文章目录
- 域名
- URL
- URLEncode和URLDecode
- HTTP的请求
- HTTP的响应
- 请求与响应的获取
- 简单的Web服务器
域名
任何客户端在需要访问一个服务端时都需要一个IP和端口号,而当一个浏览器去访问一个网页时通常更多使用的是域名而不是IP:port的方式,
www.baidu.com
这是百度的域名;
实际上当浏览器访问到一个网站的域名时将会把域名解析成对应的IP:port即IP+端口号的形式进行访问,本质上还是采用IP和端口号的形式进行访问,只不过使用域名访问的方式将大幅度提升用户的使用体验;
域名实际上是一串字符串,这是运营商的一种映射的方式,将对应的字符串映射至对应的IP和端口号从而对服务端进行访问;
通常使用ping来查看当前网络连接的情况,在进行ping时对应的也会将对应域名的IP地址暴露出来;
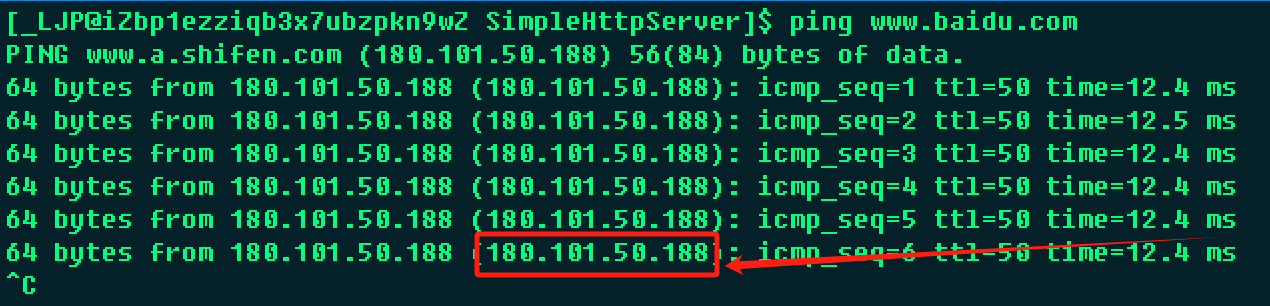
ping www.baidu.com
在这个例子中使用ping来查看当前计算机与百度首页的连接,其中返回了一个180.101.50.188的IP地址,可以通过浏览器访问该IP地址来直接访问百度的首页;

在使用浏览器对一个IP进行访问时,若是在访问时只有IP没有端口号,浏览器默认将会以HTTP协议对该IP进行访问;
http://180.101.50.188/ 等价于 180.101.50.188:80
https://180.101.50.188/ 等价于 180.101.50.188:443
HTTP协议是一种应用层协议,该协议默认的端口号为80,HTTPS协议默认端口号为443;
URL
URL(Uniform Resource Locator) 统一资源定位符;
所有网络上的资源都可以用唯一的一个字符串表示,可以通过该统一资源定位符在公网中获取对应的网络资源;
https://gitee.com/half-intermediate-mangfu/my_-linux/tree/master/Pro24/Network/HTTP
通过域名来区分不同主机的IP,资源由哪个进程访问由端口号来决定,不仅如此服务器上也有不同的路径,无论是域名还是端口号都是具有唯一性的,域名(IP)在公网中具有唯一性,端口号则是在同一台主机下具有唯一性,同样的不同的路径也是在主机中具有唯一性的;
