一、背景
cgroup是一个非常重要的功能,其中cgroup cpu这块有不少功能,在之前的博客 CFS及RT调度整体介绍_rt调度器-CSDN博客 里,我们分析了cfs的组调度也就是cgroup cpu的这块内核逻辑的细节侧重于调度逻辑这块,在之前的博客 cgroup cpu相关的基础概念及相关内核逻辑的耗时测试-CSDN博客 里,我们总结了一下cgroup cpu子系统的一些功能,在之前的博客 cgroup threaded功能例子-CSDN博客 里,我们介绍了cgroup threaded的模式,其实对于cgroup threaded模式还是默认的domain模式,cgroup的底层核心逻辑是一致的。
这篇博客里,我们复用在介绍cgroup threaded模式博客里的程序,改写一下,用来介绍一个cgroup cpu的一个关键参数:sched_cfs_bandwidth_slice,并说明其cgroup的逻辑原理,并说明其调整后的效果。
在第二章里,我们给出测试源码和测试方法及测试结果,在第三章里,我们给出原理分析。
二、测试源码及测试结果
2.1 测试源码
#include <iostream>
#include <thread>
#include <chrono>
#include <vector>
#include <string>
#include <cstdlib>
#include <fstream>
#include <unistd.h>
#include <sys/syscall.h>const int THREAD_COUNT = 20;
const int RUN_TIME_US = 100; // 100 us
const std::string CGROUP_NAME = "test/my_cgroup";// 获取线程的 TID
pid_t gettid() {return static_cast<pid_t>(syscall(SYS_gettid));
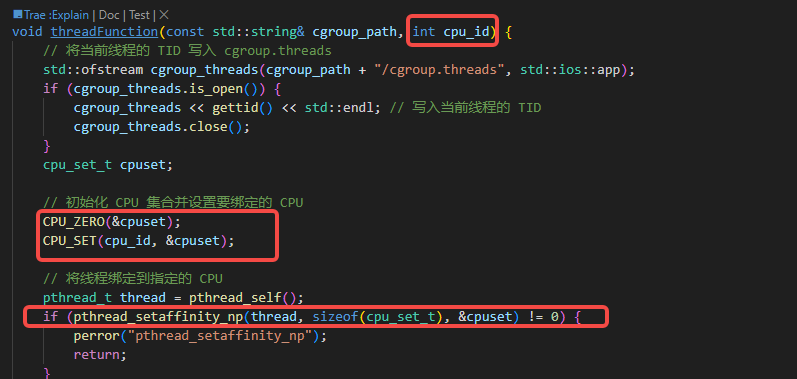
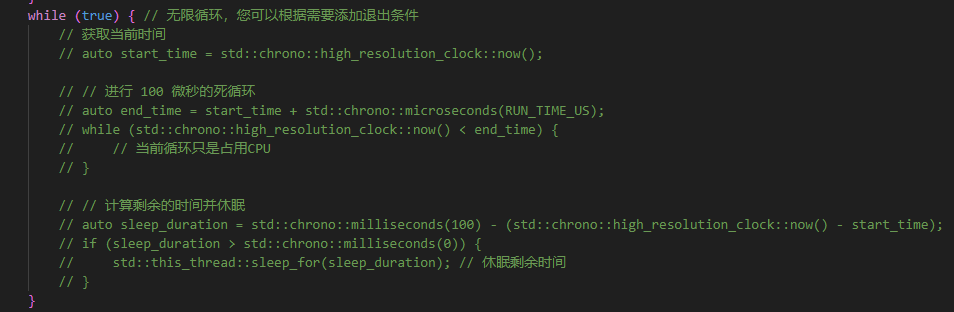
