JDBC数据库连接技术
基础篇
一、引言
1.1 数据的存储
我们在开发Java程序时,数据都是存储在内存中,属于临时存储,当程序停止或重启时,内存中的数据就丢失了!我们为了解决数据的长期存储问题,有如下解决方案:
- 数据通过I/O流技术,存储在本地磁盘中,解决了持久化问题,但是没有结构和逻辑,不方便管理和维护。
- 通过关系型数据库,将数据按照特定的格式交由数据库管理系统维护。关系型数据库是通过库和表分隔不同的数据,表中数据存储的方式是行和列,区分相同格式不同值的数据。
| 数据库存储数据 |
|---|
 |
1.2 数据的操作
数据存储在数据库,仅仅解决了我们数据存储的问题,但当我们程序运行时,需要读取数据,以及对数据做增删改的操作,那么我们如何通过Java程序对数据库中的数据做增删改查呢?
| Java程序读取数据库 |
|---|
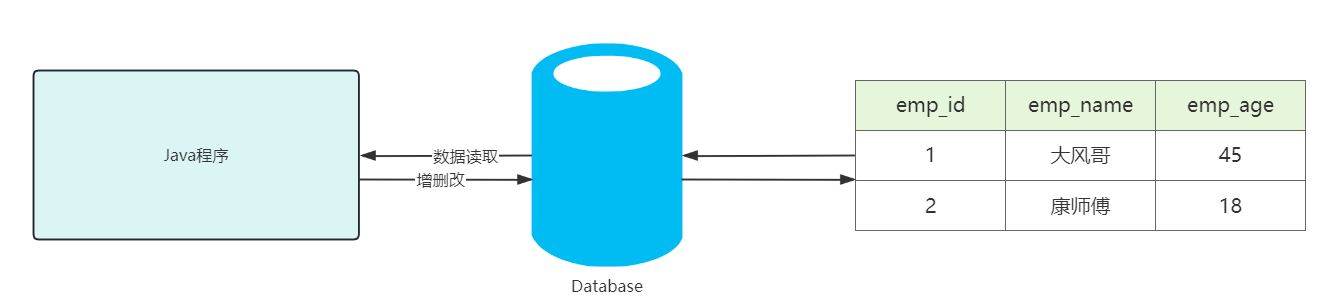 |
二、JDBC
2.1 JDBC的概念
- JDBC:Java Database Connectivity,意为Java数据库连接。
- JDBC是Java提供的一组独立于任何数据库管理系统的API。
- Java提供接口规范,由各个数据库厂商提供接口的实现,厂商提供的实现类封装成jar文件,也就是我们俗称的数据库驱动jar包。
- 学习JDBC,充分体现了面向接口编程的好处,程序员只关心标准和规范,而无需关注实现过程。
| JDBC简单执行过程 |
|---|
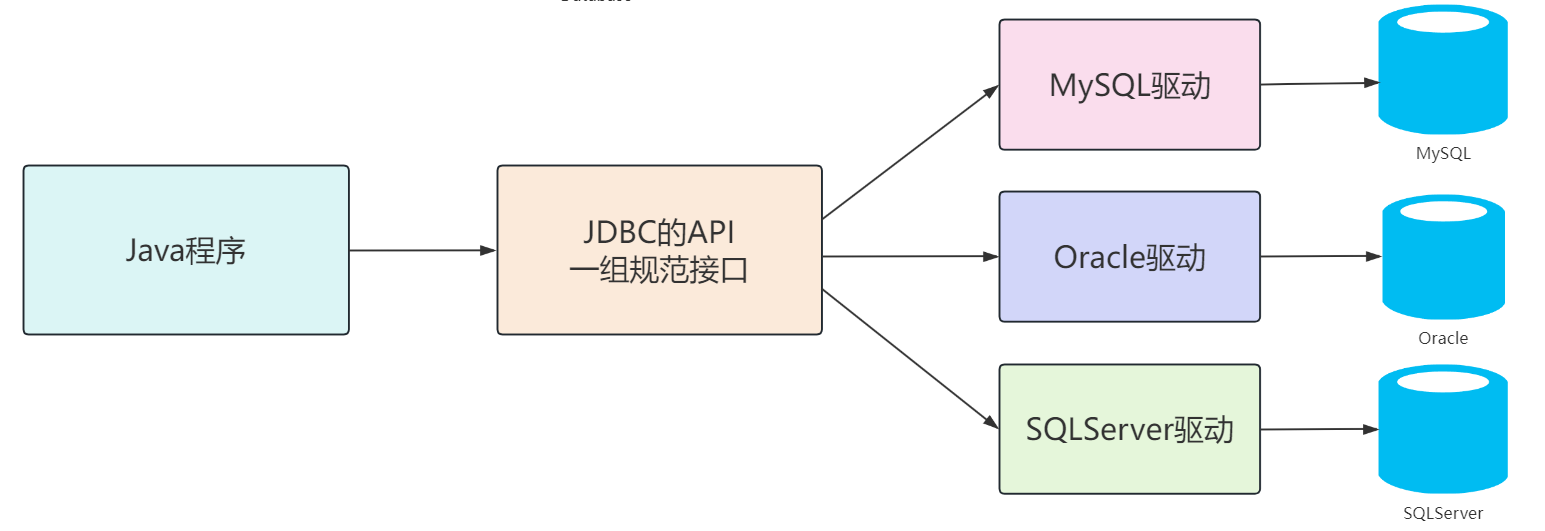 |
2.2 JDBC的核心组成
- 接口规范:
- 为了项目代码的可移植性,可维护性,SUN公司从最初就制定了Java程序连接各种数据库的统一接口规范。这样的话,不管是连接哪一种DBMS软件,Java代码可以保持一致性。
- 接口存储在java.sql和javax.sql包下。
- 实现规范:
- 因为各个数据库厂商的DBMS软件各有不同,那么各自的内部如何通过SQL实现增、删、改、查等操作管理数据,只有这个数据库厂商自己更清楚,因此把接口规范的实现交给各个数据库厂商自己实现。
- 厂商将实现内容和过程封装成jar文件,我们程序员只需要将jar文件引入到项目中集成即可,就可以开发调用实现过程操作数据库了。
三、JDBC快速入门
3.1 JDBC搭建步骤
- 准备数据库。
- 官网下载数据库连接驱动jar包。https://downloads.mysql.com/archives/c-j/
- 创建Java项目,在项目下创建lib文件夹,将下载的驱动jar包复制到文件夹里。
- 选中lib文件夹右键->Add as Library,与项目集成。
- 编写代码
3.2 代码实现
3.2.1 数据库
CREATE DATABASE atguigu;use atguigu;create table t_emp
(emp_id int auto_increment comment '员工编号' primary key,emp_name varchar(100) not null comment '员工姓名',emp_salary double(10, 5) not null comment '员工薪资',emp_age int not null comment '员工年龄'
);insert into t_emp (emp_name,emp_salary,emp_age)
values ('andy', 777.77, 32),('大风哥', 666.66, 41),('康师傅',111, 23),('Gavin',123, 26),('小鱼儿', 123, 28);
3.2.2 Java代码
package com.atguigu;import java.sql.*;public class JdbcQuick {public static void main(String[] args) throws ClassNotFoundException, SQLException {//1.注册驱动Class.forName("com.mysql.cj.jdbc.Driver");//2.获取数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/atguigu", "root", "atguigu");//3.创建Statement对象PreparedStatement preparedStatement = connection.prepareStatement("select emp_id,emp_name,emp_salary,emp_age from t_emp");//4.编写SQL语句并执行,获取结果ResultSet resultSet = preparedStatement.executeQuery();//5.处理结果while (resultSet.next()) {int empId = resultSet.getInt("emp_id");String empName = resultSet.getString("emp_name");String empSalary = resultSet.getString("emp_salary");int empAge = resultSet.getInt("emp_age");System.out.println(empId + "\t" + empName + "\t" + empSalary + "\t" + empAge);}//6.释放资源(先开后关原则)resultSet.close();preparedStatement.close();connection.close();}
}3.3 步骤总结
- 注册驱动【依赖的驱动类,进行安装】
- 获取连接【Connection建立连接】
- 创建发送SQL语句对象【Connection创建发送SQL语句的Statement】
- 发送SQL语句,并获取返回结果【Statement 发送sql语句到数据库并且取得返回结果】
- 结果集解析【结果集解析,将查询结果解析出来】
- 资源关闭【释放ResultSet、Statement 、Connection】
四、核心API理解
4.1 注册驱动
-
Class.forName("com.mysql.cj.jdbc.Driver"); -
在 Java 中,当使用 JDBC(Java Database Connectivity)连接数据库时,需要加载数据库特定的驱动程序,以便与数据库进行通信。加载驱动程序的目的是为了注册驱动程序,使得 JDBC API 能够识别并与特定的数据库进行交互。
-
从JDK6开始,不再需要显式地调用
Class.forName()来加载 JDBC 驱动程序,只要在类路径中集成了对应的jar文件,会自动在初始化时注册驱动程序。
4.2 Connection
- Connection接口是JDBC API的重要接口,用于建立与数据库的通信通道。换而言之,Connection对象不为空,则代表一次数据库连接。
- 在建立连接时,需要指定数据库URL、用户名、密码参数。
