
文章信息

论文题目为《Spatial-Temporal Large Language Model for Traffic Prediction》,文章来自ICLR 2024,是一篇交通预测领域论文,文中提出了一种新颖的空间-时间大型语言模型(ST-LLM)用于交通预测,它将位置上的时间步长定义为一个token,并通过空间-时间嵌入层对每个token进行嵌入。文中将这些token的空间-时间嵌入均匀地融合,并调整了LLM以捕获全局空间-时间依赖关系。本文通过在大量真实交通数据集上进行实验,实验结果表明,本文的交通预测模型取得了良好的效果,展示了本文的ST-LLM在各种设置下取得的卓越性能。此外,少样本和零样本预测结果突显了ST-LLM在域内和跨域知识转移方面的能力。

摘要

交通预测是智能交通系统的重要组成部分,它努力使用历史数据以预测特定位置的未来交通特征。虽然现有的交通预测模型往往强调发展复杂的神经网络结构,其精度没有得到提高。最近,大型语言模型表现出色时间序列分析能力。与现有模型不同,LLM主要通过参数扩展和扩展预训练来实现,同时保持其基本结构。受这些发展的启发,我们提出了一种时空用于交通预测的大型语言模型(ST-LLM)。在ST-LLM中,我们将每个位置的时间步长定义为token,设计一个时空嵌入来学习空间位置以及这些token的全局时间模式。此外,我们通过融合卷积将这些嵌入整合到每个嵌入中用于统一时空表示的token。此外,我们创新了一种部分冻结的注意力策略,以适应LLM捕捉流量的全局时空依赖关系。我们在真实交通数据集上进行综合实验,实验结果表明ST-LLM是一种强大的模型,其表现优于最先进的模型。值得注意的是:ST-LLM在小样本和零样本两种情况下也表现出强劲的性能。

