1. 讲讲SVM
1.1 一个关于SVM的童话故事
支持向量机(Support Vector Machine,SVM)是众多监督学习方法中十分出色的一种,几乎所有讲述经典机器学习方法的教材都会介绍。关于SVM,流传着一个关于天使与魔鬼的故事。
传说魔鬼和天使玩了一个游戏,魔鬼在桌上放了两种颜色的球。魔鬼让天使用一根木棍将它们分开。这对天使来说,似乎太容易了。天使不假思索地一摆,便完成了任务。魔鬼又加入了更多的球。随着球的增多,似乎有的球不能再被原来的木棍正确分开,如下图所示。

SVM实际上是在为天使找到木棒的最佳放置位置,使得两边的球都离分隔它们的木棒足够远。依照SVM为天使选择的木棒位置,魔鬼即使按刚才的方式继续加入新球,木棒也能很好地将两类不同的球分开。
看到天使已经很好地解决了用木棒线性分球的问题,魔鬼又给了天使一个新的挑战,如下图所示。

按照这种球的摆法,世界上貌似没有一根木棒可以将它们 完美分开。但天使毕竟有法力,他一拍桌子,便让这些球飞到了空中,然后凭借 念力抓起一张纸片,插在了两类球的中间。从魔鬼的角度看这些 球,则像是被一条曲线完美的切开了。
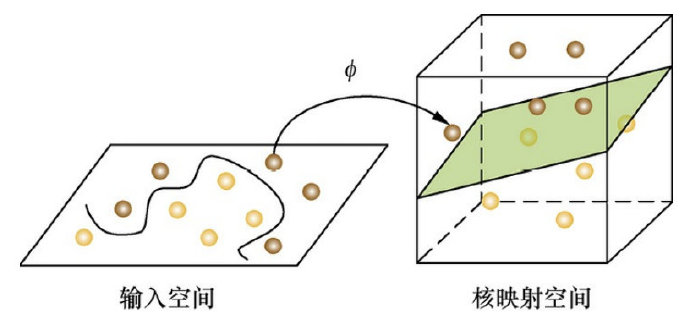
后来,“无聊”的科学家们把这些球称为“数据”,把木棍称为“分类面”,找到最 大间隔的木棒位置的过程称为“优化”,拍桌子让球飞到空中的念力叫“核映射”,在 空中分隔球的纸片称为“分类超平面”。这便是SVM的童话故事。
1.2 理解SVM:第一层
支持向量机,因其英文名为support vector machine,故一般简称SVM,通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
线性分类器:给定一些数据点,它们分别属于两个不同的类,现在要找到一个线性分类器把这些数据分成两类。如果用x表示数据点,用y表示类别(y可以取1或者0,分别代表两个不同的类),一个线性分类器的学习目标便是要在n维的数据空间中找到一个超平面(hyper plane),这个超平面的方程可以表示为( wT中的T代表转置):

这里可以查看我之前的逻辑回归章节回顾:点击打开
这个超平面可以用分类函数  =w^Tx+b)表示,当f(x) 等于0的时候,x便是位于超平面上的点,而f(x)大于0的点对应 y=1 的数据点,f(x)小于0的点对应y=-1的点,如下图所示:
=w^Tx+b)表示,当f(x) 等于0的时候,x便是位于超平面上的点,而f(x)大于0的点对应 y=1 的数据点,f(x)小于0的点对应y=-1的点,如下图所示:

1.2.1 函数间隔与几何间隔
在超平面wx+b=0确定的情况下,|wx+b|能够表示点x到距离超平面的远近,而通过观察wx+b的符号与类标记y的符号是否一致可判断分类是否正确,所以,可以用(y(w*x+b))的正负性来判定或表示分类的正确性。于此,我们便引出了函数间隔(functional margin)的概念。
函数间隔公式: 
而超平面(w,b)关于数据集T中所有样本点(xi,yi)的函数间隔最小值(其中,x是特征,y是结果标签,i表示第i个样本),便为超平面(w, b)关于训练数据集T的函数间隔:

但这样定义的函数间隔有问题,即如果成比例的改变w和b(如将它们改成2w和2b),则函数间隔的值f(x)却变成了原来的2倍(虽然此时超平面没有改变),所以只有函数间隔还远远不够。
几何间隔
事实上,我们可以对法向量w加些约束条件,从而引出真正定义点到超平面的距离--几何间隔(geometrical margin)的概念。假定对于一个点 x ,令其垂直投影到超平面上的对应点为 x0 ,w 是垂直于超平面的一个向量, 为样本x到超平面的距离,如下图所示:

