10_Python基础到实战一飞冲天(三)-python面向对象(十)–文件操作和文本编码与eval函数
一、文件操作-04-打开文件方式以及写入和追加数据
1、打开文件的方式
open函数默认以 只读方式 打开文件,并且返回文件对象。
语法如下:
f = open("文件名", "访问方式")
2、文件打开方式参数说明
| 访问方式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式。如果文件不存在,抛出异常 |
| w | 以只写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件 |
| a | 以追加方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入 |
| r+ | 以读写方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,抛出异常 |
| w+ | 以读写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件 |
| a+ | 以读写方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入 |
3、提示
- 频繁的移动文件指针,会影响文件的读写效率,开发中更多的时候会以 只读、只写 的方式来操作文件。
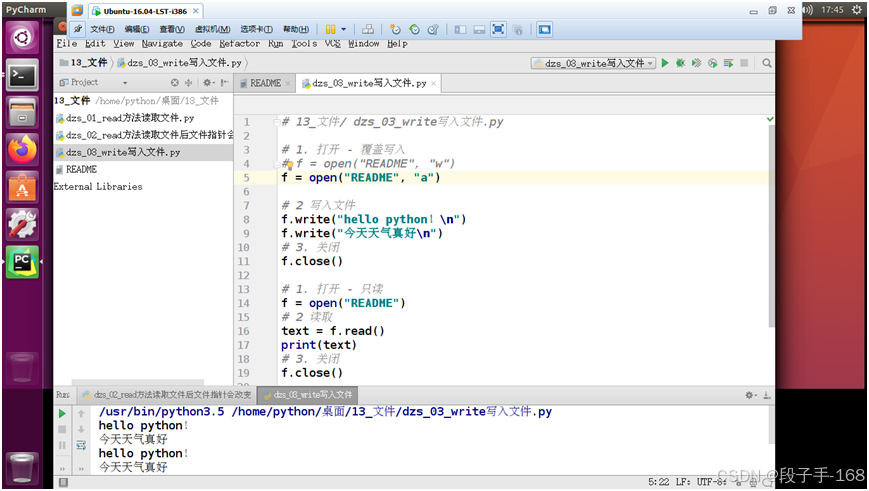
4、写入文件 示例 代码(dzs_03_write写入文件.py)
# 13_文件/README
HelloWorld
hello python
我是段子手168
# 13_文件/ dzs_03_write写入文件.py# 1. 打开 - 覆盖写入
# f = open("README", "w")
# 打开 - 追加写入
f = open("README", "a")# 2 写入文件
f.write("hello python!\n")
f.write("今天天气真好\n")
# 3. 关闭
f.close()# 1. 打开 - 只读
f = open("README")
# 2 读取
text = f.read()
print(text)
# 3. 关闭
f.close()5、示例:
二、文件操作-05-使用readline分行读取大文件
1、按行读取文件内容
1) read 方法默认会把文件的 所有内容 一次性读取到内存
2)如果文件太大,对内存的占用会非常严重。
2、 readline 方法按行读取文件内容
1) readline 方法可以一次读取一行内容。
2) 方法执行后,会把 文件指针 移动到下一行,准备再次读取。
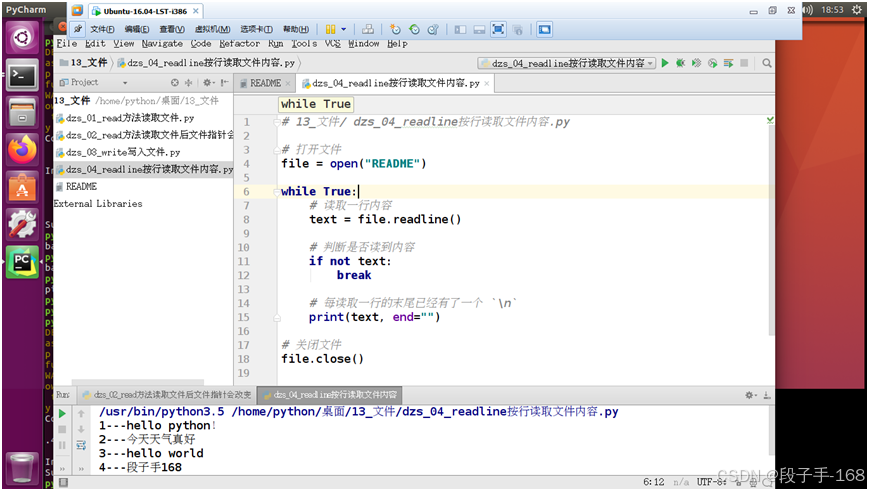
