LLM出来以后,知乎上就出现了“传统NLP已死”的言论,但是传统NLP真的就被扔进历史的垃圾桶了吗?

其实,尽管LLM具有出色的通用能力,但仍然无法有效应对低资源领域的自然语言处理任务,如小语种翻译。为了更好地解决这些任务,需要设计有效的方法(如微调或提示技术等),将所需要的任务信息或领域特定知识注入到LLM。在实践中,将大小模型进行融合,从而实现优势互补,也是一个有前景的技术方向。
本文将重点介绍LLM在三大类经典自然语言处理任务上的应用,包括序列标注、关系抽取以及文本生成任务,这些任务构成了许多现有自然语言处理系统和应用的基础。
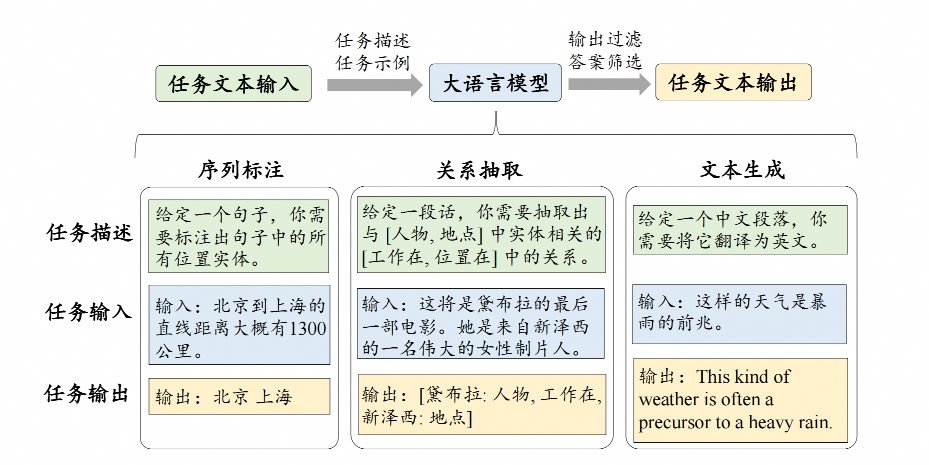
1、序列标注
序列标注任务,如命名实体识别(NER)和词性标注(POS),是一种基础的自然语言处理任务。
通常来说,这类任务要求为输入文本序列中的每一个词项分配适当的语义类别标签,例如NER任务中经典的B-I-O标记方案(Beginning,Inside和Outside)。在深度学习时代,一种主流的技术方法是通过神经网络模型(如CNN、LSTM或BERT等)对于序列单元进行编码,然后再将编码后的序列作为特征输入到经典的条件随机场模型(CRF)中,进而CRF能够基于编码后的序列特征进行序列标签的结构化预测。
不同于传统方法,LLM可以通过上下文学习或基于特殊提示的方式解决序列标注任务,而无须使用B-I-O标记。
例如,仅需要给予大模型相关的提示(如“请识别出句子中包含的实体”)或任务示例(如“输入文本‘中华人民共和国今天成立了’,请抽取出其所包含的命名实体:‘中华人民共和国’”)即可自动抽取出实体。
然而,LLM在传统序列标注任务上也面临着许多挑战,特别是在识别具有罕见或歧义名称的特殊实体时。原因在于LLM可能会误解特殊实体的含义,将其与常见的非实体词混淆,从而难以根据上下文中的提示和示例准确将它们识别出来。
2、关系抽取
关系抽取任务关注于从非结构化文本数据中自动提取出蕴含的语义关系。
例如,当输入为“莱昂内尔·梅西出生在阿根廷”,其包含的语义关系三元组为“莱昂内尔·梅西-出生地-阿根廷”。通常来说,这类任务会被转化为文本分类或序列标注任务,并可以采用对应的技术方法进行解决。
由于大模型具有出色的推理能力,它能够借助特定提示方法(如上下文学习等)来完成关系抽取任务,并在涉及复杂推理场景的任务中相较于小模型更具优势。然而,当关系标签规模较为庞大时,这些知识信息难以完全通过上下文学习的方式注入到LLM中,可能会出现关系抽取效果较差的情况。
因此,为了提高对各种场景的适应能力,可以使用LLM和小型模型互相配合的方法。例如,利用小模型进行候选关系的初筛,再利用大模型进一步从初筛后的候选关系中推理出最合适关系;也可以采用LLM对于数据进行初步标注,从而丰富可用于训练的小模型的标注数据。这种基于两种模型结合的工作范式在信息抽取场景下具有较好的应用场景。
3、文本生成
文本生成,如机器翻译和自动摘要,是在现实应用中常见的自然语言处理任务。
目前,基于微调的小型语言模型已经被广泛部署于许多产品和系统中。由前述内容所述,LLM具备强大的文本生成能力,通过适当的提示方法,在很多生成任务中能够展现出接近人类的表现。此外,LLM的使用方式更为灵活,可以应对实际应用场景的很多特殊要求。
例如,在翻译过程中,LLM能够与用户形成交互,进一步提高生成质量。
然而,LLM难以有效处理低资源语言或领域下的文本生成任务,例如马拉地语到英语的翻译。这是因为预训练数据中缺乏低资源语言的数据语料,使得LLM无法有效掌握这些语言的语义知识与语法逻辑。

4、展望
LLM和传统小模型具有各自的优点:LLM可以为各种自然语言处理任务提供统一的解决方案,并能够在零样本和少样本场景下取得有竞争力的表现;而小模型能够部署在资源受限的条件下,可以根据目标任务进行特定的训练或调整,在有充足高质量标注数据的情况下可以获得不错的性能表现。在应用中,可以根据实际情况进行选择,综合考虑标注数据可用性、计算效率、部署成本等多方面因素。
在现实生活中,用户的需求通常较为灵活多变,很多任务的解决方案可能需要多次迭代,LLM为此提供了一种高效的人机协作方式,具有较好的应用前景(如办公助手)。尽管语言模型主要源于传统自然语言处理任务,但随着其相关技术的快速发展,LLM已经能够解决更复杂、更高级的任务,自然语言处理领域的研究范畴也不断被拓宽,研究范式也受到了重要影响。
【推广时间】
AI的三大基石是算法、数据和算力,其中数据和算法都可以直接从国内外最优秀的开源模型如Llama 3、Qwen 2获得,但是算力(或者叫做GPU)由于某些众所周知的原因,限制了大部分独立开发者或者中小型企业自建基座模型,因此可以说AI发展最大的阻碍在于算力。
给大家推荐一个性价比超高的GPU算力平台:UCloud云计算旗下的Compshare算力共享平台,目前注册送20元测试金,可以畅享7小时4090算力,预装了主流的大模型和环境的镜像,开箱即用,非常方便。