在上面的这段url中https://为协议,也为端口号(https默认端口号为443),gitee.com为域名,/half-intermediate-mangfu/my_-linux/tree/master/Pro24/Network/HTTP则为路径;
这是一个较为简单的URL但并不是一个完整的URL,完整URL如下:
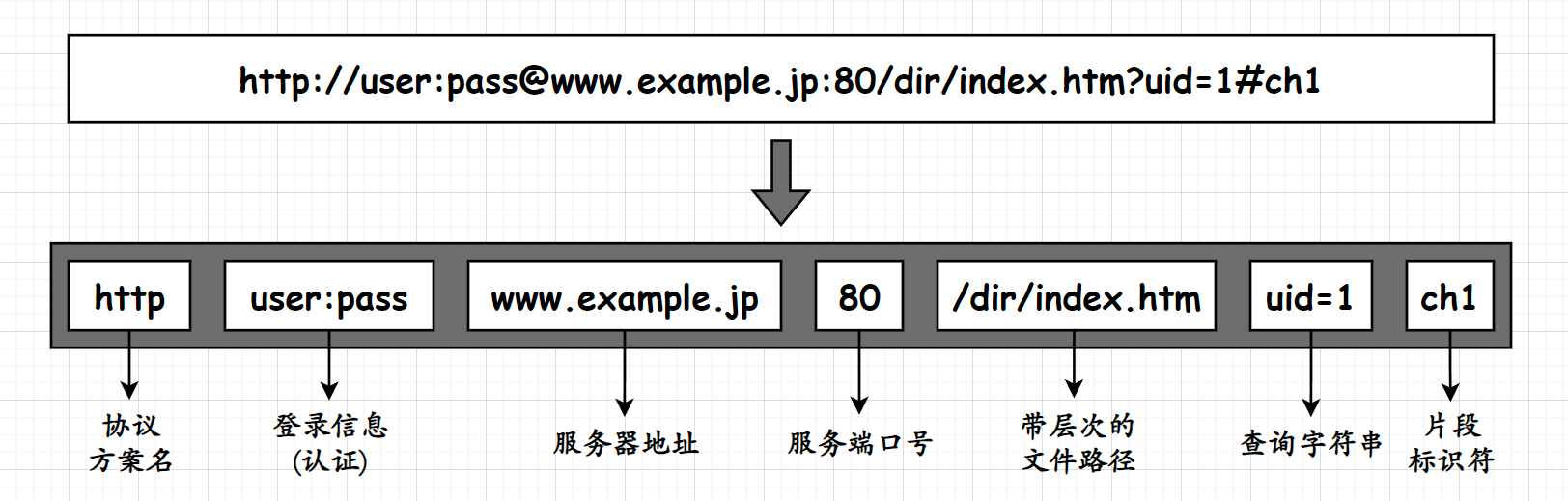
-
http该字段为协议,方案名称,表示需要使用哪种协议能够正确访问该IP;
-
user:pass表示用户的登录信息(认证),但随着登陆页面的独立化该字段也越来越少见;
-
www.example.com表示服务器的域名,即IP地址;
-
80这里的
80表示是端口号,但是由于在该URL的开头处已经指定了使用的协议,意味着该字段可以被省略;这也是上面的URL不存在端口号信息
-
/dir/index.htm表明是一个文件路径,标识着该网络资源在该服务器上的相对路径或者绝对路径;
当一个网页资源的路径以
/作为分隔符,那么这个网络资源则有肯能部署在类UINX系统中;其中第一个
/表示的是Web根目录,Web根目录可能是服务器中的根目录,也可能是服务器中的一个特定目录作为根目录,而路径则为一个相对路径; -
?uid=1网络的行为实际上只有两种:
- 获取别人的网络资源
- 上传自己的资源至网络
在访问一个网页时实际上就是将别人的
htm文件资源获取至自己的浏览器中;而当需要上传一个信息时可能该主机的一些信息也会被上传至网络,其中
uid=1是一种Key-Value的键值对形式,表示该请求的一些动态数据;即
url可以跟?符号,?符号后可以带参表示一些需要携带的信息; -
#ch1表示片段标识符;
通常用在网页中以实现页面内的跳转,它在URL中以
#符号开始,后接标诈字;
URLEncode和URLDecode
URLEncode和URLDecode为URL编码与URL解码;
这是用于处理URL中特殊字符的函数或者方法,在上文中提到,URL实际上存在许多的特殊字符,包括/ : . @ ? #等特殊符号,如果在搜索过程中直接将特殊符号以符号的形式进行搜索那么将会使得URL错误,因此在URL中对于搜索的特殊符号需要进行特殊的处理,即URLEncode(URL编码);
假设需要搜索一个内容为aaaaa://?##bbbbb的内容,如果未经过URLEncode,最终的URL将为:
https://www.bing.com/search?q=aaaaa+://?##bbbbb
