一、etcd概要
1.etcd的简介
在做微服务集群开发时,有很多应用,有很多微服务上下游节点,它们本身需要很多存储配置文件,需要有一个地方来存储这些配置文件,因此诞生了etcd,它本质是为了微服务上下游服务去存储一些配置文件,在修改配置文件可以及时生效到上下游微服务,
etcd主要功能:监听时,省去监听资源的消耗,让监听资源放到其他工作资源上。它本身监听一个对象,在对象发生改变的时候弹出这个对象的变化
etcd其实是etc distribution (分布式数据库)
数据的时效性
监听机制
操作简单
安全
快速
可靠

当你访问api server 和etcd时,本身它们就是支持curl访问API的,etcd本身支持TLS,SSL客户端的双向验证的非对称加密的双向证书验证的方式,数据可以使用https/http, 数据可靠性是使用raft算法保证一致性
2.etcd的主要功能
基于k-v的存储
监听机制
key的过期以及续约机制(响应的服务只需在相应的管道,然后只需要绑定生产者),用于监控和发现

生产者在注册中心注册完就倒计时,如果数据不被及时更新,数据过了30s之后就自动失效了,就默认此服务不可以进行绑定了,然后当消费者去请求消息时,会看具有某一特定消息的对象值,绑定关系的稳定性由租约决定,如果过期了,消费者就会自动去找下一个具有相同值或者namespace、名称、属性相同的对象,监控是只要到期,服务就挂掉了;服务发现是作为注册之后,它的消费者会自动取etcd寻址对象,根据对象的属性去寻找
原子Compare And Swap和Compare And Delete,用于分布式锁和leader选举
CAS:就是当你满足一定条件,然后对其数据做一些操作
3.使用场景
基于键值对的存储,查询反应非常快,应用程序可以 读取和写入数据
较多应用与服务注册与发现,基于key租期续约和服务发现的监控领域
基于监听机制的分布式异步系统
数据库有两种:数据格式工整(mysql),和不要求格式,直接更改yaml,代码频繁变动,数据库结构不固定,中间件etcd, redis
4.键值对存储


总结:存储时,可以是key-value(一个对应关系绑定另一个对应关系),也可以是对象名-对象,而一个字符串string必须绑定另一个字符串string
当这个对象发生变化时,etcd直接弹出一个值,就代表你要消费信息了 ,二叉树,左边存key,右边存value,根据索引查询对应的键值对
5.服务注册和发现

6.消息发布与订阅

本质:生产者和消费者建立了长连接
7.部署etcd
Releases · etcd-io/etcd · GitHub
在实例中,直接使用以下命令去启用etcd
etcd --listen-client-urls 'http://localhost:12379' \
--advertise-client-urls 'http://localhost:12379' \
--listen-peer-urls 'http://localhost:12380' \
--initial-advertise-peer-urls 'http://localhost:12380' \
--initial-cluster 'default=http://localhost:12380'
etcd部署
服务调度优先级、服务访问优先级,对内采用peer端口进行通信,对外采用client端口通信
没搭k8s,可以用以下二进制进行搭建etcd

8.etcd练习

etcd member list --write-out=table --endpoints=localhosts:port
etcdctl --endpoints=localhost:12379 put /key1 val1
etcdctl --endpoints=localhost:12379 put /key2 val2
etcdctl --endpoints=localhost:12379 get --prefix /
etcdctl --endpoints=localhost:12379 get --prefix / --keys-only
etcdctl --endpoints=localhost:12379 watch --prefix /
etcdctl --endpoints=localhost:12379 put /key val1
etcdctl --endpoints=localhost:12379 put /key val2
etcdctl --endpoints=localhost:12379 put /key val3
etcdctl --endpoints=localhost:12379 put /key val4
etcdctl --endpoints=localhost:12379 get /key -wjson
etcdctl --endpoints=localhost:12379 watch --prefix / --rev 0
etcdctl --endpoints=localhost:12379 watch --prefix / --rev 1
etcdctl --endpoints=localhost:12379 watch --prefix / --rev 2
数据写入操作测试