贡献

(1)本文提出了一种用于交通预测的时空大语言模型(ST-LLM),该模型将一个位置上的时间步定义为token,并通过时空嵌入层嵌入每个标记。本文均匀地研究这些标记的时空嵌入,并适应llm以捕获全局的时空依赖性。
(2)在LLM中提出了一种新的策略,称为部分冻结注意力,以增强交通预测中的模型。通过部分冻结多头注意力,ST-LLM适于捕获不同流量预测任务的令牌之间的全局时空依赖关系。
(3)在真实交通数据集上进行了大量的实验,以显示我们的ST-LLM在各种设置下取得的优越性能。此外,少样本和零样本的预测结果展示了ST-LLM进行域内和域间知识转移的能力。

问题定义

定义1(交通特征):本文将交通数据表示为张量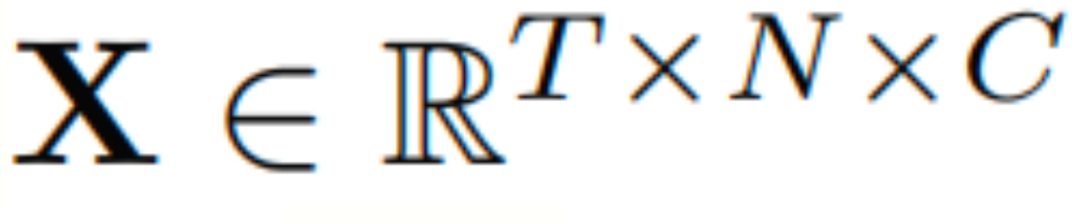 ,其中T是时间步长数,N是站点数量,C是特征。例如,C=1 表示交通流量的进出流量。
,其中T是时间步长数,N是站点数量,C是特征。例如,C=1 表示交通流量的进出流量。
定义2(交通预测):考虑到历史P个时间步长的交通量 ,目标是学习一个参数为θ的函数f(·) 以预测后面S个时间步的流量
,目标是学习一个参数为θ的函数f(·) 以预测后面S个时间步的流量 。如下面公式所示:
。如下面公式所示:
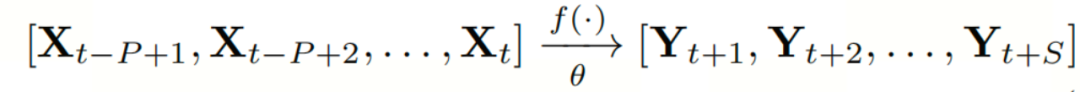

方法

5.1 概况
如图所示为时空大语言模型(ST-LLM)的框架概况,时空大语言模型(ST-LLM)框架集成了时空嵌入层、融合卷积层、LLM层和回归卷积层。开始,历史交通数据表示为XP,其中包含N个空间站点的标记。XP通过时空嵌入层进行处理,从中提取历史P时间步长、空间嵌入和时间嵌入的标记嵌入,分别为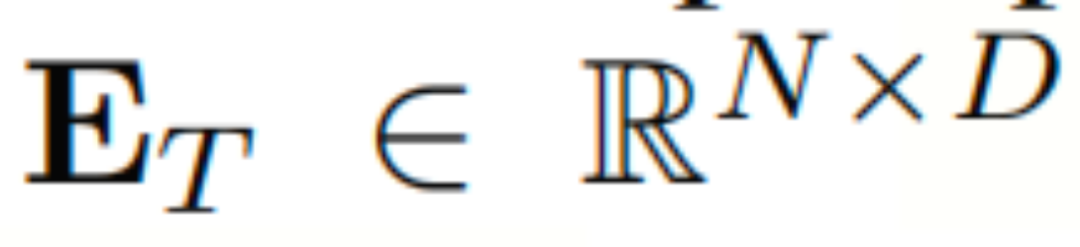 、
、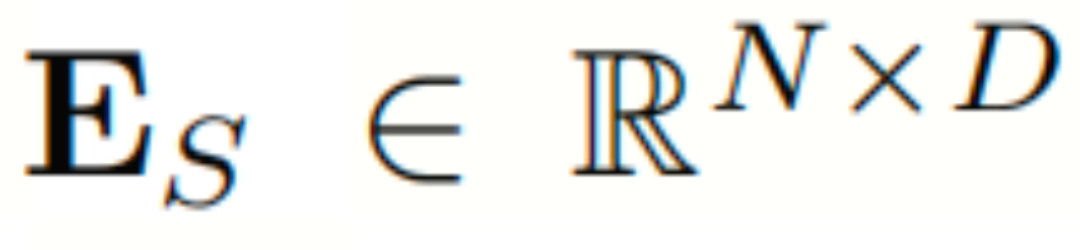 和
和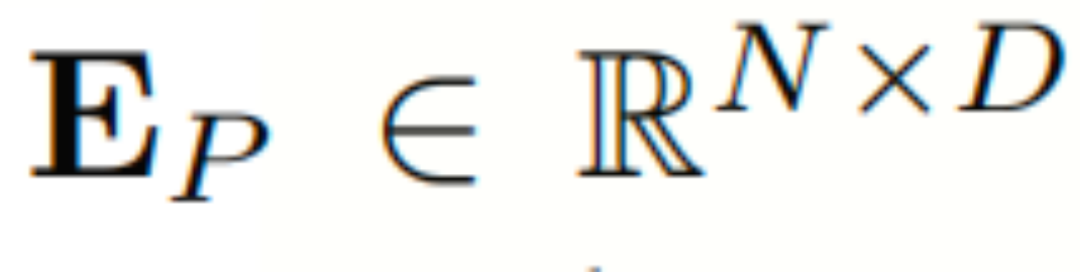 。然后通过一个融合卷积将三个嵌入整合为
。然后通过一个融合卷积将三个嵌入整合为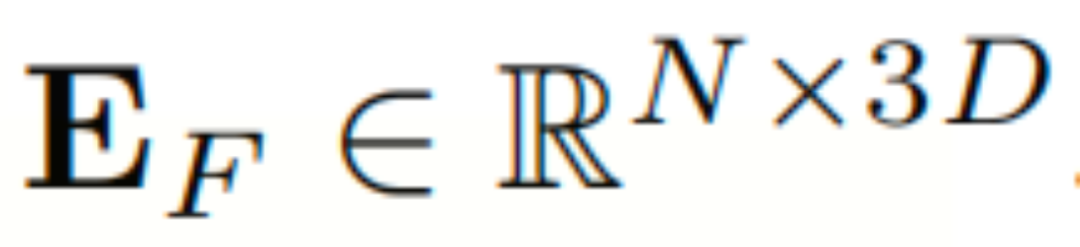 。随后,EF被输入到一个包含L + U层的PFA LLM中,在那里,多头注意力机制和前馈层在前F层中被冻结以保存预先训练好的知识,对最后U层的多头注意层进行解冻结,以增强模型对捕获时空依赖关系能力。最后,通过回归卷积层预测未来的流量数据。
。随后,EF被输入到一个包含L + U层的PFA LLM中,在那里,多头注意力机制和前馈层在前F层中被冻结以保存预先训练好的知识,对最后U层的多头注意层进行解冻结,以增强模型对捕获时空依赖关系能力。最后,通过回归卷积层预测未来的流量数据。
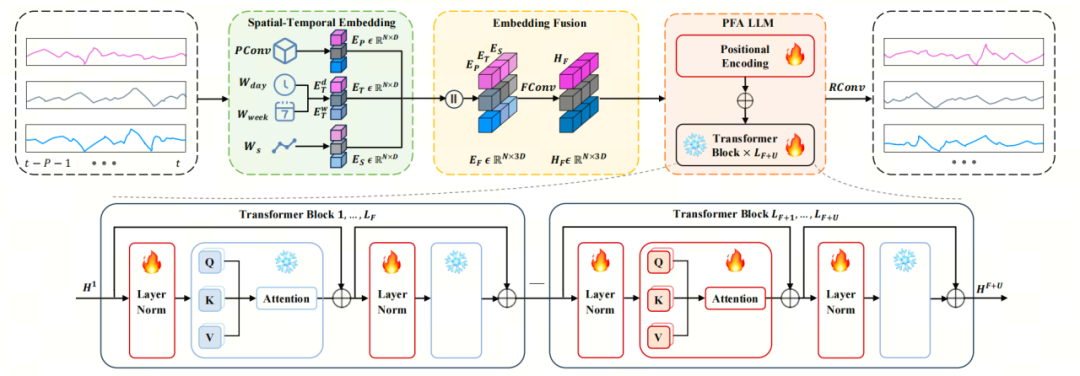