这里我直接给出几何间隔的公式,详细推到请查看博文:点击进入
几何间隔: 
从上述函数间隔和几何间隔的定义可以看出:几何间隔就是**函数间隔除以||w||*,而且函数间隔y(wx+b) = y*f(x)实际上就是|f(x)|,只是人为定义的一个间隔度量,而几何间隔|f(x)|/||w||才是直观上的点到超平面的距离。
1.2.2 最大间隔分类器的定义
对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度(confidence)也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个间隔就是下图中的Gap的一半。

通过由前面的分析可知:函数间隔不适合用来最大化间隔值,因为在超平面固定以后,可以等比例地缩放w的长度和b的值,这样可以使得 =w^Tx+b)的值任意大,亦即函数间隔可以在超平面保持不变的情况下被取得任意大。但几何间隔因为除上了,使得在缩放w和b的时候几何间隔的值是不会改变的,它只随着超平面的变动而变动,因此,这是更加合适的一个间隔。换言之,这里要找的最大间隔分类超平面中的“间隔”指的是几何间隔。
如下图所示,中间的实线便是寻找到的最优超平面(Optimal Hyper Plane),其到两条虚线边界的距离相等,这个距离便是几何间隔,两条虚线间隔边界之间的距离等于2倍几何间隔,而虚线间隔边界上的点则是支持向量。由于这些支持向量刚好在虚线间隔边界上,所以它们满足 ,对于所有不是支持向量的点,则显然有
 。
。

OK,到此为止,算是了解到了SVM的第一层,对于那些只关心怎么用SVM的朋友便已足够,不必再更进一层深究其更深的原理。
1.2.3 最大间隔损失函数Hinge loss
SVM 求解使通过建立二次规划原始问题,引入拉格朗日乘子法,然后转换成对偶的形式去求解,这是一种理论非常充实的解法。这里换一种角度来思考,在机器学习领域,一般的做法是经验风险最小化 (empirical risk minimization,ERM),即构建假设函数(Hypothesis)为输入输出间的映射,然后采用损失函数来衡量模型的优劣。求得使损失最小化的模型即为最优的假设函数,采用不同的损失函数也会得到不同的机器学习算法。SVM采用的就是Hinge Loss,用于“最大间隔(max-margin)”分类。

-
对于训练集中的第i个数据xi -
在W下会有一个得分结果向量f(xi,W) -
第j类的得分为我们记作f(xi,W)j
要理解这个公式,首先先看下面这张图片:

-
在生活中我们都会认为没有威胁的才是最好的,比如拿成绩来说,自己考了第一名99分,而第二名紧随其后98分,那么就会有不安全的感觉,就会认为那家伙随时都有可能超过我。如果第二名是85分,那就会感觉安全多了,第二名需要花费很大的力气才能赶上自己。拿这个例子套到上面这幅图也是一样的。 -
上面这幅图delta左边的红点是一个 安全警戒线,什么意思呢?也就是说 预测错误得分超过这个安全警戒线就会得到一个惩罚权重,让这个预测错误值退回到安全警戒线以外,这样才能够保证预测正确的结果具有唯一性。 -
对应到公式中, _j)就是错误分类的得分。后面一项就是 正确得分 - delta = 安全警戒线值,两项的差代表的就是惩罚权重,越接近正确得分,权重越大。当错误得分在警戒线以外时,两项相减得到负数,那么损失函数的最大值是0,也就是没有损失。
-
一直往复循环训练数据,直到最小化损失函数为止,也就找到了分类超平面。
1.3 深入SVM:第二层
1.3.1 从线性可分到线性不可分
接着考虑之前得到的目标函数(令函数间隔=1):

转换为对偶问题,解释一下什么是对偶问题,对偶问题是实质相同但从不同角度提出不同提法的一对问题。
由于求 的最大值相当于求
 的最小值,所以上述目标函数等价于(w由分母变成分子,从而也有原来的max问题变为min问题,很明显,两者问题等价):
的最小值,所以上述目标函数等价于(w由分母变成分子,从而也有原来的max问题变为min问题,很明显,两者问题等价):

