目录
- 服务注册/服务发现-Eureka
- 背景
- 问题描述
- 解决思路
- 什么是注册中心
- CAP 理论
- 常见的注册中心
- Eureka 介绍
- 搭建Eureka Server
- 创建Eureka-server 子模块
- 引入eureka-server依赖
- 项目构建插件
- 完善启动类
- 编写配置文件
- 启动服务
- 服务注册
- 引入eureka-client依赖
- 完善配置文件
- 启动服务
- 服务发现
- 引入eureka-client依赖
- 完善配置文件
- 远程调用
- 启动服务
- Eureka 和 Zookeeper 区别
- 多机部署与负载均衡 - LoadBalance
- 负载均衡介绍
- 问题描述
- 什么是负载均衡
- 负载均衡的一些实现
- 服务端负载均衡
- 客户端负载均衡
- Spring Cloud LoadBalancer
- 快速上⼿
- 使用Spring Cloud LoadBalancer实现负载均衡
- 启动多个product-service实例
- 测试负载均衡
- 负载均衡策略
- 自定义负载均衡策略
- LoadBalancer 原理
- 服务部署(Linux)
- 准备数据
- 服务构建打包
- 启动服务
- 开放端口号
- 测试
服务注册/服务发现-Eureka
背景
问题描述
之前的例子中可以看到,远程调用时,我们的 URL 是写死的:
String url = "http://127.0.0.1:9090/product/" + orderInfo.getProductId();
当更换机器或者新增机器时,这个 URL 就需要跟着变更,就需要去通知所有的相关服务去修改。随之而来的就是各个项目的配置文件反复更新,各个项目的频繁部署。这种没有具体意义,但又不得不做的工作,会让人非常痛苦。
解决思路
试想生活中的场景:
我们生活中避免不了和各个机构(医院、学校、政府部门等)打交道,就需要保存各个机构的电话号码。如果机构换了电话号码,就需要通知各个使用方,但这些机构的使用方群体是巨大的,没办法做到一通知,怎么处理呢?
机构电话如果发生变化,通知 114。用户需要联系机构时,先打 114 查询电话,然后再联系各个机构。
114 查号台的作用主要有两个:
- 号码注册:服务方把电话上报给 114
- 号码查询:使用方通过 114 可以查到对应的号码

同样的,微服务开发时,也可以采用类似的方案。
服务启动/变更时,向注册中心报道。注册中心记录应用和 IP 的关系。
调用方调用时,先去注册中心获取服务方的 IP,再去服务方进行调用。
什么是注册中心
在最初的架构体系中,集群的概念还不那么流行,且机器数量也比较少,此时直接使用 DNS + Nginx 就可以满足几乎所有服务的发现。相关的注册信息直接配置在 Nginx。但随着微服务的流行与流量的激增,机器规模逐渐变大,并且机器会有频繁的上下线行为,这种时候需要运维手动地去维护这个配置信息是一个很麻烦的操作。所以开发者们开始希望有这么一个东西,它能维护一个服务列表,哪个机器上线了,哪个机器宕机了,这些信息都会自动更新到服务列表上,客户端拿到这个列表,直接进行服务调用即可。这个就是注册中心。
注册中心主要有三种角色:
- 服务提供者 (Server):一次业务中,被其它微服务调用的服务。也就是提供接口给其它微服务。
- 服务消费者 (Client):一次业务中,调用其它微服务的服务。也就是调用其它微服务提供的接口。
- 服务注册中心 (Registry):用于保存 Server 的注册信息,当 Server 节点发生变更时,Registry 会同步变更。服务与注册中心使用一定机制通信,如果注册中心与某服务长时间无法通信,就会注销该实例。
服务提供者和服务消费者是相对的
他们之间的关系以及工作内容,可以通过两个概念来描述:
服务注册:服务提供者在启动时,向 Registry 注册自身服务,并向 Registry 定期发送心跳汇报存活状态。
服务发现:服务消费者从注册中心查询服务提供者的地址,并通过该地址调用服务提供者的接口。服务发现的一个重要作用就是提供给服务消费者一个可用的服务列表。

CAP 理论
谈到注册中心,就避不开 CAP 理论。
CAP 理论是分布式系统设计中最基础,也是最为关键的理论。

-
一致性 (Consistency):CAP 理论中的一致性,指的是强一致性。所有节点在同一时间具有相同的数据。
客户端向数据库集群发送了一个数据修改的请求,数据库集群需要向客户端进行响应,响应的时机分为两种:
- 主库接收到请求,并处理成功,此时数据暂时还未完全同步到从库
- 主库接收到请求,并且所有从库数据同步成功
强一致性:主库和从库,不论何时,对外提供的服务都是一致的
弱一致性:随着时间的推移,最终达到了一致性
-
可用性 (Availability):保证每个请求都有响应(响应结果可能不对)。
-
分区容错性 (Partition Tolerance):当出现网络分区后,系统仍然能够对外提供服务。
一个部门全国各地都有岗位,这时候,总部下发了一个通知,由于通知需要开会周知全员,当有客户咨询时:
- 所有成员对客户的回应结果都是一致的(一致性)。
- 客户咨询时,一定有回应(可用性)。
- 当其中一个成员休假时,这个部门的其他成员也可以对客户提供咨询服务(分区容错性)。
CAP 理论告诉我们:一个分布式系统不可能同时满足数据一致性、服务可用性和分区容错性这三个基本需求,最多只能同时满足其中的两个。
在分布式系统中,系统间的网络不能 100% 保证健康,服务又必须对外保证服务。因此 P 不可避免,必须保证。
不选 P,一旦发生分区错误,整个分布式系统就完全无法使用了,这是不符合实际需要的。
那就只能在 C 和 A 中选择一个。也就是 CP 或者 AP 架构。
正常情况:

网络异常:

- CP 架构:为了保证分布式系统对外的数据一致性,于是选择不返回任何数据。
- AP 架构:为了保证分布式系统的可用性,节点 2 返回 V0 版本的数据(即使这个数据不正确)。
更多参考:CAP 理论详细解释。
常见的注册中心
- Zookeeper
- Zookeeper 的官方并没有说它是一个注册中心,但是国内 Java 体系,大部分的集群环境都是依赖 Zookeeper 来完成注册中心的功能。
- Eureka
- Eureka 是 Netflix 开发的基于 REST 的服务发现框架,主要用于服务注册、管理,负载均衡和服务故障转移。
- 官方声明在 Eureka 2.0 版本停止维护,不建议使用。但是 Eureka 是 Spring Cloud 服务注册/发现的默认实现,所以目前还是有很多公司在使用。
- Nacos
- Nacos 是 Spring Cloud Alibaba 架构中重要的组件,除了服务注册、服务发现功能之外,Nacos 还支持配置管理、流量管理、DNS、动态 DNS 等多种特性。
CAP 理论对比
| 组件 | Zookeeper | Eureka | Nacos |
|---|---|---|---|
| CAP 理论 | CP | AP | CP 或 AP,默认 AP |
在分布式环境中,即使拿到一个错误的数据,也胜过无法提供实例信息而造成请求失败要好(例如淘宝 11.11,京东 618 都是谨遵 AP 原则)。
后面会介绍 Eureka 和 Nacos 的使用。
Eureka 介绍
Eureka是Netflix OSS套件中关于服务注册和发现的解决方案。Spring Cloud对Eureka进行了集成,并作为优先推荐方案进行宣传。虽然目前Eureka 2.0已经停止维护,新的微服务架构设计中也不再建议使用,但目前依然有大量公司的微服务系统使用Eureka作为注册中心。
官方文档链接:Eureka GitHub Wiki
Eureka 主要分为两个部分
- Eureka Server:作为注册中心Server端,向微服务应用程序提供服务注册、发现、健康检查等能力。
- Eureka Client:服务提供者,服务启动时,会向Eureka Server注册自己的信息(IP、端口、服务信息等),Eureka Server会存储这些信息。
关于Eureka的学习,主要包含以下三个部分:
- 搭建Eureka Server。
- 将order-service,product-service都注册到Eureka。
- order-service远程调用时,从Eureka中获取product-service的服务列表,然后进行交互。
搭建Eureka Server
Eureka-server 是⼀个独⽴的微服务.
