很多时候我们只是在谈论HANA的内存计算机制,但是HANA的持久化机制也是同样会影响到HANA的性能。所以今天学习下持久层的技术机制做下笔记:
需要注意的是:当我们讨论的“持久层”是一个逻辑概念,持久层不仅包括磁盘部分,还包括内存部分。
持久化的简单介绍
不论是行表还是列表,在写入操作过程中,log entries 先写入到内存中的log buffer,随后在事务commit操作过程中,log entries被刷到磁盘上。
列表通过内存中delta区域过在列表delta fragment增加一条变更记录,来实现新增一行的效果。然后下层页(underlying pages)会被标记为changed (dirty). “dirty” delta pages 会以异步方式的写操作来被填充和持久化。触发dirty page 到磁盘的3种方式为:
1.当page填充了足够的行记录
2.当savepoint触发时
3.表被unload到磁盘。
当列存储的delta merge触发时,HANA需要做的就是把Main fragments持久化到磁盘。该过程中持久层会先临时存放内存中的page buffer,然后再落到磁盘。
行表可以利用差异日志实现并行日志处理,使用差异日志的好处是允许不用按照写入顺序来处理日志条目。具体实现机制是XOR image,通过修改磁盘上的位运算实现redo和undo操作。
持久层架构
在谈论架构前,先了解一下 事务的持续性和一致性
1.为了保证事务的持续性,在事务提交时,并不需要持久化全量的数据,而是持久化transaction log(也就是redo log)。
2.事务的commit操作和数据的持久化没有完全对应关系。也就是说即便是未commit,也可能会有部分数据进行了持久化操作。反过来讲,即便是已经提交的事务,也可能未完成数据的持久化操作。因此,在宕机发生时,事务未提交但已经持久化的数据需要roll back回滚(通过undo files和shadow paging实现);而事务已提交但是数据还未持久化则需要通过redo log完成。
架构介绍
首先现在已经知道,持久层是包括内存和磁盘在内的逻辑层,当我们讨论这个概念时,并不是唯一指向磁盘的。
持久层主要目的是将数据存放在磁盘上并且以页面(pages)的形式来进行管理。pages大小范围4k-16M。
读写数据时,数据需要先从磁盘page加载到内存page buffer。page和page buffer都由persistence layer进行管理,HANA在访问内存中的数据时,无需进行加载page的操作(这是因为数据已经在内存了)。
Logger和log buffer
logger是HANA中的重要组件,主要的作用是提供了一个接口,供其他组件创建log entries并且允许刷新缓冲区中的redo log entries到磁盘上。
logger组件的重要目的是提供高并发,这是由把1个log volume分成多个log partitions来实现,partitions可以坐落于不同的磁盘,并且可以由轮询(round robin)方式来写入。
坐落于磁盘上的log partition又可以继续划分为log segments(日志备份的基本单元)。每个partition中仅会有一个处于active状态的log segment在写入。当active的log segment写满,就会触发log backup,整个log segment会变成log backup文件。
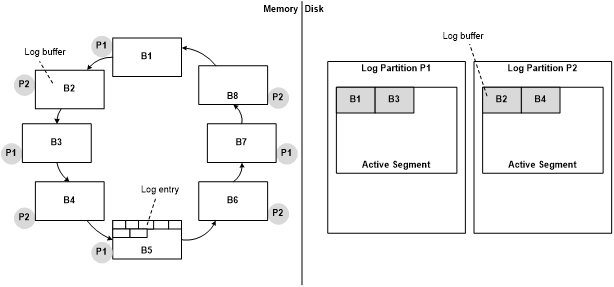
日志条目会先存放到log buffer中,随后从内存落到磁盘上的log segment中。所以可以说log buffer是Log Segment的基本单元。

Log entriy写入内存中的log buffer,log buffer再以轮询机制写入磁盘上的log segment。每一个Log partition都有一个I/O queue,如果磁盘IO受限,则log buffer会暂存在I/0 queue。
为了保障事务一致性。在一个事务进行commit操作时,HANA会直接将当前log buffer落到磁盘,即使log buffer未满。
以下这个图就显示了对于日志落盘的概念介绍。可以看到当前B5是处于active状态的log buffer。当事务提交时,即便当前B5 log buffer未满,也会记录commit操作并且准备落盘。在落盘阶段,log buffer会先进入到队列中,在队列中的期间,log entry仍可以继续写入B5。直到IO操作完成。这样就解决了大批量transaction同时commit带来的并发问题。毕竟大部分transaction的最终目的都是为了commit。
Undo 操作
Undo操作没有日志记录,所以没有见过‘undo log’这个词吧,HANA管undo操作用到的信息称之为undo information。主要由savepoint期间最新版本的行表页(包括未提交部分的数据)被刷到磁盘上。同理,对于未提交列表的delta storage页也会被刷新到磁盘上。 所以在HANA重启时,undo操作主要使用存放在data volume中的shadow page以及undo information实现。
shadow page基于持久层中的HANA converter组件实现。该组件负责在converter table中记录逻辑页和物理页的mapping关系。当读取不在内存中的逻辑页时,这个组件负责找到物理页加载位置。
Undo information由undo manager组件管理。对于每个事务,会形成一份虚拟undo 文件并且不晚于下一次savepoint,落到data 卷中。undo 文件无需在事务完成前必须落盘,这是因为即便系统崩了,下次重启进需要savepoint和redo log即可恢复。
那为什么又设计了undo information的概念呢?
