一:ydata-profiling库的介绍
ydata-profiling是一个强大的 Python 库,它为 Pandas DataFrame 提供了快速的探索性数据分析(EDA)。它能够自动生成包含详细统计信息的交互式 HTML 报告,使得数据分析变得更加直观和便捷。
安装方法:
可以通过 pip 进行安装:
pip install ydata-profiling主要特点:
- 自动化分析:自动执行描述性统计、四分位数、相关性分析等。
- 丰富的可视化:报告中包含直方图、箱线图、热力图等多种图表。
- 交互式报告:HTML 报告支持交互操作,方便用户深入了解数据。
- 自定义配置:用户可以根据需要调整分析的深度和范围。
主要功能:
用于生成数据集的轮廓报告。它为数据分析的初始阶段提供了一个自动化的方式来总结数据集的主要特性。
- 快速概览:提供数据集的快速概览,包括数据的类型、缺失值、唯一值等。
- 统计描述:生成关于数值变量、分类变量的详细统计描述。
- 相关性分析:自动检测变量间的相关性,包括皮尔逊相关系数和Spearman等级相关系数。
- 缺失值分析:分析缺失数据的模式,帮助理解数据集中的数据缺失情况。
- 文本分析:对于文本数据,提供词频和字符分布的分析。
- 交互式报告:生成HTML格式的报告,可以在Web浏览器中查看,并支持交互式探索。
接下来,我将使用ydata-profiling来演示如何为一个示例数据集生成轮廓报告。为了演示,将首先创建一个包含不同类型数据(数值、分类、文本)的样本数据集,然后使用ydata-profiling库生成其数据分析报告。
二:利用ydata-profiling库来生成数据分析报告
要创建一个利用ydata-profiling生成数据报告的实例,首先,我们需要选择一个数据集。我将使用一个著名的鸢尾花数据集(Iris dataset),它包含数值型和分类型数据。然后,我将进行上述分析并生成报告。
鸢尾花数据集(Iris dataset)链接:https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
# 导入所需的库
import pandas as pd
from ydata_profiling import ProfileReport# 加载鸢尾花数据集
iris = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data", names=['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'])iris加载鸢尾花数据集如下:

然后使用ydata-profiling库生成其相关的数据分析报告:
# 生成数据报告
profile = ProfileReport(iris, title="Iris Dataset Report", explorative=True)# 将报告保存为HTML文件
profile.to_file("iris_dataset_report.html")最后我们观察生成的HTML网页包含以下部分:
Overview(概览)
提供数据集的整体信息,如字段数、记录数、缺失值行数、重复行数、内存占用情况等。
显示数据集的基本信息,如大小和变量类型。

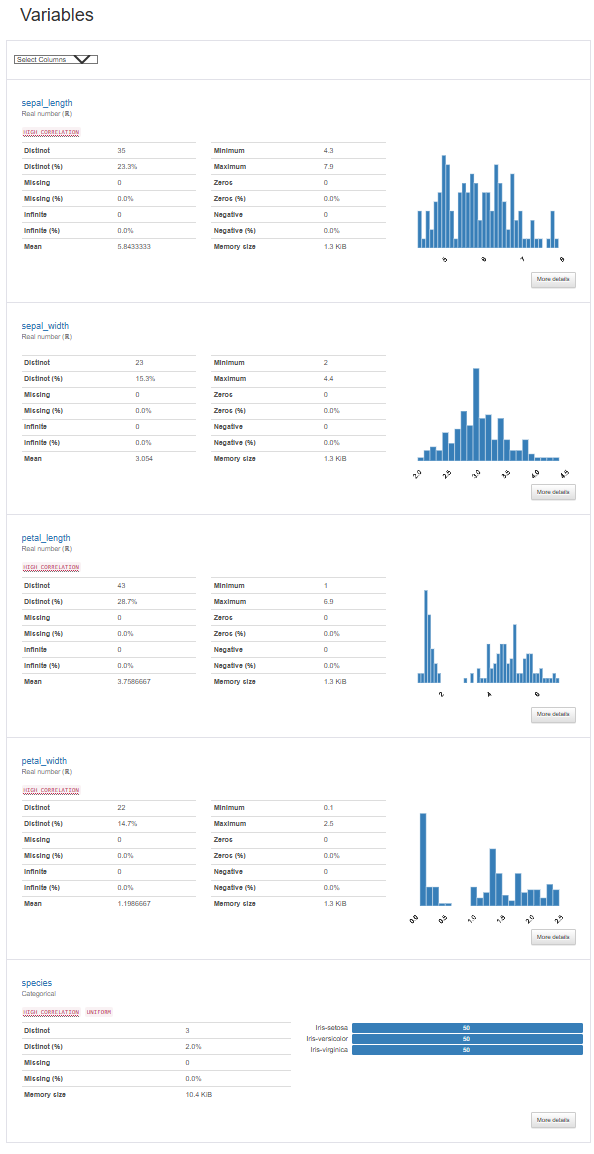
Variables(变量)
展示每个变量的详细统计信息,包括数据类型、缺失值、唯一值、描述性统计(均值、中位数、标准差、最小值、最大值等)。
提供直方图、箱线图和其他分布图来可视化每个变量的数据分布。
Interactions(交互作用)
通过散点图和相关可视化工具,展示变量之间的潜在关系和相互作用。
允许用户选择两个变量来查看它们之间的关系,帮助识别变量之间的相关性、差异性等。

Correlations(相关性)
使用热力图和其他图形展示变量之间的相关性,包括皮尔逊、斯皮尔曼和肯德尔相关系数。
帮助识别变量之间的线性关系和可能的多重共线性问题。

Missing values(缺失值)
提供关于数据集中缺失值的分布和数量的详细信息。
通过条形图和热图可视化显示每个变量的缺失值情况,帮助识别数据清洗的需求。

Sample(样本)
展示数据集的前几行和后几行记录,提供数据的直接预览。
允许用户快速查看数据集的样本,以便对数据有一个直观的理解。

Duplicate rows(重复行)
识别并报告数据集中的重复记录。
显示数据集中重复行的数量和具体内容,有助于数据清洗和去重。

ydata-profiling 通过这些部分提供了一个全面的数据集分析视图,使得能够快速理解数据集的特征,识别潜在的数据质量问题,并为进一步的数据分析和建模提供基础。报告可以导出为 HTML 或 JSON 格式,便于分享和进一步处理。
附录:实时股票行情数据

如果想了解更多相关金融工程的内容,可以关注之前的内容。