我们把原来的 spring-cloud-demo 项目复制一份成 spring-cloud-eureka 并且修改一些文件的内容
记得把新项目的 .idea 文件删除,可能会导致一些错误
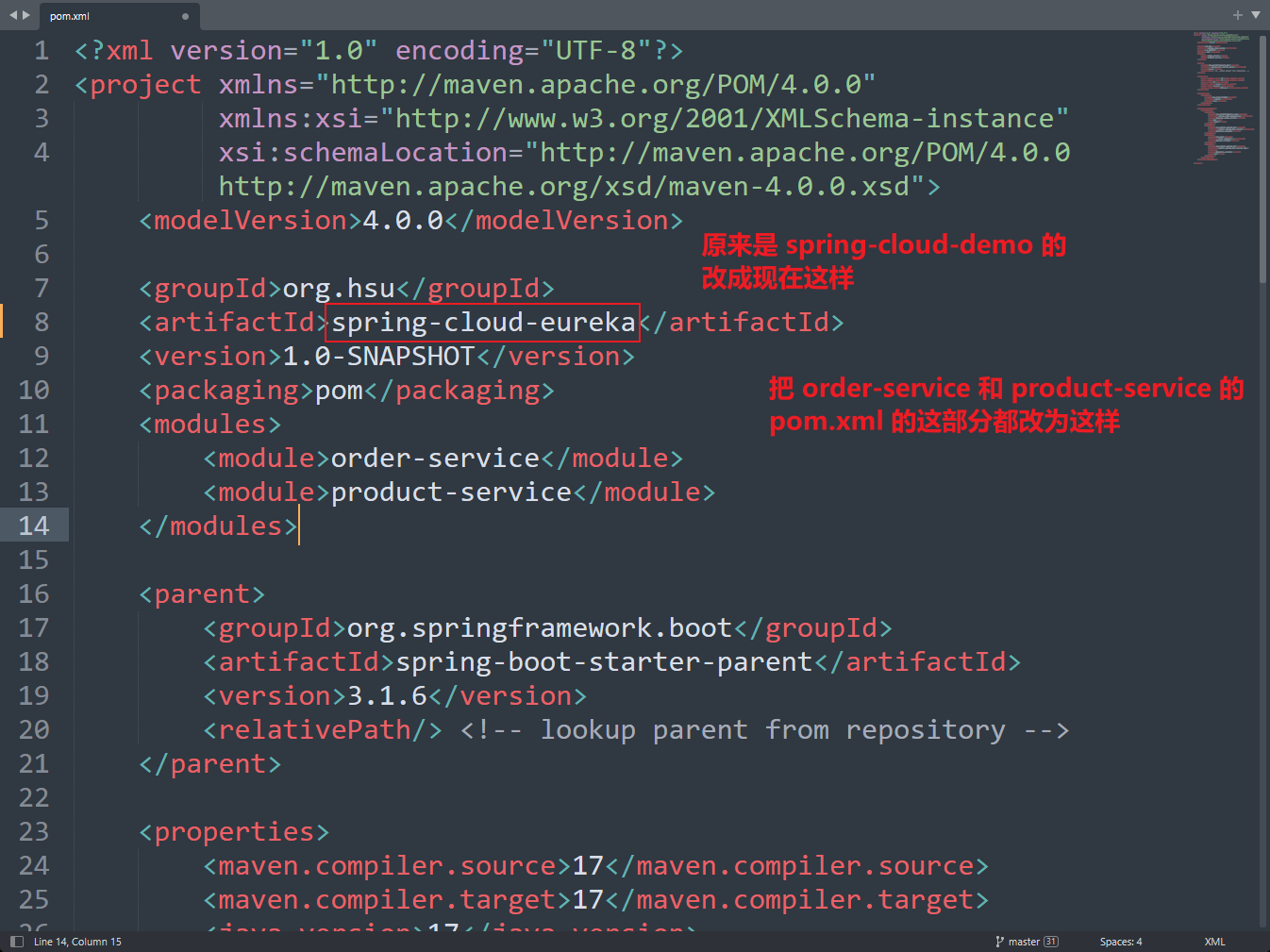
创建Eureka-server 子模块

引入eureka-server依赖
<dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency>
</dependencies>
项目构建插件
<build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins>
</build>
完善启动类
给该项⽬编写⼀个启动类, 并在启动类上添加 @EnableEurekaServer 注解, 开启eureka注册中⼼服务
@EnableEurekaServer
@SpringBootApplication
public class EurekaServerApplication {public static void main(String[] args) {SpringApplication.run(EurekaServerApplication.class, args);}
}
编写配置文件
server:port: 10010spring:application:name: eureka-servereureka:instance:hostname: localhostclient:fetch-registry: false # 表示是否从Eureka Server获取注册信息,默认为true。因为这是一个单点的Eureka Server,不需要同步其他的Eureka Server节点的数据,这里设置为false。register-with-eureka: false # 表示是否将自己注册到Eureka Server,默认为true。由于当前应用就是Eureka Server,故而设置为false。service-url:# 设置与Eureka Server的地址,查询服务和注册服务都需要依赖这个地址。defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
启动服务
启动服务, 访问注册中⼼: http://127.0.0.1:10010/
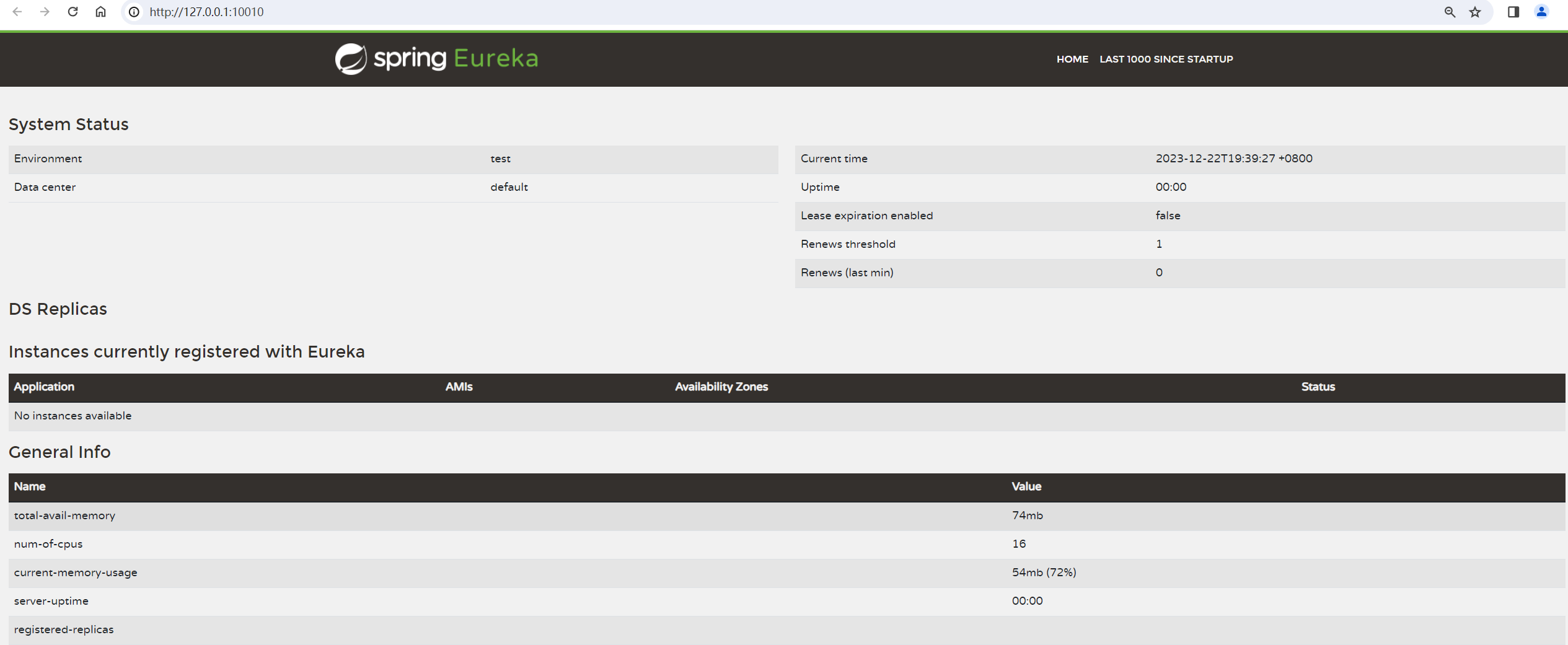
可以看到eureka-server已经启动成功了
服务注册
接下来我们把 product-service 注册到eureka-server中
引入eureka-client依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
完善配置文件
添加服务名称和eureka地址
- 为应用程序命名为 “product-service”。
- 启用 Spring Cloud Config 的服务发现功能,允许应用程序动态获取配置信息。
- 注册应用程序到 Eureka 注册中心,使其能够被其他服务发现和调用。
spring:application:name: product-servicecloud:config:discovery:enabled: true
eureka:client:service-url:defaultZone: http://127.0.0.1:10010/eureka
当前完整的配置文件
server:port: 9090spring:datasource:url: jdbc:mysql://127.0.0.1:3306/cloud_product?characterEncoding=utf8&useSSL=falseusername: rootpassword: 123456driver-class-name: com.mysql.cj.jdbc.Driverapplication:name: product-servicecloud:config:discovery:enabled: trueeureka:client:service-url:defaultZone: http://127.0.0.1:10010/eurekamybatis:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImplmap-underscore-to-camel-case: true
启动服务
启动 product-service
然后刷新注册中⼼: http://127.0.0.1:10010/
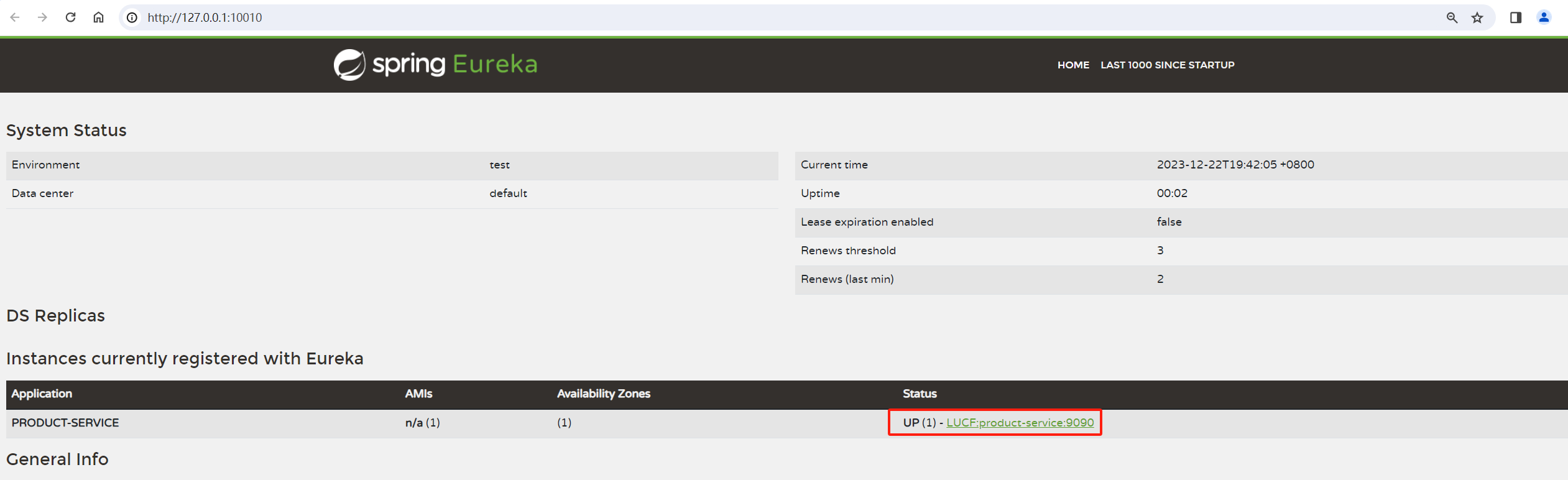
可以看到product-service已经注册到 eureka上了
服务发现