但有时这些特殊符号会导致URL解析错误;
而当对特殊符号进行URLEncode编码那么特殊符号将不会造成URL解析错误;

本质原因是当把未经编码的特殊符号传给服务端时服务端将无法直接区分众多特殊符号中哪些属于URL哪些属于用户需要搜索的内容;

少量的情况,提交或者获取数据本身可能包含和URL中特殊字符冲突的字符,要求Browser和Server双方进行编码和解码;
当Browser向Server发送数据时需要对URL中的特殊符号进行Encode编码,当Server接收到来自Browser发送来的数据时需要对URL中编码后的特殊符号进行解码,从而保证需要搜索(作为数据发送)的特殊符号不会与URL原本的特殊符号产生冲突;
-
URLEncode 编码的规则如下
将需要转码的字符转为16进制,然后够从右到左取四位,不足四位直接处理,每两位作一位,前面加上
%,编码成%XY的格式;-
获取字符的编码值
对于ASCII字符,先获取其对应的ASCII码(范围在
0-127);对于非ASCII字符(如中文字符),先将字符按照
UTF-8编码,得到对应的字节序列;
假设需要编码的字符为
?,其ASCII码为63,将63转化为十六进制得到3F,最后在3F前加上%得到%3F;假设需要编码的字符为
你,其UTF-8编码为E4 BD A0(十六进制),将每个字符前加上%,得到%E4%BD%A0; -
可以使用URLEncode工具进行验证;
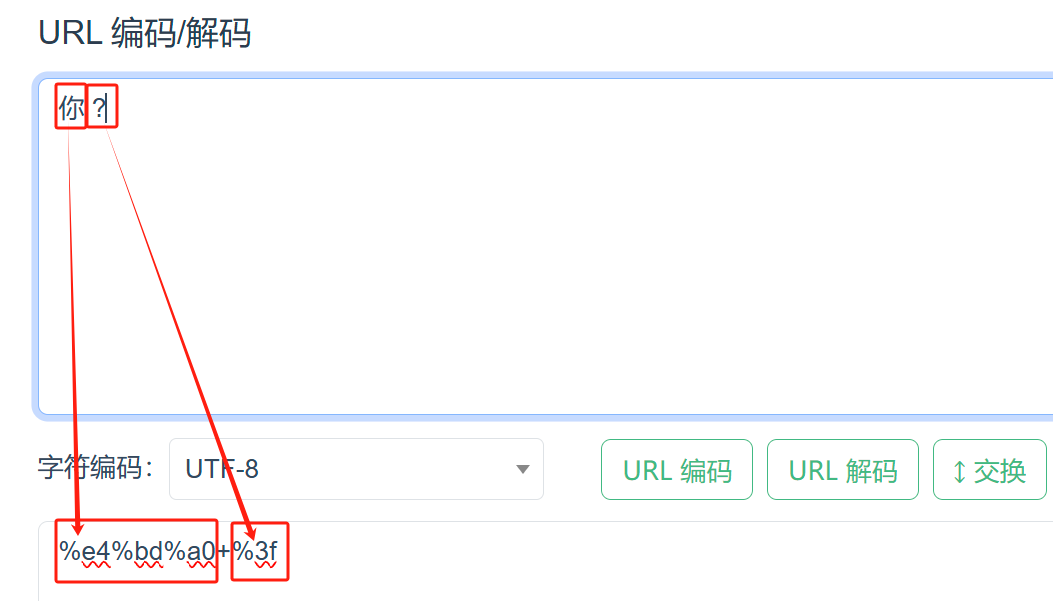
通常情况下在浏览器中进行搜索,遇到特殊符号时浏览器将自动为特殊符号进行URLEncode编码;
HTTP的请求
HTTP的请求与响应都是以行位单位进行陈列的,都是以多行为构成,这里的行实际上是以一个分隔符作为区分为一行,也可以不将分隔符作为行分隔符从而看整体为一个字符串,行分隔符可以是\n,也可以是\r\n,每一行的结尾都是以\n或是\r\n作为一行的结束;
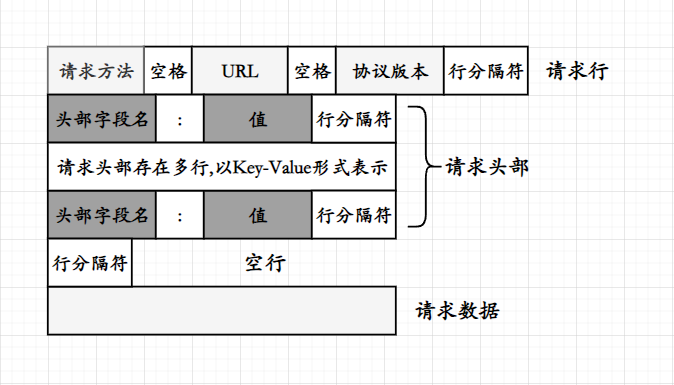
HTTP的请求为四个部分组成,分别为 请求行 , 请求头部 , 空行 与 请求数据 组成;
请求行以三个部分组成,分别为请求方法,URL ,以及协议版本,字段与字段之间通常以空格作为分隔符;
-
请求方法
常见的请求方法为如下:
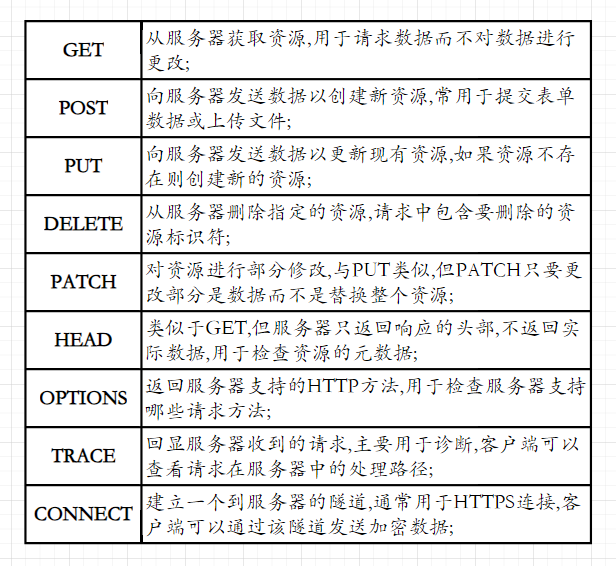