- URL:jdbc:mysql://localhost:3306/atguigu
- jdbc:mysql://IP地址:端口号/数据库名称?参数键值对1&参数键值对2
- URL:jdbc:mysql://localhost:3306/atguigu
Connection接口还负责管理事务,Connection接口提供了commit和rollback方法,用于提交事务和回滚事务。- 可以创建
Statement对象,用于执行 SQL 语句并与数据库进行交互。 - 在使用JDBC技术时,必须要先获取Connection对象,在使用完毕后,要释放资源,避免资源占用浪费及泄漏。
4.3 Statement
Statement接口用于执行 SQL 语句并与数据库进行交互。它是 JDBC API 中的一个重要接口。通过Statement对象,可以向数据库发送 SQL 语句并获取执行结果。- 结果可以是一个或多个结果。
- 增删改:受影响行数单个结果。
- 查询:单行单列、多行多列、单行多列等结果。
- 但是
Statement接口在执行SQL语句时,会产生SQL注入攻击问题:- 当使用
Statement执行动态构建的 SQL 查询时,往往需要将查询条件与 SQL 语句拼接在一起,直接将参数和SQL语句一并生成,让SQL的查询条件始终为true得到结果。
- 当使用
4.4 PreparedStatement
PreparedStatement是Statement接口的子接口,用于执行预编译的 SQL 查询,作用如下:- 预编译SQL语句:在创建PreparedStatement时,就会预编译SQL语句,也就是SQL语句已经固定。
- 防止SQL注入:
PreparedStatement支持参数化查询,将数据作为参数传递到SQL语句中,采用?占位符的方式,将传入的参数用一对单引号包裹起来’',无论传递什么都作为值。有效防止传入关键字或值导致SQL注入问题。 - 性能提升:PreparedStatement是预编译SQL语句,同一SQL语句多次执行的情况下,可以复用,不必每次重新编译和解析。
- 后续的学习我们都是基于PreparedStatement进行实现,更安全、效率更高!
4.5 ResultSet
ResultSet是 JDBC API 中的一个接口,用于表示从数据库中执行查询语句所返回的结果集。它提供了一种用于遍历和访问查询结果的方式。- 遍历结果:ResultSet可以使用
next()方法将游标移动到结果集的下一行,逐行遍历数据库查询的结果,返回值为boolean类型,true代表有下一行结果,false则代表没有。 - 获取单列结果:可以通过getXxx的方法获取单列的数据,该方法为重载方法,支持索引和列名进行获取。
五、基于PreparedStatement实现CRUD
5.1 查询单行单列
@Testpublic void querySingleRowAndColumn() throws SQLException {//1.注册驱动
// Class.forName("com.mysql.cj.jdbc.Driver");//2.获取数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/atguigu", "root","atguigu");//3.创建PreparedStatement对象,并预编译SQL语句PreparedStatement preparedStatement = connection.prepareStatement("select count(*) as count from t_emp");//4.执行SQL语句,获取结果ResultSet resultSet = preparedStatement.executeQuery();//5.处理结果while (resultSet.next()){int count = resultSet.getInt("count");System.out.println("count = " + count);}//6.释放资源(先开后关原则)resultSet.close();preparedStatement.close();connection.close();}
5.2 查询单行多列
@Testpublic void querySingleRow() throws SQLException {//1.注册驱动
// Class.forName("com.mysql.cj.jdbc.Driver");//2.获取数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/atguigu","root","atguigu");//3.创建PreparedStatement对象,并预编译SQL语句,使用?占位符PreparedStatement preparedStatement = connection.prepareStatement("select emp_id,emp_name,emp_salary,emp_age from t_emp where emp_id = ?");//4.为占位符赋值,索引从1开始,执行SQL语句,获取结果preparedStatement.setInt(1,1);ResultSet resultSet = preparedStatement.executeQuery();//5.处理结果while (resultSet.next()){int empId = resultSet.getInt("emp_id");String empName = resultSet.getString("emp_name");String empSalary = resultSet.getString("emp_salary");int empAge = resultSet.getInt("emp_age");System.out.println(empId+"\t"+empName+"\t"+empSalary+"\t"+empAge);}//6.释放资源(先开后关原则)resultSet.close();preparedStatement.close();connection.close();}
5.3 查询多行多列
@Testpublic void queryMoreRow() throws SQLException {//1.注册驱动
