Java之stream流的详细解析一-CSDN博客(以下均参考这个)
stream:创建流(Arraylist自带了.stream就行)->中间操作(.filter)->终结操作(.foreach)/收集操作(.collect)
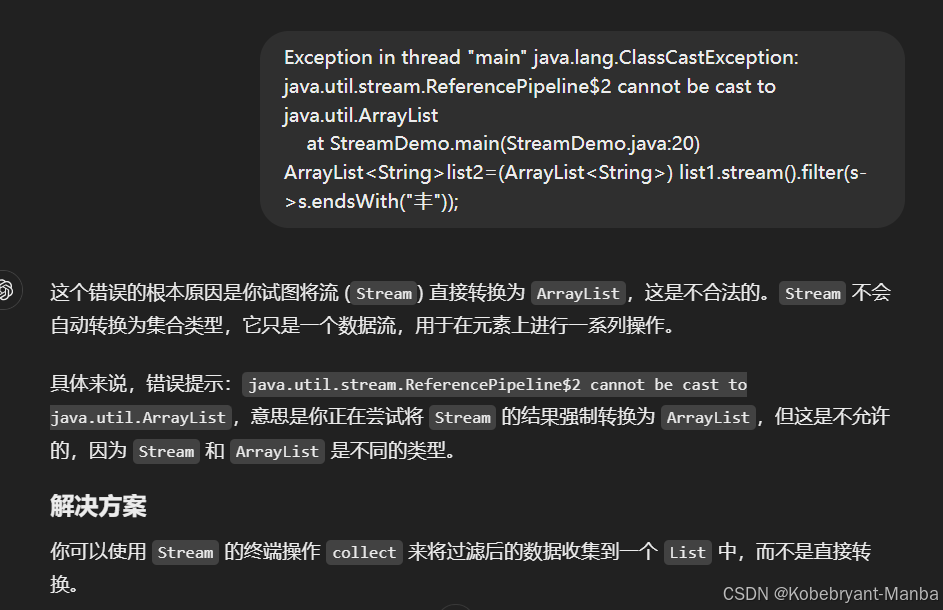
public class StreamDemo {public static void main(String[] args) {//集合的批量添加ArrayList<String> list1 = new ArrayList<>(Arrays.asList("张三丰", "张无忌", "张翠山"));//Stream流list1.stream().filter(s->s.startsWith("张")).filter(s->s.length() == 3).forEach(s-> System.out.println(s));list1.stream().filter(s->s.endsWith("丰")).forEach(s-> System.out.println(s));
// ArrayList<String>list2=(ArrayList<String>) list1.stream().filter(s->s.endsWith("丰"));ArrayList<String> list2 = list1.stream().filter(s -> s.endsWith("丰")).collect(Collectors.toCollection(ArrayList::new));
//.collect(Collectors.toCollection(ArrayList::new)):将流的结果收集到一个新的 ArrayList 中。
// Collectors.toCollection(...):这是 Collectors 类中的一个方法,它接收一个工厂方法(通常是集合的构造函数引用),并将流 (Stream) 中的元素收集到该集合类型中。它允许你指定要收集到哪种类型的集合中。
//ArrayList::new:这是 ArrayList 构造方法的引用,等价于 new ArrayList<>()。它表示使用 ArrayList 的无参构造函数来创建一个新的 ArrayList 实例。list2.forEach(s-> System.out.println(s));Stream<String> list3=Stream.concat(list1.stream(),list2.stream());list3.forEach(s-> System.out.println("---------"+s));}
}注意:
//集合的批量添加 jdk8只能用aslist 之后才能用listof
ArrayList<String> list1 = new ArrayList<>(Arrays.asList("张三丰", "张无忌", "张翠山"));
stream那些操作都是变成stream流了
运行结果:
终结操作:
import java.util.ArrayList;
import java.util.function.Consumer;/*** 功能:* 作者:IT伟* 日期:2024/10/11 14:31*/
public class MyStream5 {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();list.add("张三丰");list.add("张无忌");list.add("张翠山");list.add("王二麻子");list.add("张良");list.add("谢广坤");method1(list);// long count():返回此流中的元素数long count = list.stream().count();System.out.println(count);}private static void method1(ArrayList<String> list) {// void forEach(Consumer action):对此流的每个元素执行操作// Consumer接口中的方法void accept(T t):对给定的参数执行此操作//在forEach方法的底层,会循环获取到流中的每一个数据.//并循环调用accept方法,并把每一个数据传递给accept方法//s就依次表示了流中的每一个数据.//所以,我们只要在accept方法中,写上处理的业务逻辑就可以了.list.stream().forEach(new Consumer<String>() {@Overridepublic void accept(String s) {System.out.println(s);}});// 上面等同于lambda的:
// list.stream().forEach(
// s -> System.out.println(s)
// );System.out.println("====================");//lambda表达式的简化格式//是因为Consumer接口中,只有一个accept方法list.stream().forEach((String s)->{System.out.println(s);});System.out.println("====================");//lambda表达式还是可以进一步简化的.list.stream().forEach(s->System.out.println(s));}