接下来我们修改order-service, 在远程调⽤时, 从eureka-server拉取product-service的服务信息, 实现服务发现
引入eureka-client依赖
服务注册和服务发现都封装在eureka-client依赖中, 所以服务发现时, 也是引⼊eureka-client依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
完善配置文件
服务发现也需要知道eureka地址,因此配置内容依然与服务注册⼀致,都是配置eureka信息
- 动态配置管理: 应用程序可以从 Spring Cloud Config 服务器动态获取配置信息,而无需在代码中硬编码。
- 服务发现和注册: 应用程序会注册到 Eureka 注册中心,使其能够被其他服务发现和调用。
- 负载均衡和故障转移: Eureka 注册中心提供了服务发现和负载均衡的功能,可以帮助实现高可用的微服务架构。
spring:application:name: order-servicecloud:config:discovery:enabled: true
eureka:client:service-url:defaultZone: http://127.0.0.1:10010/eureka
当前完整的配置文件
server:port: 8080spring:datasource:url: jdbc:mysql://127.0.0.1:3306/cloud_order?characterEncoding=utf8&useSSL=falseusername: rootpassword: 123456driver-class-name: com.mysql.cj.jdbc.Driverapplication:name: order-servicecloud:config:discovery:enabled: truemybatis:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImplmap-underscore-to-camel-case: true # 配置驼峰自动转换eureka:client:service-url:defaultZone: http://127.0.0.1:10010/eureka
远程调用
远程调⽤时, 我们需要从eureka-server中获取product-service的列表(可能存在多个服务), 并选择其中⼀个进⾏调⽤
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import lombok.extern.slf4j.Slf4j;import javax.annotation.Resource;
import java.util.List;@Slf4j
@Service
public class OrderService {@Autowiredprivate OrderMapper orderMapper;@Resourceprivate DiscoveryClient discoveryClient;@Autowiredprivate RestTemplate restTemplate;public OrderInfo selectOrderById(Integer orderId) {OrderInfo orderInfo = orderMapper.selectOrderById(orderId);// 根据应用名称从Eureka获取服务列表List<ServiceInstance> instances = discoveryClient.getInstances("product-service");// 服务可能有多个, 获取第一个ServiceInstance instance = instances.get(0);log.info(instance.getInstanceId());// 拼接URLString url = instance.getUri() + "/product/" + orderInfo.getProductId();log.info("远程调用url:{}", url);// 调用远程服务获取ProductInfoProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);orderInfo.setProductInfo(productInfo);return orderInfo;}
}
启动服务
启动 order-service
然后刷新注册中⼼: http://127.0.0.1:10010/
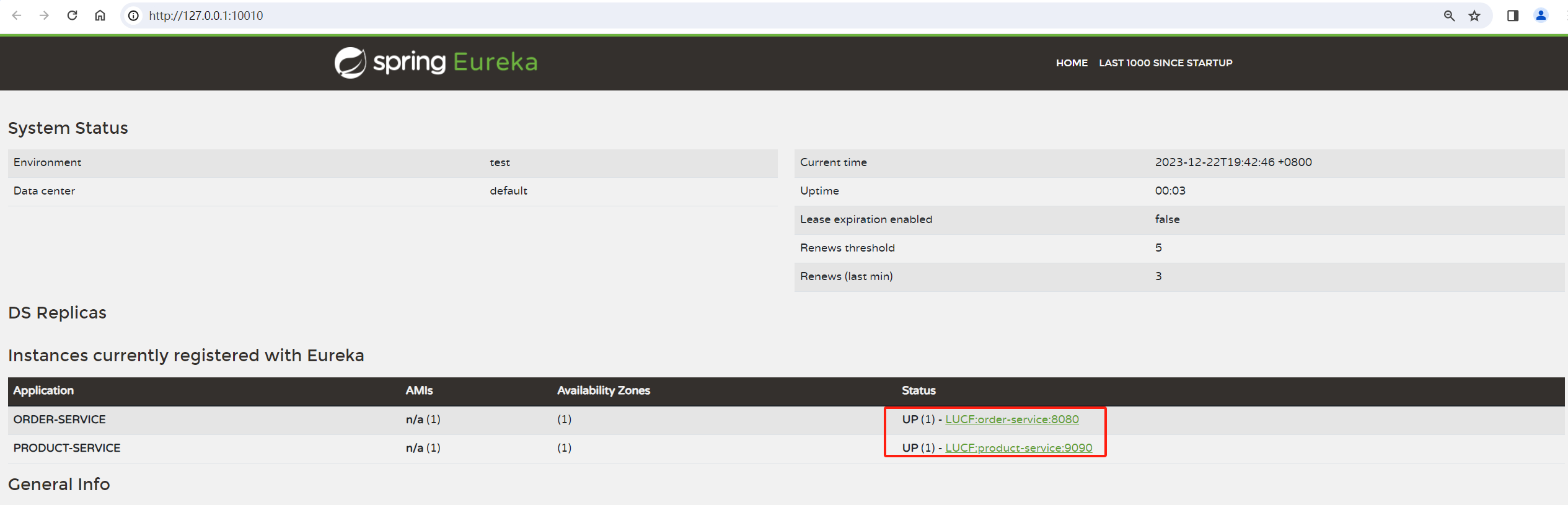
可以看到order-service已经注册到 eureka上了
访问接⼝: http://127.0.0.1:8080/order/1
可以看到, 远程调⽤也成功了.