5.2 时空嵌入与融合层
本文的目标是修改已经训练过的交通预测任务的llm。将每个交通数据位置上的时间步长定义为token。时空嵌入层将token转换为与llm对齐的时空表示。这些表示包括空间相关性、周模式、日模式和token信息。
5.2.1 token嵌入
本文通过点态卷积嵌入token,其中输入数据XP被转换为嵌入的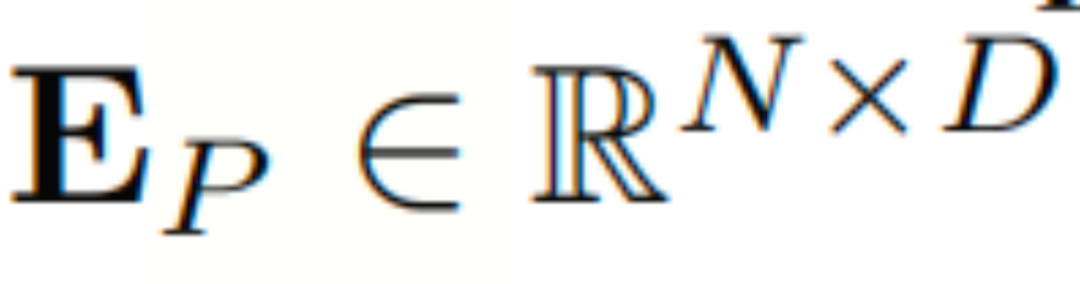 :
:
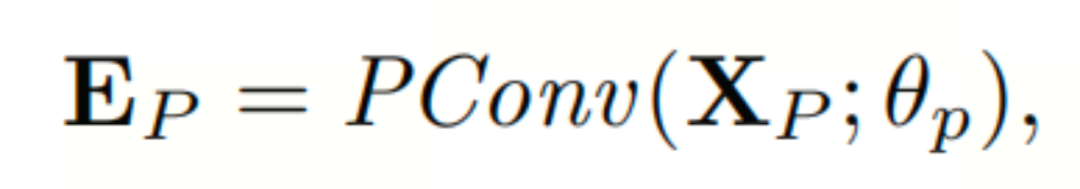
其中,EP表示token嵌入。PConv表示使用核大小为1×1的滤波器的点态卷积操作。XP为输入数据,D为隐藏维度。θ表示点态卷积的参数。
5.2.2 时间嵌入
为了保留token中的时间信息,本文利用一个线性层将输入数据编码到单独的嵌入层中,包括日模式和周模式的时间嵌入。具体如下:
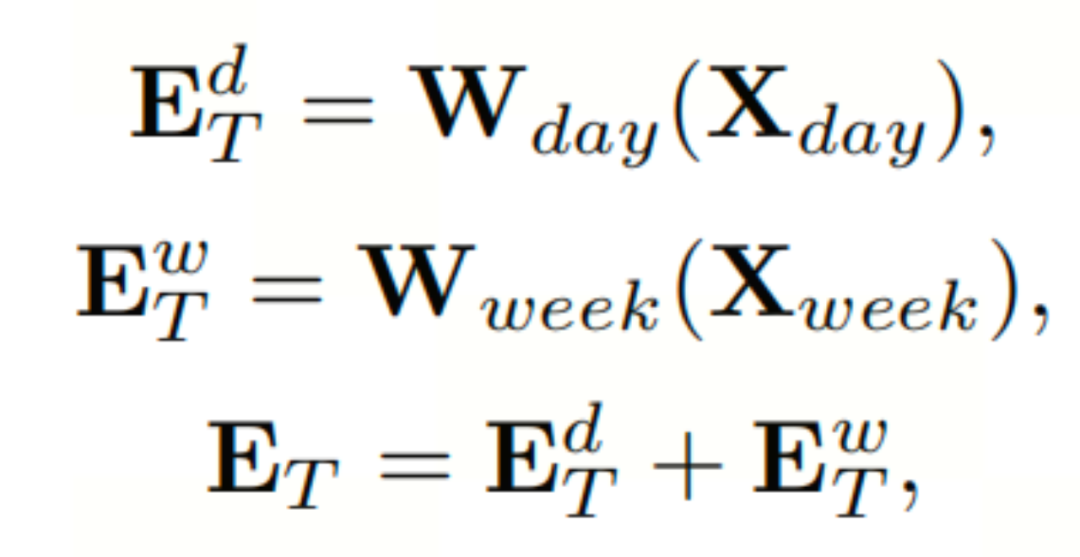
其中,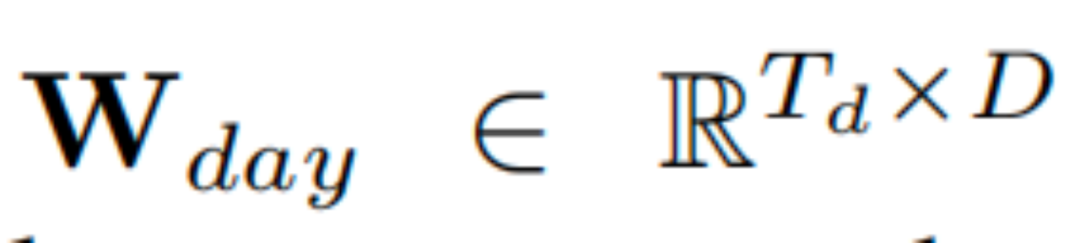 和
和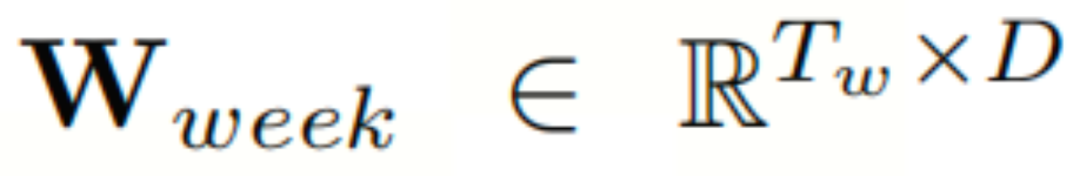 分别为日模式和周模式的可学习参数嵌入。通过添加这两个嵌入,本文得到了时间嵌入
分别为日模式和周模式的可学习参数嵌入。通过添加这两个嵌入,本文得到了时间嵌入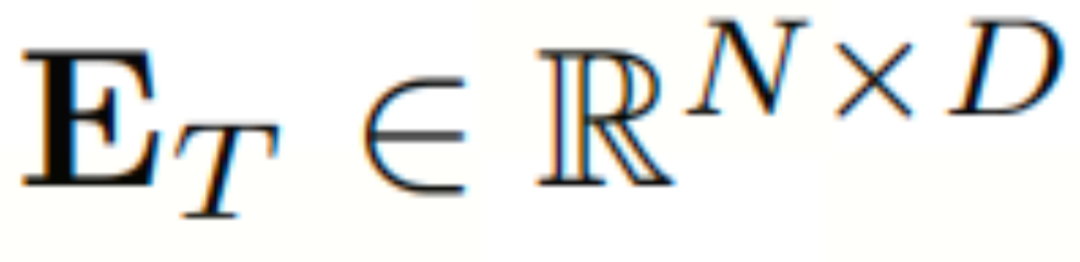 .