// Class.forName("com.mysql.cj.jdbc.Driver");//2.获取数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/atguigu","root","atguigu");//3.创建Statement对象PreparedStatement preparedStatement = connection.prepareStatement("select emp_id,emp_name,emp_salary,emp_age from t_emp");//4.编写SQL语句并执行,获取结果ResultSet resultSet = preparedStatement.executeQuery();//5.处理结果while (resultSet.next()){int empId = resultSet.getInt("emp_id");String empName = resultSet.getString("emp_name");String empSalary = resultSet.getString("emp_salary");int empAge = resultSet.getInt("emp_age");System.out.println(empId+"\t"+empName+"\t"+empSalary+"\t"+empAge);}//6.释放资源(先开后关原则)resultSet.close();preparedStatement.close();connection.close();}
5.4 新增
@Testpublic void insert() throws SQLException {//1.注册驱动
// Class.forName("com.mysql.cj.jdbc.Driver");//2.获取数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/atguigu","root", "atguigu");//3.创建Statement对象PreparedStatement preparedStatement = connection.prepareStatement("insert into t_emp (emp_name,emp_salary,emp_age)values (?, ?,?)");//4.为占位符赋值,索引从1开始,编写SQL语句并执行,获取结果preparedStatement.setString(1,"rose");preparedStatement.setDouble(2,666.66);preparedStatement.setDouble(3,28);int result = preparedStatement.executeUpdate();//5.处理结果if(result>0){System.out.println("添加成功");}else{System.out.println("添加失败");}//6.释放资源(先开后关原则)preparedStatement.close();connection.close();}
5.5 修改
@Testpublic void update() throws SQLException {//1.注册驱动
// Class.forName("com.mysql.cj.jdbc.Driver");//2.获取数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/atguigu", "root", "atguigu");//3.创建Statement对象PreparedStatement preparedStatement = connection.prepareStatement("update t_emp set emp_salary = ? where emp_id = ?");//4.为占位符赋值,索引从1开始,编写SQL语句并执行,获取结果preparedStatement.setDouble(1,888.88);preparedStatement.setDouble(2,8);int result = preparedStatement.executeUpdate();//5.处理结果if(result>0){System.out.println("修改成功");}else{System.out.println("修改失败");}//6.释放资源(先开后关原则)preparedStatement.close();connection.close();}
5.6 删除
@Testpublic void delete() throws SQLException {//1.注册驱动
// Class.forName("com.mysql.cj.jdbc.Driver");//2.获取数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/atguigu", "root", "atguigu");//3.创建Statement对象PreparedStatement preparedStatement = connection.prepareStatement("delete from t_emp where emp_id = ?");//4.为占位符赋值,索引从1开始,编写SQL语句并执行,获取结果preparedStatement.setInt(1,8);int result = preparedStatement.executeUpdate();//5.处理结果if(result>0){System.out.println("删除成功");}else{System.out.println("删除失败");}//6.释放资源(先开后关原则)preparedStatement.close();connection.close();}
六、常见问题
6.1 资源的管理
在使用JDBC的相关资源时,比如Connection、PreparedStatement、ResultSet,使用完毕后,要及时关闭这些资源以释放数据库服务器资源和避免内存泄漏是很重要的。
6.2 SQL语句问题
java.sql.SQLSyntaxErrorException:SQL语句错误异常,一般有几种可能:
- SQL语句有错误,检查SQL语句!建议SQL语句在SQL工具中测试后再复制到Java程序中!
- 连接数据库的URL中,数据库名称编写错误,也会报该异常!
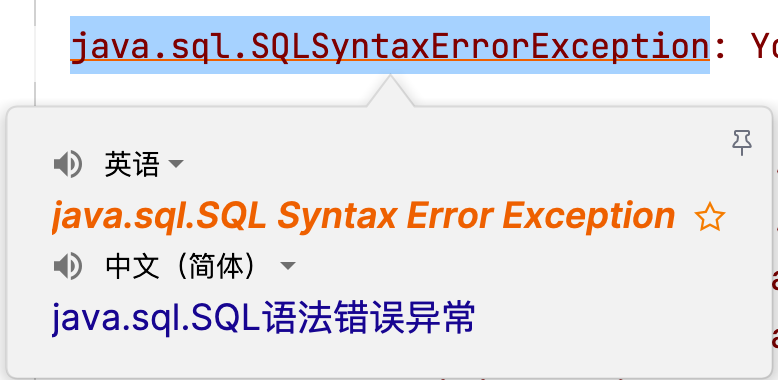
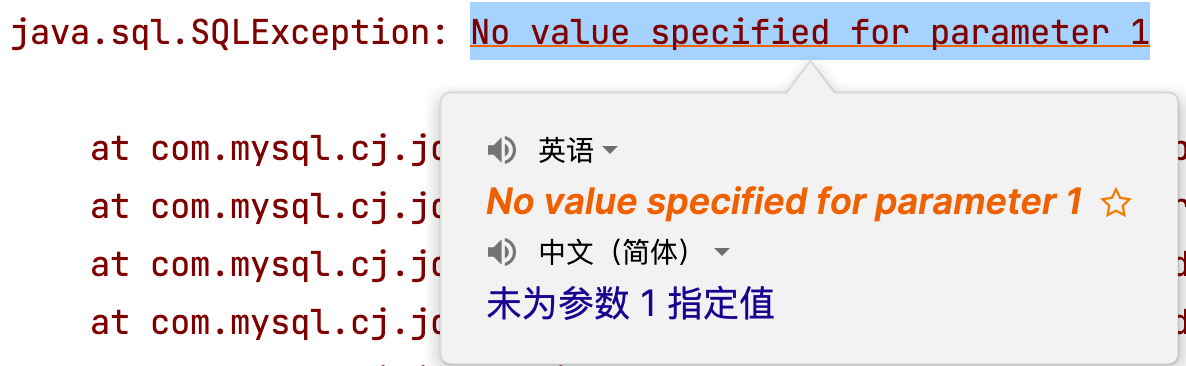
6.3 SQL语句未设置参数问题
java.sql.SQLException:No value specified for parameter 1
在使用预编译SQL语句时,如果有?占位符,要为每一个占位符赋值,否则报该错误!
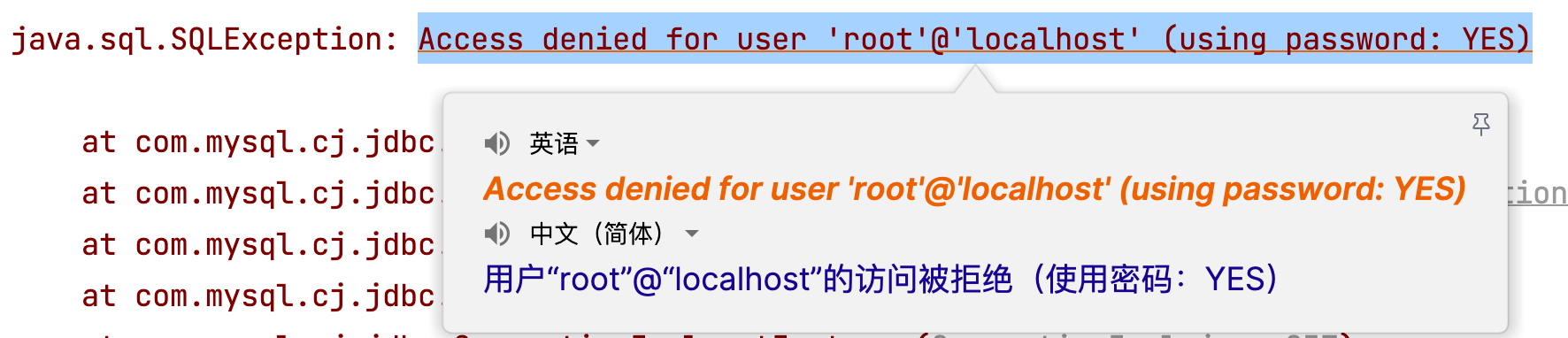
6.4 用户名或密码错误问题
连接数据库时,如果用户名或密码输入错误,也会报SQLException,容易混淆!所以一定要看清楚异常后面的原因描述
6.5 通信异常
在连接数据库的URL中,如果IP或端口写错了,会报如下异常:
com.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failure

进阶篇
七、JDBC扩展
7.1 实体类和ORM
- 在使用JDBC操作数据库时,我们会发现数据都是零散的,明明在数据库中是一行完整的数据,到了Java中变成了一个一个的变量,不利于维护和管理。而我们Java是面向对象的,一个表对应的是一个类,一行数据就对应的是Java中的一个对象,一个列对应的是对象的属性,所以我们要把数据存储在一个载体里,这个载体就是实体类!
