对象存储是一种云存储服务,具有海量、安全、低成本和高可靠性的特点,适合存放任意类型的文件。它提供了容量和处理能力的弹性扩展,用户可以根据需求选择不同的存储类型,已经逐渐成为云计算、大数据分析和数据备份等领域的首选存储解决方案。
在对象存储领域,Ozone 是一个备受关注的开源项目。Ozone 旨在提供一个可扩展、高性能、持久性和多租户的对象存储系统。它采用了一种分层的存储架构,可以轻松地扩展到成百上千的节点,并具有优秀的容错性和数据安全性。
而在对象存储内部,元数据管理十分地重要,凡是涉及到对象存储的数据访问,都会经过元数据的查询或更新操作,如果元数据操作出现性能瓶颈,将会严重影响存储系统的性能表现。随着AI时代的快速发展,对存储技术提出了更高的要求,尤其在大规模、高性能和低成本方面。Ozone作为一款为大数据场景打造的对象存储系统,必然面临海量文件元数据管理的挑战。本文介绍了360基于Ozone的元数据系统架构演进,以及遇到的挑战与作出的优化。
1

Ozone概述
Ozone 是一个分布式、多副本的对象存储系统,同时针对大数据场景进行了专门的优化。Apache Spark、Hive 和 YARN 等应用无需任何修改即可使用 Ozone。Ozone 提供了 Java API、S3 接口和命令行接口,极大地方便了 Ozone 在不同应用场景下的使用。
Ozone 的管理由卷、桶和键组成。卷的概念和用户账号类似,只有管理员可以创建和删除卷。卷用来存储桶,桶的概念和目录类似,用户可以在自己的卷下创建任意数量的桶,每个桶可以包含任意数量的键,但是不可以包含其它的桶。键的概念和文件类似,用户通过键来读写数据。
下图展示了Ozone的核心组件:
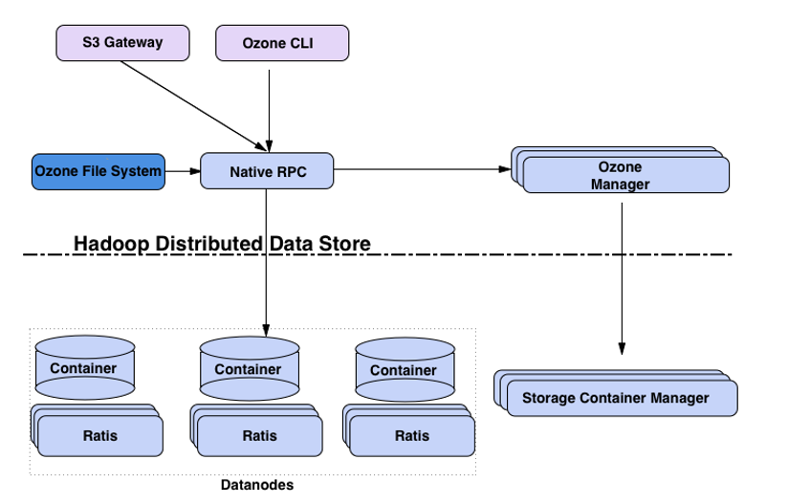