1.事务提交时,更少的log entries持久化操作
2.log卷增长缓慢
3.数据库可以仅用data卷即可恢复至一致性状态
Consistent Change Protocol
所有修改持久化页面的操作都需要遵循一致性更改协议。该协议确保记录所有更改,并在修改后将页面标记为已更改。
consistent change 发生时,该协议使用共享模式锁(shared mode).
Save point的第二阶段(exclusive part)需要使用到该协议的排他模式锁(exclusive mode)
一致性变更协议要求在修改数据时执行以下步骤:
•开始一致性更改操作。
这将产生consistent change lock(是一种共享锁),来保护当前Savepoint的写入操作。
•修改页面
•写入redo log条目和undo information
•设置指示页面已被修改的标志(flag)
•关闭一致性变更操作。释放共享锁。
Persistence Containers
持久化页(pages)会存放在持久化容器中:
Virtual files 主要存放列表的Main存储部分。
fixed size entry container 存放固定大小的数据对象。其中一个子类型容器用于存放livecache中同一类对象。
var size entry container 存放可变大小的数据对象。主要存放页的Link地址,使用B* trees管理。
Memory Management
对于列表存储,数据会从磁盘先加载到属于persistence layer 的page buffer中,然后再复制到连续性的包含完整一列的column table area。随后persistence layer 立即释放内存。这样的好处是避免一列的数据分散到内存不同区域。
对于行表存储,则直接存放在persistence layer,persistence layer提供接口访问到行表page ,无需再进行copy操作。
Savepoint 操作
持久层会定期执行保存点(savepoint)操作。
在保存点操作期间,页面缓冲区中已修改的页面(page)、脏的列存储delta页面以及行存储所生成的页面都会被写入磁盘。
与此同时,缓冲的redo日志条目也会被刷新到磁盘。
savepoint由savepoint coordinator组件异步实现。可以由backup, database shutdown, restart is completed来自动触发,也可以手动触发。
Savepoint的3个主要阶段:
第一阶段
大部分已更改的数据会被写入磁盘。在此阶段,数据库操作会照常继续进行。
第二阶段
- 申请consistent change lock 进入排他模式(exclusive
mode),这回阻塞当前持久层的写操作。HANA会通知事务管理器,事务不可以启动,也不可以完成写操作。 - 需要进行持久化的页面会copy到临时内存。
- 记录当前log位置。
- 收集当前正在进行的事务列表。
- 对以下数据,异步写操作到磁盘:
临时buffer页,进行中事务列表,log位置,converter table以及事务的开始位置。 - 退出exclusive mode,consistent change lock释放,通知事务管理器可以继续进行操作。
第三阶段
在此阶段,等待异步IO完成。并且同步写入重启记录link到anchor page。这个时候,新的savepoint被认定为已完成,而被旧的savepoint标记的shadow page 标记为"free"。
其他:
1.日志不落盘事务就不能完成提交
2.列表的full page以及delta merge都会触发持久化操作
3.行表数据持久化仅会在savepoint期间进行(因为行表没有列表具备Delta Merge机制)。
4.Snapshot可以视为永久存在的savepoint。可用于无需日志恢复数据库。
5.行表并不像列表是连续存放在内存中的,所以行表有更大概率看到fragmentation。所以对于HANA,当我们谈论GC时,主要是对行表的MVCC进行。
--处理行表defragment操作,120代表着允许20%的碎片--
--该操作 online进行,不会阻塞对表的访问--
ALTER SYSTEM RECLAIM DATAVOLUME '<host>:<port>' 120 DEFRAGMENT