3、读取大文件的正确姿势使用 readline 按行读取 示例 代码(dzs_04_readline按行读取文件内容.py)
# 13_文件/ dzs_04_readline按行读取文件内容.py# 打开文件
file = open("README")while True:# 读取一行内容text = file.readline()# 判断是否读到内容if not text:break# 每读取一行的末尾已经有了一个 `\n`print(text, end="")# 关闭文件
file.close()4、示例:
三、文件操作-06-小文件复制
1、文件读写:用代码的方式,来实现文件复制过程
2、小文件复制
- 打开一个已有文件,读取完整内容,并写入到另外一个文件。
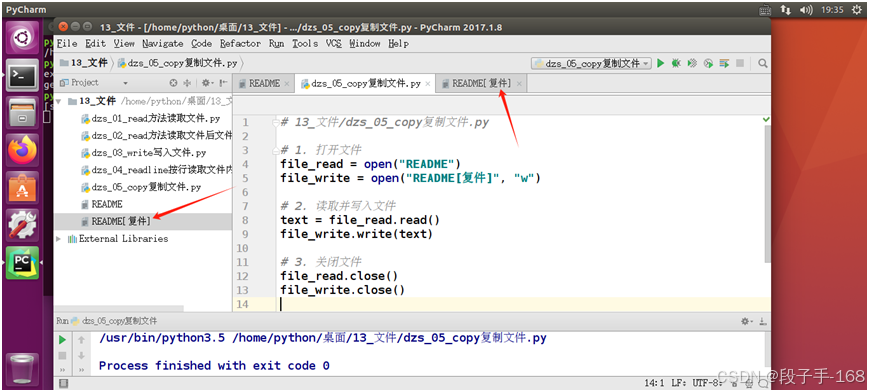
3、文件读写案例–复制文件 示例 代码(13_文件/dzs_05_copy复制文件.py):
# 13_文件/dzs_05_copy复制文件.py# 1. 打开文件
file_read = open("README")
file_write = open("README[复件]", "w")# 2. 读取并写入文件
text = file_read.read()
file_write.write(text)# 3. 关闭文件
file_read.close()
file_write.close()4、示例:
四、文件操作-07-大文件复制
1、大文件复制
- 打开一个已有文件,逐行读取内容,并顺序写入到另外一个文件
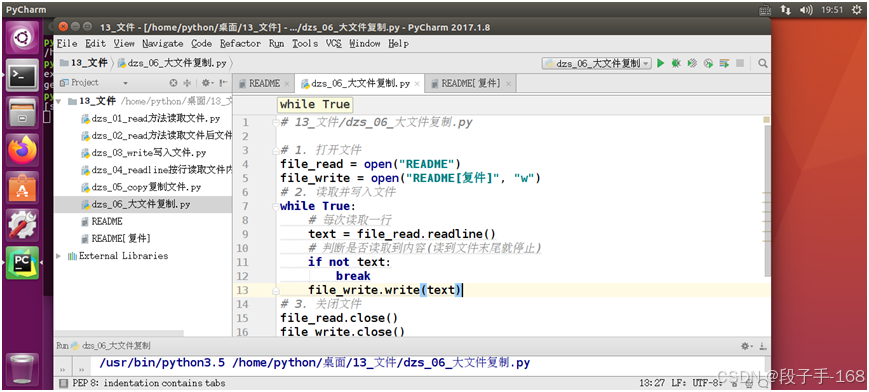
2、大文件复制文件 示例 代码(13_文件/dzs_06_大文件复制.py):
# 13_文件/dzs_06_大文件复制.py# 1. 打开文件
file_read = open("README")
file_write = open("README[复件]", "w")# 2. 读取并写入文件
while True:# 每次读取一行 text = file_read.readline()# 判断是否读取到内容(读到文件末尾就停止)if not text:breakfile_write.write(text)# 3. 关闭文件
file_read.close()
file_write.close()3、示例:
五、导入os模块,执行文件和目录管理操作
1、文件/目录的常用管理操作
1)在 终端 / 文件浏览器、 中可以执行常规的 文件 / 目录 管理操作,例如:
* 创建、重命名、删除、改变路径、查看目录内容、……。
2)在 Python 中,如果希望通过程序实现上述功能,需要导入 os 模块。
2、文件操作
| 序号 | 方法名 | 说明 | 示例 |
|---|---|---|---|