.
5.2.3 空间嵌入
为了挖掘token对之间的空间相关性,本文设计了一个自适应的token嵌入,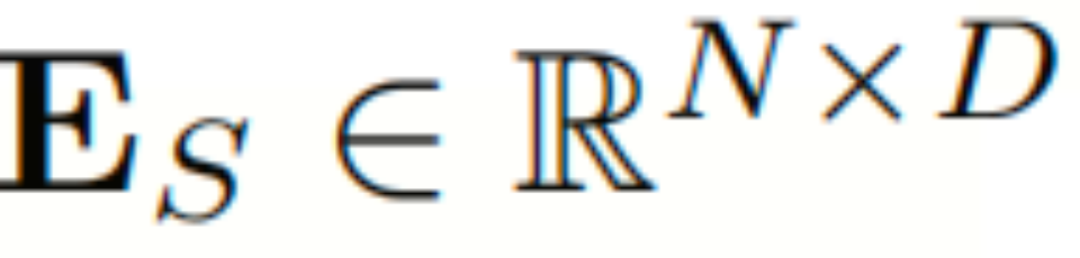 :
:
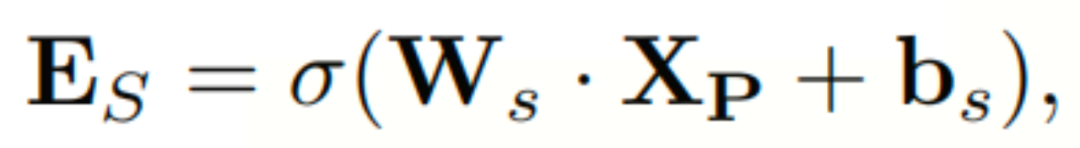
其中σ为激活函数,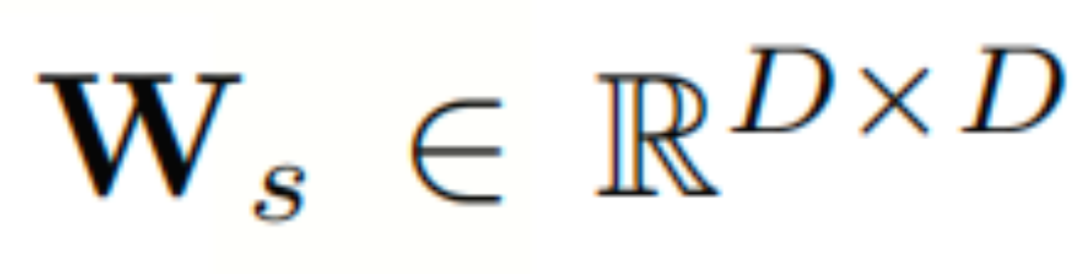 和
和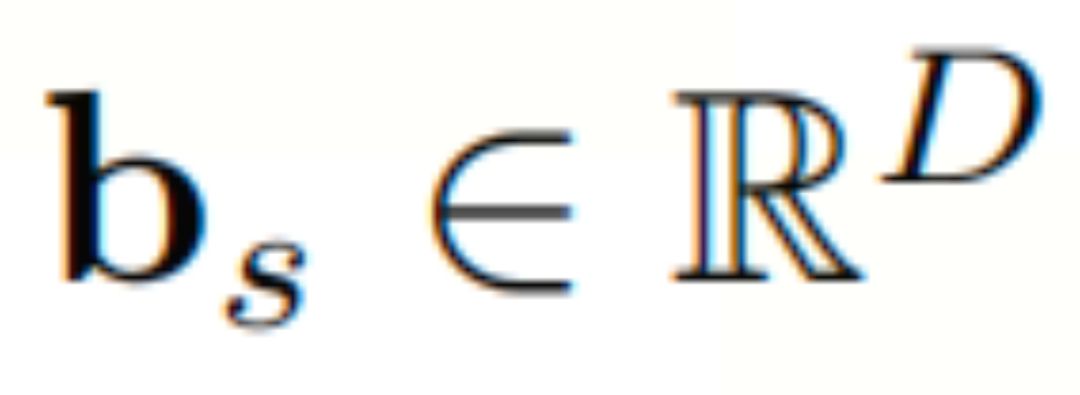 为可学习参数。
为可学习参数。
5.2.4 信息融合
随后,本文引入了一个融合卷积(FConv)来将交通特征投影到LLM的所需维度上。具体来说,FConv集成了token、空间和时间嵌入以一致地表示每个token:
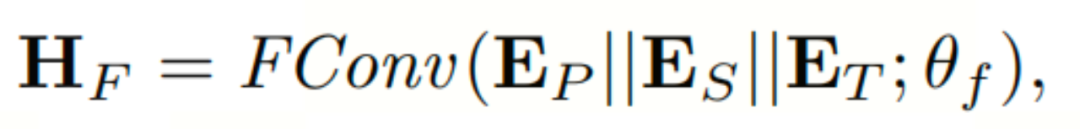
其中,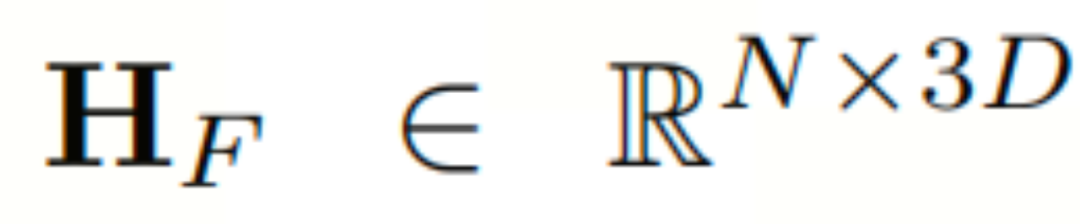 ,||表示连接,θ表示FConv的可学习参数。
,||表示连接,θ表示FConv的可学习参数。
5.3 部分注意力冻结策略
在FPT框架中,多头注意力层和前馈层在训练过程中都被冻结,这些层包含了LLM中学习知识的最重要部分。FPT和本文的PFA之间的区别主要在于冻结的注意层。在PFA中,保持前F层与FPT相同,但最重要的是,本文解冻了后U层的多头注意力层,因为注意层有效地处理了数据中的时空依赖性。因此,本文的PFA LLM可以在保持基础知识的同时适应交通预测在训练前获得。
此外,本文的PFA LLM将传统的计算维数从时间转换为空间。这种反转是有意的,并与部分冻结层的操作相一致。通过焦点在空间维度上,本文的模型比本文只关注时间方面更有效地捕获全局依赖关系。这种转变与交通预测尤其相关在这里,空间动力学在决定流体模式中起着关键的作用。