但最常用的请求方法实际上为
GET与POST,即获取服务器的资源与向服务器发送资源; -
URL即统一资源标识符,包括请求的资源路径,通常包括主机名,端口号(如果非默认),路径以及查询字符串等(参照上文);
-
HTTP版本
常见的HTTP版本为,
HTTP/1.0,HTTP/1.1,HTTP/2等;
请求行的格式通常为:
GET /index.html HTTP/1.1
HTTP的请求行过后是请求头部,请求行与请求头部以行分隔符进行分割,同样的分割符可以是\n或者是\r\n;
请求头部存在多行,每一行都以Key-Value的方式进行存储,通常情况下请求头部的每一行存储的是一些关于请求的属性;
当服务端接收到来自浏览器的请求时需要对请求行和请求头部进行读取以及分析,而请求头部过后紧接着的是请求数据,也就是请求正文,而为了避免请求头部与请求数据中的混淆,请求头部和请求数据(请求正文)之间将存在一行为空行,这个空行只有行分隔符,当服务端读取至一行只存在行分隔符时则表示请求行和请求头部已经读取完毕,剩下的内容即为请求数据(请求正文),换种说法即为报头与有效载荷进行分离;
请求正文为客户端/浏览器在发送请求时需要传输的数据,这些数据可以是图片,音频,视频等二进制流,同时这个字段可以为空,因为在一些时候只是单纯向服务端发送请求使服务端将数据以响应的形式反馈给客户端;
在请求报头中存在一个属性为Content-Length,这个属性表示请求正文的长度以保证服务端能够判断接收到的报文是否为一个完整的报文;
HTTP的响应
HTTP的响应格式与请求的格式几乎相同;
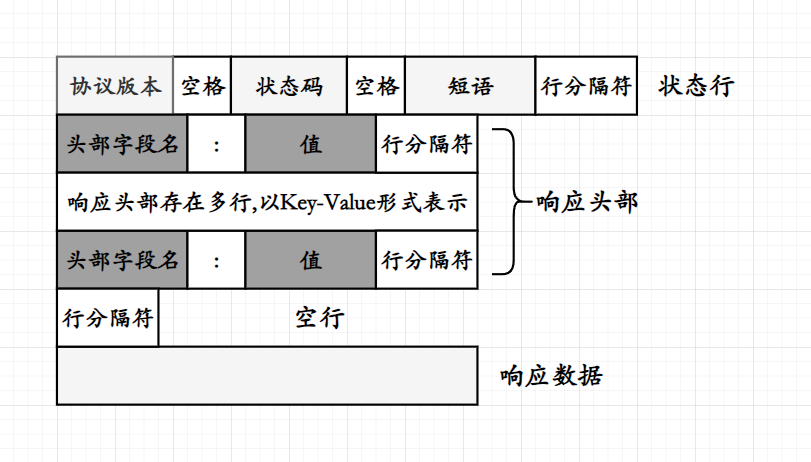
-
状态码
HTTP的状态码为服务器处理客户端请求的完成状态,常用的状态码为如下:
-
200表明请求成功 -
302表明请求重定向 -
304表明请求资源没有改变,访问本地缓存 -
404表明请求资源不存在,通常是用户路径编写错误,也可能是服务器资源已删除 -
500表明服务器内部错误,通常程序抛异常
-
-
短语
短语也是状态信息,状态信息是根据状态码变化而变化的,是对状态码的文本描述,虽然状态短语不是严格必要的,但是能够帮助用户理解响应;
-
响应头部
响应头部与请求头部相同,包含多个以
Key-Value键值对字段,传递关于响应的元数据,如服务器信息,内容类型等,同样的响应头部中同样存在一个Content-Length字段,这个字段用来描述响应正文的长度,使得客户端在接收到一个响应报文时判断响应报文是否为一个完整的报文; -