| 01 | rename | 重命名文件 | os.rename(源文件名, 目标文件名) |
| 02 | remove | 删除文件 | os.remove(文件名) |
3、目录操作
| 序号 | 方法名 | 说明 | 示例 |
|---|---|---|---|
| 01 | listdir | 目录列表 | os.listdir(目录名) |
| 02 | mkdir | 创建目录 | os.mkdir(目录名) |
| 03 | rmdir | 删除目录 | os.rmdir(目录名) |
| 04 | getcwd | 获取当前目录 | os.getcwd() |
| 05 | chdir | 修改工作目录 | os.chdir(目标目录) |
| 06 | path.isdir | 判断是否是文件 | os.path.isdir(文件路径) |
提示:文件或者目录操作都支持 相对路径 和 绝对路径
4、在 ipython3 中演示文件和文件夹操作
python@Ubuntu:~/桌面$ ipython3
Python 3.5.2 (default, Jan 26 2021, 13:30:48)
Type "copyright", "credits" or "license" for more information.IPython 2.4.1 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
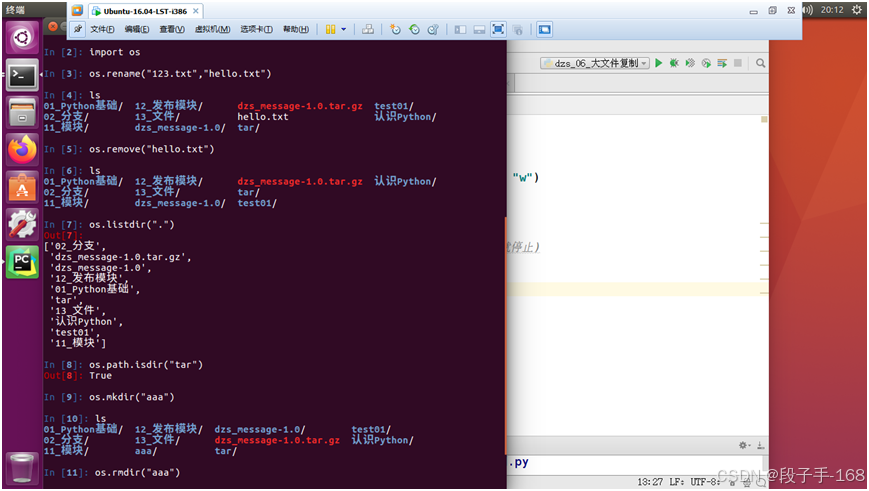
object? -> Details about 'object', use 'object??' for extra details.In [1]: ls
01_Python基础/ 123.txt dzs_message-1.0/ test01/
02_分支/ 12_发布模块/ dzs_message-1.0.tar.gz 认识Python/
11_模块/ 13_文件/ tar/In [2]: import osIn [3]: os.rename("123.txt","hello.txt")In [4]: ls
01_Python基础/ 12_发布模块/ dzs_message-1.0.tar.gz test01/
02_分支/ 13_文件/ hello.txt 认识Python/
11_模块/ dzs_message-1.0/ tar/In [5]: os.remove("hello.txt")In [6]: ls
01_Python基础/ 12_发布模块/ dzs_message-1.0.tar.gz 认识Python/
02_分支/ 13_文件/ tar/
11_模块/ dzs_message-1.0/ test01/In [7]: os.listdir(".")
