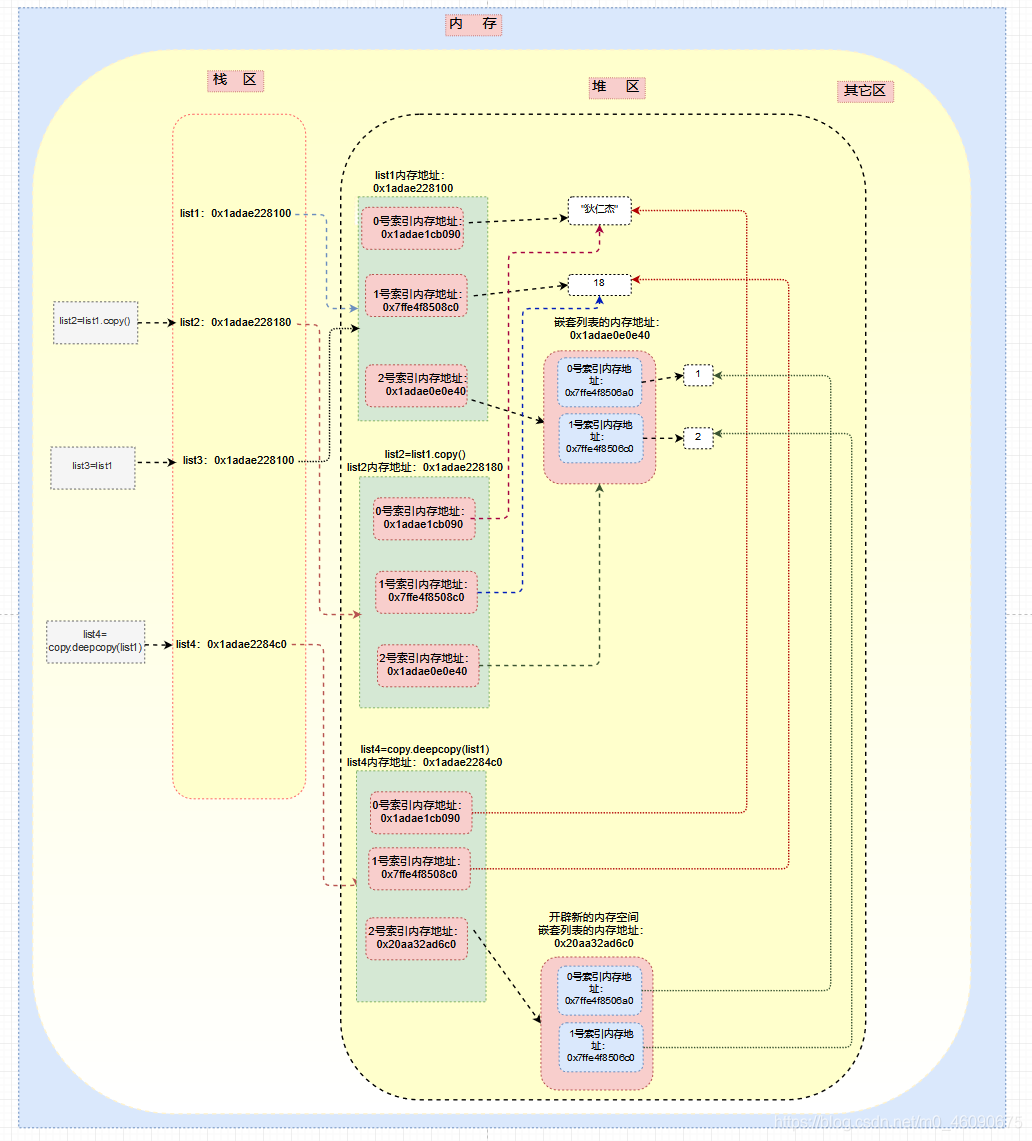
第二十一节:Python数据库操作
一、补充Mysql8的命令
# 创建用户
CREATE USER 'username'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';# 修改用户
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的密码';# 查询所有的用户
select user,host from mysql.user;# 给用户授权
GRANT ALL ON *.* TO `wangwei`@`127.0.0.1` WITH GRANT OPTION;# 执行完授权,需要执行flush privileges 指令,才能使新增权限生效。
flush privileges; //权限刷新create table ti(
id int auto_increment primary key,
name varchar(20),
age tinyint unsigned
)
#unsigned 从正数开始 例如: tinyint -127 - 127 | tinyint unsigned 0-255
#primary key 设置主键(仅有一个)
#auto_increment 自动变化#int
#smallint
#midiumin
#tinyint
#bigint二、Python操作数据库的三个库
1、MySQLdb
MySQLdb又叫MySQL-python ,是 Python 连接 MySQL 的一个驱动,很多框架都也是基于此库进行开发,遗憾的是它只支持 Python2.x,而且安装的时候有很多前置条件,因为它是基于C开发的库,在 Windows 平台安装非常不友好,经常出现失败的情况,现在基本不推荐使用,取代的是它的衍生版本。
2、Mysqlclient
由于 MySQLdb 年久失修,后来出现了它的 Fork 版本 mysqlclient,完全兼容 MySQLdb,同时支持 Python3.x,是 Django ORM的依赖工具,如果你想使用原生 SQL 来操作数据库,那么推荐此驱动。Mysqlclient是一个C扩展模块,编译安装可能会导致报各种错误。
pip install mysqlclient
官方下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#mysqlclient
import MySQLdbdb = MySQLdb.connect(host="127.0.0.1", port=3306, db="test1", user="root", password="123123", charset='utf8')
# cursor = db.cursor(MySQLdb.cursors.DictCursor)
cursor = db.cursor()
# 使用cursor()方法获取操作游标# SQL 插入语句
sql="insert into t_test(name, age) values(%s,%s)"
try:# 执行sql语句cursor.executemany(sql, [('Smith', 15), ('Mac', 20)])# 提交到数据库执行db.commit()#cursor.execute("select * from t_test")#data = cursor.fetchall()#print(data, type(data))
except Exception as ex:print(ex)# Rollback in case there is any errordb.rollback()
# 关闭数据库连接
db.close()
3、PyMySQL
PyMySQL是纯 Python 实现的驱动,速度上比不上 MySQLdb,最大的特点可能就是它的安装方式没那么繁琐。
直接使用pip进行安装,基本不会报错。
pip install pymysql
import pymysqldb = pymysql.connect(host="localhost", port=3306,user='root', #在这里输入用户名password='888888', #在这里输入密码charset='utf8mb4' ) #连接数据库cursor = db.cursor() #创建游标对象sql = 'show databases' #sql语句cursor.execute(sql) #执行sql语句one = cursor.fetchone() #获取一条数据