空行
响应头部与响应数据中存在一个空行作为间隔,这个空行中只存在行分隔符使得客户端能够判断响应报文中哪些字段属于状态行与报头,哪些字段属于响应数据;
-
响应数据
响应数据也被成为响应正文,是服务器返回给客户端的实际内容,这个响应数据可能是HTML页面,JSON数据,文件等;
当状态码为
200时表示成功,响应正文将包含客户端请求的资源内容;
请求与响应的获取
可以使用一些较为基本的工具对响应进行一个抓取;
-
telnet工具在之前的文章中,在实现一些TCP程序时当未完成客户端的编写时采用了
telnet工具作为平替,即使用telnet工具对自定义编写的TCP服务器进行访问;而该工具基本上可以访问任何可以访问的服务器;
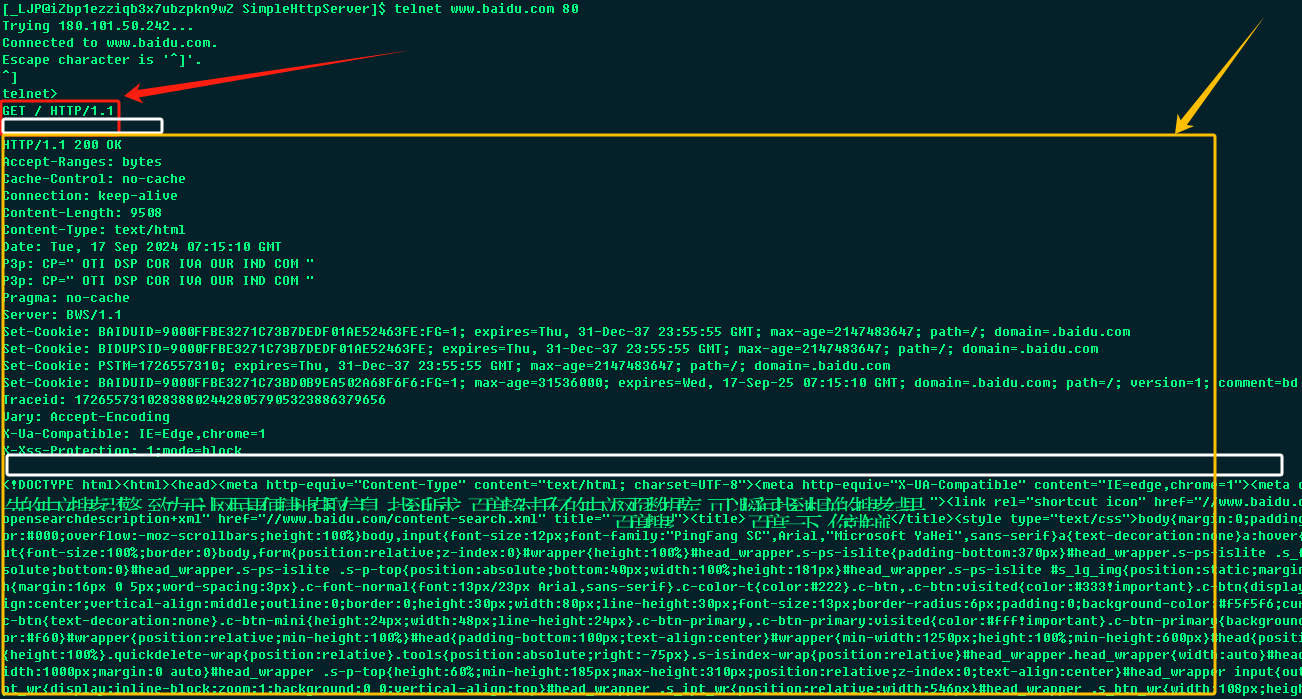
在这个例子中构建了一个最简单的请求;
GET / HTTP/1.1GET为请求的方法,/表示根目录,一般情况下根目录表示获取该服务器的首页资源,HTTP/1.1表示HTTP协议的版本,这是一个最简单的请求,这个请求不需要报头也不携带任何请求资源;当第一次回车时表示第一个行分隔符,表示请求行已经结束,此时并没有反应,因为当只有空行结束时才表示这个请求已经结束;
在上图中分为红色区域与黄色区域,其中红色区域表示请求报文,黄色区域表示响应报文,白色区域表示请求报文和响应报文中的空行(仅有行分隔符);
响应报文中空行上部表示状态行与响应报头(以
Key-Value的方式表示),空行下部表示响应正文(返回给客户端的文件等内容);
从响应的结果可知,无论是客户端还是服务端都需要互相通一下各自的HTTP协议版本;
通常情况下,不同版本的客户端支持的HTTP协议版本不同,当一个客户端使用HTTP/1.1协议版本的协议向服务端发送请求这也表示客户端也期望接收到的响应也应是HTTP/1.1协议版本的响应;
这种机制的网络通信可以保持稳定有效,避免由于协议不匹配引发潜在的问题;
-
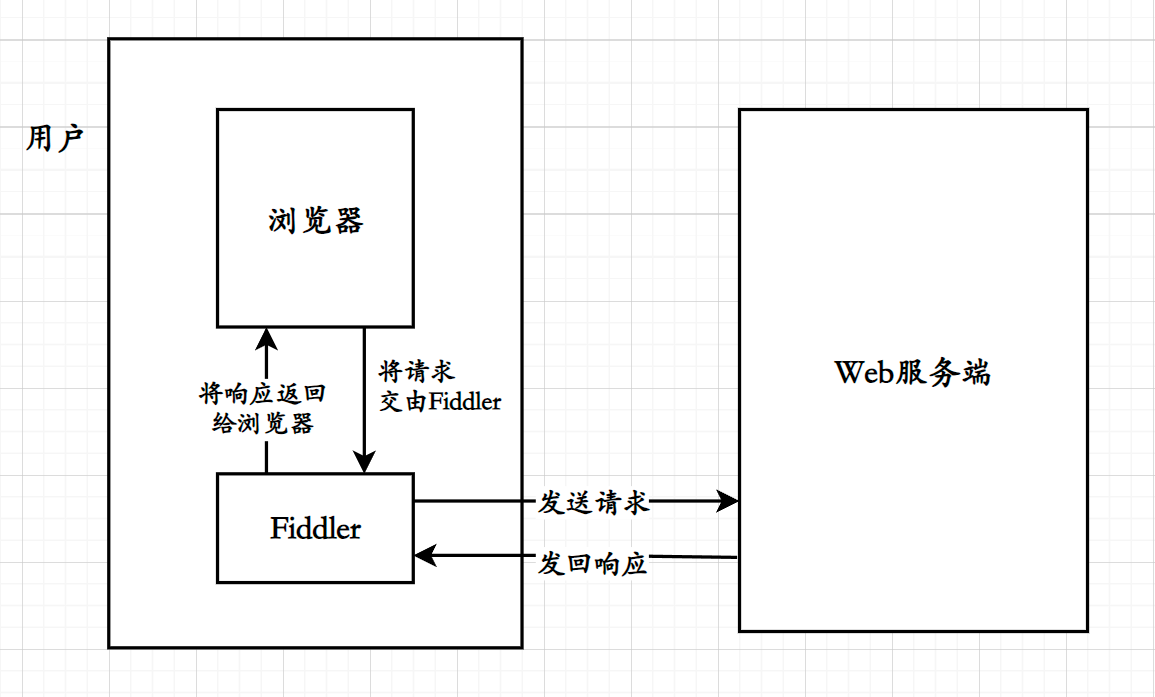
Fiddler该工具是一个用于抓包的工具,可以对客户端向服务端发送的请求进行抓包;
当使用浏览器访问一个Web服务器时实际上是通过浏览器作为客户端直接向Web服务器发送一个请求,而Fiddler工具则是浏览器不直接访问Web服务器,而是将请求交由Fiddler工具,由Fiddler向服务器发起请求,相应的服务器的响应也将先发送回给Fiddler,由Fiddler工具交还给浏览器;