}void threadFunction(const std::string& cgroup_path, int cpu_id) {// 将当前线程的 TID 写入 cgroup.threadsstd::ofstream cgroup_threads(cgroup_path + "/cgroup.threads", std::ios::app);if (cgroup_threads.is_open()) {cgroup_threads << gettid() << std::endl; // 写入当前线程的 TIDcgroup_threads.close();}cpu_set_t cpuset;// 初始化 CPU 集合并设置要绑定的 CPUCPU_ZERO(&cpuset);CPU_SET(cpu_id, &cpuset);// 将线程绑定到指定的 CPUpthread_t thread = pthread_self();if (pthread_setaffinity_np(thread, sizeof(cpu_set_t), &cpuset) != 0) {perror("pthread_setaffinity_np");return;}while (true) { // 无限循环,您可以根据需要添加退出条件// 获取当前时间// auto start_time = std::chrono::high_resolution_clock::now();// // 进行 100 微秒的死循环// auto end_time = start_time + std::chrono::microseconds(RUN_TIME_US);// while (std::chrono::high_resolution_clock::now() < end_time) {// // 当前循环只是占用CPU// }// // 计算剩余的时间并休眠// auto sleep_duration = std::chrono::milliseconds(100) - (std::chrono::high_resolution_clock::now() - start_time);// if (sleep_duration > std::chrono::milliseconds(0)) {// std::this_thread::sleep_for(sleep_duration); // 休眠剩余时间// }}
