stanford cs231 编程作业(assignment1,Q3: softmax classifier
softmax classifier和svm classifier的assignment绝大多部分都是重复的,这里只捡几个重点。
1,softmax_loss_naive函数,尤其是dW部分
1,1 正向传递


第i张图的在所有分类下的得分:
softmax概率,其中C是总类别,y[i]是样本 i 的真实标签:
第i张图的softmax损失函数:
所有样本softmax的加权和:
1,2 反向传递(需区分正确分类与其他分类)
1,2,1 对正确分类![S[y[i]]](https://latex.csdn.net/eq?S%5By%5Bi%5D%5D) 而言:
而言:
其中:
整合后:
Tips:商函数的导数
1,2,2 对其他分类![S[j],j\neq y_{i}](https://latex.csdn.net/eq?S%5Bj%5D%2Cj%5Cneq%20y_%7Bi%7D) 而言:
而言:
其中:
整合后:
2,学习率(learning rate)与正则化约束的系数(regularization strength)
2,1 初次尝试
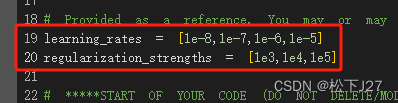
计算结果:
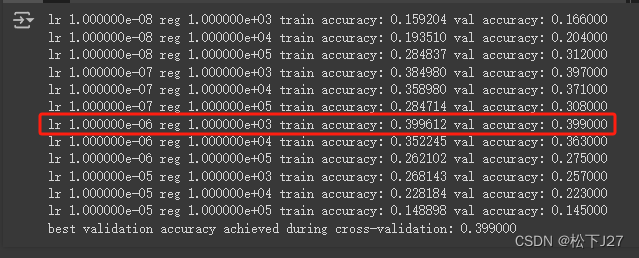
观察:
根据初次尝试的计算结果得出,当lr=1e-6时和reg=1e3时,验证集的准确率最高接近40%的准确率。
2,2 基于初次尝试的结果重新选择lr和reg
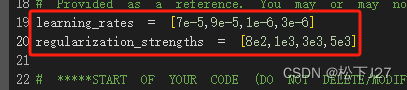
在lr=1e-6时和reg=1e3的附近分别取了几个值,得到如下结果:
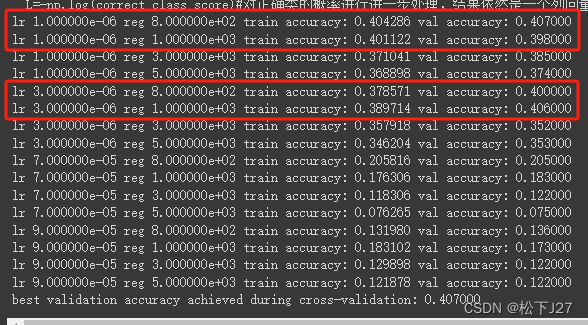
观察:
从上面的结果来看当lr在e-6这个数量级上,且reg在e2这个数量级上时,accuracy是高的。
2,3 最后一次尝试
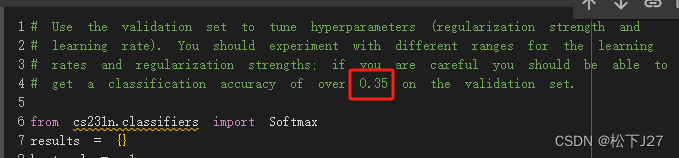
因为按照官方的要求,只要验证集的正确类能够达到35%就够了。但基于上面的结果似乎还能再逼近一下极限。
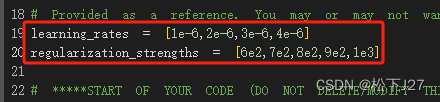
这次,lr的调整就限制在了e-6。reg的值域基本上是在5e2~1e3之间浮动。
实验结果:

观察:
总的正确率都很高,最大值出现在lr=2e-6,reg=7e2。
思考题:

每一类所对应的权重矩阵W的可视化:

可参考课件,每个W矩阵都是一个和图像同等大小的特征:
3,Python code
3,1 softmax function(code里面有较为详细的注释)
from builtins import range
import numpy as np
from random import shuffle
from past.builtins import xrange
import ipdbdef softmax_loss_naive(W, X, y, reg):"""Softmax loss function, naive implementation (with loops)Inputs have dimension D, there are C classes, and we operate on minibatchesof N examples.Inputs:- W: A numpy array of shape (D, C) containing weights.- X: A numpy array of shape (N, D) containing a minibatch of data.- y: A numpy array of shape (N,) containing training labels; y[i] = c meansthat X[i] has label c, where 0 <= c < C.- reg: (float) regularization strengthReturns a tuple of:- loss as single float- gradient with respect to weights W; an array of same shape as W"""# Initialize the loss and gradient to zero.loss = 0.0dW = np.zeros_like(W)############################################################################## TODO: Compute the softmax loss and its gradient using explicit loops. ## Store the loss in loss and the gradient in dW. If you are not careful ## here, it is easy to run into numeric instability. Don't forget the ## regularization! ############################################################################### *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****num_samples = X.shape[0]num_classes = W.shape[1]for i in range(num_samples): Xi=X[i,:]#求每张图的logitslogits=Xi@W#当logit很大时,指数函数e^x会变得非常大,这很容易导致计算结果超出当前类型的最大值。#因此,在计算exp之前要对原始数据logits做如下处理。logits_shifted = logits-np.max(logits)exp_logits =np.exp(logits_shifted)#求logits向量的指数#指数化后再归一化得到概率sum_exp=np.sum(exp_logits)P=exp_logits/sum_exp#取出正确类的概率correct_class_score=P[y[i]]#正确类概率的负自然对数Li=-np.log(correct_class_score)#sum of all samplesloss+=Li#Calc grad#矩阵W共有D行,C列,所以每列表示一个分类,因此在计算dW时应按列选择。for j in range(num_classes):if j == y[i]:dW[:,j]+=(P[j]-1)*Xielse:dW[:,j]+=P[j]*Xi# Avgloss/=num_samplesdW/=num_samples# +Regloss+=reg*np.sum(W*W)dW+=2*reg*W# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return loss, dWdef softmax_loss_vectorized(W, X, y, reg):"""Softmax loss function, vectorized version.Inputs and outputs are the same as softmax_loss_naive."""# Initialize the loss and gradient to zero.loss = 0.0dW = np.zeros_like(W)############################################################################## TODO: Compute the softmax loss and its gradient using no explicit loops. ## Store the loss in loss and the gradient in dW. If you are not careful ## here, it is easy to run into numeric instability. Don't forget the ## regularization! ############################################################################### *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****num_samples = X.shape[0]num_classes = W.shape[1]logits=X@W #NxD,DxC=NxClogits_shifted = logits-np.max(logits,axis=1,keepdims=True)# NxC矩阵 - 按行(类)取出最大值exp_logits =np.exp(logits_shifted)#NxCsum_exp=np.sum(exp_logits,axis=1,keepdims=True)# 按行(类)求和,得到一个列向量,Nx1P=exp_logits/sum_exp# 按列计算得到NxC矩阵correct_class_score=P[range(num_samples),y]#找到每行正确类的概率,得到一个列向量L=-np.log(correct_class_score)#对正确类的概率进行进一步处理,结果依然是一个列向量loss+=np.sum(L)#列向量所有元素的和#Calc grad'''输入:矩阵P=NxC和矩阵X=NxD输出:矩阵dW=DxC对输入矩阵P而言,P=NxC,每行是一张图的c类的概率,共N张图。而每张图的dW中的全部列(一列表示一类)都是由P[j]*Xi或(P[j]-1)*Xi决定的。详细来说,第一张图对dW第一列的贡献为P[j]*X1或(P[j]-1)*X1。第二张图对dW第一列的贡献也是P[j]*X2或(P[j]-1)*X2。第n张图对dW第一列的贡献也是P[j]*Xn或(P[j]-1)*Xn。依此类推,全部图像对dW第一列的贡献为N个P[j]*Xi或(P[j]-1)*Xi的线性组合。另一方面,计算结果dW应该是一个DxC的矩阵,而X的维度是NxD。所以,矩阵乘法的顺序只能是X'xP。其中上面提到的Xi为矩阵X'的第i列,故而前面的线性组合是对矩阵X各列的操作。根据矩阵的乘法,X'xP=dW的每一列,都是基于P的某一列中的所有元素为权重去计算的。具体来说,X'xP的第一列就是以P的第一列中的元素为权重去计算的。其中第一列中的第一个元素就是第一张图的P[j]或P[j]-1,第一列中的第二个元素就是第二张图的P[j]或P[j]-1,总共有多少张图,第一列就有多少个元素。他们分别乘以X1,X2,...Xn.得到了第一列的结果。'''P[np.arange(num_samples), y] -= 1 #提取了每个样本(即每行)正确类别的概率,然后减去1,得到P[j]-1,其他类别保持P[j]不变dW=X.T@P# Avgloss/=num_samplesdW/=num_samples# +Regloss+=reg*np.sum(W*W)dW+=2*reg*W# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****return loss, dW
(全文完)
--- 作者,松下J27
参考文献(鸣谢):
1,Stanford University CS231n: Deep Learning for Computer Vision
2,Assignment 1
3,cs231n/assignment1/svm.ipynb at master · mantasu/cs231n · GitHub
4,CS231/assignment1/svm.ipynb at master · MahanFathi/CS231 · GitHub
(配图与本文无关)
版权声明:所有的笔记,可能来自很多不同的网站和说明,在此没法一一列出,如有侵权,请告知,立即删除。欢迎大家转载,但是,如果有人引用或者COPY我的文章,必须在你的文章中注明你所使用的图片或者文字来自于我的文章,否则,侵权必究。 ----松下J27