Out[7]:
['02_分支','dzs_message-1.0.tar.gz','dzs_message-1.0','12_发布模块','01_Python基础','tar','13_文件','认识Python','test01','11_模块']In [8]: os.path.isdir("tar")
Out[8]: TrueIn [9]: os.mkdir("aaa")In [10]: ls
01_Python基础/ 12_发布模块/ dzs_message-1.0/ test01/
02_分支/ 13_文件/ dzs_message-1.0.tar.gz 认识Python/
11_模块/ aaa/ tar/In [11]: os.rmdir("aaa")In [12]: ls
01_Python基础/ 12_发布模块/ dzs_message-1.0.tar.gz 认识Python/
02_分支/ 13_文件/ tar/
11_模块/ dzs_message-1.0/ test01/5、示例:
六、文本编码-01-文本文件的编码方式ASCII和UTF8
1、文本文件的编码格式(科普)
- 文本文件存储的内容是基于 字符编码 的文件,常见的编码有
ASCII编码,UNICODE编码等。
Python 2.x 默认使用
ASCII编码格式
Python 3.x 默认使用UTF-8编码格式
2、 ASCII 编码
1)计算机中只有 256 个 ASCII 字符
2)一个 ASCII 在内存中占用 1 个字节 的空间。
* 8 个 0/1 的排列组合方式一共有 256 种,也就是 2 ** 8。
3、 UTF-8 编码格式
1)计算机中使用 1~6 个字节 来表示一个 UTF-8 字符,涵盖了 地球上几乎所有地区的文字。
2)大多数汉字会使用 3 个字节 表示。
3) UTF-8 是 UNICODE 编码的一种编码格式。
七、文本编码-02-怎么样在Python2.x中使用中文
1、 Ptyhon 2.x 中如何使用中文