}void threadFunctionEx(const std::string& cgroup_path) {// 将当前线程的 TID 写入 cgroup.threadsstd::ofstream cgroup_threads(cgroup_path + "/cgroup.threads", std::ios::app);if (cgroup_threads.is_open()) {cgroup_threads << gettid() << std::endl; // 写入当前线程的 TIDcgroup_threads.close();}std::this_thread::sleep_for(std::chrono::seconds(1));std::string command = "/usr/bin/deadloop &";system(command.c_str());while (true) { // 无限循环,您可以根据需要添加退出条件// 获取当前时间auto start_time = std::chrono::high_resolution_clock::now();// 进行 100 微秒的死循环auto end_time = start_time + std::chrono::microseconds(RUN_TIME_US);while (std::chrono::high_resolution_clock::now() < end_time) {// 当前循环只是占用CPU}// 计算剩余的时间并休眠auto sleep_duration = std::chrono::milliseconds(100) - (std::chrono::high_resolution_clock::now() - start_time);if (sleep_duration > std::chrono::milliseconds(0)) {std::this_thread::sleep_for(sleep_duration); // 休眠剩余时间}}
}void createCgroup(std::string& cgroup_path) {// 创建 cgroup 目录cgroup_path = "/sys/fs/cgroup/" + CGROUP_NAME;std::string command = "mkdir -p " + cgroup_path;system(command.c_str());// 设置 cgroup 为线程模式std::ofstream cgroup_mode(cgroup_path + "/cgroup.type");if (cgroup_mode.is_open()) {cgroup_mode << "threaded" << std::endl; // 