- ORM(Object Relational Mapping)思想,对象到关系数据库的映射,作用是在编程中,把面向对象的概念跟数据库中表的概念对应起来,以面向对象的角度操作数据库中的数据,即一张表对应一个类,一行数据对应一个对象,一个列对应一个属性!
- 当下JDBC中这种过程我们称其为手动ORM。后续我们也会学习ORM框架,比如MyBatis、JPA等。
package com.atguigu.pojo;
//类名和数据库名对应,但是表名一般缩写,类名要全写!
public class Employee {private Integer empId;//emp_id = empId 数据库中列名用下划线分隔,属性名用驼峰!private String empName;//emp_name = empNameprivate Double empSalary;//emp_salary = empSalaryprivate Integer empAge;//emp_age = empAge//省略get、set、无参、有参、toString方法。
}
封装代码:
@Testpublic void querySingleRow() throws SQLException {//1.注册驱动
// Class.forName("com.mysql.cj.jdbc.Driver");//2.获取数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/atguigu", "root","atguigu");//3.创建PreparedStatement对象,并预编译SQL语句,使用?占位符PreparedStatement preparedStatement = connection.prepareStatement("select emp_id,emp_name,emp_salary,emp_age from t_emp where emp_id = ?");//4.为占位符赋值,索引从1开始,执行SQL语句,获取结果preparedStatement.setInt(1, 1);ResultSet resultSet = preparedStatement.executeQuery();//预先创建实体类变量Employee employee = null;//5.处理结果while (resultSet.next()) {int empId = resultSet.getInt("emp_id");String empName = resultSet.getString("emp_name");Double empSalary = Double.valueOf(resultSet.getString("emp_salary"));int empAge = resultSet.getInt("emp_age");//当结果集中有数据,再进行对象的创建employee = new Employee(empId,empName,empSalary,empAge);}System.out.println("employee = " + employee);//6.释放资源(先开后关原则)resultSet.close();preparedStatement.close();connection.close();}
7.2 主键回显
-
在数据中,执行新增操作时,主键列为自动增长,可以在表中直观的看到,但是在Java程序中,我们执行完新增后,只能得到受影响行数,无法得知当前新增数据的主键值。在Java程序中获取数据库中插入新数据后的主键值,并赋值给Java对象,此操作为主键回显。
-
代码实现:
-
@Testpublic void testReturnPK() throws SQLException {//1.注册驱动 // Class.forName("com.mysql.cj.jdbc.Driver");//2.获取数据库连接Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/atguigu", "root", "atguigu");//3.创建preparedStatement对象,传入需要主键回显参数Statement.RETURN_GENERATED_KEYSPreparedStatement preparedStatement = connection.prepareStatement("insert into t_emp (emp_name, emp_salary, emp_age)values (?, ?,?)",Statement.RETURN_GENERATED_KEYS);//4.编写SQL语句并执行,获取结果Employee employee = new Employee(null,"rose",666.66,28);preparedStatement.setString(1,employee.getEmpName());preparedStatement.setDouble(2,employee.getEmpSalary());preparedStatement.setDouble(3,employee.getEmpAge());int result = preparedStatement.executeUpdate();//5.处理结果if(result>0){System.out.println("添加成功");}else{System.out.println("添加失败");}//6.获取生成的主键列值,返回的是resultSet,在结果集中获取主键列值ResultSet resultSet = preparedStatement.getGeneratedKeys();if (resultSet.next()){int empId = resultSet.getInt(1);employee.setEmpId(empId);}System.out.println(employee.toString());//7.释放资源(先开后关原则)resultSet.close();preparedStatement.close();connection.close();}
-
7.3 批量操作
-
插入多条数据时,一条一条发送给数据库执行,效率低下!
-
通过批量操作,可以提升多次操作效率!
-
代码实现:
-
@Testpublic void testBatch() throws Exception {//1.注册驱动 // Class.forName("com.mysql.cj.jdbc.Driver");//2.获取连接Connection connection = DriverManager.getConnection("jdbc:mysql:///atguigu?rewriteBatchedStatements=true", "root", "atguigu");//3.编写SQL语句/*注意:1、必须在连接数据库的URL后面追加?rewriteBatchedStatements=true,允许批量操作2、新增SQL必须用values。且语句最后不要追加;结束3、调用addBatch()方法,将SQL语句进行批量添加操作4、统一执行批量操作,调用executeBatch()*/String sql = "insert into t_emp (emp_name,emp_salary,emp_age) values (?,?,?)";//4.创建预编译的PreparedStatement,传入SQL语句PreparedStatement preparedStatement = connection.prepareStatement(sql);//获取当前行代码执行的时间。毫秒值long start = System.currentTimeMillis();for(int i = 0;i<10000;i++){//5.为占位符赋值preparedStatement.setString(1, "marry"+i);preparedStatement.setDouble(2, 100.0+i);preparedStatement.setInt(3, 20+i);preparedStatement.addBatch();}//执行批量操作preparedStatement.executeBatch();long end = System.currentTimeMillis();System.out.println("消耗时间:"+(end - start));preparedStatement.close();connection.close();}
-
八、连接池
8.1 现有问题
- 每次操作数据库都要获取新连接,使用完毕后就close释放,频繁的创建和销毁造成资源浪费。
- 连接的数量无法把控,对服务器来说压力巨大。
8.2 连接池
连接池就是数据库连接对象的缓冲区,通过配置,由连接池负责创建连接、管理连接、释放连接等操作。
预先创建数据库连接放入连接池,用户在请求时,通过池直接获取连接,使用完毕后,将连接放回池中,避免了频繁的创建和销毁,同时解决了创建的效率。
当池中无连接可用,且未达到上限时,连接池会新建连接。
池中连接达到上限,用户请求会等待,可以设置超时时间。
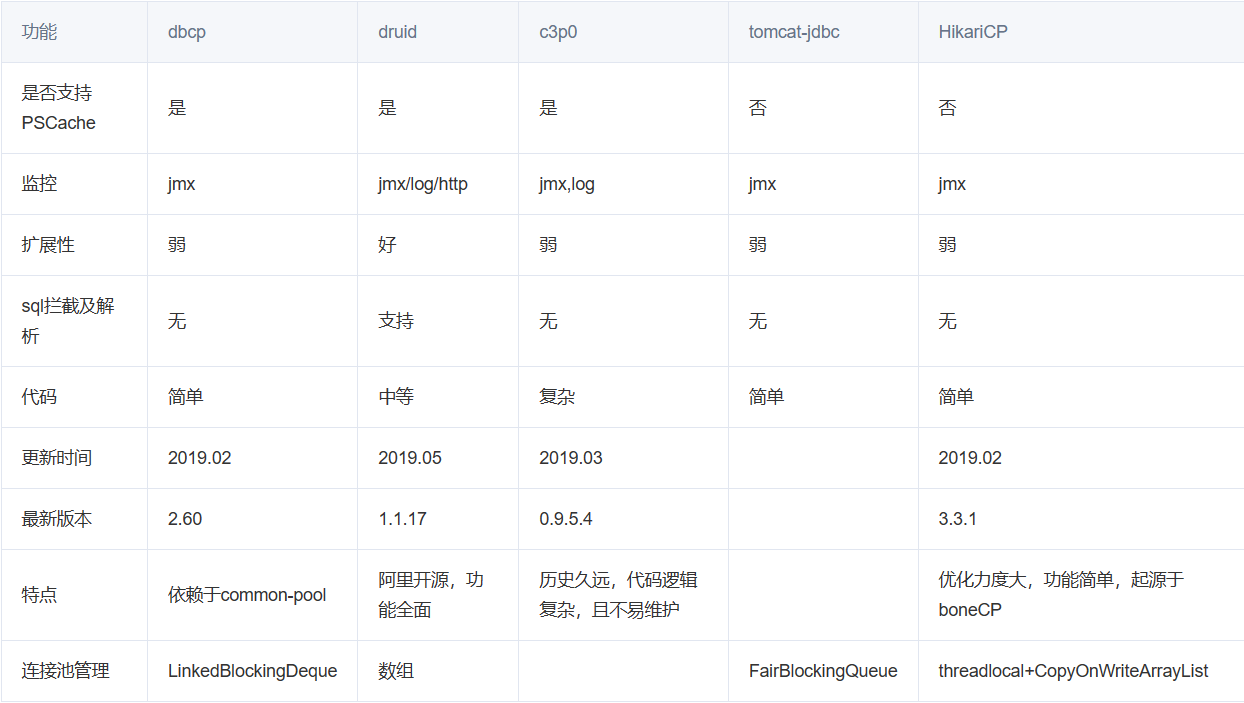
8.3 常见连接池
JDBC 的数据库连接池使用 javax.sql.DataSource接口进行规范,所有的第三方连接池都实现此接口,自行添加具体实现!也就是说,所有连接池获取连接的和回收连接方法都一样,不同的只有性能和扩展功能!