PFA LLM是使用基于transformer的架构构建的,本文选择了GPT2 。GPT2在很大程度上遵循了OpenAI GPT模型的细节,并进行了一些修改。值得注意的是,归一化层模块化定位于每个子块的输入端,类似于剩余网络中的预激活。此外,在最后的多头注意之后,还添加了一个额外的层标准化。此外,本文引入了一种PFA策略来适应GPT2来捕获融合张量HF的时空依赖性。
在PFA LLM之后,本文设计了一个回归卷积(RConv)来预测以下S个时间步长上的交通量:
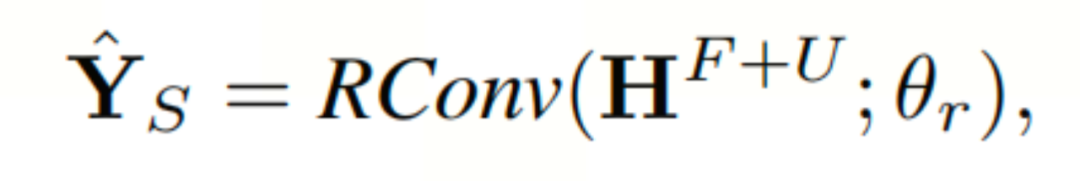
ST-LLM的损失函数建立如下:
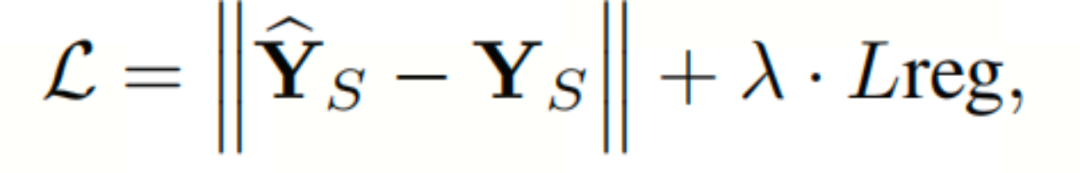

实验

6.1 总体效果
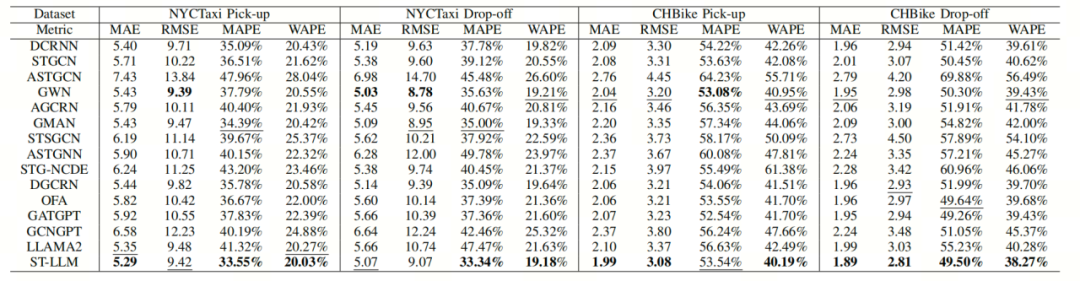
与基线的比较结果见下表。标粗的结果是最好的,带下划线的结果是第二好的。ST-LLM中的LLM是GPT2。本文得到如下结论:(1)基于llm的方法具有优越的预测结果,其中ST-LLM的性能最好。ST-LLM在四个数据集上流量预测效果都优于其他llm (2) OFA和LLAMA2是合格的,但被STLLM超越,STLLM的平均MAE比OFA提高了22.5%,比LLAMA2提高了20.8%。这可能是由于OFA的流量数据嵌入效率低下,使得LLM难以理解数据之间的时空依赖关系。尽管LLAMA2的尺寸和复杂性更大,但它并不能直接转化为比ST-LLM更好的流量预测。GATGPT和GCNGPT不会提取交通数据的时间表示,以影响LLM捕获时空依赖关系。