设置为线程模式cgroup_mode.close();}// 将当前进程的 PID 写入 cgroup.procs// std::ofstream cgroup_cpus(cgroup_path + "/cpuset.cpus");// if (cgroup_cpus.is_open()) {// cgroup_cpus << 30;// cgroup_cpus.close();// }// 设置 CPU 限制std::ofstream cpu_max(cgroup_path + "/cpu.max");if (cpu_max.is_open()) {cpu_max << "150000 1000000" << std::endl; // 设置 CPU 限制cpu_max.close();}
}int main() {std::string cgroup_path;cgroup_path = "/sys/fs/cgroup/test";std::string command = "mkdir -p " + cgroup_path;system(command.c_str());command = "echo " + std::to_string(getpid()) + " >" + cgroup_path + "/cgroup.procs";system(command.c_str());command = "echo +cpuset +cpu > " + cgroup_path + "/cgroup.subtree_control";system(command.c_str());// 创建 cgroupcreateCgroup(cgroup_path);// 创建线程std::vector<std::thread> threads;for (int i = 0; i < THREAD_COUNT; ++i) {threads.emplace_back(threadFunction, cgroup_path, i);}//threads.emplace_back(threadFunctionEx, cgroup_path);// 主线程等待所有子线程完成for (auto& thread : threads) {thread.join();}// 清理 cgroupcommand = "rmdir " + cgroup_path; // 清理 cgroup 目录system(command.c_str());return 0;
}
2.2 测试源码的主要修改