- DBCP 是Apache提供的数据库连接池,速度相对C3P0较快,但自身存在一些BUG。
- C3P0 是一个开源组织提供的一个数据库连接池,速度相对较慢,稳定性还可以。
- Proxool 是sourceforge下的一个开源项目数据库连接池,有监控连接池状态的功能, 稳定性较c3p0差一点
- Druid 是阿里提供的数据库连接池,是集DBCP 、C3P0 、Proxool 优点于一身的数据库连接池,性能、扩展性、易用性都更好,功能丰富。
- Hikari(ひかり[shi ga li]) 取自日语,是光的意思,是SpringBoot2.x之后内置的一款连接池,基于 BoneCP (已经放弃维护,推荐该连接池)做了不少的改进和优化,口号是快速、简单、可靠。
| 主流连接池的功能对比 |
|---|
 |
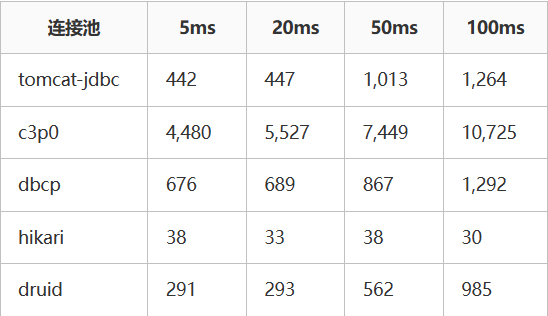
| mock性能数据(单位:ms) |
|---|
 |
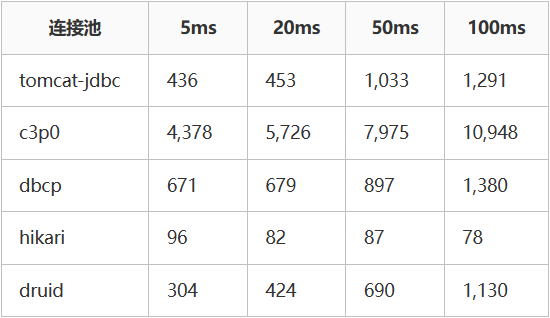
| mysql性能数据 (单位:ms) |
|---|
 |
8.4 Druid连接池使用
-
使用步骤:
- 引入jar包。
- 编码。
-
代码实现:
-
硬编码方式(了解):
-
@Testpublic void testHardCodeDruid() throws SQLException {/*硬编码:将连接池的配置信息和Java代码耦合在一起。1、创建DruidDataSource连接池对象。2、设置连接池的配置信息【必须 | 非必须】3、通过连接池获取连接对象4、回收连接【不是释放连接,而是将连接归还给连接池,给其他线程进行复用】*///1.创建DruidDataSource连接池对象。DruidDataSource druidDataSource = new DruidDataSource();//2.设置连接池的配置信息【必须 | 非必须】//2.1 必须设置的配置druidDataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");druidDataSource.setUrl("jdbc:mysql:///atguigu");druidDataSource.setUsername("root");druidDataSource.setPassword("atguigu");//2.2 非必须设置的配置druidDataSource.setInitialSize(10);druidDataSource.setMaxActive(20);//3.通过连接池获取连接对象Connection connection = druidDataSource.getConnection();System.out.println(connection);//基于connection进行CRUD//4.回收连接connection.close();}
-
-
软编码方式(推荐):
-
在项目目录下创建resources文件夹,标识该文件夹为资源目录,创建db.properties配置文件,将连接信息定义在该文件中。
-
# druid连接池需要的配置参数,key固定命名 driverClassName=com.mysql.cj.jdbc.Driver url=jdbc:mysql:///atguigu username=root password=atguigu initialSize=10 maxActive=20
-
-
Java代码:
-
@Testpublic void testResourcesDruid() throws Exception {//1.创建Properties集合,用于存储外部配置文件的key和value值。Properties properties = new Properties();//2.读取外部配置文件,获取输入流,加载到Properties集合里。InputStream inputStream = DruidTest.class.getClassLoader().getResourceAsStream("db.properties");properties.load(inputStream);//3.基于Properties集合构建DruidDataSource连接池DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);//4.通过连接池获取连接对象Connection connection = dataSource.getConnection();System.out.println(connection);//5.开发CRUD//6.回收连接connection.close();}
-
-
-
8.5 Druid其他配置【了解】
| 配置 | 缺省 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 如果没有配置,将会生成一个名字,格式是:”DataSource-” + System.identityHashCode(this) | |
| jdbcUrl | 连接数据库的url,不同数据库不一样。例如:mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/使用ConfigFilter | |
| driverClassName | 根据url自动识别 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下) | |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 有两个含义: 1)Destroy线程会检测连接的间隔时间2)testWhileIdle的判断依据,详细看testWhileIdle属性的说明 | |
| numTestsPerEvictionRun | 不再使用,一个DruidDataSource只支持一个EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 当数据库抛出一些不可恢复的异常时,抛弃连接 | |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall | |
| proxyFilters | 类型是List,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
8.6 HikariCP连接池使用
-
使用步骤:
-
引入jar包
-
硬编码方式:
-
@Test public void testHardCodeHikari() throws SQLException {/*硬编码:将连接池的配置信息和Java代码耦合在一起。1、创建HikariDataSource连接池对象2、设置连接池的配置信息【必须 | 非必须】3、通过连接池获取连接对象4、回收连接*///1.创建HikariDataSource连接池对象HikariDataSource hikariDataSource = new HikariDataSource();//2.设置连接池的配置信息【必须 | 非必须】//2.1必须设置的配置hikariDataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");hikariDataSource.setJdbcUrl("jdbc:mysql:///atguigu");hikariDataSource.setUsername("root");hikariDataSource.setPassword("atguigu");//2.2 非必须设置的配置hikariDataSource.setMinimumIdle(10);hikariDataSource.setMaximumPoolSize(20);//3.通过连接池获取连接对象Connection connection = hikariDataSource.getConnection();System.out.println(connection);//回收连接connection.close(); }
-
-
软编码方式:
-
在项目下创建resources/hikari.properties配置文件
-
driverClassName=com.mysql.cj.jdbc.Driver jdbcUrl=jdbc:mysql:///atguigu username=root password=atguigu minimumIdle=10 maximumPoolSize=20
-
-
编写代码:
-
