论文分享简介
本推文介绍的是2024 ICML的最佳论文之一《Scaling Rectified Flow Transformers for High-Resolution Image Synthesis》,论文介绍了Stable Diffusion 3的技术细节。该论文提出了一种对修正流模型(rectified flow)中的噪声尺度重新加权的方法,类似于噪声预测扩散模型的技术,显著提高了模型性能。其次,设计了一种新型的Transformer架构,该架构允许在图像和文本token之间进行双向信息混合,改善了文本理解、排版和人类偏好评分,相较于传统架构(如UViT和DiT)表现更为出色。此外,论文还进行了模型的可扩展性研究,结果显示模型遵循可预测的缩放趋势,并且验证损失的降低与文本到图像生成性能的提升(如自动评分和人类评分)之间具有强相关性。推文作者为许东舟,审校为黄星宇和邱雪。
论文链接:https://openreview.net/forum?id=FPnUhsQJ5B
1. 会议介绍

ICML(International Conference on Machine Learning,国际机器学习会议)创办于1980年,由国际机器学习协会主办,每年举办一次。作为人工智能(Artificial Intelligence, AI)和机器学习领域中最具有影响力的会议之一,它的讨论主题领域广泛,包括通用机器学习、深度学习、学习理论、优化、概率推理等。
2. 研究背景
近年来,扩散模型(Diffusion Models)已成为生成高分辨率图像和视频的主流方法。它们通过将噪声转化为数据(如图像或视频)来生成高质量的图像、视频。这种方法在训练过程中面临着计算成本高和采样时间长等挑战。
修正流模型(Rectified Flow)通过构建基于常微分方程的映射,在两个分布之间实现生成建模。和传统的扩散模型不同,它在数据和噪声之间建立一条直线来简化生成过程。尽管修正流模型具有更好的理论特性和简洁的概念,但并不是总能得到最优的传输结果。
基于上述背景,论文旨在通过改进修正流模型中的噪声采样方法,并设计一种新型的Transformer架构,以更好地处理文本到图像的合成任务。此外,研究还探讨了这些改进在大规模模型中的可扩展性及其对生成性能的影响。
3. 方法
3.1 无仿真流训练(Simulation-Free Training of Flows)
在传统流模型训练中,通常需要沿着数据分布到噪声分布的路径进行逐步仿真,这种过程计算成本较高。而文中提出的方法通过直接从目标分布中采样,将生成问题转化为优化一个新的损失函数。
这个损失函数用于衡量生成数据和真实数据之间的差异,考虑了数据和噪声之间的直线映射关系,而不再依赖传统的曲线路径。通过这种方式,模型在训练时能够更加快速地收敛到最优解,从而提高了效率。
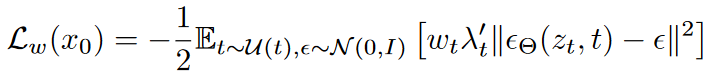
该损失函数通过加权的方式,进一步优化了噪声重构误差,使得模型能够在训练过程中更好地拟合目标数据分布。这种加权方案结合了时间步𝑡和噪声 ϵ 的采样,以增强模型的训练稳定性和生成质量。
3.2 流轨迹(Flow Trajectories)
该段落的目的是讨论如何通过优化流轨迹来增强修正流模型的训练效果。具体来说,这段讨论的核心在于设计和调整生成路径的轨迹,以便模型在生成数据时更加高效和准确。
论文对修正流、EDM、Cosine、(LDM-)Linear这些方法进行了介绍(详见原文)。此外,文中还介绍了几种新的时间步长采样方法,以优化修正流模型的训练。
修正流损失函数通常对所有时间步 t∈[0,1]进行均匀采样。然而,由于在中间时间步(即t接近 0.5 时),预测误差更大,作者建议改变时间步的采样分布以更频繁地采样中间时间步。这种方法等效于一个加权损失:
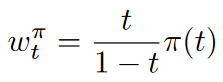
接下来将对用于训练模型的时间步密度π(t)进行介绍。
1)Logit-Normal采样
首先是Logit-Normal 采样,它为中间时间步分配了更多的权重。其概率密度函数为:
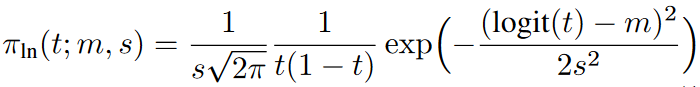
其中,![]() ,m是位置参数,s是尺度参数。位置参数m用于控制训练时间步偏向数据po(当m为负)或噪声p1(当m为正)。尺度参数s决定了分布的宽度。
,m是位置参数,s是尺度参数。位置参数m用于控制训练时间步偏向数据po(当m为负)或噪声p1(当m为正)。尺度参数s决定了分布的宽度。
2)具有重尾的模式采样(Mode Sampling with Heavy Tails)
由于Logit-Normal 分布在时间步的端点(0和1)处的密度为零,为了探讨这种性质是否会对性能产生不利影响,文中还提出了一种在区间[0,1]上具有严格正密度的时间步采样分布,其定义为:

通过该公式,可以控制采样分布的偏移程度,使其更偏向于中间点或端点。
3)CosMap采样
最后,文中还采用了Cosine 调度(CosMap)来匹配对数信噪比(log-SNR)。具体而言,寻找了一个映射![]() ,使得其符合余弦调度:
,使得其符合余弦调度:![]()
求解后得到:
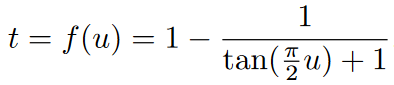
从中得到相应密度:

3.3 文生图架构

图2 MM-DiT的模型架构。连接操作用⊙表示,元素级乘法用∗表示。可以在 Q 和 K 上添加 RMS-Norm 以稳定训练过程。
图2展示了本文提出的用于文本到图像生成任务的多模态扩散Transformer架构(MM-DiT),该架构能够同时处理文本和图像两种模态的输入信息,并通过多个Transformer块在两者之间实现双向信息流动。
文中的架构建立在DiT架构的基础上。DiT仅考虑类条件的图像生成,并使用一种调制机制,根据扩散过程的时间步和类别标签来对网络进行条件化。同样地,文中使用时间步t和文本编码c_vec的嵌入作为调制机制的输入。然而,由于池化后的文本表示仅保留了关于文本输入的粗粒度信息,网络还需要从序列表示c_ctxt中获取信息。
文中构建了一个由文本和图像输入的嵌入组成的序列。具体而言,添加了位置编码并将潜在像素表示![]() 的2×2块展平为长度为
的2×2块展平为长度为![]() 的块编码序列。在对这些块编码和文本编码c_ctxt进行相同维度的嵌入后,将这两个序列连接起来。然后遵循DiT的做法,应用一系列调制注意力和MLP。
的块编码序列。在对这些块编码和文本编码c_ctxt进行相同维度的嵌入后,将这两个序列连接起来。然后遵循DiT的做法,应用一系列调制注意力和MLP。
由于文本和图像嵌入在概念上相当不同,作者为这两种模态使用了两组独立的权重。如图2b所示,这相当于为每种模态各自设置了两个独立的transformer,但在注意力操作中将这两种模态的序列连接在一起,使得两种表示可以在各自的空间中工作,同时考虑到另一种表示。
在缩放实验中,我们通过模型深度d(即注意力块的数量)来参数化模型的大小,具体做法是将隐藏层大小设置为64·d(在MLP块中扩展为4·64·d通道),并将注意力头的数量设为d。
4. 实验结果
4.1 改进修正流
该部分比较不同无模拟训练正规化流方法的效率,通过控制优化算法、模型架构、数据集和采样器来实现公平比较。研究中使用ImageNet和CC12M数据集训练模型,并通过验证损失、CLIP得分和FID指标来评估训练权重和EMA权重,所有评估均在COCO-2014验证集上进行。详细的训练和采样超参数在附录B.3中提供。
表1展示了各种模型变体的平均排名,表2则是各模型变体在固定的25个采样步骤下的FID(越低表示生成图像的质量越高)分数和CLIP(用于评估生成的图像与文本描述之间的一致性,得分越高表示生成图像与文本的匹配度越好)分数。
表1 变体的全局排名。排名基于EMA(指数移动平均)和非EMA权重两个数据集以及不同采样设置上应用了非支配排序的平均值。