Ozone 通过对命名空间与块空间的管理进行分离,大大增加了其可扩展性,其中命名空间由存储卷组成,统一由 Ozone Manager (OM)管理,块空间由 Storage Container Manager(SCM)管理,数据由Datanode节点存储,数据之间的复制使用raft协议。
SCM+Datanode 的组合可以提供块接口,对其抽象出一层,称之为Hadoop Distributed Data Store(HDDS)。
2

元数据系统的架构演进
社区版Ozone Manager使用 RocksDB 在本地持久化元数据(卷、桶和键)。使用 Apache Ratis(一种 Raft 协议的开源实现)来同步 Ozone Manager 的状态和元数据,这为 Ozone 提供了高可用保证。
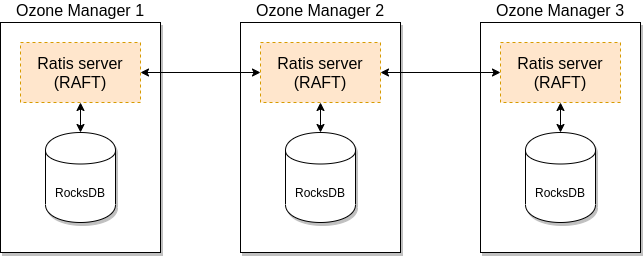
但是这种方案也存在问题:
1)随着元数据体量逐渐增加,单机RocksDB容量成为瓶颈,元信息存储上限受限于单机磁盘的大小,无法满足海量数据规模的存储需求;
2)元信息基于raft协议复制到follower节点,需要引入snapshot等功能保证元信息在所有OM节点的一致性,复杂度偏高。
基于此我们决定将OM元数据存储到分布式KV中,一方面om leader无需再向Follower节点同步数据,只需要同步状态即可;另一方面可以去掉快照snapshot的逻辑,元数据的一致性由分布式KV保证。
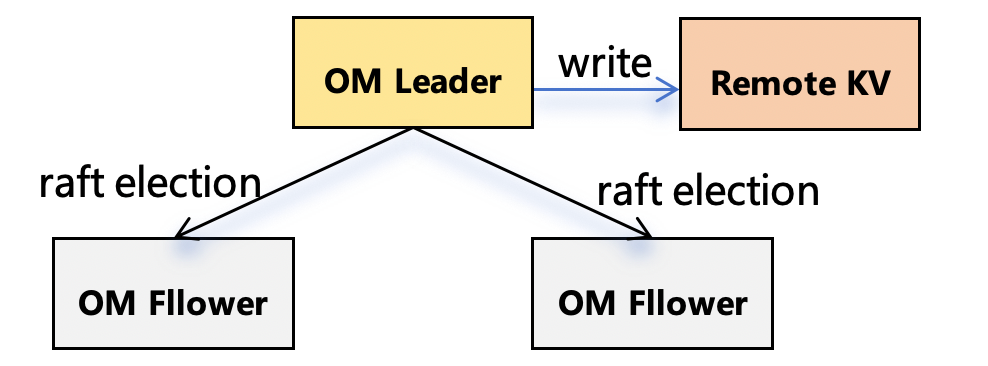
分布式KV的选型这里考虑了以下三点:
om的元信息通过double buffer flush将多次db操作合并为一次,数据库需要支持多表多行batch操作的原子性;
数据需要按照key名有序存储,便于实现s3的object list等操作;
规模可以水平扩展,依赖组件少。
在对业界的分布式KV数据库进行一系列调研后,我们选择使用Apache Cassandra作为元数据系统存储底座。