代码改写自之前的博客 cgroup threaded功能例子-CSDN博客 里 2.1 里的程序,把线程的数量减少,减少到20个:
![]()
并每个线程绑定到不同的cpu上:
另外把每个线程里的行为从原来的100ms执行100us改成死循环:
设置cgroup cpu的quota和period从原来的一般默认的100ms周期改大道1秒的周期,cpu使用率限额是15%:

2.3 测试方式及测试结果
测试方法是先用系统一般默认的sched_cfs_bandwidth_slice_us参数(5000)来跑 2.1 的测试程序,通过抓ftrace放到perfetto上进行分析,看调度的情况。
然后再把sched_cfs_bandwidth_slice_us参数改大到(150000)即150ms,正好等于 2.1 代码里的cgroup的quota的配置150ms,这么改后,一样的抓ftrace放到perfetto上看调度情况。
最后,我们把cgroup的cpu的quota和period同比例的改小,再来看调度情况。
2.3.1 较大的period下sched_cfs_bandwidth_slice_us较大和较小对调度的影响
下图是较大的period下sched_cfs_bandwidth_slice_us也较大的情况下抓的2秒的ftrace放到perfetto里来看到的截图(关于ftrace的抓取和perfetto的使用见之前的博客 分析sys高问题的方法总结_cpu sys较高-CSDN博客 里的第五章):

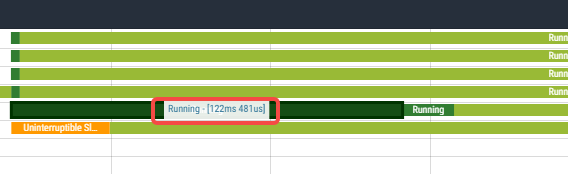
从上图里可以看到除了之前一个cgroup的period周期触发总限但各个核上还残留一些运行时间在新的period周期开始后可以补偿以外,其他时间基本都聚集给了某一个cpu上的线程,这个cpu上的这个线程持续运行时间有122ms:
加上下图里的后面一小段running的时间16ms:
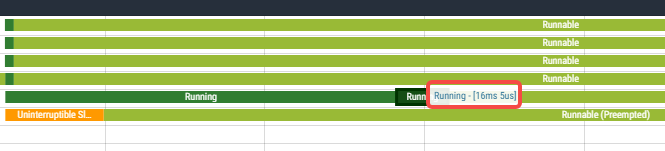
累积是138ms,加上其他几个核上的一点补偿的2ms,加一起正好是设置的cgroup的quota的150ms的时间。
那为什么都给了这一个cpu上的线程呢?就是和sched_cfs_bandwidth_slice_us的设置有关,sched_cfs_bandwidth_slice_us设置的是150ms,是个比较大的值,所以导致某个cpu上会运行比较多的时间。具体细节我们在第三章里展开。