9.TTL能力(信息的生命周期)
给一个key设置一个有效期,到期后这个key就会被自动删除掉,这在很多分布式的锁的实现上会用到,可以保证所得实时有效性

10.CAS

数据一致性,基于原子的
数据修改+条件触发是同一时间的,无延时
关于zookeeper存储键值对这种场景
判断键值是否符合规则,合规 才进行存储,不合规则不进行存储。当一个键过来时,首先判断,这时候已经有其他的键过来将同样的key占用了,人家数据比较新,但此时已经判断完成,所以把这个后面数据漏了,所以把旧的数据掩盖了,如果加锁,互斥锁,性能变低;乐观锁,容易导致数据落盘混乱错误,最好办法是拿的时候锁住,拿完之后解开
etcd的优点:判断和落盘是同时发生的,提高性能的同时,避免由于判断失误,导致落盘失误,得提前知道落盘的key是多少,才能设置
二、raft协议
1.理解raft

此图提取自raft协议的论文
http://thesecretlivesofdata.com/raft/
etcd内部有一个一致性模块,所有节点,不论是谁,先接触的消息,缓存完之后交给一致性模块处理,处理完之后,一致性模块做两个事情:第一在多个集群中,将你推送的key-value推送到集群中,同时会将日志信息放到日志模块中,然后日志模块中的信息达到一定水位线之后,push到状态机,在状态机中查看你是否落盘
raft算法三个基本角色:
follower、leader、candidate
其中所有节点默认处于follower状态,只有它接受不到leader请求的时候,才会变为candidate,candidate在发完投票,并且在获得投票之后,会给自己的tearm+1,从此变成一个leader,要么变成一个leader、要么没被选上变成一个follower
2.learner

leader就是把etcd往进加 member add --leader的时候,加进去之后,这个节点处于一个可读可写,但是不可参加选举的状态,知道他们里面的数据量和其他节点处于同步状态的时候,这样它才能成为一个正式的可被投票选举的状态,加入的时候以leader形式加,后面同步的时候再设置member
3.思考
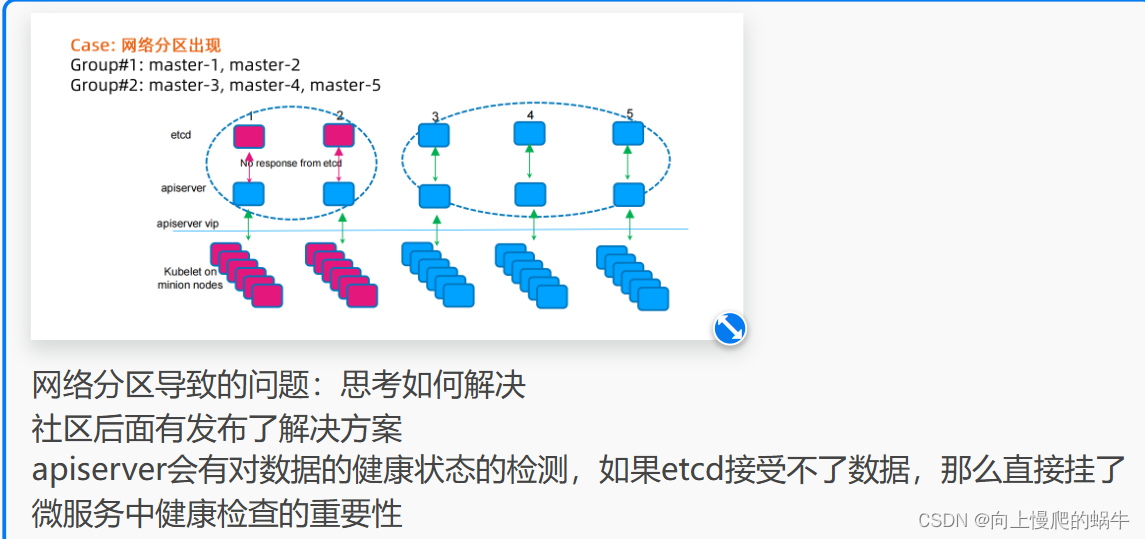
三节点的集群中,leader挂了会发生什么
三节点的集群中,如果因为网络波动出现了两个leader会发生什么,脑裂现象