多种数据分区策略,支持ByteOrderedPartitioner,与rocksdb排序规则相同;
支持多表多行batch操作的原子性;
无中心节点架构,可调节的一致性模型,规模可水平扩展;
支持多数据中心部署,可保证元数据的异地容灾;
方便与计算引擎结合,进行分布式的元信息分析(如spark-cassandra-connector)。
3

元数据系统的挑战与优化
3.1 元数据读写分离
随着对象存储承接的请求越来越多,主节点的RPC压力也越来越大,而且大文件因元信息过大,在反序列化时会产生临时的大对象,频繁读取大文件的元数据,很容易触发OM的java垃圾回收从而影响整体服务质量。基于此我们考虑实现元数据读写分离,一方面可以减轻主节点RPC压力和GC压力,另一方面也缩短了元数据的读取路径,降低读取时延。
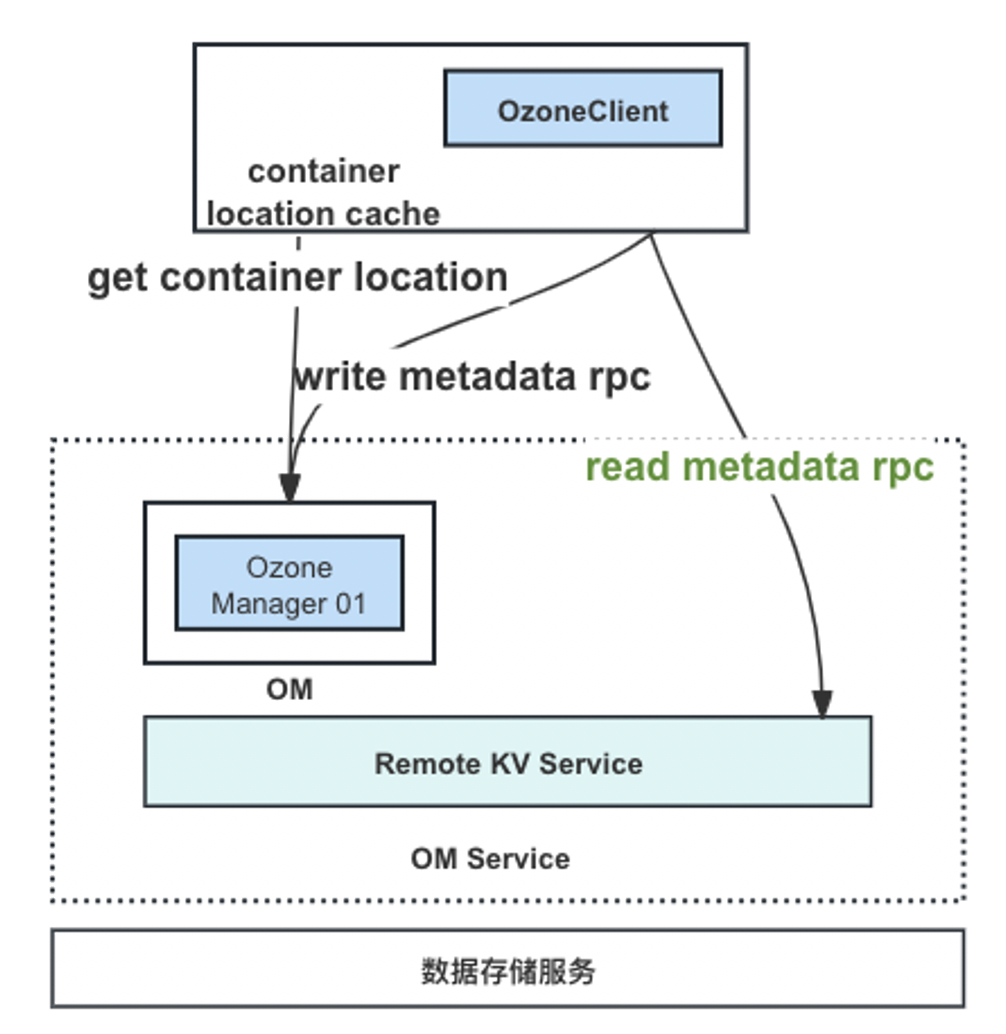
由于已经将元数据存储至分布式KV,不存在OM Follower节点与Leader节点数据同步有延迟的情况,所以这里使用客户端直接连接分布式KV读取元信息。
客户端会实现类似于OM的ContainerLocationCache,缓存container的位置信息,如果是List/Head Object 请求则直接从KV读取元信息;如果是Get Object请求,则除了从KV读取元信息以外,还需要从客户端的container location cache获取container位置信息,如未获取到则从om端获取。
3.2 元信息处理能力无限扩展
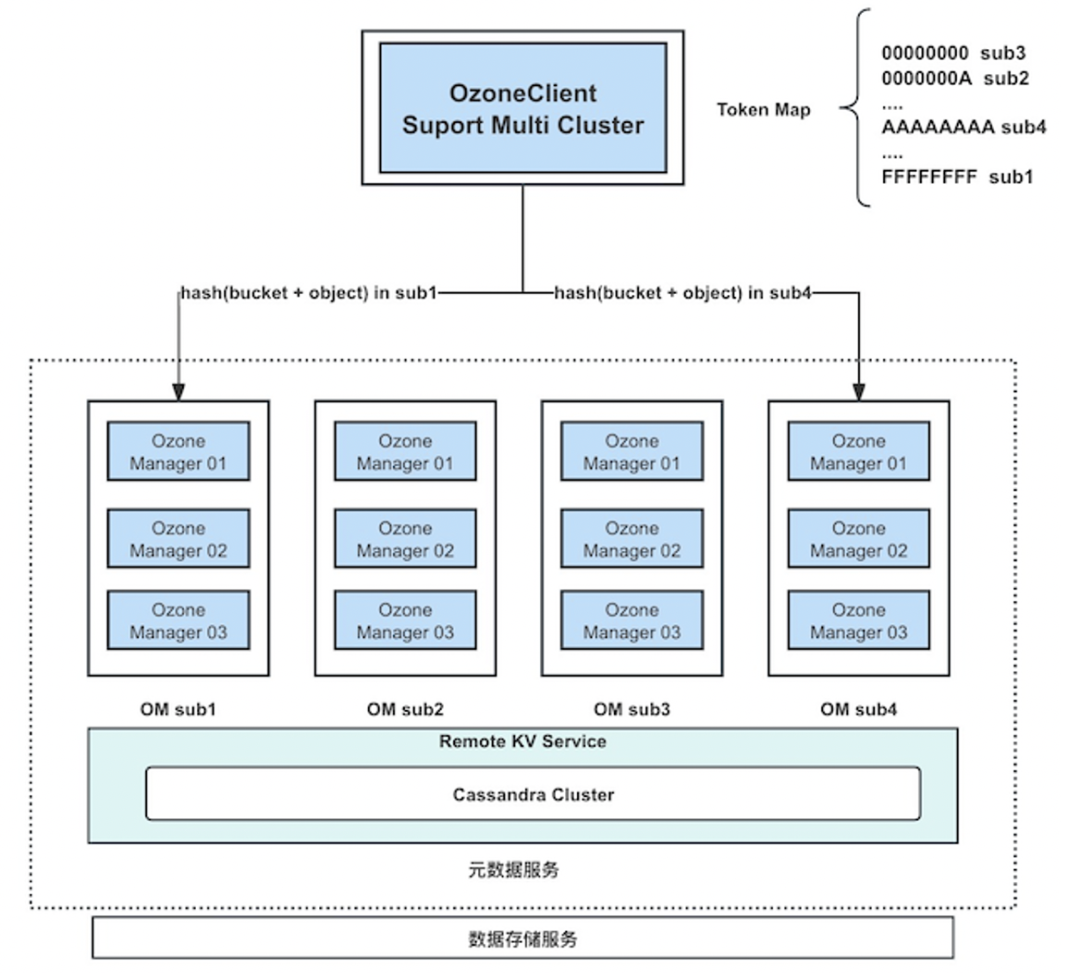
元数据存储需要极高的扩展性来支持数据的大量存储和快速增长。一组OM的RPC处理能力其实是有上限的,一个OM Leader节点的硬件条件根本无法支撑超大规模的元数据读写场景。目前社区版本只能通过拆分桶到其它集群来突破其处理上限,为了满足更高的扩展性,我们在一个Ozone集群中扩展了多组OM,通过hash分区打散RPC请求到多组OM,解决主节点的单点瓶颈问题。