因为现在的目标函数是二次的,约束条件是线性的,所以它是一个凸二次规划问题。这个问题可以用现成的QP (Quadratic Programming) 优化包进行求解。一言以蔽之:在一定的约束条件下,目标最优,损失最小。
此外,由于这个问题的特殊结构,还可以通过拉格朗日对偶性(Lagrange Duality)变换到对偶变量 (dual variable) 的优化问题,即通过求解与原问题等价的对偶问题(dual problem)得到原始问题的最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一者对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题。
详细过程请参考文章末尾给出的参考链接。
1.3.2 核函数Kernel
事实上,大部分时候数据并不是线性可分的,这个时候满足这样条件的超平面就根本不存在。在上文中,我们已经了解到了SVM处理线性可分的情况,那对于非线性的数据SVM咋处理呢?对于非线性的情况,SVM 的处理方法是选择一个核函数 κ(⋅,⋅) ,通过将数据映射到高维空间,来解决在原始空间中线性不可分的问题。
具体来说,在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。如图所示,一堆数据在二维空间无法划分,从而映射到三维空间里划分:


通常人们会从一些常用的核函数中选择(根据问题和数据的不同,选择不同的参数,实际上就是得到了不同的核函数),例如:多项式核、高斯核、线性核。
读者可能还是没明白核函数到底是个什么东西?我再简要概括下,即以下三点:
-
实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去(映射到高维空间后,相关特征便被分开了,也就达到了分类的目的); -
但进一步,如果凡是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到可怕的。那咋办呢? -
此时,核函数就隆重登场了,核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,避免了直接在高维空间中的复杂计算。
如果数据中出现了离群点outliers,那么就可以使用松弛变量来解决。
1.3.3 总结
不准确的说,SVM它本质上即是一个分类方法,用 w^T+b 定义分类函数,于是求w、b,为寻最大间隔,引出1/2||w||^2,继而引入拉格朗日因子,化为对拉格朗日乘子a的求解(求解过程中会涉及到一系列最优化或凸二次规划等问题),如此,求w.b与求a等价,而a的求解可以用一种快速学习算法SMO,至于核函数,是为处理非线性情况,若直接映射到高维计算恐维度爆炸,故在低维计算,等效高维表现。
OK,理解到这第二层,已经能满足绝大部分人一窥SVM原理的好奇心,针对于面试来说已经足够了。
1.4 SVM的应用
SVM在很多诸如文本分类,图像分类,生物序列分析和生物数据挖掘,手写字符识别等领域有很多的应用,但或许你并没强烈的意识到,SVM可以成功应用的领域远远超出现在已经在开发应用了的领域。
2. SVM的一些问题
-
是否存在一组参数使SVM训练误差为0?
答:存在
-
训练误差为0的SVM分类器一定存在吗?
答:一定存在
-
加入松弛变量的SVM的训练误差可以为0吗?
答:使用SMO算法训练的线性分类器并不一定能得到训练误差为0的模型。这是由 于我们的优化目标改变了,并不再是使训练误差最小。
-
带核的SVM为什么能分类非线性问题?
答:核函数的本质是两个函数的內积,通过核函数将其隐射到高维空间,在高维空间非线性问题转化为线性问题, SVM得到超平面是高维空间的线性分类平面。其分类结果也视为低维空间的非线性分类结果, 因而带核的SVM就能分类非线性问题。
-
如何选择核函数?
-
如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM; -
如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数; -
如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。
-
3. LR和SVM的联系与区别
3.1 相同点
-
都是线性分类器。本质上都是求一个最佳分类超平面。 -
都是监督学习算法。 -
都是判别模型。判别模型不关心数据是怎么生成的,它只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。常见的判别模型有:KNN、SVM、LR,常见的生成模型有:朴素贝叶斯,隐马尔可夫模型。
3.2 不同点
-
LR是参数模型,svm是非参数模型,linear和rbf则是针对数据线性可分和不可分的区别; -
从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。 -
SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。 -
逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。 -
logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
4. 线性分类器与非线性分类器的区别以及优劣
线性和非线性是针对模型参数和输入特征来讲的;比如输入x,模型y=ax+ax^2 那么就是非线性模型,如果输入是x和X^2则模型是线性的。
-
线性分类器可解释性好,计算复杂度较低,不足之处是模型的拟合效果相对弱些。
LR,贝叶斯分类,单层感知机、线性回归
-
非线性分类器效果拟合能力较强,不足之处是数据量不足容易过拟合、计算复杂度高、可解释性不好。
决策树、RF、GBDT、多层感知机
SVM两种都有(看线性核还是高斯核)
参考文献
支持向量机通俗导论(理解SVM的三层境界)
获取更多干货内容,记得关注我哦。
本文由 mdnice 多平台发布