三、etcd如何实现raft协议
1.选举方法


2.日志复制

当leader接收到ack之后,数据一致性模块中,收到的数据确认请求数+1, 这个数>n/2+1时,这个数就会被提交并且追加到本地磁盘中
3.安全性

term选举新的任期,必须包含前几个任期,如果不包含前几个任期,就不配成为新的任期
4.失效处理

5.wal日志

index是多数数据进行同步时,新的数据 进来会更新你的index信号,index属于一直递增的状态,通过index这个值去确定数据是否是最新的状态

etcd-dump-logs是将你的日志从你的存储目录中down下来
6.etcd v3存储机制,watch以及过期机制
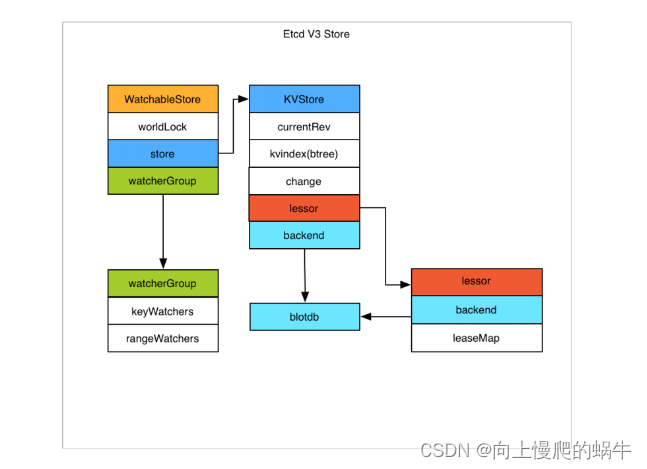
图解:
当数据过来时,会进入一个kvstore,这会有个缓存, 缓存之后是其前端,后端是blotdb(谷歌开源数据库),往左边有一个watchablestore,它是用来将数据down下了之后,进行数据监控的,当数据发生变化后,watch是有感知的,然后它会将其变化的数据推送出去,数据要进行等待和验证,验证之后才会到blotdb,这个数据库可以换成任何一种开源的数据库
前端kv是用来做索引的
boltDB是google开源的一个k-v数据库
来数据了会同时进入kvstore和通过boltDB落盘
watchablestore是负责监听某个对象的事件
backend是可以对接多种类型的数据库的,目前使用的是boltDB
存储机制:

 打印数据的细节
打印数据的细节
etcdctl --endpoint=xxxx:xx get /key1 -wjson
reversion概念
一个自增长的值,任何修改都会使得该值增加,当作数据修改的时候,会护法
事务机制
main revision
sub revision
7.etcd数据存储流程

限制包大小,就是限制提交yaml文件的大小 ,然后将数据丢到一致性模块中进行选主,如果是主,继续往下进行,如果不是主,存一条日志,然后返回,在下一次心跳的时候告诉master;确认是主的话,在同步日志的时候,会进行一个raft暂存,暂存之后,然后再日志模块中写入这条日志,选择x为3、y为1或者9,进行数据存储的暂存,同时如果你不是主,在暂存同时,要把这条消息发给leader,如果是主,发出的信息就是日志确认的信息;这条日志通过心跳发送出去,其他节点通过心跳回馈给你的leader,对这一类数据进行同步,一致性模块就会进行检查,是否通过多数选择,如果通过之后,通过MVCC模块会记录并存储这条数据,在内存中正式变更这条数据
过程:
预检查阶段:
配额:etcd有数据大小的配置限制
限速:对写请求限制
鉴权:有没有写的权限
包大小限制:超过1.5M则拒收,因为要多次确认,包大则效率低
KVserver检查
一致性模块
选主 日志复制
构建raftlog,然后数据存储到unstable层,同时给同步到wal日志模块
wallog日志模块是要落盘的,通过fsync周期性的同步至硬盘
写wallog的同时,会有另外的goroutine将消息同步给其他的follower做一次message append
其他的follower写了wallog后,则回消息(message append response)给leader这边
leader这边在走一致性模块,确认了是有半数以上的同意写入,他就认为这条数据已经commit了
然后更新matchIndex,同时一致性模块中这条数据走到了committed,commited同时以apply的方法请求状态机来记录这次数据
状态机基于MVCC机制(多版本并发控制的模块),这个里面维护了treeIndex和BoltDB
在treeIndex模块中,key保存了k的信息,但是value没有保存实际的值,保存的是和这个值有关的所有数据版本信息
modified 最后一次变更信息
generation 记录了版本 /代/历史信息
落盘之后
key是revision,value变成了k-v的具体信息(变更的整个信息,和版本对应)
对一个key的完整的生命周期的变更
8.etcd的数据一致性