Python 2.x 默认使用
ASCII编码格式
Python 3.x 默认使用UTF-8编码格式
1)在 Python 2.x 文件的 第一行 增加以下代码,解释器会以 utf-8 编码来处理 python 文件
# *-* coding:utf8 *-*
这方式是官方推荐使用的!
2)也可以使用
# coding=utf8
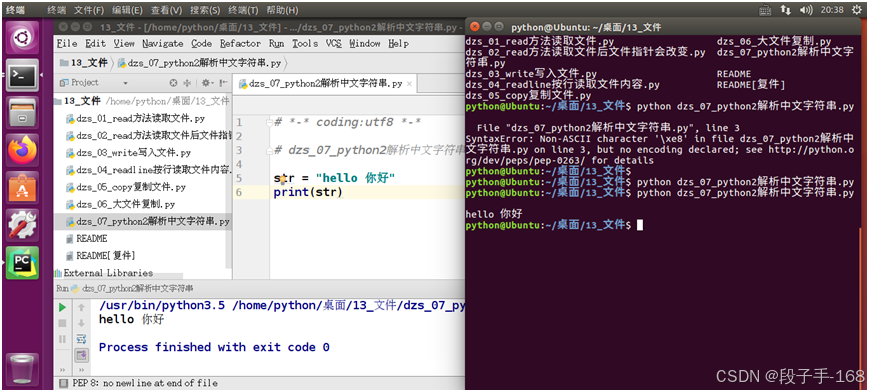
2、python2解析中文 示例 代码(dzs_07_python2解析中文字符串.py):
# *-* coding:utf8 *-*# dzs_07_python2解析中文字符串.pystr = "hello 你好"
print(str)3、示例:
八、文本编码-03-Python2.x处理中文字符串
1、 unicode 字符串
1)在 Python 2.x 中,即使指定了文件使用 UTF-8 的编码格式,但是在遍历字符串时,仍然会 以字节为单位遍历 字符串。
2)要能够 正确的遍历字符串,在定义字符串时,需要 在字符串的引号前,增加一个小写字母 u,告诉解释器这是一个 unicode 字符串(使用 UTF-8 编码格式的字符串)。
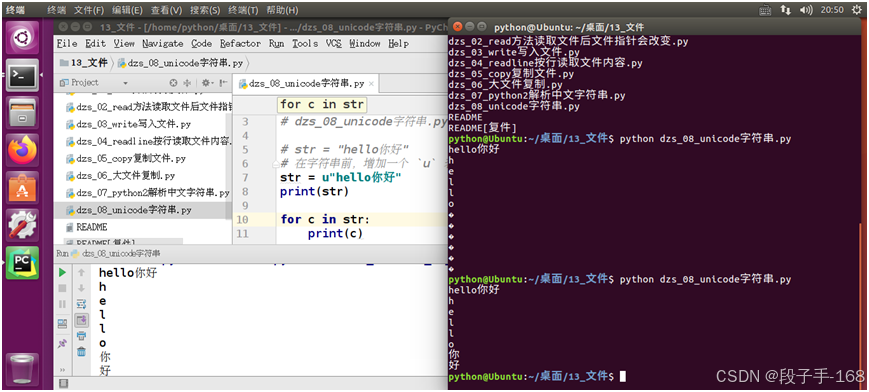
2、 unicode 字符串 示例 代码(dzs_08_unicode字符串.py)
# *-* coding:utf8 *-*# dzs_08_unicode字符串.py# str = "hello你好"
# 在字符串前,增加一个 `u` 表示这个字符串是一个 utf8 字符串
str = u"hello你好"
print(str)for c in str:print(c)3、示例:
九、eval-01-基本使用
1、 eval 函数
eval() 函数十分强大 —— 将字符串 当成 有效的表达式 来求值 并 返回计算结果
2、在 ipython3中演示 eval 函数 示例 代码