}
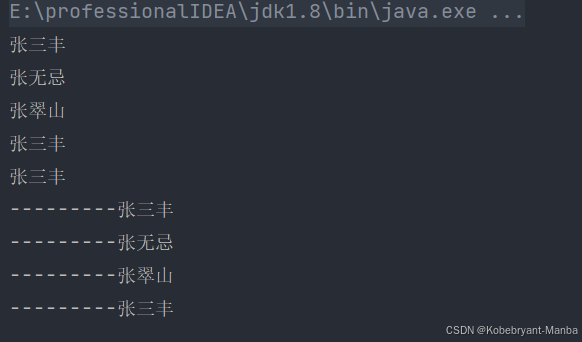
结果:
张三丰
张无忌
张翠山
王二麻子
张良
谢广坤
====================
张三丰
张无忌
张翠山
王二麻子
张良
谢广坤
====================
张三丰
张无忌
张翠山
王二麻子
张良
谢广坤
6Process finished with exit code 0收集操作:
// toList和toSet方法演示
public class MyStream7 {public static void main(String[] args) {ArrayList<Integer> list1 = new ArrayList<>();for (int i = 1; i <= 10; i++) {list1.add(i);}list1.add(10);list1.add(10);list1.add(10);list1.add(10);list1.add(10);//filter负责过滤数据的.//collect负责收集数据.//获取流中剩余的数据,但是他不负责创建容器,也不负责把数据添加到容器中.//Collectors.toList() : 在底层会创建一个List集合.并把所有的数据添加到List集合中.List<Integer> list = list1.stream().filter(number -> number % 2 == 0).collect(Collectors.toList());System.out.println(list);Set<Integer> set = list1.stream().filter(number -> number % 2 == 0).collect(Collectors.toSet());System.out.println(set);}
}
//结果
[2, 4, 6, 8, 10, 10, 10, 10, 10, 10]
[2, 4, 6, 8, 10]
有难度例子:
因为本身给的是key和value一起,所以需要先切割(,而且因为切割得到的还是字符串,转成数字),看最下面那个map操作即可
/**Stream流的收集方法 toMap方法演示创建一个ArrayList集合,并添加以下字符串。字符串中前面是姓名,后面是年龄"zhangsan,23""lisi,24""wangwu,25"保留年龄大于等于24岁的人,并将结果收集到Map集合中,姓名为键,年龄为值*/
public class MyStream8 {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();//map不能有相同的keylist.add("zhangsan,23");list.add("lisi,24");list.add("wangwu,25");
//测试是否这样做正确list.stream().filter(s -> {String[] split = s.split(",");int age = Integer.parseInt(split[1]);return age >= 24;//必须要有返回值 这是过滤条件 并不是只返回age值给stream}).forEach(System.out::println);System.out.println("====================");//需要加s->xx,先传进来list.stream().filter(s -> {String[] split = s.split(",");int age = Integer.parseInt(split[1]);return age >= 24;}).forEach(s-> System.out.println(s));System.out.println("====================");Map<String, Integer> map = list.stream().filter(s -> {String[] split = s.split(",");int age = Integer.parseInt(split[1]);return age >= 24;}// collect方法只能获取到流中剩余的每一个数据.//在底层不能创建容器,也不能把数据添加到容器当中//Collectors.toMap 创建一个map集合并将数据添加到集合当中// s 依次表示流中的每一个数据//第一个lambda表达式就是如何获取到Map中的键//第二个lambda表达式就是如何获取Map中的值).collect(Collectors.toMap(s -> s.split(",")[0],s -> Integer.parseInt(s.split(",")[1]) ));System.out.println(map);}
lisi,24
wangwu,25
====================
lisi,24
wangwu,25
====================