任期变化,怎么发生了变化
matchIndex和index的区别是什么
这个重新选举的过程中成为leader的优先级如何判定
9.watch的机制
key watchers
模糊匹配来查询,range watchers
通过watchableStore开辟内存空间来满足这些watch需求
synced不带revision信息,能直接给
unsynced,带revision信息,得查盘,所以放到unsynced中,等backend的数据同步到内存中,在给丢到synced,在同步数据


10.etcd的相关操作
a 起一个etcd
b watch一个key
c 一直更新这个key
多版本的练习
get /key --rev=n
watch /key --rev=n


四、etcd的高可用集群理论
1.成员相关参数
名字,默认default
落盘的位置,默认./default.etcd
member之间的通信peer-url
client来的通信client-url


2.安全相关参数

3.灾备
通过peer指定的多member的集群,容灾一台服务器崩溃
如果极端情况出现
比如calico的cni插件保存的ip信息如果崩溃了会怎么样
因此需要经常做备份/快照
做在灾备实验
物料在gitee中

4.碎片整理

5.容量管理
单个对象大小不建议超过1.5m
默认容量为2g
不建议超过8g

出现alarm,etcd不可以在存储数据,需要进行处理,一般是进行碎片整理

五、etcd生产集群管理
1.高可用的etcd解决方案

kubelet会扫描本地的目录,然后kubeadm可以把扫描的etcd的pod数据放进去,从而起一个etcd
kubernetes on kubernetes

基于bitnami安装etcd的高可用集群

每半个小时做snapshot,每半个小时做一个event
所有服务通过API server(冗余部署)去访问etcd,API server就是restserver,其里都是缓存机制
进行压测etc发现300台是3个节点, 1000是5,当节点数据变多,为了保持数据同步,需要同步的资源变多,多数反应需要3个节点
2.k8s如何使用etcd
每个模型都定义了storage.go,决定的事这个代码如何存储
kbernetes对象在etcd中的存储路径
k get的时候实际上就是发送了一个curl get命令

etcd在集群中所处的位置

3.k8s堆叠部署etcd集群
堆叠etcd,就是每个master上有一个etcd,kubelet自己管理
kubelet会扫描mainfests有没有相关的yaml文件,如果有的话则会直接拉起来
这种情况下所有的数据都是直接通过loopback接口来访问的,读操作不经过网络非常轻便
核心组件放到一起很好管理和维护,效率更高
etcd重落盘,对落盘有要求,但是刚好其他的组件不要求磁盘io
如果master太小的话可以用这种方式

etcd集群高可用数量问题
1个性能最好,但是一点容错都没
3个性能还行,但是有点费运维
5个性能比较差,运维可能好受点,睡一觉起来在修也行
etcd横向的动态的扩缩容还是很麻烦的

grpc协议,http2.0 多路复用
故障分享

4.etcd的存储规划
备份出来的数据给哪里,网盘吗(依赖于网络,虽然安全,但是网络一抖就出问题)
能不能让大部分的member存储到他们本地,但是有一个member上来listen
做listen的会一直掉队
都存到本地,然后定期remote
确保local io
空间规划
为什么同样的数据,不同的member的数据他们存储的数据不一样呢
保证认证鉴权的安全性,包括通信加密
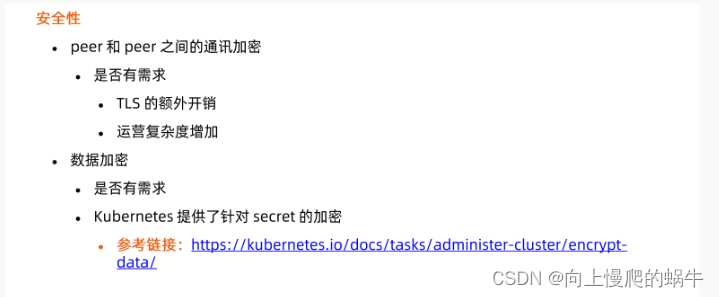
有的对象是纯粹做审计的,丢了也没啥大影响
所以允许在apiserver里面定义允许起一个etcd的instance,把一些对象扔进去