@Testpublic void testResourcesHikari()throws Exception{//1.创建Properties集合,用于存储外部配置文件的key和value值。Properties properties = new Properties();//2.读取外部配置文件,获取输入流,加载到Properties集合里。InputStream inputStream = HikariTest.class.getClassLoader().getResourceAsStream("db.properties");properties.load(inputStream);// 3.创建Hikari连接池配置对象,将Properties集合传进去HikariConfig hikariConfig = new HikariConfig(properties);// 4. 基于Hikari配置对象,构建连接池HikariDataSource hikariDataSource = new HikariDataSource(hikariConfig);// 5. 获取连接Connection connection = hikariDataSource.getConnection();System.out.println("connection = " + connection);//6.回收连接connection.close();} }
-
-
-
8.7 HikariCP其他配置【了解】
| 属性 | 默认值 | 说明 |
|---|---|---|
| isAutoCommit | true | 自动提交从池中返回的连接 |
| connectionTimeout | 30000 | 等待来自池的连接的最大毫秒数 |
| maxLifetime | 1800000 | 池中连接最长生命周期如果不等于0且小于30秒则会被重置回30分钟 |
| minimumIdle | 10 | 池中维护的最小空闲连接数 minIdle<0或者minIdle>maxPoolSize,则被重置为maxPoolSize |
| maximumPoolSize | 10 | 池中最大连接数,包括闲置和使用中的连接 |
| metricRegistry | null | 连接池的用户定义名称,主要出现在日志记录和JMX管理控制台中以识别池和池配置 |
| healthCheckRegistry | null | 报告当前健康信息 |
| poolName | HikariPool-1 | 连接池的用户定义名称,主要出现在日志记录和JMX管理控制台中以识别池和池配置 |
| idleTimeout | 是允许连接在连接池中空闲的最长时间 |
高级篇
九、JDBC优化及工具类封装
9.1 现有问题
我们在使用JDBC的过程中,发现部分代码存在冗余的问题:
- 创建连接池。
- 获取连接。
- 连接的回收。
9.2 JDBC工具类封装V1.0
-
resources/db.properties配置文件:
-
# druid连接池需要的配置参数,key固定命名 driverClassName=com.mysql.cj.jdbc.Driver username=root password=atguigu url=jdbc:mysql:///atguigu
-
-
工具类代码:
-
import com.alibaba.druid.pool.DruidDataSourceFactory;import javax.sql.DataSource; import java.sql.Connection; import java.sql.SQLException; import java.util.Properties; /** * JDBC工具类(V1.0): * 1、维护一个连接池对象。 * 2、对外提供在连接池中获取连接的方法 * 3、对外提供回收连接的方法 * 注意:工具类仅对外提供共性的功能代码,所以方法均为静态方法! */ public class JDBCTools {//创建连接池引用,因为要提供给当前项目全局使用,所以创建为静态的。private static DataSource dataSource;//在项目启动时,即创建连接池对象,赋值给dataSourcestatic{try {Properties properties = new Properties();InputStream inputStream = JDBCTools.getClass().getClassLoader().getSystemResourceAsStream("db.properties");properties.load(inputStream);dataSource = DruidDataSourceFactory.createDataSource(properties);} catch (Exception e) {e.printStackTrace();}}//对外提供获取连接的静态方法!public static Connection getConnection() throws SQLException {return ds.getConnection();}//对外提供回收连接的静态方法public static void release(Connection conn) throws SQLException {conn.close();//还给连接池} }
-
-
注意:此种封装方式,无法保证单个请求连接的线程,多次操作数据库时,连接是同一个,无法保证事务!
9.3 ThreadLocal
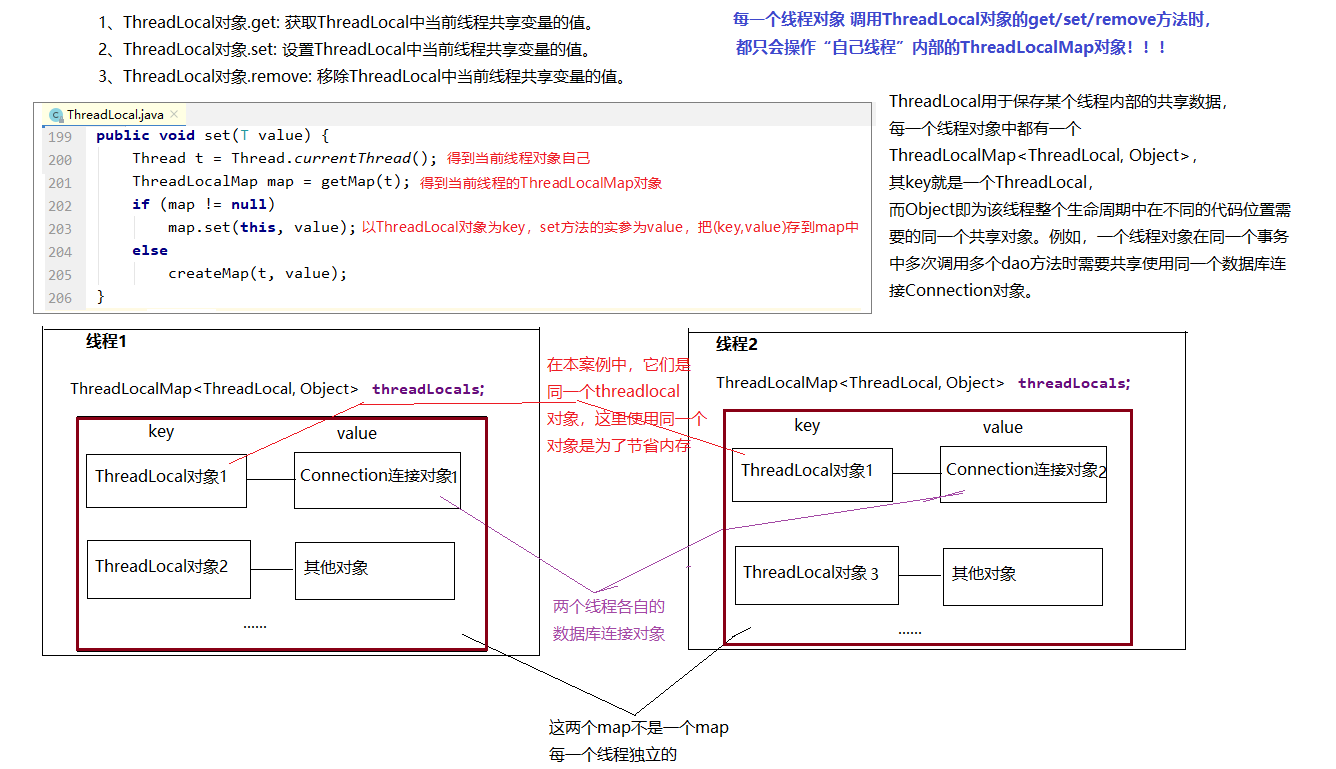
JDK 1.2的版本中就提供java.lang.ThreadLocal,为解决多线程程序的并发问题提供了一种新的思路。使用这个工具类可以很简洁地编写出优美的多线程程序。通常用来在在多线程中管理共享数据库连接、Session等。
ThreadLocal用于保存某个线程共享变量,原因是在Java中,每一个线程对象中都有一个ThreadLocalMap<ThreadLocal, Object>,其key就是一个ThreadLocal,而Object即为该线程的共享变量。
而这个map是通过ThreadLocal的set和get方法操作的。对于同一个static ThreadLocal,不同线程只能从中get,set,remove自己的变量,而不会影响其他线程的变量。
- 在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束。
- 线程间数据隔离。
- 进行事务操作,用于存储线程事务信息。
- 数据库连接,
Session会话管理。1、ThreadLocal对象.get: 获取ThreadLocal中当前线程共享变量的值。
2、ThreadLocal对象.set: 设置ThreadLocal中当前线程共享变量的值。
3、ThreadLocal对象.remove: 移除ThreadLocal中当前线程共享变量的值。
9.4 JDBC工具类封装V2.0
在V1.0的版本基础上,我们将连接对象放在每个线程的ThreadLocal中,保证从头到尾当前线程操作的是同一连接对象。
代码实现:
package com.atguigu.senior.util;import com.alibaba.druid.pool.DruidDataSourceFactory;import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
/*** JDBC工具类(V2.0):* 1、维护一个连接池对象、维护了一个线程绑定变量的ThreadLocal对象* 2、对外提供在ThreadLocal中获取连接的方法* 3、对外提供回收连接的方法,回收过程中,将要回收的连接从ThreadLocal中移除!* 注意:工具类仅对外提供共性的功能代码,所以方法均为静态方法!* 注意:使用ThreadLocal就是为了一个线程在多次数据库操作过程中,使用的是同一个连接!*/
public class JDBCUtilV2 {//创建连接池引用,因为要提供给当前项目的全局使用,所以创建为静态的。private static DataSource dataSource;private static ThreadLocal<Connection> threadLocal = new ThreadLocal<>();//在项目启动时,即创建连接池对象,赋值给dataSourcestatic {try {Properties properties = new Properties();InputStream inputStream = JDBCUtil.class.getClassLoader().getResourceAsStream("db.properties");properties.load(inputStream);dataSource = DruidDataSourceFactory.createDataSource(properties);} catch (Exception e) {throw new RuntimeException(e);}}//对外提供在连接池中获取连接的方法public static Connection getConnection(){try {//在ThreadLocal中获取Connection、Connection connection = threadLocal.get();//threadLocal里没有存储Connection,也就是第一次获取if (connection == null) {//在连接池中获取一个连接,存储在threadLocal里。