(3)基于注意力的模型,如ASTGNN和GMAN,在不同的数据集上表现出不同的性能。他们在某些情况下表现得很好,但不如ST-LLM。这种可变性可能归因于传统的注意机制在处理复杂的时空嵌入方面的局限性。(4)基于GNN的模型,如GWN和DGCRN,表现出了具有竞争力的性能,特别是在特定的指标方面,但仍然不能超过ST-LLM。这表明,虽然GNN为了捕获空间依赖性,它们的时间分析能力可能没有ST-LLM那样先进,这限制了它们的整体性能。综上所述,实验结果在不同类型的模型之间显示出明显的性能差别。基于llm的方法成为表现最好的方法,展示了它们处理不同交通预测任务的能力。在基于llm的模型之后,基于注意的模型占据了第二。最后,基于GCN的模型虽然仍然有效,但排名较低,与上述模型相比。这个层次结构突出了模型功能的不断发展的格局,基于llm的方法在交通预测任务中处于领先地位。
6.2 消融实验
6.2.1 模型组建消融
ST-LLM由几个关键组件组成,每个组件都有助于其在交通预测中的整体有效性。本节比较ST-LLM各组件变化以证明不同组成部分的有效性。
w/o LLM:删除LLM的ST-LLM的变体。
w/o ST:去掉ST-时空嵌入的llm的变体。
w/o T:去除时间嵌入。
w/o S:去掉了空间嵌入。
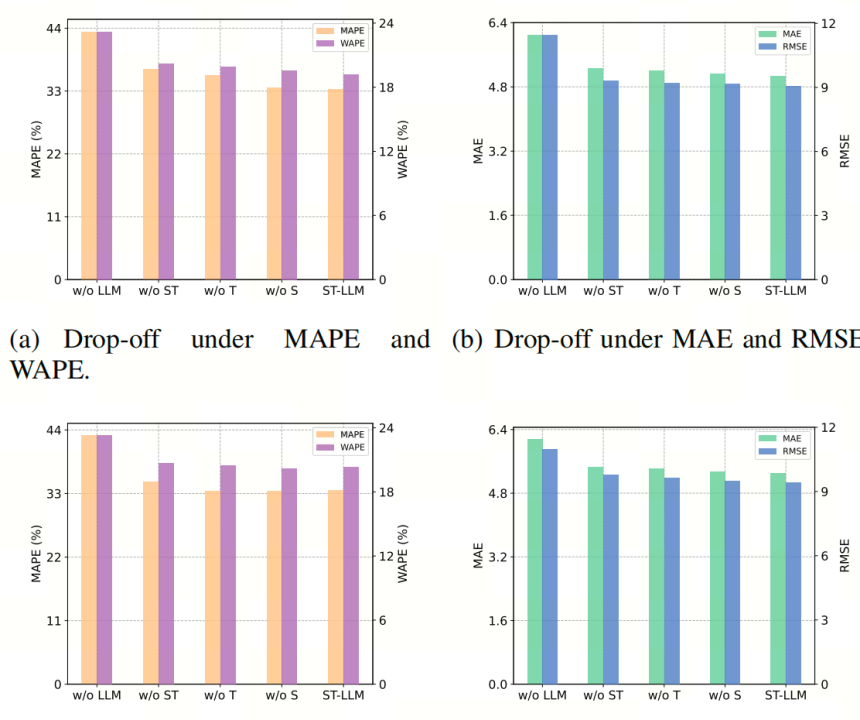
下图展示了在NYCTaxi数据集上的消融实验,分析了ST-LLM模型中不同组件的影响。没有使用LLM的变体(w/o LLM)在所有指标上的误差都有显著增加。移除LLM导致性能下降,表明ST-LLM的预测能力很大程度上依赖于LLM从交通数据中学习复杂依赖关系的能力。