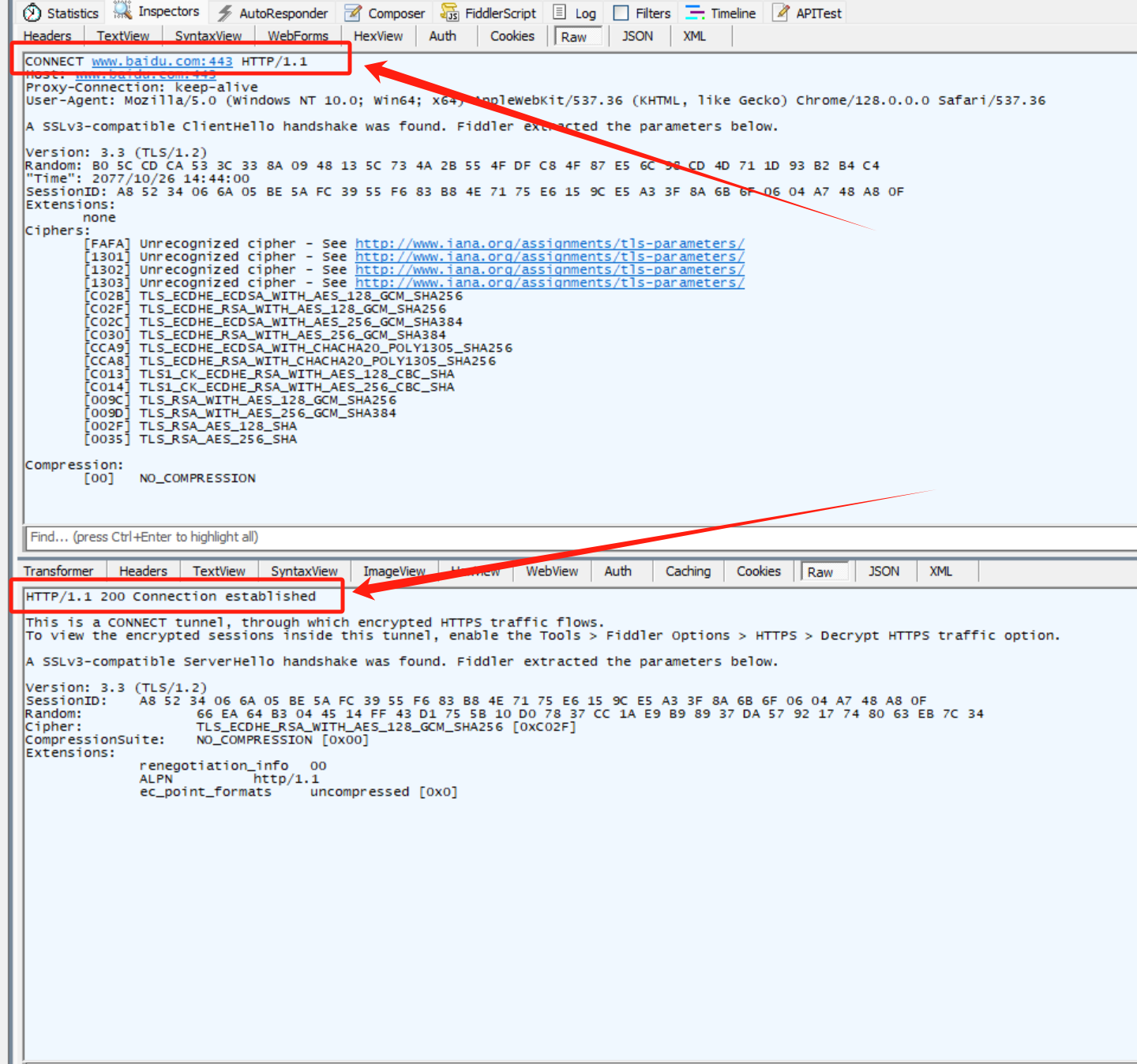
其中上部分内容为请求,下部分内容为响应;
红色方框框住的内容分别为请求报文的请求行以及响应报文的状态行;
该报文的正文部分并不太直观,本质原因是这两个报文实际上采用的是HTTPS协议,所以进行了一定的简单加密;
换句话说Fiddler工具就相当于一个代理,也是一个Web调试工具;
-
Postman该工具是用来构建网络请求的;
与Fiddler工具不同,Fiddler工具通过代理的方式来获取浏览器的请求,以该工具为浏览器和Web
服务器的媒介,来发送请求与接收响应;
Postman工具不同,该工具直接用于与Web服务器进行直接交互而不需要浏览器;
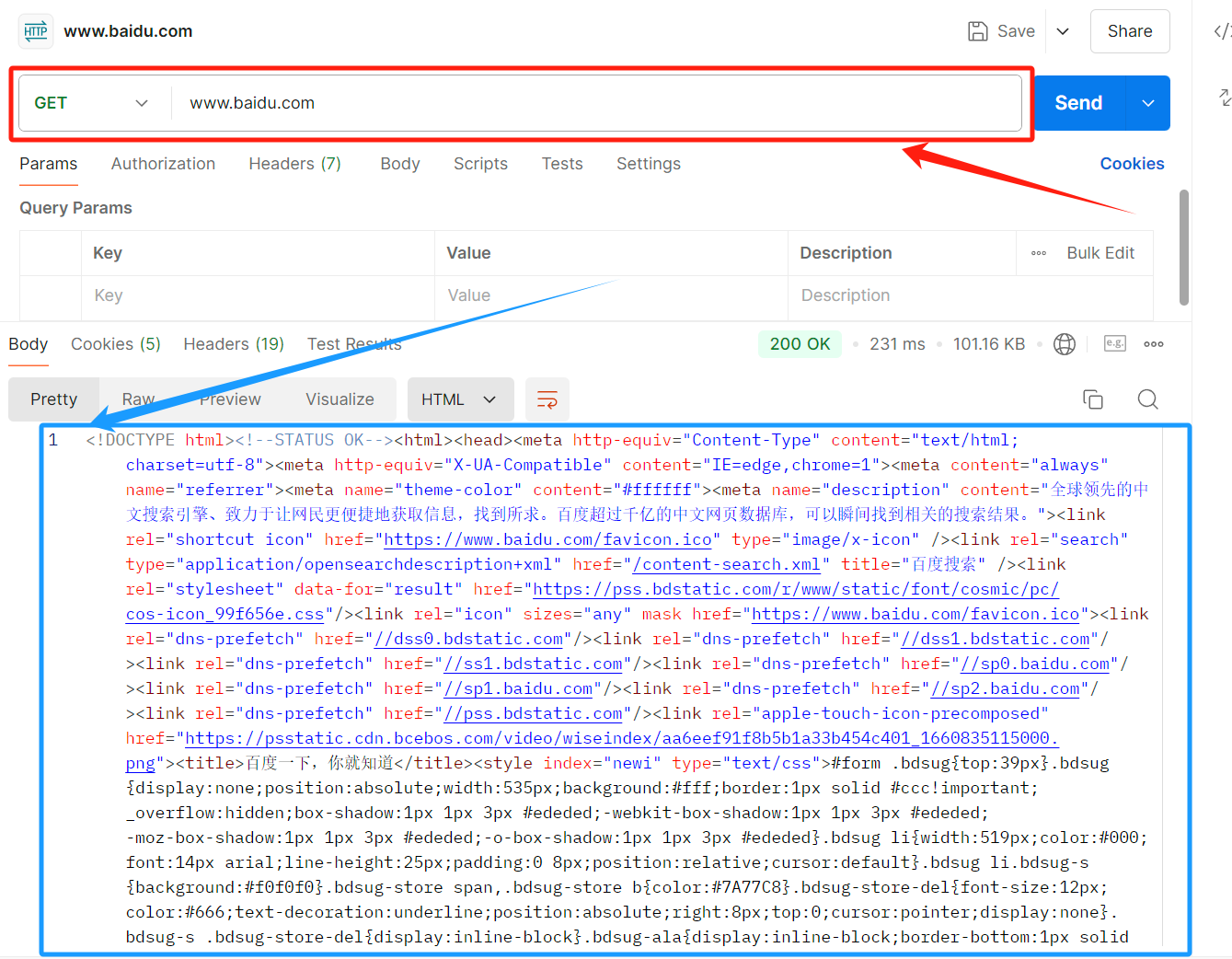
在这个例子中使用
GET方法向www.baidu.com发起请求,其中红色部分为请求部分,蓝色部分为响应部分;
简单的Web服务器
HTTP协议是应用层协议,同样的底层协议可以选择使用TCP或UDP作为底层协议,因此本次在实现时使用文章『 Linux 』协议的定制中 “套接字接口的封装” 中的网络插件(TCP套接字的封装),并使用自定义的日志插件进行服务端日志的打印;
-
服务器大致框架
在该版本的HTTP服务器中同样以一个类的形式对服务器进行一个封装;
将套接字的初始化部分与运行部分进行整合为一个
Start()函数;在该服务器中使用多线程的方式避免在单执行流情况下出现的阻塞问题;
/* httpserver.hpp */class HttpServer { public:HttpServer(uint16_t port = defaultport) : port_(port) {}~HttpServer() {}bool Start(){}static void *ThreadRun(void *args){// 线程执行}protected: private:uint16_t port_;static const uint16_t defaultport;NetSocket listensock_; }; const uint16_t HttpServer::defaultport = 8049;成员如下:
-