connection = dataSource.getConnection();threadLocal.set(connection);}return connection;} catch (SQLException e) {throw new RuntimeException(e);}}//对外提供回收连接的方法public static void release(){try {Connection connection = threadLocal.get();if(connection!=null){//从threadLocal中移除当前已经存储的Connection对象threadLocal.remove();//如果开启了事务的手动提交,操作完毕后,归还给连接池之前,要将事务的自动提交改为trueconnection.setAutoCommit(true);//将Connection对象归还给连接池connection.close();}} catch (SQLException e) {throw new RuntimeException(e);}}}十、DAO封装及BaseDAO工具类
10.1 DAO概念
DAO:Data Access Object,数据访问对象。
Java是面向对象语言,数据在Java中通常以对象的形式存在。一张表对应一个实体类,一张表的操作对应一个DAO对象!
在Java操作数据库时,我们会将对同一张表的增删改查操作统一维护起来,维护的这个类就是DAO层。
DAO层只关注对数据库的操作,供业务层Service调用,将职责划分清楚!
10.1 BaseDAO概念
基本上每一个数据表都应该有一个对应的DAO接口及其实现类,发现对所有表的操作(增、删、改、查)代码重复度很高,所以可以抽取公共代码,给这些DAO的实现类可以抽取一个公共的父类,复用增删改查的基本操作,我们称为BaseDAO。
10.2 BaseDAO搭建
public abstract class BaseDAO {/*通用的增、删、改的方法String sql:sqlObject... args:给sql中的?设置的值列表,可以是0~n*/protected int update(String sql,Object... args) throws SQLException {
// 创建PreparedStatement对象,对sql预编译Connection connection = JDBCTools.getConnection();PreparedStatement ps = connection.prepareStatement(sql);//设置?占位符的值if(args != null && args.length>0){for(int i=0; i<args.length; i++) {ps.setObject(i+1,args[i]);//?的编号从1开始,不是从0开始,数组的下标是从0开始}}//执行sqlint len = ps.executeUpdate();ps.close();//这里检查下是否开启事务,开启不关闭连接,业务方法关闭!//connection.getAutoCommit()为false,不要在这里回收connection,由开启事务的地方回收//connection.getAutoCommit()为true,正常回收连接//没有开启事务的话,直接回收关闭即可!if (connection.getAutoCommit()) {//回收JDBCTools.release();}return len;}/*通用的查询多个Javabean对象的方法,例如:多个员工对象,多个部门对象等这里的clazz接收的是T类型的Class对象,如果查询员工信息,clazz代表Employee.class,如果查询部门信息,clazz代表Department.class,返回List<T> list*/protected <T> ArrayList<T> query(Class<T> clazz,String sql,Object... args) throws Exception {// 创建PreparedStatement对象,对sql预编译Connection connection = JDBCTools.getConnection();PreparedStatement ps = connection.prepareStatement(sql);//设置?的值if(args != null && args.length>0){for(int i=0; i<args.length; i++) {ps.setObject(i+1, args[i]);//?的编号从1开始,不是从0开始,数组的下标是从0开始}}ArrayList<T> list = new ArrayList<>();ResultSet res = ps.executeQuery();/*获取结果集的元数据对象。元数据对象中有该结果集一共有几列、列名称是什么等信息*/ResultSetMetaData metaData = res.getMetaData();int columnCount = metaData.getColumnCount();//获取结果集列数//遍历结果集ResultSet,把查询结果中的一条一条记录,变成一个一个T 对象,放到list中。while(res.next()){//循环一次代表有一行,代表有一个T对象T t = clazz.newInstance();//要求这个类型必须有公共的无参构造//把这条记录的每一个单元格的值取出来,设置到t对象对应的属性中。for(int i=1; i<=columnCount; i++){//for循环一次,代表取某一行的1个单元格的值Object value = res.getObject(i);//这个值应该是t对象的某个属性值//获取该属性对应的Field对象//String columnName = metaData.getColumnName(i);//获取第i列的字段名//这里再取别名可能没办法对应上String columnName = metaData.getColumnLabel(i);//获取第i列的字段名或字段的别名Field field = clazz.getDeclaredField(columnName);field.setAccessible(true);//这么做可以操作private的属性field.set(t,value);}list.add(t);}res.close();ps.close();//这里检查下是否开启事务,开启不关闭连接,业务方法关闭!//没有开启事务的话,直接回收关闭即可!if (connection.getAutoCommit()) {//回收JDBCTools.release();}return list;}protected <T> T queryBean(Class<T> clazz,String sql, Object... args) throws Exception {ArrayList<T> list = query(clazz, sql,args);if(list == null || list.size() == 0){return null;}return list.get(0);}
}
10.3 BaseDAO的应用
10.3.1 创建员工DAO接口
package com.atguigu.senior.dao;import com.atguigu.senior.pojo.Employee;import java.util.List;/*** EmployeeDao这个类对应的是t_emp这张表的增删改查的操作*/
public interface EmployeeDao {/*** 数据库对应的查询所有的操作* @return 表中所有的数据*/List<Employee> selectAll();/*** 数据库对应的根据empId查询单个员工数据操作* @param empId 主键列* @return 一个员工对象(一行数据)*/Employee selectByEmpId(Integer empId);/*** 数据库对应的新增一条员工数据* @param employee ORM思想中的一个员工对象* @return 受影响的行数*/int insert(Employee employee);/*** 数据库对应的修改一条员工数据* @param employee ORM思想中的一个员工对象* @return 受影响的行数*/int update(Employee employee);/*** 数据库对应的根据empId删除一条员工数据* @param empId 主键列* @return 受影响的行数*/int delete(Integer empId);
}10.3.2 创建员工DAO接口实现类
