在实际应用过程中,我们经常会部署开源的大模型并将其定义成服务接口,或者做成web页面的形式,这样就能使用和测试大模型的推理能力。我们在使用kimi,千问,deepseek时会发现他们都有一个联网功能,大模型增加了联网搜索功能后,能够实时为大模型提供推理所需的素材,减少大模型的幻觉,提供大模型的推理准确性。
离线的大模型可以通过搜索接口实现联网搜索功能,常用的搜索引擎几乎都会提供API接口,其中倍受推荐的是tavily,但这些API接口都是收费的,本文使用DuckDuckGo来实现离线大模型的联网搜索功能,DuckDuckGo的好处就是免费。
1.启动虚拟环境
根据自己的实际情况启动运行大模型的虚拟环境,在本例中我使用了千问的模型,所以在我的测试服务器上我使用以下命令启动了千问的虚拟环境。
conda activate qwen
2.安装依赖
pip install -qU langchain-openai
pip install -qU langchain-anthropic
pip install -qU langchain_community
pip install -qU langchain_experimental
pip install -qU langgraph
pip install -qU duckduckgo-search
📓 如果你使用kaggle的notebook环境,还需要安装accelerate和ipywidgets。
3.代码示例
3.1 大模型不联网的示例
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from langchain_core.prompts import ChatPromptTemplate# 设置模型标识符或本地模型目录
model_dir = "Qwen/Qwen2-7B-Instruct"# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_dir,return_dict=True,low_cpu_mem_usage=True,torch_dtype=torch.float16,device_map="auto",trust_remote_code=True,
)# 使用 transformers 的 pipeline 初始化聊天模型
chat = pipeline('text-generation', model=model, tokenizer=tokenizer)# 定义聊天提示模板(只包含系统提示和用户输入)
prompt = ChatPromptTemplate.from_messages([("system", "You are a helpful assistant."),("user", "{input}")
])# 创建一个提问和生成回答的链
def chain(input_text):# 格式化提示模板,将用户输入填入prompt_text = prompt.format(input=input_text)# 使用模型生成回复response = chat(prompt_text, max_length=512, num_return_sequences=1)return response[0]['generated_text']# 示例用法
response = chain("青岛今天的天气如何")
print(response)
运行上面的代码后,会出现如下的输出,说明大模型并没有联网功能。

3.2 大模型联网后的示例
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser# 初始化 DuckDuckGoSearchRun 工具
search_tool = DuckDuckGoSearchRun()# 初始化模型
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline# 设置模型保存路径
model_dir = './Qwen2-7B-Instruct'# 如果模型目录不存在,则下载并保存模型
if not os.path.exists(model_dir):os.makedirs(model_dir)base_model = "Qwen/Qwen2-7B-Instruct"tokenizer = AutoTokenizer.from_pretrained(base_model)tokenizer.save_pretrained(model_dir)model = AutoModelForCausalLM.from_pretrained(base_model,return_dict=True,low_cpu_mem_usage=True,torch_dtype=torch.float16,device_map="auto",trust_remote_code=True,)model.save_pretrained(model_dir)
else:tokenizer = AutoTokenizer.from_pretrained(model_dir)model = AutoModelForCausalLM.from_pretrained(model_dir,return_dict=True,low_cpu_mem_usage=True,torch_dtype=torch.float16,device_map="auto",trust_remote_code=True,)# 初始化聊天模型
chat = pipeline('text-generation', model=model, tokenizer=tokenizer)# 为聊天机器人定义一个提示模板
prompt = ChatPromptTemplate.from_messages([("system", "You are a helpful assistant. Use the search tool to find up-to-date information if needed."),("user", "{input}"),("assistant", "{search_results}"),
])# 创建一个集成搜索工具和 LLM(大型语言模型)的链
def chain(input_text):# 获取搜索结果search_results = search_tool.invoke({'query': input_text})# 将搜索结果和用户输入整合到提示模板中prompt_text = prompt.format(input=input_text, search_results=search_results)# 生成响应response = chat(prompt_text, max_length=512, num_return_sequences=1)return response[0]['generated_text']# 示例用法
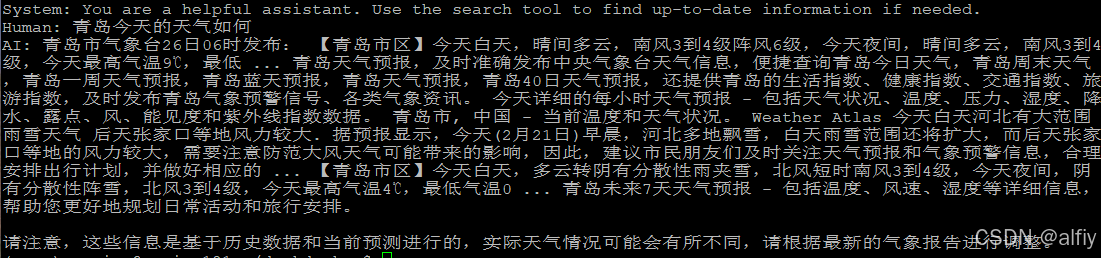
response = chain("青岛今天的天气如何")
print(response)
运行上面的代码后,会输出如下图所示的输出,说明模型具备了联网的功能。
👿 由于duckduckgo需要梯子才能使用,所以上面的示例要有科学上网的环境才行。