Eureka 和 Zookeeper 区别
-
项目背景:
- Eureka:由 Netflix 开源,用于服务注册和发现。
- Zookeeper:由 Apache 开源,广泛用于分布式系统的协调服务。
-
一致性与可用性:
- Eureka:遵循 AP 原则,保证系统高可用性,但数据一致性可能会有延迟。
- Zookeeper:遵循 CP 原则,确保数据一致性,但可能会在节点故障时影响系统的可用性。
-
节点角色:
- Eureka:所有节点在服务注册和发现中功能平等。
- Zookeeper:节点分为 Leader、Follower 和 Observer。Leader 负责写操作,Follower 负责读操作。当 Leader 故障时,需要重新选举新 Leader,选举期间可能会出现短暂的系统不可用。
多机部署与负载均衡 - LoadBalance
负载均衡介绍
问题描述
观察之前远程调用的代码:
List<ServiceInstance> instances = discoveryClient.getInstances("product-service");
//服务可能有多个, 获取第一个
EurekaServiceInstance instance = (EurekaServiceInstance) instances.get(0);
- 根据应用名称获取了服务实例列表。
- 从列表中选择了一个服务实例。
思考: 如果一个服务对应多个实例呢?流量是否可以合理地分配到多个实例呢?
现象观察
我们再启动2个 product-service 实例。
选中要启动的服务,右键选择 Copy Configuration...
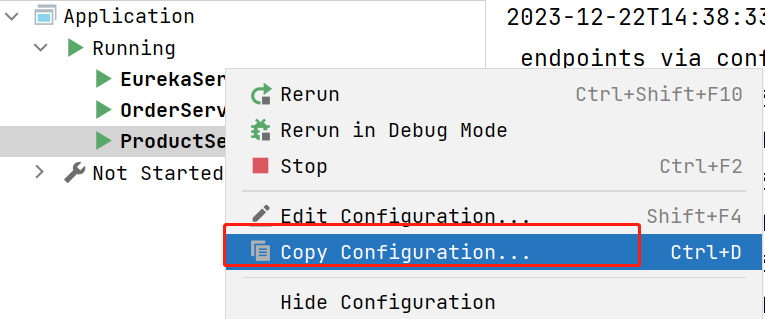
在弹出的框中,选择 Modify options -> Add VM options