package com.atguigu.senior.dao.impl;import com.atguigu.senior.dao.BaseDAO;
import com.atguigu.senior.dao.EmployeeDao;
import com.atguigu.senior.pojo.Employee;import java.util.List;public class EmployeeDaoImpl extends BaseDAO implements EmployeeDao {@Overridepublic List<Employee> selectAll() {try {String sql = "SELECT emp_id empId,emp_name empName,emp_salary empSalary,emp_age empAge FROM t_emp";return executeQuery(Employee.class,sql,null);} catch (Exception e) {throw new RuntimeException(e);}}@Overridepublic Employee selectByEmpId(Integer empId) {try {String sql = "SELECT emp_id empId,emp_name empName,emp_salary empSalary,emp_age empAge FROM t_emp where emp_id = ?";return executeQueryBean(Employee.class,sql,empId);} catch (Exception e) {throw new RuntimeException(e);}}@Overridepublic int insert(Employee employee) {try {String sql = "INSERT INTO t_emp(emp_name,emp_salary,emp_age) VALUES (?,?,?)";return executeUpdate(sql,employee.getEmpName(),employee.getEmpSalary(),employee.getEmpAge());} catch (Exception e) {throw new RuntimeException(e);}}@Overridepublic int update(Employee employee) {try {String sql = "UPDATE t_emp SET emp_salary = ? WHERE emp_id = ?";return executeUpdate(sql,employee.getEmpSalary(),employee.getEmpId());} catch (Exception e) {throw new RuntimeException(e);}}@Overridepublic int delete(Integer empId) {try {String sql = "delete from t_emp where emp_id = ?";return executeUpdate(sql,empId);} catch (Exception e) {throw new RuntimeException(e);}}
}十一、事务
11.1 事务回顾
- 数据库事务就是一种SQL语句执行的缓存机制,不会单条执行完毕就更新数据库数据,最终根据缓存内的多条语句执行结果统一判定! 一个事务内所有语句都成功及事务成功,我们可以触发commit提交事务来结束事务,更新数据! 一个事务内任意一条语句失败,即为事务失败,我们可以触发rollback回滚结束事务,数据回到事务之前状态!
- 一个业务涉及多条修改数据库语句! 例如:
- 经典的转账案例,转账业务(A账户减钱和B账户加钱,要一起成功)
- 批量删除(涉及多个删除)
- 批量添加(涉及多个插入)
- 事务的特性:
- 原子性(Atomicity)原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生, 要么都不发生。
- 一致性(Consistency)事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
- 隔离性(Isolation)事务的隔离性是指一个事务的执行不能被其他事务干扰, 即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(Durability)持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的, 接下来的其他操作和数据库故障不应该对其有任何影响
- 事务的提交方式:
- 自动提交:每条语句自动存储一个事务中,执行成功自动提交,执行失败自动回滚!
- 手动提交: 手动开启事务,添加语句,手动提交或者手动回滚即可!
11.2 JDBC中事务实现
-
关键代码:
-
try{connection.setAutoCommit(false); //关闭自动提交了//connection.setAutoCommit(false)也就类型于SET autocommit = off//注意,只要当前connection对象,进行数据库操作,都不会自动提交事务//数据库动作!//prepareStatement - 单一的数据库动作 c r u d //connection - 操作事务 //所有操作执行正确,提交事务!connection.commit();}catch(Execption e){//出现异常,则回滚事务!connection.rollback();}
-
11.3 JDBC事务代码实现
-
准备数据库表:
-
-- 继续在atguigu的库中创建银行表 CREATE TABLE t_bank(id INT PRIMARY KEY AUTO_INCREMENT COMMENT '账号主键',account VARCHAR(20) NOT NULL UNIQUE COMMENT '账号',money INT UNSIGNED COMMENT '金额,不能为负值') ;INSERT INTO t_bank(account,money) VALUES('zhangsan',1000),('lisi',1000);
-
-
DAO接口代码:
-
public interface BankDao{int addMoney(Integer id,Integer money);int subMoney(Integer id,Integer money); }
-
-
DAO实现类代码:
-
public class BankDaoImpl extends BaseDao implements BankDao{public int addMoney(Integer id,Integer money){try {String sql = "update t_bank set money = money + ? where id = ? ";return executeUpdate(sql,money,id);} catch (SQLException e) {throw new RuntimeException(e);}}public int subMoney(Integer id,Integer money){try {String sql = "update t_bank set money = money - ? where id = ? ";return executeUpdate(sql,money,id);} catch (SQLException e) {throw new RuntimeException(e);}} }
-
-
测试代码:
-
@Testpublic void testTransaction(){BankDao bankDao = new BankDaoImpl();Connection connection=null;try {//1.获取连接,将连接的事务提交改为手动提交connection = JDBCUtilV2.getConnection();connection.setAutoCommit(false);//开启事务,当前连接的自动提交关闭。改为手动提交!//2.操作减钱bankDao.subMoney(1,100);int i = 10 / 0;//3.操作加钱bankDao.addMoney(2,100);//4.前置的多次dao操作,没有异常,提交事务!connection.commit();} catch (Exception e) {try {connection.rollback();} catch (Exception ex) {throw new RuntimeException(ex);}}finally {JDBCUtilV2.release();}}
-
注意:
当开启事务后,切记一定要根据代码执行结果来决定是否提交或回滚!否则数据库看不到数据的操作结果!