
8.1 预训练语言模型BERT——预训练语言模型 BERT
第6章介绍了以Word2Vec为代表的传统词向量学习方法,本质上这是一种静态的词向量表示方法,即在训练完成之后,词向量不会随着语境进行相应变化,例如,"这类桃子水分很足"和"他的话有很多水分",对于"水分"这个词,在这两句话中明显有着不同的语义,但是静态词向量是固定的,不会随着语境进行变化。
鉴于此,后续逐步出现了动态词向量的算法,其中比较早期算法是ELMO模型,其根据上下文实时计算,从而动态生成单词的词向量。近年来,以BERT为代表的模型吸取了ELMO模型的思路并异军突起,其通过在大规模文本上进行预训练,学到了很好的语言知识,能够更好地进行词向量表示,当前已经成为主流的文本表示模型。
1. 预训练模型是什么
在正式讲解之前,我们先来了解一下什么是预训练模型。从字面上看,预训练模型(pre-training model)是先通过一批语料进行训练模型,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。这样的理解基本上是对的,预训练模型的训练和使用分别对应两个阶段:预训练阶段(pre-training)和 微调(fune-tuning)阶段。
预训练阶段一般会在超大规模的语料上,采用无监督(unsupervised)或者弱监督(weak-supervised)的方式训练模型,经过大规模语料的”洗礼”,预训练模型能够学习到语言相关的知识,比如句法,语法知识等等。
微调阶段是利用预训练好的模型,去定制化地训练某些任务,使得预训练模型”更懂”这个任务。例如,利用预训练好的模型继续训练文本分类任务,将会获得比较好的一个分类结果,直观地想,预训练模型已经懂得了语言的知识,在这些知识基础上去学习文本分类任务将会事半功倍。利用预训练模型去微调的一些任务(例如前述文本分类)被称为下游任务(down-stream)。
预训练模型极大地推动了自然语言处理领域的发展,推动了自然语言处理任务不断达到更好的效果,并开启了自然语言处理任务的训练新范式:预训练+微调。
2. BERT 网络结构
近年来,基于Transformer结构的模型大放异彩,基于Transformer结构Encoder或Decoder结构设计的预训练模型不断被提出,特别是在2018年预训练模型BERT的提出,其在多项NLP任务上均取得了突破性的进展,具有里程碑式的意义。自此,不管是学术界,还是工业界均掀起了基于Transformer的预训练模型研究和应用的热潮,并且逐渐从NLP延伸到CV、语音等多项领域。
BERT(Bidirectional Encoder Representations from Transformers)以Transformer Encoder为网络基本组件,如图2.1 所示,其中每层的Encoder Layer的模型细节同Transfomer Encoder Layer是一样的,这部分内容在《Transformer网络结构》一节中已经详细讲过,这里不再赘述。
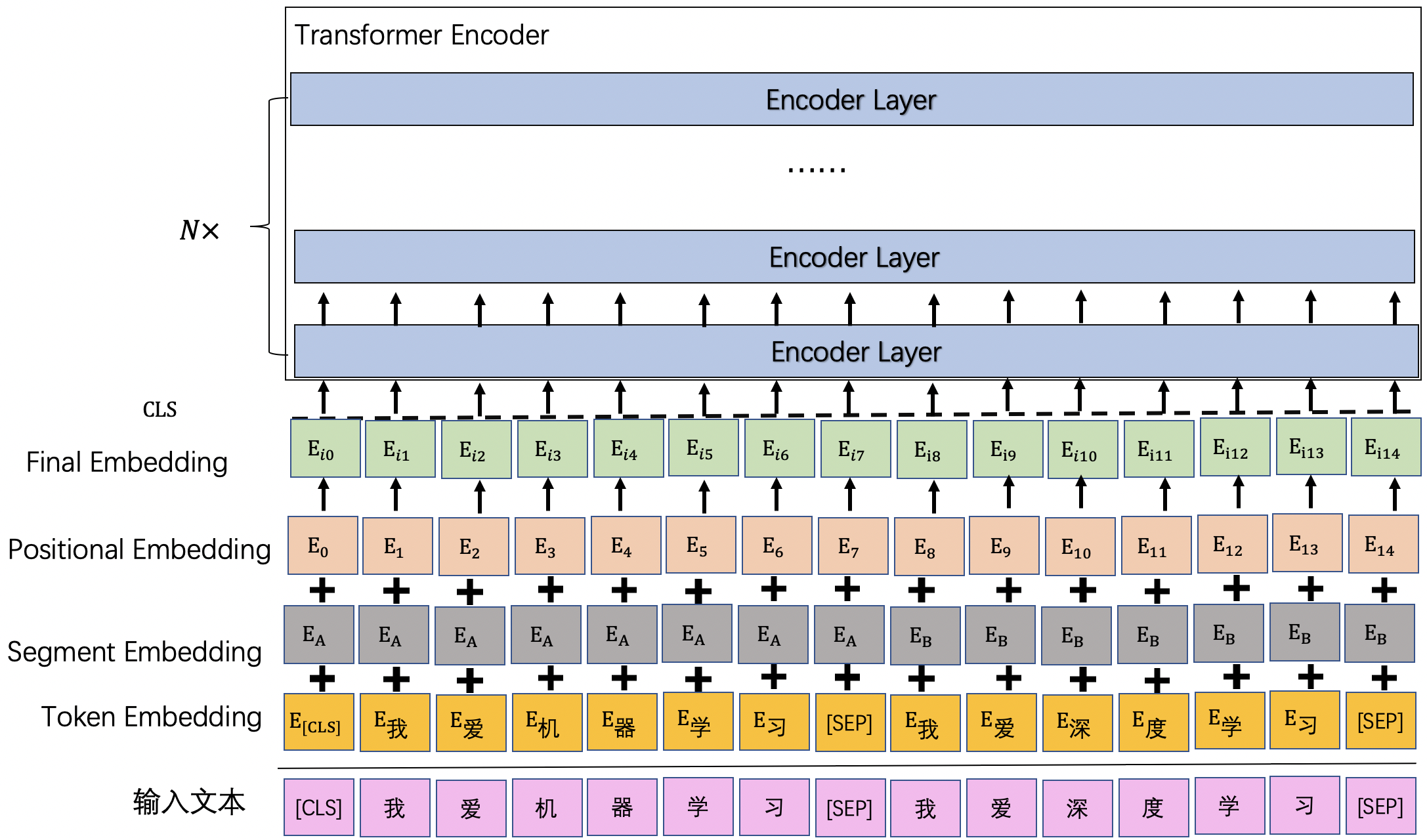
图 2.1 Bert网络结构