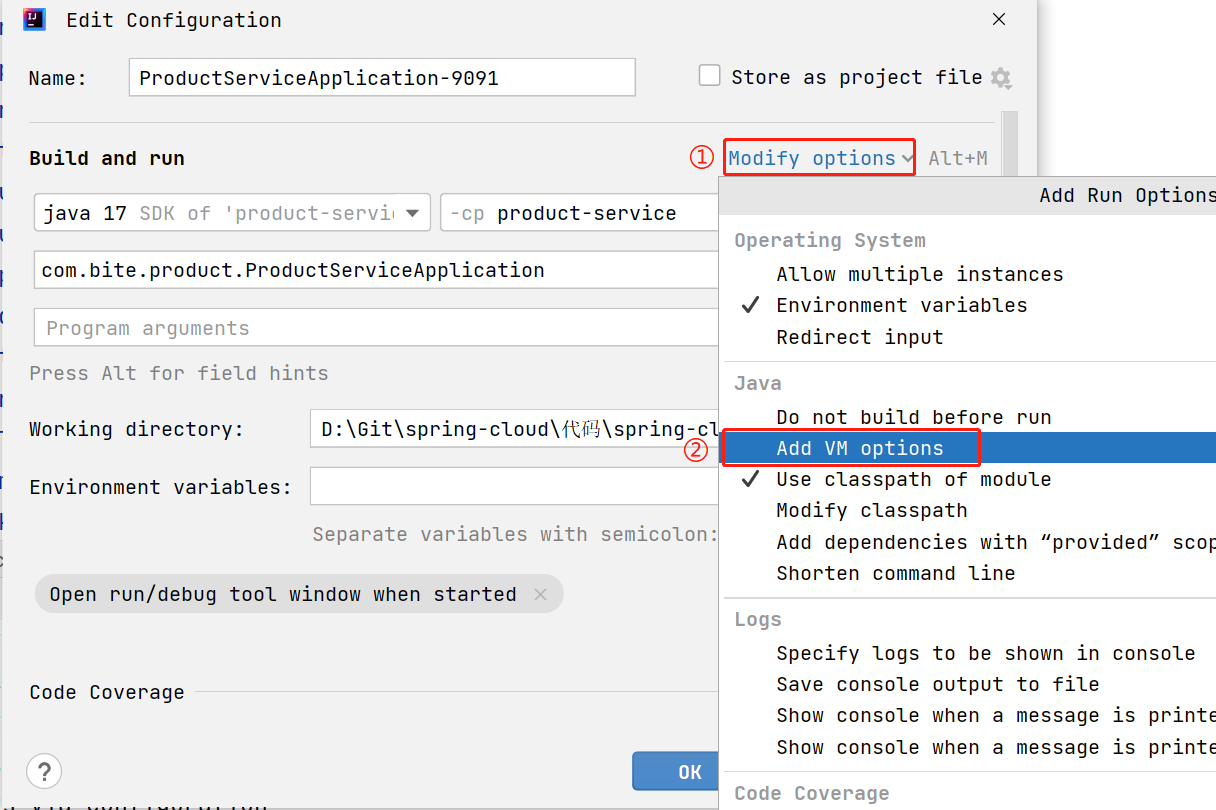
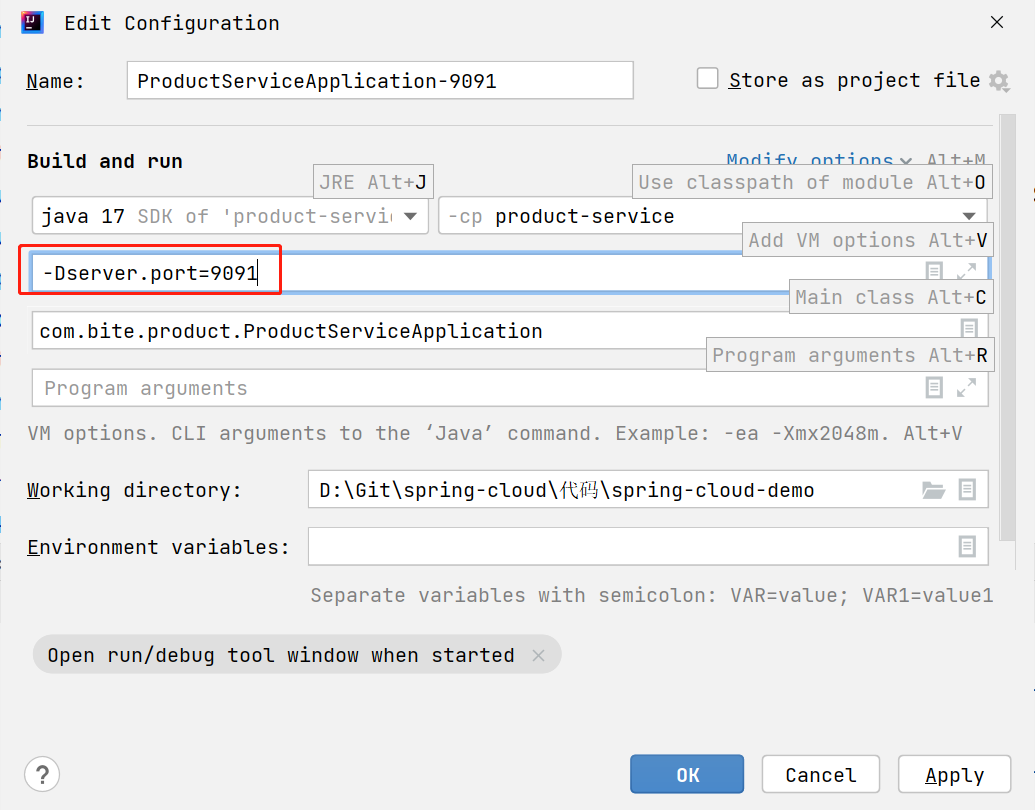
添加 VM options : -Dserver.port=9091
9091 为服务启动的端口号,根据自己的情况进行修改
现在IDEA的Service窗口就会多出来一个启动配置,右键启动服务即可
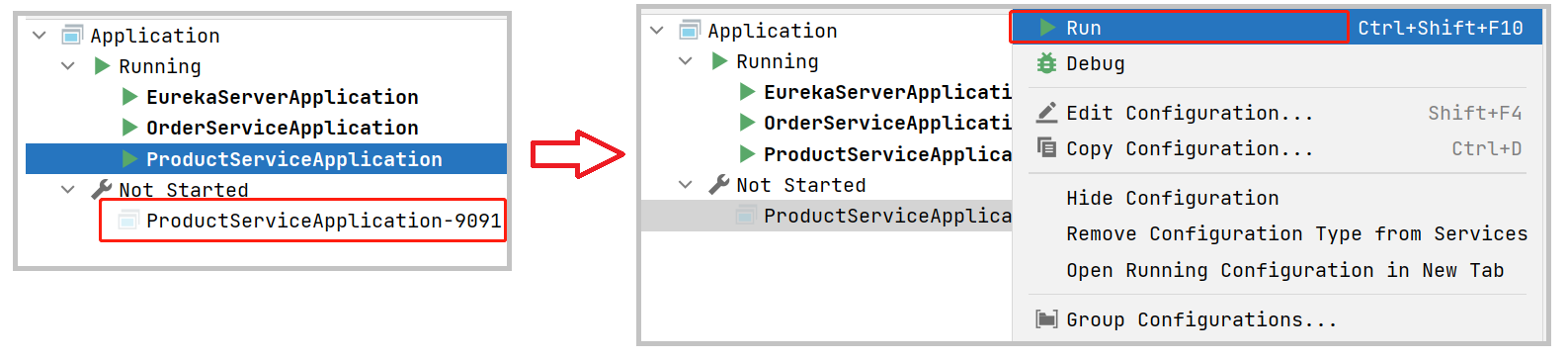
同样的操作,再启动1个实例,共启动3个服务。
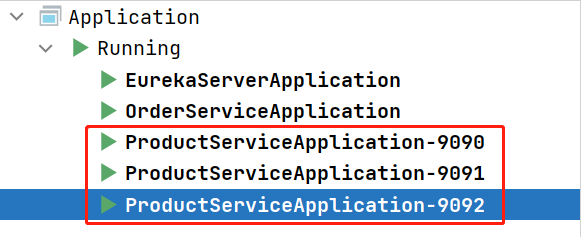
观察Eureka,可以看到 product-service 下有三个实例:
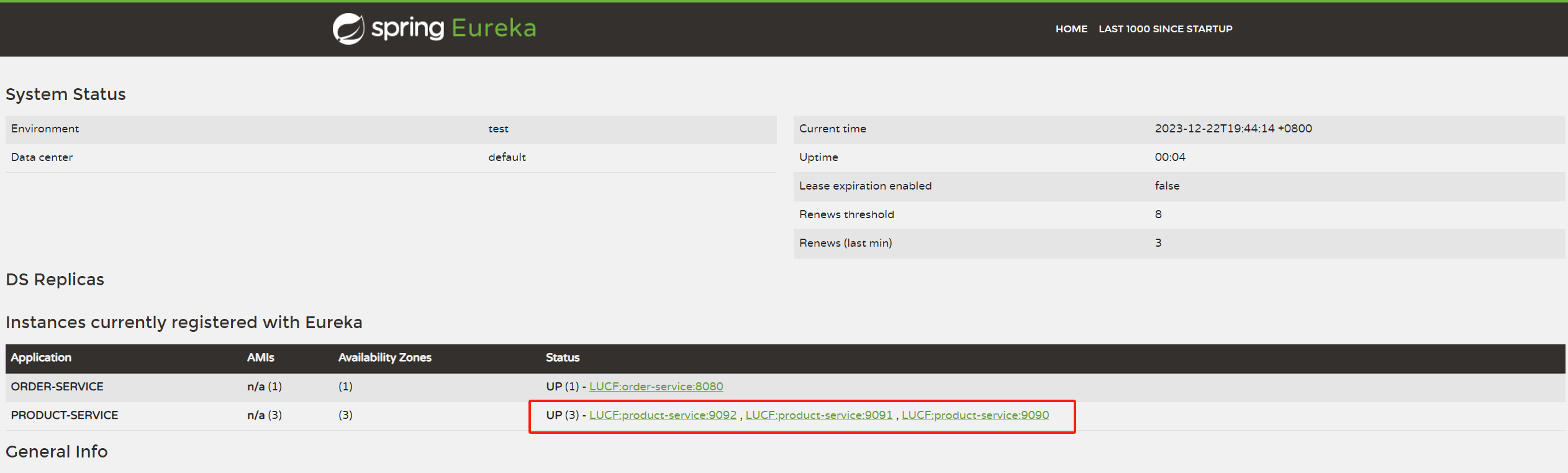
访问结果:
访问: http://127.0.0.1:8080/order/1
11:46:05.684+08:00 INFO 23128 --- [nio-8080-exec-1] com.bite.order.service.OrderService : LUCF:product-service:9090
11:46:06.435+08:00 INFO 23128 --- [nio-8080-exec-2] com.bite.order.service.OrderService : LUCF:product-service:9090
11:46:07.081+08:00 INFO 23128 --- [nio-8080-exec-3] com.bite.order.service.OrderService : LUCF:product-service:9090
通过日志可以观察到,请求多次访问,都是同一台机器。
这肯定不是我们想要的结果,我们启动多个实例,是希望可以分担其他机器的负荷,那么如何实现呢?