{lisi=24, wangwu=25}流操作本身不会创建容器或将数据添加到容器中。如果你需要将流的结果存入某个容器中,必须使用诸如 collect 这样的终端操作。
//在底层不能创建容器,也不能把数据添加到容器当中:
在流操作中,Stream 本身是不会直接创建或修改底层集合的。也就是说,Stream 的中间操作(如 filter、map 等)不会像传统的循环那样直接往一个集合里添加数据。流的设计哲学是惰性求值和不可变性,所有中间操作只是定义了对数据的处理方式,只有在执行终端操作(如 collect、forEach 等)时,流中的数据才会被实际处理或收集。
更具体的说明:
-
流的中间操作不创建或修改集合:
- 当你执行诸如
filter()、map()、sorted()等中间操作时,流只是在逻辑上“准备”好这些操作,但并不实际执行,也不会修改或创建集合。 - 这些中间操作都是惰性求值的,只有当终端操作(如
collect()或forEach())被调用时,流才会被消耗。
- 当你执行诸如
-
终端操作决定了数据的去向:
- 比如,
collect(Collectors.toList())或collect(Collectors.toCollection(ArrayList::new))是终端操作,它们会在流的末端实际执行,并将流中的数据收集到某个容器中。 - 在此之前,流不会修改任何已有的容器,也不会创建新的容器。流的数据是不可变的。
- 比如,
-
底层不能创建或修改容器:
- 这意味着流的运算是在已有的数据上进行处理,但不会通过流的中间操作来创建新的集合,除非你明确通过终端操作(如
collect)来收集结果。 - 如果你希望将流的结果放入某个集合中,需要通过
collect()或类似的操作来实现。
- 这意味着流的运算是在已有的数据上进行处理,但不会通过流的中间操作来创建新的集合,除非你明确通过终端操作(如
实操:Java之Stream流及方法引用的详细解析二-CSDN博客
interface Printable {void printString(String s);
}public class PrintableDemo {public static void main(String[] args) {//在主方法中调用usePrintable方法
// usePrintable((String s) -> {
// System.out.println(s);
// });//Lambda简化写法usePrintable(s -> System.out.println(s));//方法引用usePrintable(System.out::println);}private static void usePrintable(Printable p) {p.printString("爱生活爱Java");}
}
爱生活爱Java
爱生活爱Java
不用重写接口方法吗
在 Java 中,使用 Lambda 表达式 或 方法引用 的时候,你不需要显式地重写函数式接口中的方法。这是因为 Lambda 表达式 和 方法引用 已经隐式地实现了函数式接口中的抽象方法。
函数式接口的特点:
- 函数式接口 是指仅有一个抽象方法的接口,通常会用
@FunctionalInterface注解来标识(虽然不加注解也是函数式接口)。 - 函数式接口的最大优势就是可以通过 Lambda 表达式 或 方法引用 来简化实现。
在你的例子中,Printable 是一个函数式接口,它只有一个抽象方法 printString(String s),所以你可以使用 Lambda 表达式或方法引用来简化其实现。
为什么不需要重写接口方法?
通常,在传统的实现方式中,类需要通过 implements 关键字来实现接口,并且显式地重写接口中的方法,如下所示:
public class MyPrintable implements Printable {
@Override
public void printString(String s) { System.out.println(s); } }
然后你会通过创建类的实例来使用该实现:
Printable p = new MyPrintable();
p.printString("爱生活爱Java");
然而,Lambda 表达式 和 方法引用 本质上已经是对接口中唯一抽象方法的实现,Java 编译器能够根据上下文推断出该方法的签名,因此不需要显式创建类或重写方法。
例如:
usePrintable(s -> System.out.println(s)); // 使用 Lambda 表达式
在这个例子中,s -> System.out.println(s) 是 Printable 接口的 printString(String s) 方法的实现,Java 编译器会自动将这个 Lambda 表达式理解为 printString 方法的实现。
再例如,使用方法引用:
usePrintable(System.out::println); // 使用方法引用
System.out::println 是对 System.out.println(String) 方法的引用,而这个方法的签名与 printString(String s) 完全匹配,因此编译器会自动将其作为 printString 方法的实现。