# 基本的数学计算
In [1]: eval("1 + 1")
Out[1]: 2# 字符串重复
In [2]: eval("'*' * 10")
Out[2]: '**********'# 将字符串转换成列表
In [3]: type(eval("[1, 2, 3, 4, 5]"))
Out[3]: list# 将字符串转换成字典
In [4]: type(eval("{'name': 'xiaoming', 'age': 18}"))
Out[4]: dict
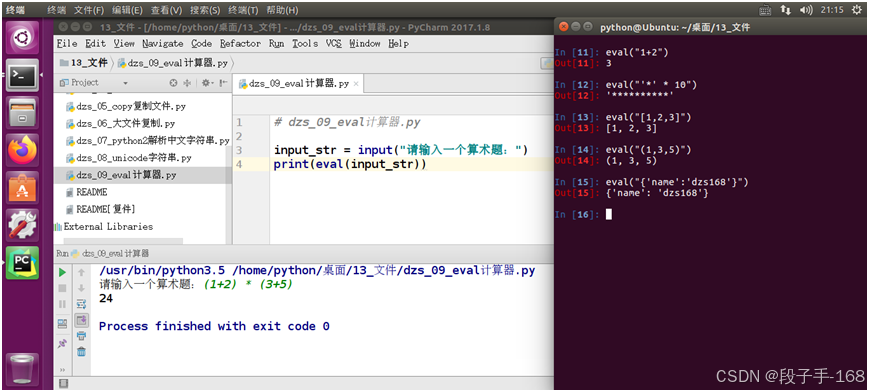
3、eval 函数 案例 - 简单计算器
1)需求
- 提示用户输入一个 加减乘除混合运算,返回计算结果。
2)示例代码(dzs_09_eval计算器.py)
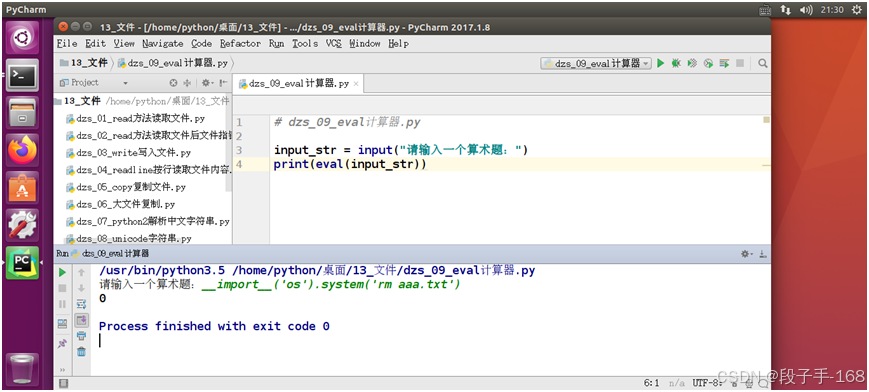
# dzs_09_eval计算器.pyinput_str = input("请输入一个算术题:")print(eval(input_str))4、示例:
十、eval-02-[扩展]不要直接转换input结果
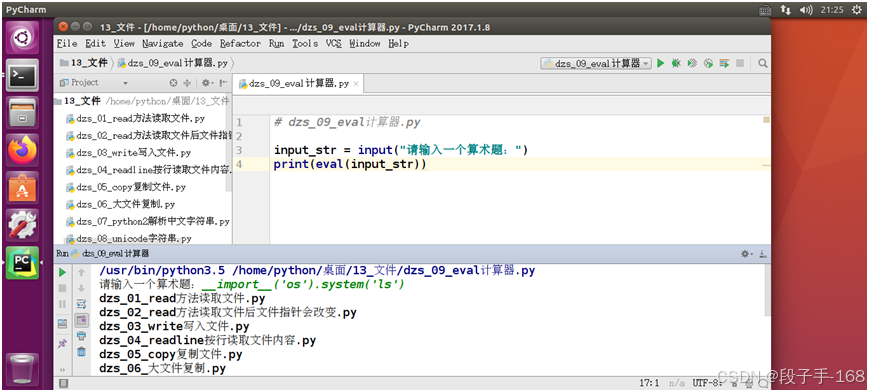
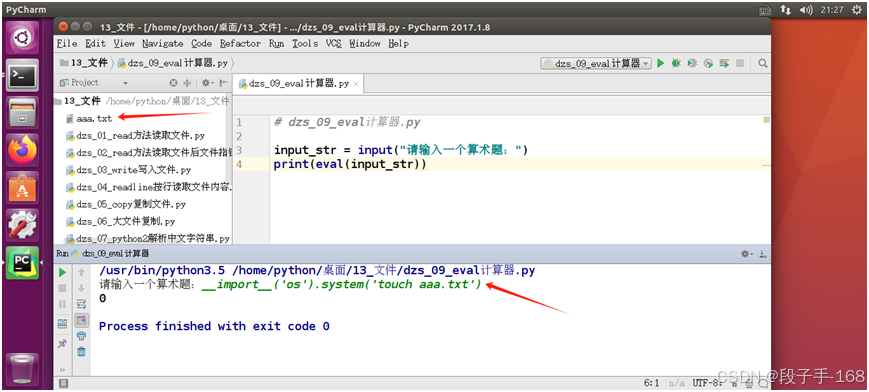
1、 不要滥用 eval 函数
在开发时千万不要使用
eval直接转换input的结果
__import__('os').system('ls')__import__('os').system('touch aaa.txt')__import__('os').system('rm aaa.txt')
- 等价代码
import osos.system("终端命令")
- 执行成功,返回 0
- 执行失败,返回错误信息
2、示例
上一节关联链接请点击:
09_Python基础到实战一飞冲天(三)-python面向对象(九)–包模块pip安装和文件