解决方案
我们可以对上述代码进行简单修改:
@Slf4j
@Service
public class OrderService {@Autowiredprivate OrderMapper orderMapper;@Resourceprivate DiscoveryClient discoveryClient;@Autowiredprivate RestTemplate restTemplate;// 计数器private AtomicInteger count = new AtomicInteger(1);private List<ServiceInstance> instances;// 如果这块代码写在方法中,不能保证Eureka给我们返回的结果是不变的// 可能第一次是120,第二次是012,第三次是210@PostConstructpublic void init() {// 根据应用名称从Eureka获取服务列表instances = discoveryClient.getInstances("product-service");}public OrderInfo selectOrderById(Integer orderId) {OrderInfo orderInfo = orderMapper.selectOrderById(orderId);// 计算轮流的实例indexint index = count.getAndIncrement() % instances.size();// 获取实例ServiceInstance instance = instances.get(index);log.info(instance.getInstanceId());// 拼接URLString url = instance.getUri() + "/product/" + orderInfo.getProductId();log.info("远程调用url:{}", url);// 调用远程服务获取ProductInfoProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);orderInfo.setProductInfo(productInfo);return orderInfo;}
}
@Slf4j
@RestController
@RequestMapping("/product")
public class ProductController {@Autowiredprivate ProductService productService;@RequestMapping("/{productId}")public ProductInfo getProductById(@PathVariable("productId") Integer productId) {log.info("接收到参数:productId " + productId);return productService.selectProductById(productId);}
}
观察日志
12:02:13.245+08:00 INFO 1800 --- [nio-8080-exec-1] com.bite.order.service.OrderService : LUCF:product-service:9091
12:02:15.723+08:00 INFO 1800 --- [nio-8080-exec-2] com.bite.order.service.OrderService : LUCF:product-service:9090
12:02:16.534+08:00 INFO 1800 --- [nio-8080-exec-3] com.bite.order.service.OrderService : LUCF:product-service:9092
12:02:16.864+08:00 INFO 1800 --- [nio-8080-exec-4] com.bite.order.service.OrderService : LUCF:product-service:9091
12:02:17.078+08:00 INFO 1800 --- [nio-8080-exec-5] com.bite.order.service.OrderService : LUCF:product-service:9090
12:02:17.260+08:00 INFO 1800 --- [nio-8080-exec-6] com.bite.order.service.OrderService : LUCF:product-service:9092
12:02:17.431+08:00 INFO 1800 --- [nio-8080-exec-7] com.bite.order.service.OrderService : LUCF:product-service:9091
通过日志可以看到,请求被均衡地分配到了不同的实例上,这就是负载均衡。
什么是负载均衡
负载均衡(Load Balance,简称 LB)是高并发、高可用系统必不可少的关键组件。当服务流量增大时,通常会采用增加机器的方式进行扩容,负载均衡就是用来在多个机器或者其他资源中,按照一定的规则合理分配负载。
一个团队最开始只有一个人,后来随着工作量的增加,公司又招聘了几个人。负载均衡就是:如何把工作量均衡地分配到这几个人身上,以提高整个团队的效率。
负载均衡的一些实现
上面的例子中,我们只是简单地对实例进行了轮询,但真实的业务场景会更加复杂。比如根据机器的配置进行负载分配,配置高的分配的流量高,配置低的分配流量低等。
类似企业员工:能力强的员工可以多承担一些工作。
服务多机部署时,开发人员都需要考虑负载均衡的实现,所以也出现了一些负载均衡器,来帮助我们实现负载均衡。
负载均衡分为服务端负载均衡和客户端负载均衡。
服务端负载均衡
在服务端进行负载均衡的算法分配。
比较有名的服务端负载均衡器是 Nginx。请求先到达 Nginx 负载均衡器,然后通过负载均衡算法,在多个服务器之间选择一个进行访问。
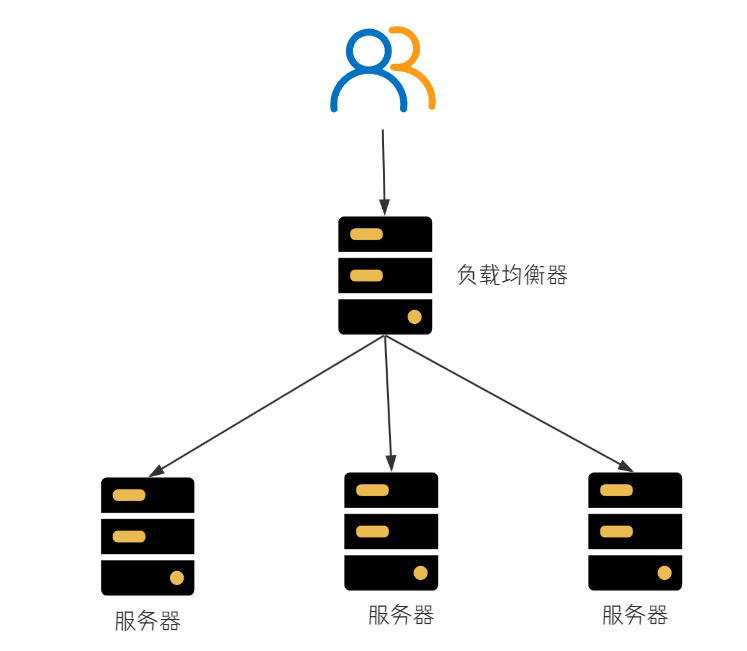
客户端负载均衡
在客户端进行负载均衡的算法分配。
把负载均衡的功能以库的方式集成到客户端,而不再是由一台指定的负载均衡设备集中提供。
比如 Spring Cloud 的 Ribbon,请求发送到客户端,客户端从注册中心(比如 Eureka)获取服务列表,在发送请求前通过负载均衡算法选择一个服务器,然后进行访问。
Ribbon 是 Spring Cloud 早期的默认实现,由于不再维护,所以最新版本的 Spring Cloud 负载均衡集成的是 Spring Cloud LoadBalancer(Spring Cloud 官方维护)。
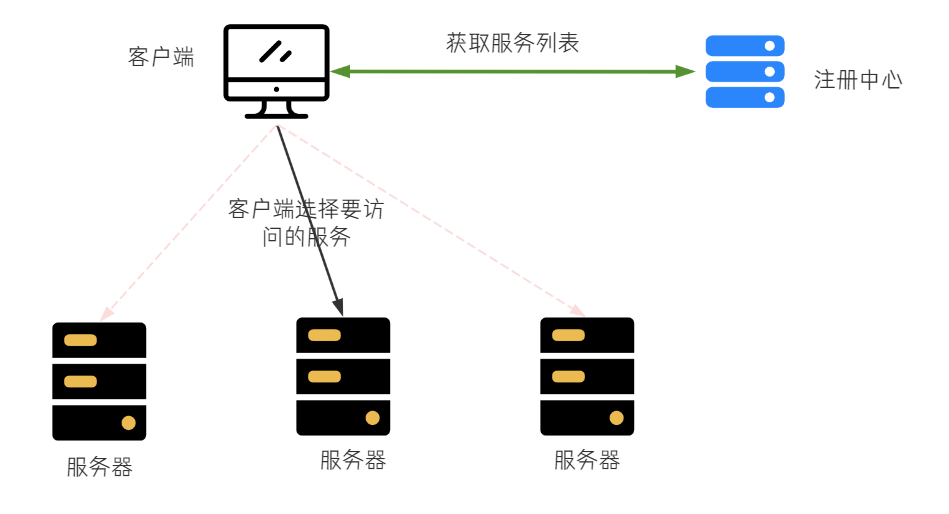
客户端负载均衡和服务端负载均衡最大的区别在于服务清单所存储的位置。
Spring Cloud LoadBalancer
快速上⼿
SpringCloud 从 2020.0.1 版本开始,移除了Ribbon 组件,使⽤Spring Cloud LoadBalancer 组件来代替 Ribbon 实现客⼾端负载均衡.