下面我们看一下较大的period下sched_cfs_bandwidth_slice_us较小,也就是设的是默认的5000也就是5ms的情况:
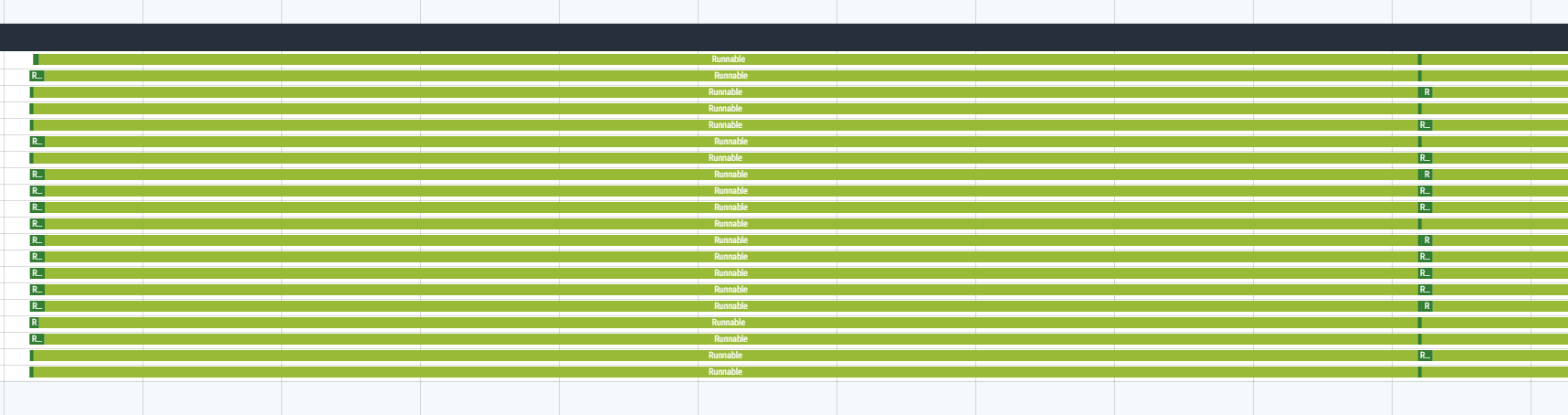
可以看到,如果是较小的sched_cfs_bandwidth_slice_us,如上图,分散到每个核上的运行时间也会相对均匀。
2.3.2 较小的period下sched_cfs_bandwidth_slice_us较大和较小对调度的影响
较小的period是指一般采用的100ms的周期,当前设的是100ms周期内可运行15ms。由于period的周期相对较小,就算sched_cfs_bandwidth_slice_us较大,但是如果稍微拉长一下周期,因为period周期较短导致各个核上的runtime时间被不断切割,最终还是会变成相对较短的周期,为了体现这样的变化,我们先启动ftrace抓取,抓取相对长一些的时间,来看这个变化趋势:
下图是sched_cfs_bandwidth_slice_us较大的情况:
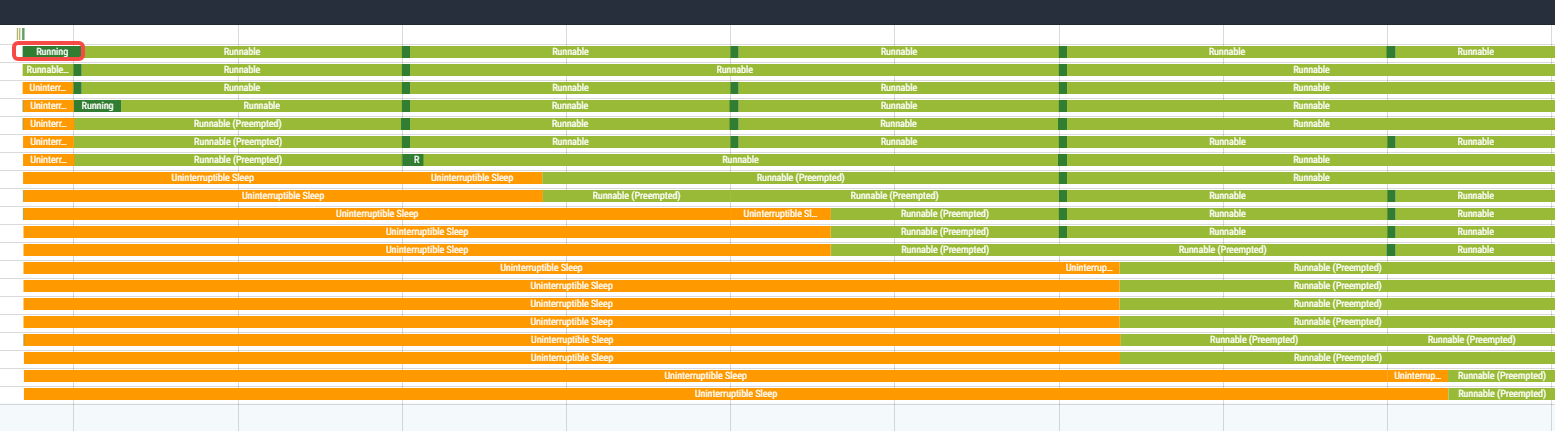
下图是sched_cfs_bandwidth_slice_us较小的情况:

可以明显的看出来sched_cfs_bandwidth_slice_us较大的情况下,在程序刚启动那会儿会有cpu上运行相对比较长的时间,如下图里运行了17ms:
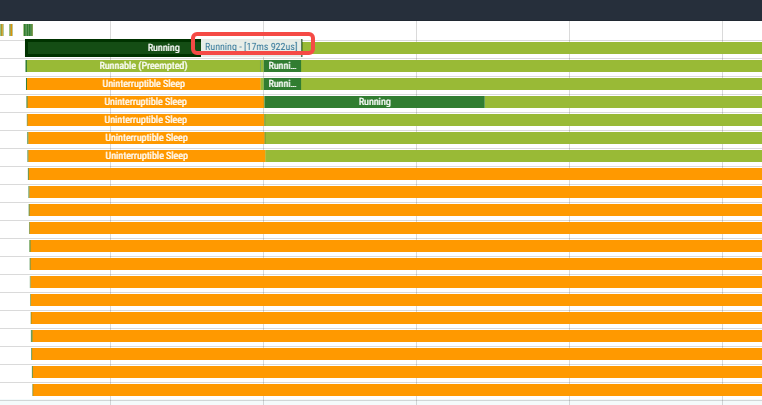
这个状态在时间慢慢拉长后,慢慢变短:
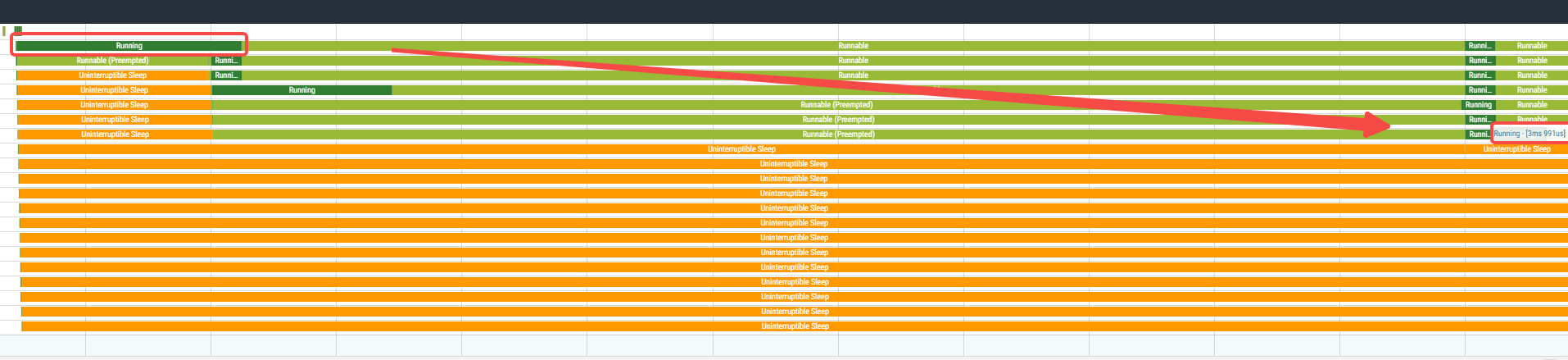
而对于sched_cfs_bandwidth_slice_us较小的情况,则一上来就不会某个核上运行较长时间:

三、原理分析
sched_cfs_bandwidth_slice_us是一个颗粒度概念,表示的是某个cgroup cpu上一次申请runtime的时间颗粒度。这个sched_cfs_bandwidth_slice_us的单位是us,相关的函数如下:

这个值可以通过/proc/sys/kernel/sched_cfs_bandwidth_slice_us设置,也可以通过sysctl -w来设置。
我们再来解释一下这个sched_cfs_bandwidth_slice_us这个颗粒度的概念。
