基本介绍
Iceberg的Merge-On-Read
Merge-On-Read,顾名思义,就是在读取的时候进行合并,是与Copy-On-Write相反的一种模式
在Iceberg中,Merge-On-Read同样用于行级更新,整体过程如下
当更新数据时,Iceberg不再Copy一份旧数据,而是直接将更新数据写入独立的一个文件用来标识需要删除的数据
这种模式减少了写入时的合并操作,但是加重了读取数据时的合并操作,因此适合写多读少的场景
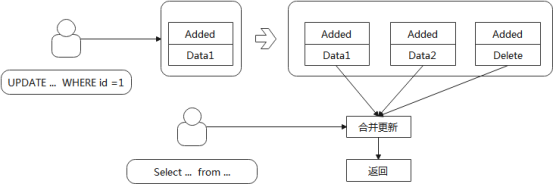
Merge-On-Read类型
Iceberg的Merge-On-Read有两种类型,对应使用两种不同的方法来定位需要删除的数据,分别是:EqualityDelete和PositionDelete
EqualityDelete:等值删除。这种模式下,delete文件记录的内容跟数据文件一样,是行级的数据。进行读取合并时,使用指定的列做等值判断,进行数据的删除合并
PositionDelete:位置删除。这种模式下,delete文件记录的内容是需要删除的数据位置,即数据文件地址和数据行号。进行读取合并时,基于数据地址进行删除合并
目前Iceberg没有进行EqualityDelete和PositionDelete选择的配置,使用哪种模式就看API实现了哪个接口。比如配置Spark使用Merge-On-Read时,使用的就是PositionDelete
case MERGE_ON_READ:return new SparkPositionDeltaOperation(spark, table, branch, info, isolationLevel);测试表现
执行如下测试
CREATE TABLE icedb.morTable (id bigint COMMENT 'unique id',data string)USING iceberg TBLPROPERTIES ('format-version'='2', 'write.update.mode' = 'merge-on-read');insert into icedb.morTable values (1, 'name1'),(99, 'name99');insert into icedb.morTable values (2, 'name1'),(88, 'name88');update icedb.morTable set data = 'update' WHERE id =1;- snapshot:与Copy-On-Write表现一致
- manifest-list:这里存在差异,产生了一条content=1的数据,也就是被标记为deletes,其他三条数据都是content=0
- manifest:这里总共四个manifest(2条insert分别产生一个,一个update产生两个),这里四个manifest的status都为1(0=existing、1=added、2=deleted);注意的是data_file中的content字段,指向deletes文件的是1,其他为0(0=data, 1=position deletes, 2=equality deletes)
- datafile:主要关注update产生的两个文件,一个是正常的数据文件,存的是update后的数据(1, 'update' );另一个是position delete文件,存的是需要删除的文件地址和行号{"file_path": "hdfs://nameservice/spark/icedb.db/morTable/data/00000-0-52cbb7ca-6a2b-4f87-a2ba-fefa2470d5b8-00001.parquet", "pos": 0}
Spark Update更新流程
整体流程与Copy-On-Write是一样的,两者都是Iceberg用来做行级更新的,只是具体的实现过程不一样
扫描过程
第一步同样是做旧数据的扫描,根据update传入的where条件扫描数据
不同的是,构建BatchScan扫描器的时候,Merge-On-Read比Copy-On-Write少了一项设置:ignoreResiduals()
ignoreResiduals()的作用在Copy-On-Write中已经介绍过,是设置扫描过滤条件只应用到文件。也就是说,设置了此项的Copy-On-Write扫描的时候返回的是文件粒度的数据,会把不需要更新的数据也读出来重写一遍;而没有设置此项的Merge-On-Read只读取完全匹配的数据,并不会读取不需要更新的数据行来进行重写
这个的具体应用是在文件扫描任务BaseFileScanTask当中,构建的时候会设置这个参数
BaseFileScanTask baseFileScanTask =new BaseFileScanTask(dataFile, deleteFiles, ctx.schemaAsString(), ctx.specAsString(), ctx.residuals());RewriteUpdateTable
Merge-On-Read走buildWriteDeltaPlan分支,生成的计划树如下
WriteIcebergDelta RelationV2[id#0L, data#1] spark_catalog.icedb.morTable spark_catalog.icedb.morTable+- UpdateRows[__row_operation#8, id#9L, data#10, _file#11, _pos#12L, _spec_id#13, _partition#14]+- Filter (id#0L = cast(1 as bigint))+- RelationV2[id#0L, data#1, _file#4, _pos#5L, _spec_id#2, _partition#3] spark_catalog.icedb.morTable spark_catalog.icedb.morTableRowLevelCommandScanRelationPushDown