print('one:',one)many = cursor.fetchmany(3) #获取指定条数的数据,不写默认为1
print('many:',many)all = cursor.fetchall() #获取全部数据
print('all:',all)cursor.close()
db.close() #关闭数据库的连接三、基于mysqlclient的封装
import logging
import MySQLdbfrom MySQLdb import cursorsclass MySQLdbUtil(object):def __init__(self, host, user, passwd, db, port):self.host = hostself.user = userself.passwd = passwdself.db = dbself.port = portself.cursor = Noneself.conn = Nonedef get_connection(self):self.conn = MySQLdb.connect(self.host, self.user, self.passwd, self.db, self.port)def select_one(self, sql, args=None):try:self.get_connection()self.cursor = self.conn.cursor(cursors.DictCursor)self.cursor.execute(sql, args=args)data = self.cursor.fetchone()return dataexcept Exception as e:logging.error(e)finally:self.close()def select_many(self, sql, args=None):try:self.get_connection()self.cursor = self.conn.cursor(cursors.DictCursor)self.cursor.execute(sql, args=args)data = self.cursor.fetchall()return dataexcept Exception as e:logging.error(e)finally:self.close()def dml_operation(self, sql, args=None):try:self.get_connection()cursor = self.conn.cursor()count = cursor.execute(sql, args=args)self.conn.commit()return countexcept Exception as e:logging.error(e)self.conn.rollback()finally:self.close()def close(self):if self.cursor:self.cursor.close()if self.conn:self.conn.close()if __name__ == '__main__':client = MySQLdbUtil("127.0.1.1", "root", "123123", "test1", 3306)# result = client.select_many("select * from t_test;")# result = client.select_one("select * from t_test;")# result = client.dml_operation("update t_test set name=%s where id=%s", ('张三', 3))# result = client.dml_operation("insert into t_test(name, age) values(%s, %s)", ('张三33', 33))result = client.dml_operation("delete from t_test where id=%s", (4,))print(result)