port_该成员变量负责服务端需要绑定的端口号;
-
defaultport该成员变量为端口号的默认值,进行了初始化默认为
8049(便于测试); -
listensock_TCP协议中存在两个套接字,一个套接字用于监听,一个套接字负责与客户端进行通信,用于监听的套接字一般称为监听套接字,该套接字使用的是封装后的TCP套接字,用于监听来自客户端的连接;
-
构造函数
构造函数主要负责初始化端口号;
-
Start()函数该成员函数主要负责初始化套接字信息,如调用
NetSocket::Socket()函数创建套接字,调用NetSocket::Bind()绑定端口号,调用NetSocket::Listen()函数设置监听等操作;同时该函数也负责对执行流进行分离,即在调用
NetSocket::Accept()函数后创建新线程由新线程执行主要任务,由主线程继续返回监听状态等待下一个来自客户端的连接到来; -
static void *ThreadRun(void *args)这是一个静态成员函数,是线程的执行函数,为了避免成员函数中参数存在一个隐含的
this指针导致参数不匹配,在函数前加上static修饰为静态成员函数;该函数主要为分离执行流后的新线程处理主要的工作;
-
-
Start()启动函数/* httpserver.hpp */class HttpServer { public:bool Start(){listensock_.Socket();listensock_.Bind(port_);listensock_.Listen();for (;;){std::string clientip;uint16_t clientport;int sockfd = listensock_.Accept(&clientip, &clientport);pthread_t tid;ThreadData *td = new ThreadData(sockfd);pthread_create(&tid, nullptr, ThreadRun, td);}}static void *ThreadRun(void *args){}protected:struct ThreadData{ThreadData(int sockfd) : sockfd_(sockfd) {}int sockfd_;}; }; const uint16_t HttpServer::defaultport = 8049; #endif该函数初始化TCP套接字需要的创建套接字,绑定端口,设置监听等操作,同时定义了一个内部结构体