使用Spring Cloud LoadBalancer实现负载均衡
- 给 RestTemplate 这个Bean添加
@LoadBalanced注解就可以
@Configuration
public class BeanConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate() {return new RestTemplate();}
}
- 修改IP端⼝号为服务名称
@Slf4j
@Service
public class OrderService {@Autowiredprivate OrderMapper orderMapper;@Resourceprivate DiscoveryClient discoveryClient;@Autowiredprivate RestTemplate restTemplate;// 计数器private AtomicInteger count = new AtomicInteger(1);private List<ServiceInstance> instances;// 如果这块代码写在方法中,不能保证Eureka给我们返回的结果是不变的// 可能第一次是120,第二次是012,第三次是210@PostConstructpublic void init() {// 根据应用名称从Eureka获取服务列表instances = discoveryClient.getInstances("product-service");}public OrderInfo selectOrderById(Integer orderId) {OrderInfo orderInfo = orderMapper.selectOrderById(orderId);// 使用服务名称替换IP地址和端口号String url = "http://product-service/product/" + orderInfo.getProductId();log.info("远程调用url:{}", url);// 调用远程服务获取ProductInfoProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);orderInfo.setProductInfo(productInfo);return orderInfo;}
}
启动多个product-service实例
按照之前的⽅式, 启动多个product-service实例
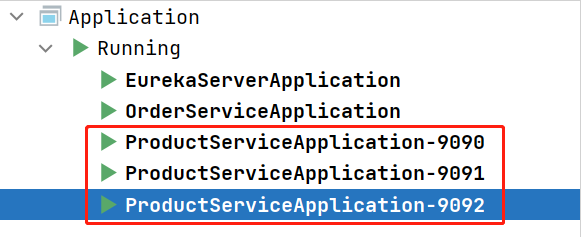
测试负载均衡
连续多次发起请求: http://127.0.0.1:8080/order/1
观察product-service的⽇志, 会发现请求被分配到这3个实例上了
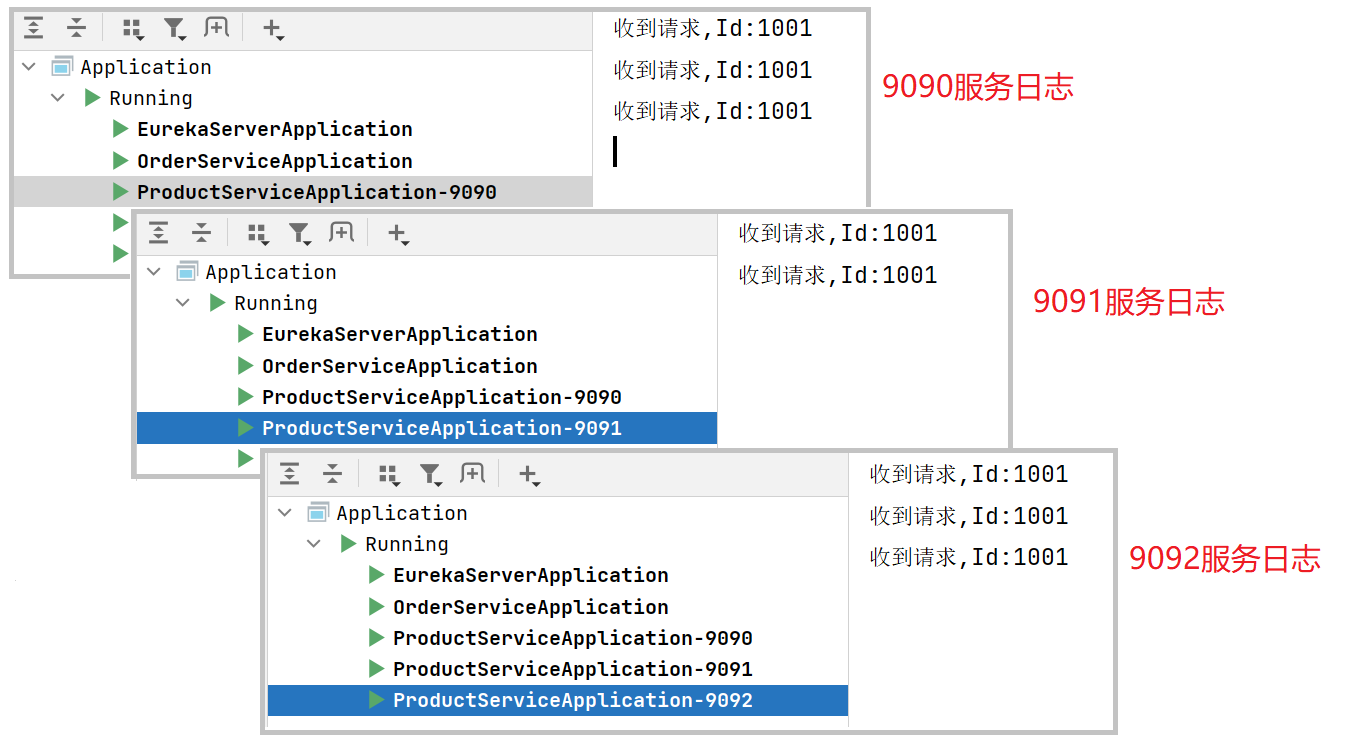
负载均衡策略
负载均衡策略是⼀种思想, ⽆论是哪种负载均衡器, 它们的负载均衡策略都是相似的. Spring Cloud LoadBalancer 仅⽀持两种负载均衡策略: 轮询策略 和 随机策略
-
轮询(Round Robin): 轮询策略是指服务器轮流处理⽤⼾的请求. 这是⼀种实现最简单, 也最常⽤的策略. ⽣活中也有类似的场景, ⽐如学校轮流值⽇, 或者轮流打扫卫⽣.
-
随机选择(Random): 随机选择策略是指随机选择⼀个后端服务器来处理新的请求.
自定义负载均衡策略
Spring Cloud LoadBalancer 默认负载均衡策略是 轮询策略, 实现是 RoundRobinLoadBalancer, 如果服务的消费者如果想采⽤随机的负载均衡策略, 也⾮常简单.
参考官⽹地址:Spring Cloud LoadBalancer :: Spring Cloud Commons
- 定义随机算法对象, 通过
@Bean将其加载到 Spring 容器中
此处使⽤Spring Cloud LoadBalancer提供的 RandomLoadBalancer
public class CustomLoadBalancerConfiguration {@BeanReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,LoadBalancerClientFactory loadBalancerClientFactory) {String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class),name);}
}
注意: 该类需要满⾜:
- 不⽤
@Configuration注释- 在组件扫描范围内
- 使⽤
@LoadBalancerClient或者@LoadBalancerClients注解
在 RestTemplate 配置类上⽅, 使⽤ @LoadBalancerClient 或 @LoadBalancerClients 注解, 可以对不同的服务提供⽅配置不同的客⼾端负载均衡算法策略.
由于项⽬中只有⼀个服务提供者, 所以使⽤@LoadBalancerClient
@LoadBalancerClient(name = "product-service", configuration = CustomLoadBalancerConfiguration.class)
@Configuration
public class BeanConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate() {return new RestTemplate();}
}
@LoadBalancerClient 注解说明
- name: 该负载均衡策略对哪个服务⽣效(服务提供⽅)
- configuration : 该负载均衡策略 ⽤哪个负载均衡策略实现.