国内50ms,跨洲400ms,etcd有各种超时限制,所以尽量同区域部署
并发过多的时候可能会把peer的通信挤掉,所以可以通过pc的命令做网络调优,保证优先级



设置合理的存储配额,控制在8个g,一定要及时维护,避免出现alarm

自动压缩历史版本

定期消除碎片化

优化运行参数,如健康心跳的周期,选举超时的时间,配合使用
心跳周期应当是选举参数的10倍(根据大量生产经验得出的最佳实践方案,也是etcd的默认)



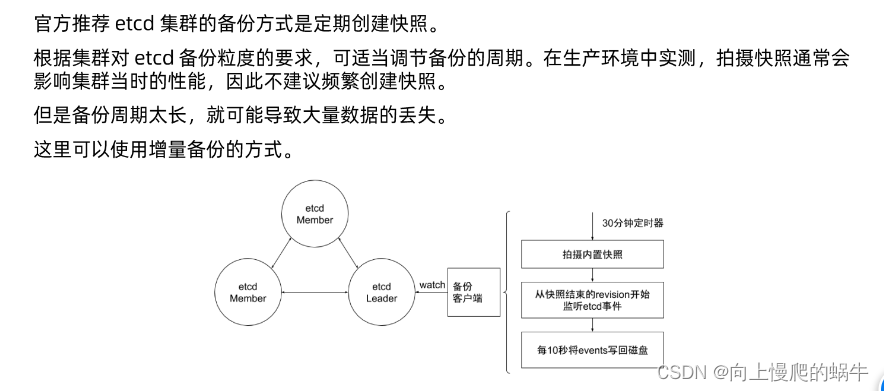
备份方案实践(社区实践版本的增强,非权威流行方式)
30snapshot,期间记录revision,然后每10s重新写回磁盘一次
六、etcd的常见问题
1.数据备份方案
snapshop好处和缺点
其他方法,watch kubenetes/etcd event
只能拿下来pod的spec 拿不到status
所以建议event结合snapshot


2.数据加密方案

 任何对象存储的时候,都带着一个resourceVersion
任何对象存储的时候,都带着一个resourceVersion
可以指定一个版本,从某个版本开始watch
这个时候拿到的数据,只要没compact,就是该对象从某个版本开始变动的所有信息

分页查询
etcd里面数据有时候存的是非常多的,所以这种时候全量查询就很无奈
比如远端cat了一个几百m的binary
所以查询数据库最好不要全量返回
k8s有限制,默认只给你返回500个,然后返回的list中会有一个continue的tocken,然后拿着这个tocken才能接上下来的数据
新的里面如果500不完就在给一个tocken

3.resourceVersion
resourceVersion每个list都有,但是不可能重复
resourceVersion是集群维护的,自增长的
在回顾乐观锁 乐观锁修改失败的一方返回409 conflict
然后list行为,list对象的时候,如果不加resourceVersion,那就意味着不相信apiserver的cache,该请求会直接击穿apiserver直接到etcd
label的查询是通过apiserver做的,etcd没有这个能力

4.遇到的问题
这些事生产实践中遇到的陷阱,这些路是行不通的
频繁的 leader election
etcd 分裂
etcd 不响应
与 apierver 之间的链路阻塞
磁盘暴涨

这个是测试中遇到的问题
故意的把控制面上遭一些故障出来,然后来看看控制面的集群会不会出问题
这些事情相对于现在来说可能属于比较早期的内容了(21--22年左右),社区可能已经将这些问题修复了,分享出来是提供一些问题解决的思路/方案