下面,BERT同原始Transformer Encoder不同的地方主要聚焦于嵌入层。下面我们来进一步看一下。
2.1 引入更多项 Embedding类型
从图2.1可以看到,相比于Transformer,BERT模型的嵌入层多了一个分段编码(Segment Embedding)。即BERT的输入Embedding是由三部分相加获得:token编码(Token Embedding)、分段编码(Segment Embedding)、位置编码(Positional Embedding)。
2.1.1 token编码
token编码(Token Embedding)是指将输入的文本经分词后,将分词后的每个token映射为对应的词向量,该项编码能够表示Token本身的语义信息。其可以按照如下方式进行初始化:
class paddle.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, sparse=False, weight_attr=None, name=None)
关键参数含义如下:
- vocab_size: 词表中的单词数量。
- emb_size: 词向量的维度。
- padding_idx: 如果配置padding_idx,在训练过程中遇到此id时,其参数及对应的梯度将会以0进行填充。
2.1.2 位置编码
BERT模型基于Transformer Encoder部分的模型结构构建的,因此BERT模型同样不具有RNN模型那样表示顺序的能力。引入需要通过位置编码(Positional Embedding)为各个token引入对应的位置信息。
但与Transformer不同的是,BERT模型的位置编码初始化并不是按照三角函数进行初始化的,而是将位置编码作为可学习的参数,使用paddle.nn.Embedding初始化位置编码。
2.1.3 分段编码
BERT模型支持同时输入多个语句,从而建模语句级别的任务,例如用于判断两句话是否相似的文本匹配任务。多个语句之间是通过拼接成一段话输入至BERT模型的,因此可以通过引入一个新的编码:分段编码(Segment Embedding)用于标记输入句子,帮助模型区分输入的不同句子。
例如在图2.1中,用A表示第一个句子,用B表示第2个句子,则会用分段编码E_A表示标记句子A,E_B表示标记句子B。 其同样可以使用paddle.nn.Embedding进行初始化。
在分别获取token编码、位置编码和分段编码后,将这三者进行相加获取最终的输入向量,此时该向量即同时包含了这三者的信息,能够帮助BERT模型更好地进行建模NLP任务。
2.2 输入句子的形式
BERT模型支持输入1到多个句子,从而进行不同的任务,但输入的语句默认需要遵循一定的规则。图2.2展示了BERT模型在输入1条语句和2条语句时的输入形式。默认情况下,语句开头需要拼接一个[CLS]token,不同的句子中间需要用[SEP]token进行拼接。
一般情况下,[CLS]位置输出的向量能够通过自注意力的结构学习到整个句子的语义,所以其可以被视为输入语句的语义向量,基于该向量可以进行不同的下游任务,例如文本分类。

图 2.2 Bert模型输入形式