将元信息存储到分布式KV,意味着我们具备了共享元信息的能力,可以很方便的扩展多组om去连接同一个分布式KV,数据一致性由分布式KV保证。
这里在OzoneClient端实现一个TokenMap,如图所示,通过hash算法将请求路由到多组OM上。多组OM是无状态的,每组OM逻辑上可以处理所有的元数据请求。
3.3 元数据分区管理
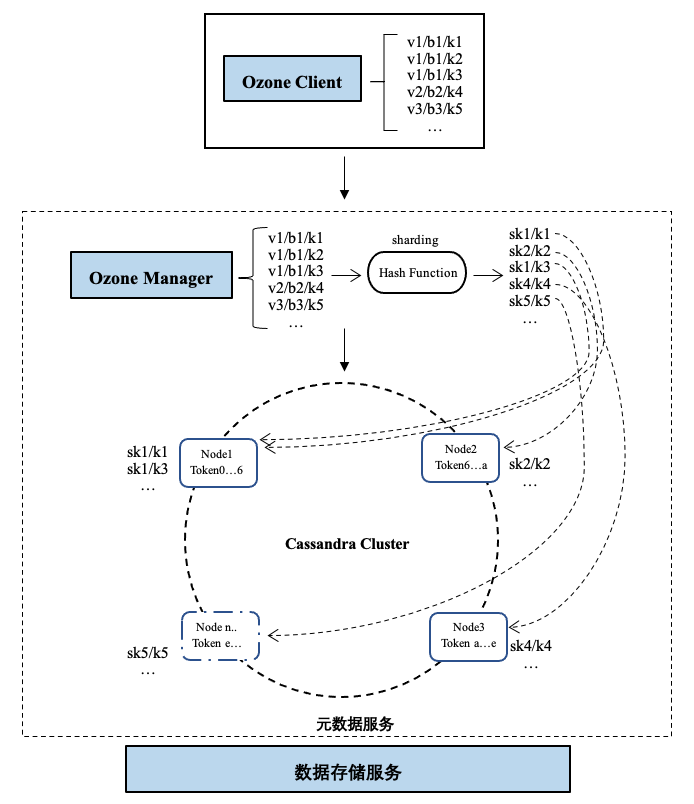
在大数据场景下,由于桶和桶之间的对象数量有可能差距很大,存储元数据的节点可能会存在非常大的数据倾斜问题。元数据集中在部分存储节点,极端情况下,所有负载可能会压在一个节点,其余节点空闲,系统瓶颈就落在这最忙的“热节点”上,这会对单机的性能造成较大压力,影响服务稳定性。
为了解决这个问题,我们优化了数据分布的策略。使用复合分区,先hash分区,再range分区。具体就是在元数据最前面增加一个hash产生的shardKey,不同shardKey的数据间隔放置,同一个shardKey下的数据顺序放置,这样元信息“热节点”数据就可以被分散到多个节点上。
推荐阅读:
云舟观测:Arkit数据解析插件详解
iOS屏幕共享技术实践
更多技术和产品文章,请关注👆
如果您对哪个产品感兴趣,欢迎留言给我们,我们会定向邀文~
360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。
目前,智汇云提供数据库、中间件、存储、大数据、人工智能、计算、网络、视联物联与通信等多种产品服务以及一站式解决方案,助力客户降本增效,累计服务业务1000+。
智汇云致力于为各行各业的业务及应用提供强有力的产品、技术服务,帮助企业和业务实现更大的商业价值。
官网:https://zyun.360.cn 或搜索“360智汇云”
客服电话:4000052360