通过多次测试 http://127.0.0.1:8080/order/1 发现,上面 CustomLoadBalancerConfiguration 的实现是是随机选择的
LoadBalancer 原理
LoadBalancer 的实现, 主要是 LoadBalancerInterceptor , 这个类会对 RestTemplate 的请求进⾏拦截, 然后从Eureka根据服务id获取服务列表,随后利⽤负载均衡算法得到真实的服务地址信息,替换服务id
我们来看看源码实现:
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor {// ...@Overridepublic ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException {URI originalUri = request.getURI();String serviceName = originalUri.getHost();Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);// Execute the request through the load balancerreturn (ClientHttpResponse) this.loadBalancer.execute(serviceName, this.requestFactory.createRequest(request, body, execution));}
}
可以看到这⾥的intercept⽅法, 拦截了⽤⼾的HttpRequest请求,然后做了⼏件事:
request.getURI()从请求中获取uri, 也就是 http://product-service/product/1001originalUri.getHost()从uri中获取路径的主机名, 也就是服务id,product-serviceloadBalancer.execute根据服务id, 进⾏负载均衡, 并处理请求
点进去继续跟踪
public class BlockingLoadBalancerClient implements LoadBalancerClient {// ...@Overridepublic <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {String hint = this.getHint(serviceId);LoadBalancerRequestAdapter<T, TimedRequestContext> lbRequest = new LoadBalancerRequestAdapter(request, this.buildRequestContext(request, hint));Set<LoadBalancerLifecycle> supportedLifecycleProcessors = this.getSupportedLifecycleProcessors(serviceId);supportedLifecycleProcessors.forEach((lifecycle) -> {lifecycle.onStart(lbRequest);});// 根据 serviceId 和负载均衡策略选择服务实例ServiceInstance serviceInstance = this.choose(serviceId, lbRequest);if (serviceInstance == null) {supportedLifecycleProcessors.forEach((lifecycle) -> {lifecycle.onComplete(new CompletionContext(Status.DISCARD, lbRequest, new EmptyResponse()));});throw new IllegalStateException("No instances available for " + serviceId);} else {return this.execute(serviceId, serviceInstance, lbRequest);}}/*** 根据 serviceId 和负载均衡策略选择服务实例*/public <T> ServiceInstance choose(String serviceId, Request<T> request) {// 获取负载均衡器ReactiveLoadBalancer<ServiceInstance> loadBalancer = this.loadBalancerClientFactory.getInstance(serviceId);if (loadBalancer == null) {return null;} else {// 根据负载均衡算法,在列表中选择一个服务实例Response<ServiceInstance> loadBalancerResponse = (Response) Mono.from(loadBalancer.choose(request)).block();return loadBalancerResponse == null ? null : (ServiceInstance) loadBalancerResponse.getServer();}}
}
服务部署(Linux)
接下来我们把服务部署在Linux系统上
准备数据
安装 MySQL
参考上面 MySQL安装 的笔记
数据初始化
同理参考上面 环境和工程搭建的数据准备 的笔记
修改配置文件
修改配置⽂件中, 数据库的密码
分别在 order-service 和 product-service 创建 application.yml、application-dev.yml、application-prod.yml,下面以 order-service 的举例,product-service 同理,eureka-server 不用修改
spring:profiles:active: @profile.name@
server:port: 8080spring:datasource:url: jdbc:mysql://127.0.0.1:3306/cloud_order?characterEncoding=utf8&useSSL=falseusername: rootpassword: 123456driver-class-name: com.mysql.cj.jdbc.Driverapplication:name: order-servicecloud:config:discovery:enabled: truemybatis:configuration:
# log-impl: org.apache.ibatis.logging.stdout.StdOutImplmap-underscore-to-camel-case: true # 配置驼峰自动转换eureka:client:service-url:defaultZone: http://127.0.0.1:10010/eureka
server:port: 8080spring:datasource:url: jdbc:mysql://127.0.0.1:3306/cloud_order?characterEncoding=utf8&useSSL=falseusername: rootpassword: 云服务器的数据库密码driver-class-name: com.mysql.cj.jdbc.Driverapplication:name: order-servicecloud:config:discovery:enabled: truemybatis:configuration:
# log-impl: org.apache.ibatis.logging.stdout.StdOutImplmap-underscore-to-camel-case: true # 配置驼峰自动转换eureka:client:service-url:defaultZone: http://127.0.0.1:10010/eureka
修改pom.xml
添加下面这部分
<profiles><profile><id>dev</id><properties><profile.name>dev</profile.name></properties></profile><profile><id>prod</id><properties><profile.name>prod</profile.name></properties></profile>
</profiles>
服务构建打包
采⽤Maven打包, 需要对3个服务分别打包:
eureka-server, order-service, product-service
- 打包⽅式和SpringBoot项⽬⼀致, 依次对三个项⽬打包即可.

启动服务
- 上传Jar包到云服务器
第⼀次上传需要安装lrzsz
apt install lrzsz
直接拖动⽂件到xshell窗⼝, 上传成功.
最好创建一个文件夹比如 spring_cloud 什么的,放这些jar包,然后在里面创建个 logs 文件夹放日志文件什么的
- 启动服务
#后台启动eureka-server, 并设置输出⽇志到logs/eureka.log
nohup java -jar eureka-server.jar >logs/eureka.log &#后台启动order-service, 并设置输出⽇志到logs/order.log
nohup java -jar order-service.jar >logs/order.log &#后台启动product-service, 并设置输出⽇志到logs/order.log
nohup java -jar product-service.jar >logs/product-9090.log &
再多启动两台product-service实例
#启动实例, 指定端⼝号为9091
nohup java -jar product-service.jar --server.port=9091 >logs/product-9091.log &#启动实例, 指定端⼝号为9092
nohup java -jar product-service.jar --server.port=9092 >logs/product-9092.log &
开放端口号
根据⾃⼰项⽬设置的情况, 在云服务器上开放对应的端⼝号
不同的服务器⼚商, 开放端⼝号的⼊⼝不同, 需要⾃⾏找⼀找或者咨询对应的客服⼈员.
以腾讯云服务器举例:
- 进⼊防⽕墙管理⻚⾯

- 添加规则

端⼝号写需要开放的端⼝号, 多个端⼝号以逗号分割.
测试
- 访问Eureka Server: http://110.41.51.65:10010
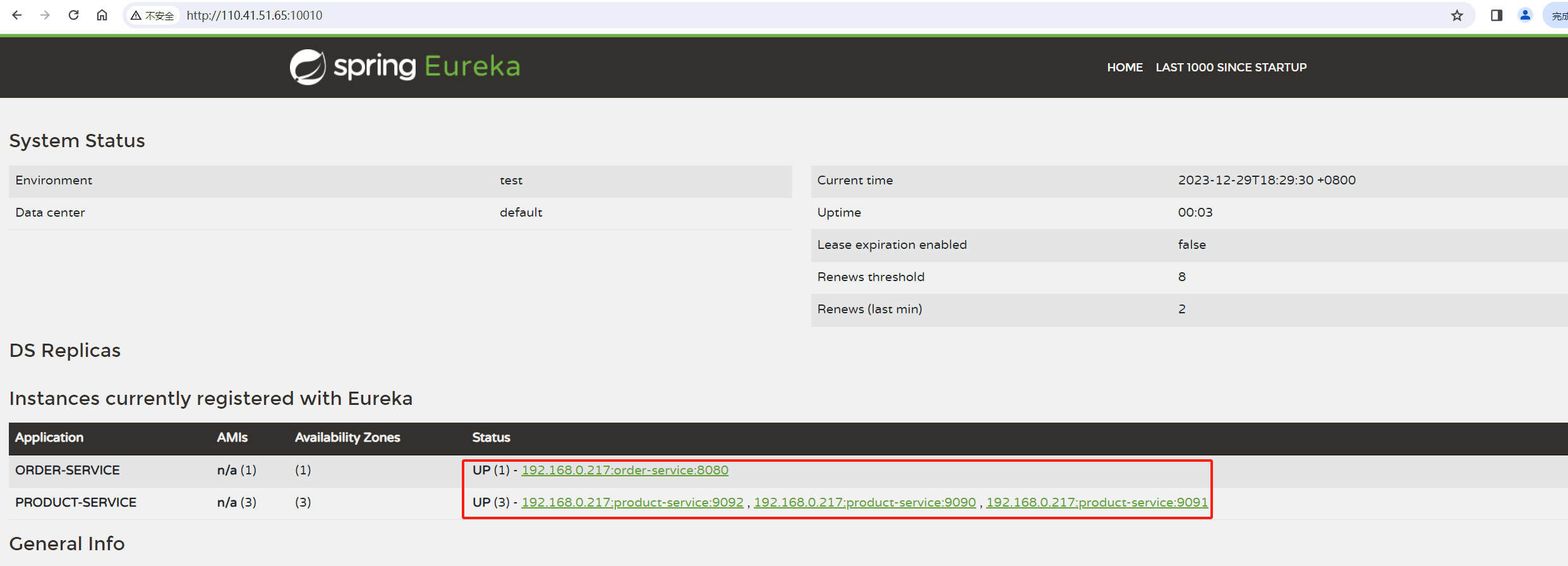
- 访问订单服务接⼝: http://110.41.51.65:8080/order/1

远程调⽤成功.