ThreadData,用于向线程执行函数传入需要进行通信的套接字描述符,同时利用了结构体以便于进行需要传递数据的拓展; -
ThreadRun()函数该函数为线程的入口函数,主要执行一些重要的任务;
/* httpserver.hpp */class HttpServer { public:static void *ThreadRun(void *args){ThreadData *td = static_cast<ThreadData *>(args);pthread_detach(pthread_self());char buffer[10240];ssize_t n = recv(td->sockfd_, buffer, sizeof(buffer) - 1, 0);if (n > 0){buffer[n] = 0;std::cout << buffer;}close(td->sockfd_);delete td;return nullptr;} private:uint16_t port_;static const uint16_t defaultport;NetSocket listensock_; }; const uint16_t HttpServer::defaultport = 8049;在这个简单的服务器中主要的任务为打印来自客户端的请求,当打印完客户端的请求后服务器将关闭该连接,表示一次服务结束;
在该服务器中,main函数只需要进行Start()函数的调用即可;
/* httpserver.cc */int main(int argc, char *argv[])
{std::unique_ptr<HttpServer> svr(new HttpServer());svr->Start();return 0;
}
这里使用了智能指针来管理实例的生命周期;
-
测试
启动服务器,并使用
telnet或浏览器等工具以IP/port的方式向服务器发起请求,服务器将打印对应的请求信息;-
使用
telnet工具
使用
telnet工具发送的请求被服务器接收并打印; -
使用浏览器
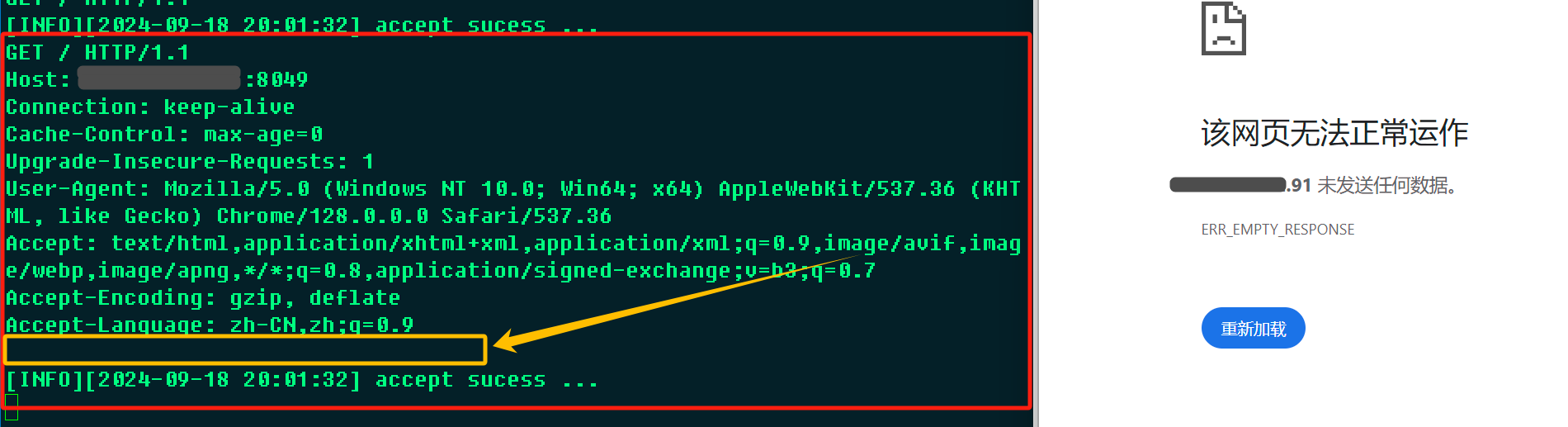
使用浏览器发送的请求被服务器接收并打印,黄色部分为请求的空行部分,该请求不携带任何正文;
-