ID:数据的唯一标识。
并发流量大采用Mysql分库分表(Sharding-JDBC)
分布式ID满足要求:
- 全局唯一
- 生成Id速度快,对本地资源消耗少
- 生成Id服务需高可用(不能出错)
- id有序递增(提升DataBase写入速度)
- 有具体业务含义(通过id定位问题更加透明)
- 分布式Id场景多,需要独立部署发号器服务
解决方案
一、数据库
在主键自增(auto_inc)的场景下
使用replace into代替 insert into
步骤:
- 尝试将数据插入表中
- 判断主键/唯一索引是否重复出现,如果出现重复,则删除该重复行,再尝试判将数据插入表中

优点:简单、id、有序递增、存储空间消耗少
缺点:并发不高,Id没有具体业务含义,存在安全问题(通过订单id的递增规律,可以推断出每天的订单数,商业机密不可随意泄露),每次获取数据,都要向数据库发送请求(数据库压力上升,获取速度变慢)
数据库号字段
存在内存中
问题:单点问题
开源项目:Tinyid
NoSQL
redis Cluster / Codis(redis集群方案)
RDB 和 AOF
缺点:与自增类似
MongoDB
ObjectId --> 分布式id解决方案
缺点:重复id问题、安全(id有规律)
二、算法
UUID算法(通用唯一标识符)
// 生成ID
UUID.randomUUID();
注:5种不同version的值对应的含义不一致。
优点:生成快、简单、UUID可保证唯一性,因为其生成规则包含MAC地址、时间戳、名字空间(NameSpace)、随机/伪随机数、时序等元素。
缺点:存储消耗空间大(32个字符,128位),不安全(基于MAC地址生成的UUID,会导致MAC地址泄露),无具体业务含义,重复ID(机器时间错误的情况下)
雪花算法(Snowflake)
Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 由 64 bit 的二进制数字组成,这 64bit 的二进制被分成了几部分,每一部分存储的数据都有特定的含义:
生成id组成如下:
| sign | timestamp | datacenter id | worker id | sequence | |
|---|---|---|---|---|---|
| 占用空间(bit) | 1 | 41 | 5 | 5 | 12 |
| 含义 | 符号位,始终为0,代表id为正数 | 时间戳(毫秒) | 机房id | 机器id | 序列号(自增),单台机器每毫秒能产出的最大id数(2^12 = 4096个) |
优点:速度快、Id有序
缺点:
- id重复问题(依赖时间、存在时间回拨问题)
- 依赖机器id问题
Seata
改良版雪花算法,改进原版雪花算法的时间回拨问题,大幅提高QPS
内置分布式UUID生成器,用于辅助生成全局事务ID和分支事务ID
Seata官网介绍
Uid Generator(百度)
UidGenerator 是百度开源的基于Snowflake(雪花算法)的进行改进的唯一ID生成器。
生成id组成如下:
| sign | delta seconds | Worker id | sequence | |
|---|---|---|---|---|
| 占用空间(bit) | 1 | 28 | 22 | 13 |
| 含义 | 符号位,始终为0,代表id为正数 | 当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约 8.7 年 | 机器 id,最多可支持约 420w 次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略 | 每秒下的并发序列,13 bits 可支持每秒 8192 个并发。 |
Uid Generator官方介绍
Leaf(美团)
Leaf 提供了 号段模式 和 Snowflake(雪花算法) 这两种模式来生成分布式 ID。并且支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper(使用 Zookeeper 作为注册中心,通过在特定路径下读取和创建子节点来管理 workId) 。
