目录
YOLO v1 算法详解
1. 核心思想
2. 算法优势
3. 网络结构(Unified Detection)
4. 关键创新
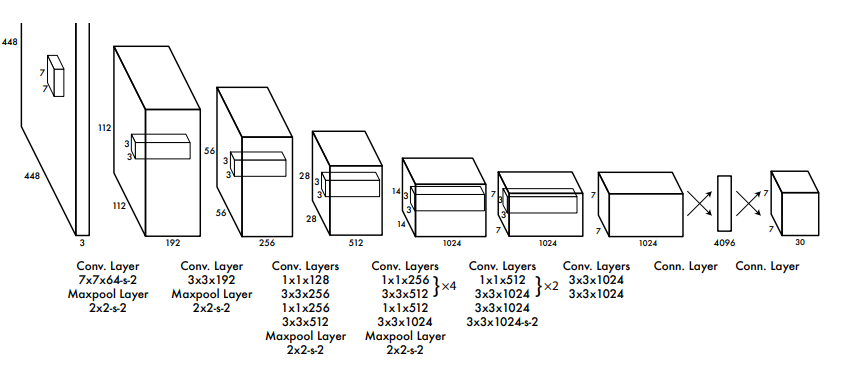
5. 结构示意图(Fig1)
Confidence Score 的计算
类别概率与 Bounding Box 的关系
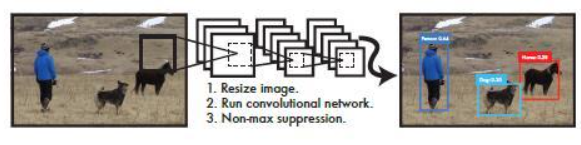
后处理:非极大值抑制(NMS)
网络结构实现细节
输出张量示例(7×7×30)
深入解析YOLO v1:实时目标检测的开山之作
YOLO(You Only Look Once)是目标检测领域的里程碑式算法,由Joseph Redmon等人在2016年CVPR会议上提出。作为第一个将目标检测任务转化为单阶段(one-stage)回归问题的算法,YOLO v1以其惊人的速度和简洁的网络结构迅速成为研究热点。本文将全面剖析YOLO v1的核心思想、实现细节及技术优势,并对比同期算法(如Faster R-CNN)的差异。
论文名称:You only look once unified real-time object detection
论文链接
YOLO v1 算法详解
1. 核心思想
YOLO(You Only Look Once)将物体检测(object detection)任务视为一个端到端的回归问题,通过单个卷积神经网络(CNN)直接从输入图像预测目标边界框(bounding box)和类别概率。
2. 算法优势
YOLO v1 的主要优势包括:
- 速度快:在 Titan X GPU 上达到 45 FPS,快速版(Fast YOLO)可达 150 FPS,适合实时检测。
- 全局推理:基于整张图像进行预测(而非滑动窗口或候选区域),减少背景误检(false positives),比 Fast R-CNN 的误检率低一半以上。
- 泛化能力强:学习到的特征更具通用性,在迁移到新领域时表现较好。
- 高准确率:在 VOC 2007 数据集上 mAP 达 63.4%,兼顾速度和精度。
3. 网络结构(Unified Detection)
YOLO v1 采用 24 层卷积网络 + 2 层全连接层,结构特点如下:
- 输入:448×448 图像(通过下采样适应网络)。
- 输出:
S×S×(B×5 + C)的张量,其中:S×S表示网格划分(默认7×7)。B是每个网格预测的边界框数量(默认2)。5包含边界框的坐标(x, y, w, h)和置信度(confidence)。C是类别概率(如 VOC 数据集的 20 类)。
4. 关键创新
- 网格化预测:图像被划分为
S×S网格,每个网格负责预测中心落在该区域的目标。 - 多任务损失函数:联合优化边界框坐标、置信度和分类概率,损失函数设计如下:
- 坐标误差(加权)
- 置信度误差(区分有无目标)
- 分类误差(交叉熵)
5. 结构示意图(Fig1)
Confidence Score 的计算
每个 bounding box 对应一个 confidence score,用于衡量该框内是否包含物体以及预测框的准确性:
- 公式:
![]()
-
- 如果 grid cell 中没有物体(背景),则 confidence = 0。
- 如果 grid cell 中有物体,confidence = 预测框与真实框的 IOU(交并比)。
如何判断 grid cell 是否包含物体?
- 规则:若某物体的 ground truth 边界框的中心点坐标落在某个 grid cell 内,则该 grid cell 负责预测该物体。
类别概率与 Bounding Box 的关系
-
类别概率(Class Probability):
- 每个 grid cell 预测 C 个类别概率(如 VOC 数据集的 20 类),表示该 grid cell 包含物体时属于各类别的概率。
- 注意:类别概率是针对 grid cell 的,而非单个 bounding box。
-
Bounding Box 的最终分类得分:
- 将每个 bounding box 的 confidence 与 grid cell 的类别概率相乘,得到该 box 属于某类别的置信度得分:
![]()
-
- 输出矩阵:
- 形状为
20×(7×7×2) = 20×98(20 类,98 个 bounding box)。
- 形状为
- 输出矩阵:
后处理:非极大值抑制(NMS)
- 阈值过滤:
- 对每一类别(矩阵的每一行),将得分 < 0.2 的 bounding box 置 0。
- 排序与去重:
- 按得分从高到低排序,选择最高得分的 box,计算其与其余 box 的 IOU:
- 若 IOU > 0.5(重叠过高),则抑制(得分置 0)。
- 否则保留。
- 重复上述过程,直到所有 box 被处理。
- 按得分从高到低排序,选择最高得分的 box,计算其与其余 box 的 IOU:
- 最终分类:
- 对每个 bounding box,取 20 个类别得分中的最大值:
- 若最大值 > 0,则判定为对应类别;
- 若最大值 = 0,判定为背景(忽略)。
- 对每个 bounding box,取 20 个类别得分中的最大值:
网络结构实现细节
- Backbone:基于 GoogLeNet 改进的卷积网络(24 层卷积 + 4 层 Inception 模块)。
- 输出层:
- 全连接层输出
7×7×30的张量,其中:7×7:grid cell 数量。30:包含 2 个 bounding box 的坐标(x,y,w,h)和 confidence,以及 20 个类别概率。
- 全连接层输出
- 关键改动:
- 替换 GoogLeNet 的复杂 Inception 模块为简单的
1×1和3×3卷积组合,提升速度。 - 最后一层全连接层直接回归边界框和类别(端到端训练)。
- 替换 GoogLeNet 的复杂 Inception 模块为简单的
输出张量示例(7×7×30)
| 分量 | 维度 | 说明 |
|---|---|---|
| Bounding Box 1 | 5 (x,y,w,h,conf) | 第一个预测框的坐标和置信度 |
| Bounding Box 2 | 5 (x,y,w,h,conf) | 第二个预测框的坐标和置信度 |
| Class Probabilities | 20 | 20 个类别的条件概率(P(class|obj)) |