移除时空嵌入(w/o ST)也导致了显著的性能下降,这突显了时空嵌入在理解交通数据中时空依赖关系的重要性。实验结果显示,移除时间(w/o T)或空间(w/o S)组件都会对模型的预测误差产生类似的影响。去掉这些嵌入中的任意一个,都会导致误差增加,表明它们都是准确预测所必需的。特别地,移除时间组件会带来更大的预测误差,这进一步强调了本文精心设计的时间(小时)和周(天)嵌入的重要性。
这一观察进一步说明了平衡的空间和时间嵌入在提升模型预测性能中的关键作用。当所有组件都整合在一起时(即完整的ST-LLM模型),本文在所有指标上都观察到最低的误差率。这表明结合LLM、空间和时间嵌入对于处理交通预测中的时空依赖关系具有显著的效果。
6.2.2 注意力冻结消融
部分冻结注意力LLM的消融实验。在本小节中,本文进行了消融实验,评估本文提出的部分冻结注意力(PFA)LLM的有效性。PFA与几种变体进行了对比:冻结预训练Transformer(FPT)、未使用预训练的模型(No Pretrain)、使用GPT-2全部十二层的模型(Full Layer)以及没有冻结层、完全微调的模型(Full Tuning)。PFA LLM的消融结果展示在下表中。PFA在所有数据集的所有指标上表现出优越的性能,这表明部分冻结注意力显著提升了预测准确性。
虽然FPT表现出较为出色的性能,但仍稍逊于PFA。这表明部分冻结策略在利用预学习特征和适应新数据之间达到了更佳的平衡。Full Layer和Full Tuning模型表现出竞争力,但它们的效率和准确性仍不及PFA模型。这强调了选择性冻结在管理模型适应性方面的优势。
与No Pretrain模型的对比突出了预训练对模型性能的重要性。虽然No Pretrain模型表现得还算不错,但很明显,预训练,特别是结合部分冻结策略,对于实现更高精度至关重要。