Leaf 对原有的号段模式进行改进,比如这里增加了双号段避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是一个号段还没用完之前,系统就主动提前去获取下一个号段(图片来自于美团官方文章:《Leaf——美团点评分布式 ID 生成系统》)。
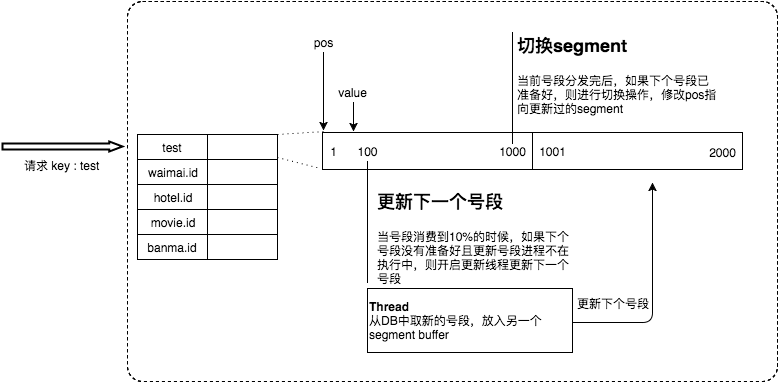
根据项目 README 介绍,在 4C8G VM 基础上,通过公司 RPC 方式调用,QPS 压测结果近 5w/s,TP999 1ms。
Leaf官方介绍
Tinyid(滴滴)
Tinyid 是滴滴开源的一款基于数据库号段模式的唯一 ID 生成器。
数据库号段模式的原理我们在上面已经介绍过了。Tinyid 有哪些亮点呢?
基于数据库号段模式的简单架构方案:
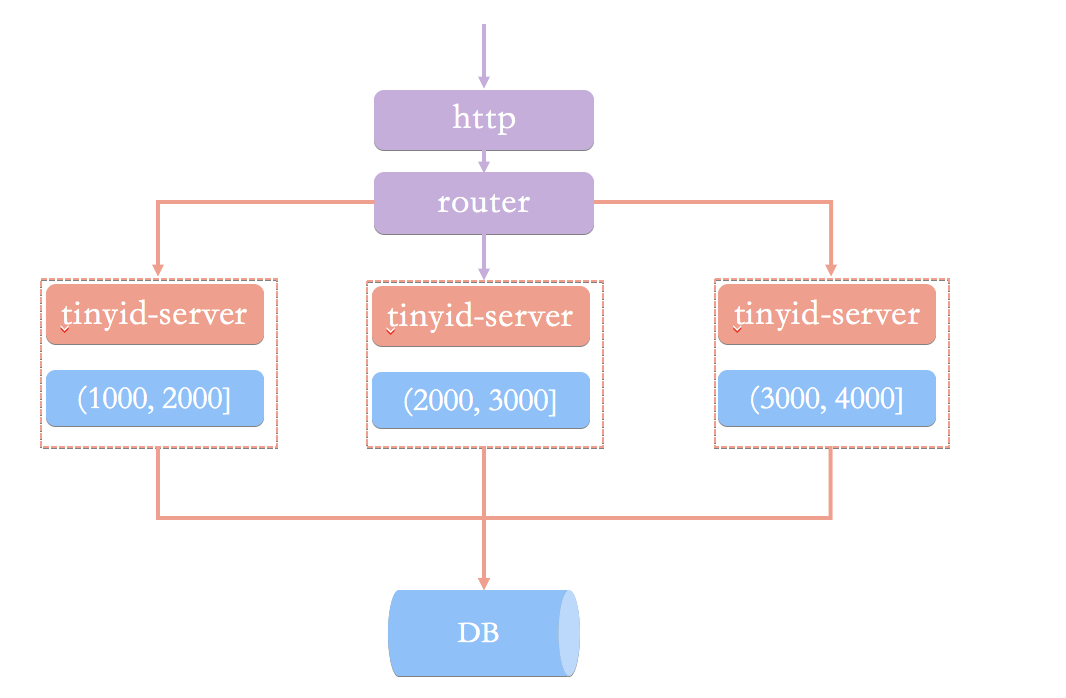
通过 HTTP 请求向发号器服务申请唯一 ID。负载均衡 router 会把我们的请求送往其中的一台 tinyid-server。
上述架构主要存在问题:
- 获取新号段的情况下,程序获取唯一 ID 的速度比较慢。
- 需要保证 DB 高可用,这个是比较麻烦且耗费资源的。
- HTTP 调用存在网络开销。
Tinyid 的原理比较简单,其架构如下图所示
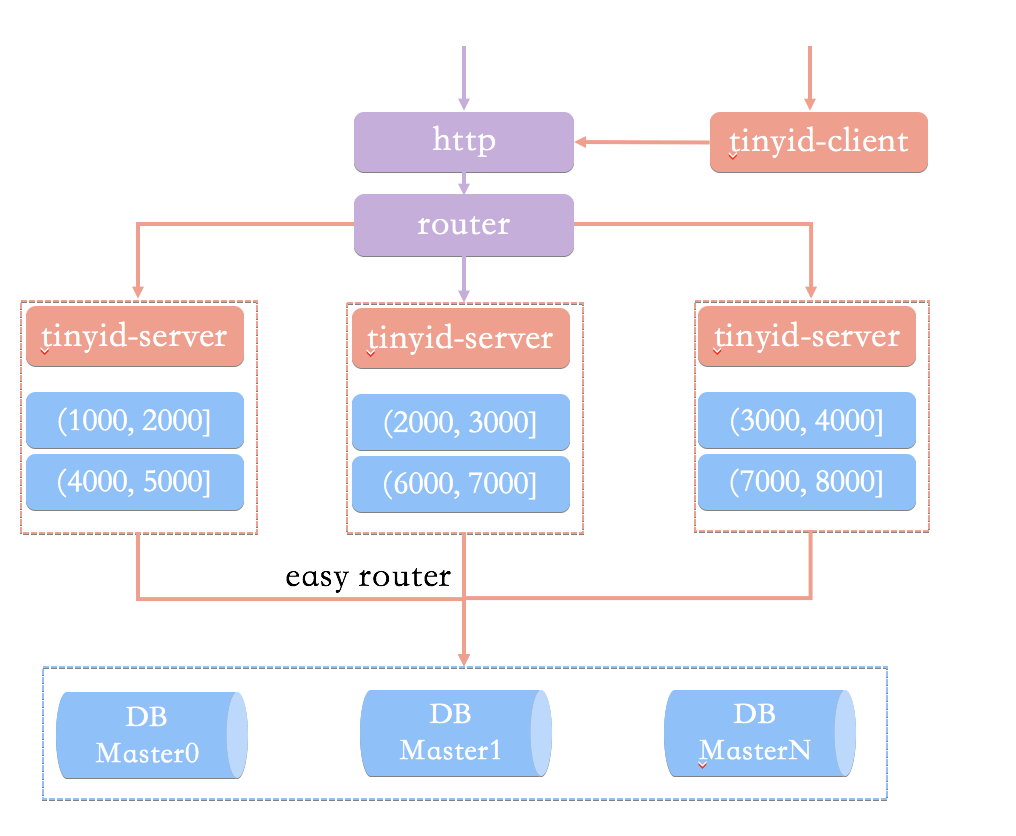
相比于基于数据库号段模式的简单架构方案,Tinyid 的优化方案:
- 双号段缓存:为了避免在获取新号段的情况下,程序获取唯一 ID 的速度比较慢。 Tinyid 中的号段在用到一定程度的时候,就会去异步加载下一个号段,保证内存中始终有可用号段。
- 增加多 db 支持:支持多个 DB,并且,每个 DB 都能生成唯一 ID,提高了可用性。
- 增加 tinyid-client:纯本地操作,无 HTTP 请求消耗,性能和可用性都有很大提升。
Tinyid官方介绍
总结:
本文主要介绍的是分布式 ID 的理论知识。在实际的面试中,面试官可能会结合具体的业务场景来考察面试者对分布式 ID 的设计。