每个cpu上都有一个cfs_rq,如下图里这个cgroup cpu的申请时间的核心函数assign_cfs_rq_runtime的逻辑:
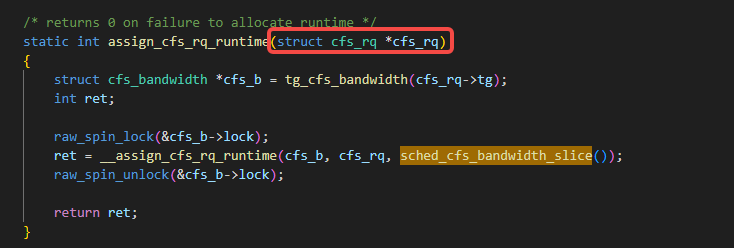
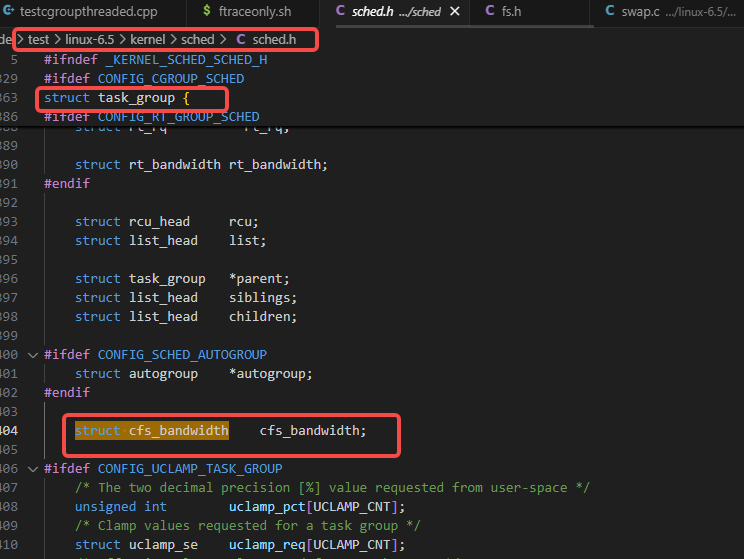
传入的cfs_rq是每个cpu上都有一个实例的,它们被cgroup的层次结构相关的管理对象task_group锁管理,task_group这个数据结构体里的核心就是上图里用到的这个cfs_bandwidth管理对象,如下图里task_group的定义:
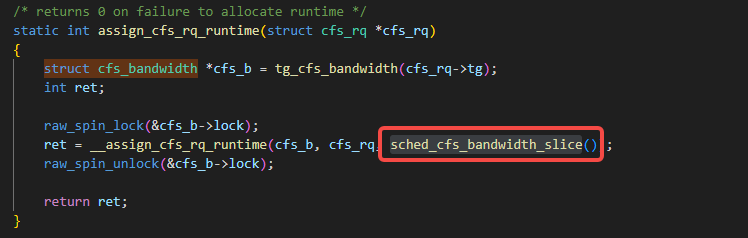
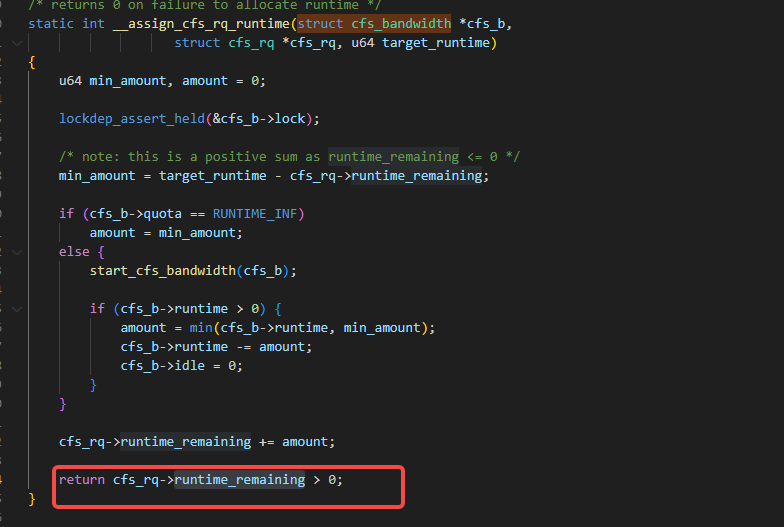
assign_cfs_rq_runtime通过__assign_cfs_rq_runtime函数来为某个cpu的rq即cfs_rq争取到运行时间,看一下__assign_cfs_rq_runtime这个函数,这个函数的第三个入参target_runtime就是通过获取sched_cfs_bandwidth_slice()来得到的:
回到__assign_cfs_rq_runtime函数里,我们看到这个函数里大体上分为三步:
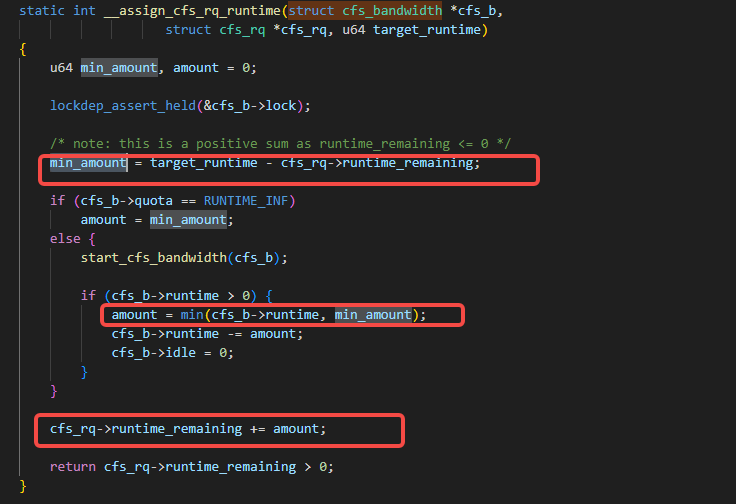
第一步是min_amount通过之前的残留的runtime_remaining加上这一次分配的target_runtime来计算得到和值,要注意runtime_remaining是一个负数:

第二步是把刚计算到的min_amount与当前的task_group里的总剩余时间比较,不能超限,如果超限则用当前task_group里的总剩余时间:
![]()
当然在申请到这个amount时间后,也得从剩余总时间里扣除:
![]()
第三步,就是把申请到的时间和当前这个cfs_rq里剩余的时间相加,这个相加的意思由于runtime_remaining是负数,相当于就是把之前多运行的时间(借的时间)现在还回来。
如果还不回来的话,就要把当前这个cfs_rq就绪队列从上一级的cgroup的sched_entity里移除:
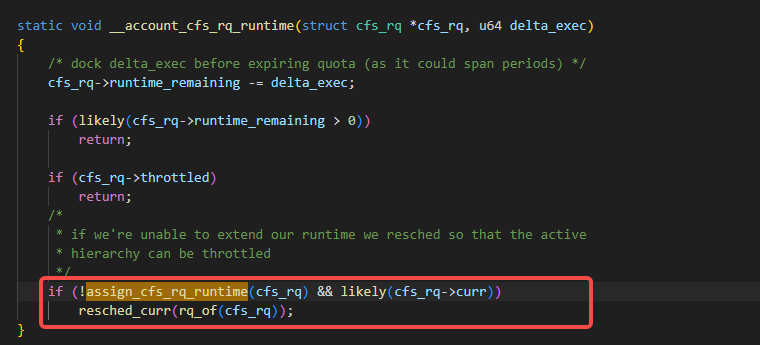
为什么会有runtime_remaining是负数,是因为我们cgroup的计算时间是否超限的逻辑一般由tick触发,由于tick是一个低精度的时钟,所以肯定会有多跑的情形。