这步走第一个分支,rewritePlan为WriteIcebergDelta的分支,最终的计划树为
WriteIcebergDelta RelationV2[id#105L, data#106] spark_catalog.icedb.morTable spark_catalog.icedb.morTable+- UpdateRows[__row_operation#113, id#114L, data#115, _file#116, _pos#117L, _spec_id#118, _partition#119]+- Project [id#105L, data#106, _file#109, _pos#110L, _spec_id#107, _partition#108]+- Filter (isnotnull(id#105L) AND (id#105L = 1))+- RelationV2[id#105L, data#106, _file#109, _pos#110L, _spec_id#107, _partition#108] spark_catalog.icedb.morTableExtendedV2Writes
这一步走的是WriteIcebergDelta分支,最终的计划树为
UpdateIcebergTable [assignment(id#0L, id#0L), assignment(data#1, update2)], (id#0L = 1):- RelationV2[id#0L, data#1] spark_catalog.icedb.morTable spark_catalog.icedb.morTable+- WriteIcebergDelta+- UpdateRows[__row_operation#8, id#9L, data#10, _file#11, _pos#12L, _spec_id#13, _partition#14]+- Project [id#0L, data#1, _file#4, _pos#5L, _spec_id#2, _partition#3]+- Filter (isnotnull(id#0L) AND (id#0L = 1))+- RelationV2[id#0L, data#1, _file#4, _pos#5L, _spec_id#2, _partition#3] spark_catalog.icedb.morTabWriteDeltaExec
最后同样进入ExtendedDataSourceV2Strategy,此处走WriteIcebergDelta分支,生成WriteDeltaExec(3.4这个类Spark集成了,所以不在Iceberg里了)
WriteDeltaExec与ReplaceDataExec一样是V2ExistingTableWriteExec的子类,不同的是WriteDeltaExec里对writingTask进行了特殊的实现,分别是DeltaWritingSparkTask和DeltaWithMetadataWritingSparkTask
两个writingTask的实现类基本相同,核心逻辑是根据不同的操作类型(insert、update、delete)调用DeltaWriter的对应接口
这里的DeltaWriter就是前面SparkPositionDeltaOperation创建的SparkPositionDeltaWrite,目前测试看update语句走的是insert+delete的流程
insert就是正常的流程,SparkPositionDeltaWrite的delete接口接收数据,这个数据是包含两个字段filePath和position,最终把这个字段写入delete类型的文件当中,写delete文件的时候在result的字段会记录delete列表,最终commit提交的时候就有对应关系
看前面的计划树,返回的数据schema当中包含了(_file#4, _pos#5L),这个就是delete这边数据的来源
定位信息
前面说过,最终写入delete文件的是file、pos两个字段,这两个字段在构建计划树的时候已经放在了schema上,来源是RewriteUpdateTable.buildWriteDeltaPlan,也就是RewriteUpdateTable的SupportsDelta分支
分支会重写计划,重写计划的时候有一步resolveRowIdAttrs,这一步会提取相应字段,让最终的数据源返回上加上file和position信息
读取数据
首先在创建ManifestGroup的时候,会去构建deleteIndexBuilder,deleteIndexBuilder用于查询标记为delete的文件,其输入是deleteManifests。
Iceberg元数据可以单独获取对应的类型的Manifest,具体操作在build的时候,build当中会单独对EqualityDelete和PositionDelete做操作,操作相同,只是找的文件类型不同
最后在createFileScanTasks构建扫描任务的时候,会把DeleteFile信息放入扫描任务
最终生效在读取文件的时候。以Spark为例,在BatchDataReader当中,基于上诉生成的扫描任务,首先获取要读取的文件,然后获取对应的delete文件封装SparkDeleteFilter,最终传入reader函数
真正生效的地方在ColumnarBatchReader当中,调用读取的时候会略过传入的delete对应的点,这样就只读取有效函数,忽略delete数据
具体的逻辑是在spark里,首先传入delete文件当中的position单独读取要删除的数据;然后在spark的逻辑里,从数据集当中把读到的这个数据给删除掉,在BufferedRowIterator的next当中,有删除逻辑
public InternalRow next() {return currentRows.remove();}