大家好,我是南枫,这篇文章我将给大家介绍如何使用Python爬虫来达到想爬哪个明星图片就能爬下来的效果,那我们接下来看看如何实现的吧。
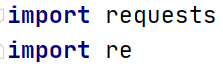
导入Python的requests库和re库。requests库用于发送HTTP请求,而re库用于处理正则表达式。
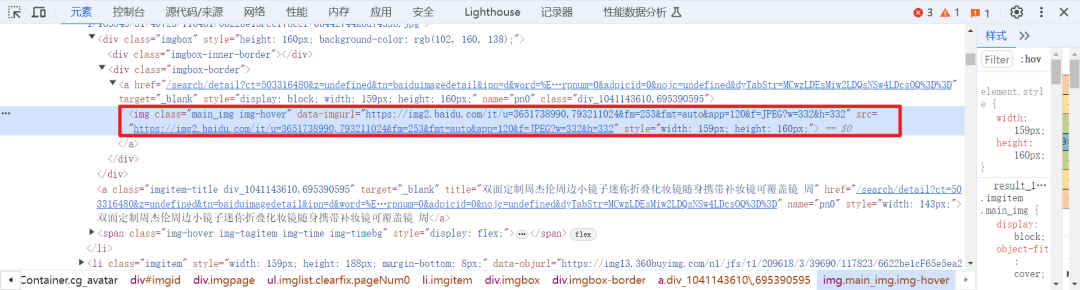
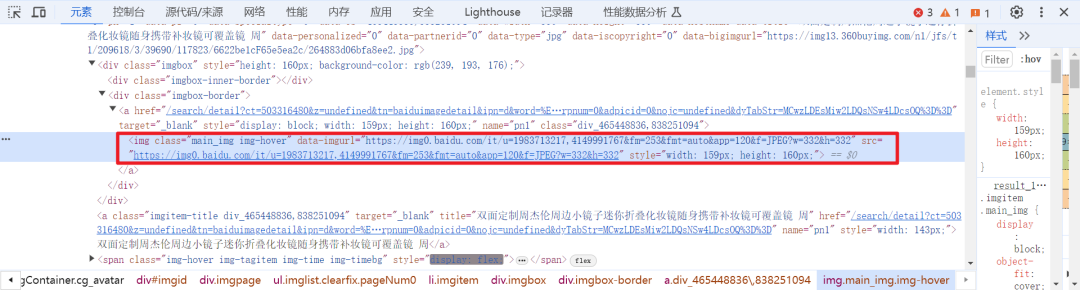
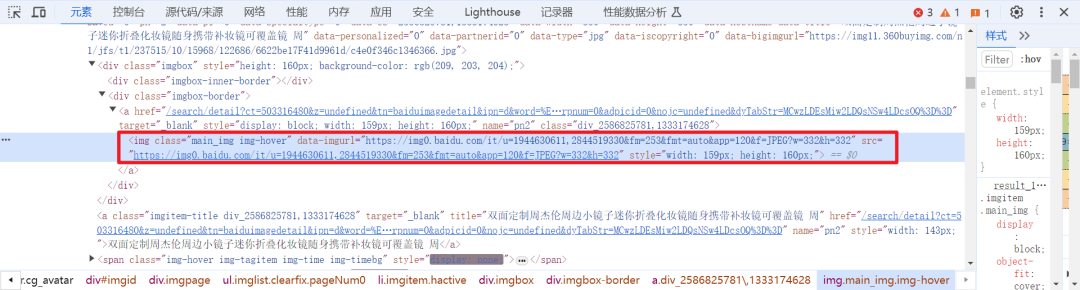
通过这三张图可以看出,我们需要的图片都在我标记的地方,那我们为什么要用正则表达式都知道了吧?那我们继续

打印提示信息,让用户输入关键词

获取用户输入的关键词

定义一个变量url,其值为百度图片搜索
的URL,其中包含了搜索关键词(即前面定义的keyword)
![]()
定义一个字典headers,其中包含了一个键值对,键为"User-Agent",值为一个字符串,这个字符串描述了浏览器的信息。这是为了防止服务器识别出这是一个爬虫程序

使用requests库的get方法发送一个GET请求到指定的url,同时传入headers参数,打印出请求的结果。
![]()
使用re库的findall方法在请求结果中查找所有匹配正则表达式r'objURL":"(.*?)",'的字符串,并将这些字符串放入一个列表中。这个正则表达式用于匹配图片的URL

定义一个变量a,初始值为1,遍历上一步得到的包含图片URL的列表。每次循环,将a的值加1。打印出当前的图片URL。再次使用requests库的get方法发送一个GET请求到当前的图片URL,同时传入headers参数和timeout参数(设置超时时间为10秒),定义一个变量name,其值为一个字符串,这个字符串包含了图片的保存路径和文件名,文件名由关键词和序号组成,打印出图片的保存路径和文件名。以二进制写模式打开一个文件,文件名为name,将图片的内容写入到文件中,打印出一条消息,表示正在下载第几张图片。