表2 不同变体的指标。不同变体在25个采样步骤下的FID和CLIP分数。突出了表现最好、次好和第三好的条目。

4.2 改进特定模态的表示
该部分介绍了在多模态文本到图像生成任务中如何改进特定模态(即文本和图像)的表示,比如对自编码器、字幕的改进,实验结果如图3、图4、表3、表4所示。图5展示了模型大小对性能的影响。

图3 修正流的样本效率。修正流在较少采样步骤时表现优于其他公式。在25步及以上的采样中,只有rf/lognorm(0.00, 1.00)能够与eps/linear相竞争。
表3 改进自编码器。不同通道配置下的重构性能指标。所有模型的下采样因子为f = 8。

表4 改进字幕。使用50/50的比例混合合成和原始字幕,提升了文本到图像的性能。通过GenEval基准进行评估。


图4 模型架构的训练动态。对DiT, CrossDiT, UViT和MM-DiT在CC12M上的比较分析,重点关注验证损失、CLIP分数和FID。MM-DiT在所有指标上表现良好。

图5 缩放的定量效果。分析了模型大小对性能的影响,同时保持一致的训练超参数。深度为38的模型是一个例外,需要在3 × 10^5步时调整学习率以防止发散。(上)无论是图像(第1和第2列)还是视频模型(第3和第4列),验证损失随模型大小和训练步骤的增加而平滑下降。(下)验证损失是整体模型性能的有力预测指标。验证损失与整体图像评价指标(包括GenEval(Ghosh et al., 2023),第1列)、人类偏好(第2列)和T2I-CompBench(Huang et al., 2023,第3列)之间有显著的相关性。对视频模型,在第4列中观察到验证损失与人类偏好之间的类似相关性。
4.3 大规模训练
该部分讨论了模型在大规模训练下的表现。关于这一扩展性研究的准备工作在附录C中进行了介绍,作者描述了在扩展训练数据(附录C.1)和图像分辨率(附录C.2)时确保高效且稳定训练所需的步骤。
随后,将前面章节中关于扩散公式、架构和数据的所有考虑因素汇总到本节中,并将模型的参数规模扩大到80亿(8B)。图6是对8B模型在人类偏好方面的评估,表5、表6分别是对模型在GenEval基准上的评估比较和模型大小对采样效率的影响。

图6 人类偏好评估与当前封闭和开放的SOTA生成图像模型的比较。在使用parti-prompts (Yu et al., 2022) 进行评估时, 8B模型在视觉质量、提示跟随和排版生成类别上相较于当前最先进的文本到图像模型表现优异。
表5 GenEval比较。文中最大的模型(深度=38)在GenEval (Ghosh et al., 2023) 上优于所有当前开放的模型和DALLE-3 (Betker et al., 2023)。突出显示了最佳、第二好和第三好的条目。关于DPO,请参见附录C.3。

表6 模型大小对采样效率的影响。表格显示了相对于使用50个采样步骤在固定种子下评估的CLIP分数的相对性能下降。较大的模型可以使用更少的步骤进行采样,我们将此归因于其更高的鲁棒性和更好地符合修正流模型的直线路径目标,从而产生更短的路径长度。

5. 总结与展望
研究对修正流模型在文本到图像合成中的扩展性进行了分析。论文提出了一种新的时间步采样方法,用于修正流的训练,相较于先前的潜在扩散模型训练方法具有更好的表现,并保持了修正流在少步采样中的优良特性。随后,论文还展示了基于Transformer的MM-DiT架构在考虑多模态特性的文本到图像任务中的优势。最后,对这一组合进行了规模扩展研究,将模型扩展到80亿(8B)参数和5 × 10²²次训练FLOPs。结果表明,验证损失的改进与现有的文本到图像基准测试和人类偏好评估具有相关性。
文章对生成建模和可扩展的多模态架构上的改进,使得模型性能能够与最先进的扩散模型相媲美,并且扩展趋势没有显示出饱和迹象,这使得对未来进一步提升模型性能充满信心。