文章目录
- 2 封装
- 2.1 基础框架
- 2.2 迭代器(1)
- 2.3 迭代器(2)
- 3. 位图
- 3.1 问题引入
- 3.2 左移和右移?
- 3.3 位图的实现
- 3.4 位图的题目
- 3.5 位图的应用
2 封装
2.1 基础框架
文章
有了前面map和set封装的经验,容易写出下面的代码
// UnorderedSet.h
#pragma once
#include "HashTable.h"
template <class K, class Hash = HashFunc<K>>
class UnorderedSet
{// 返回keystruct SetKeyOfT{const K& operator()(const K& key){return key;}};
public:bool insert(const K& key){return _ht.Insert(key);}
private:HashTable<K, K, SetKeyOfT, Hash> _ht;
};
// UnorderedMap.h
#pragma once
#include "HashTable.h"
template <class K, class V, class Hash = HashFunc<K>>
class UnorderedMap
{// 返回pair的first,即keystruct MapKeyOfT{const K& operator()(const pair<K, V> &kv){return kv.first;}};
public:bool insert(const pair<K, V>& kv){return _ht.Insert(kv);}private:HashTable<K, pair<K, V>, MapKeyOfT, Hash> _ht;
};
// HashTable.h
template <class T>
struct HashNode
{HashNode(const T& data): _data(data), _next(nullptr){}HashNode* _next;T _data;
};
// UnorderedMap->HashTable<K, pair<K, V>>
// UnorderedSet->HashTable<K, K>
template <class K, class T, class KeyOfT , class Hash>
class HashTable
{typedef HashNode<T> Node;
public:// ...bool Insert(const T& data){// 如果已经有该元素了,返回falseif (Find(kot(data))) return false;size_t sz = _table.size();// 负载因子设置到1if (_table.size() == _n){size_t newSz = sz * 2;vector<Node*> newTable;newTable.resize(newSz, nullptr);for (size_t i = 0; i < sz; ++i) {Node* cur = _table[i];while (cur) {Node* next = cur->_next;size_t hashI = hf(kot(cur->_data)) % newSz;// 头插到新链表cur->_next = newTable[hashI];newTable[hashI] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newTable);}size_t hashI = hf(kot(data)) % sz;Node* newNode = new Node(data);// 头插newNode->_next = _table[hashI];_table[hashI] = newNode;++_n;return true;}// ...
private: vector<Node*> _table;size_t _n;Hash hf;KeyOfT kot;
};
其中HashTable.h中部分代码已经省略,详细见文章
2.2 迭代器(1)
写法1
// HashTable.h
template <class T>
struct __HTIterator
{typedef HashNode<T> Node;typedef __HTIterator<T> Self;Node* _node;vector<Node*>& _table; // 方便找下一个桶size_t _hashI; // 当前找到哪个桶了__HTIterator(Node* node, vector<Node*>& table, size_t hashI): _node(node), _table(table), _hashI(hashI){}Self& operator++(){if (_node->_next) {// 当前桶还有节点,走到下一个节点_node = _node->_next;}else {// 当前桶没有节点了,去找下一个桶++_hashI;while (_hashI < _table.size()) {if (_table[_hashI] != nullptr) {// 找到了非空节点_node = _table[_hashI];break;}++_hashI;}// 没有下一个有节点的桶了if (_hashI == _table.size()) {_node = nullptr; // 让nullptr充当end()}}return *this;}bool operator!=(const Self& s){return _node != s._node;}T& operator*(){return _node->_data;}T* operator->(){return &(_node->_data);}
};template <class K, class T, class KeyOfT , class Hash = HashFunc<K>>
class HashTable
{// ...typedef __HTIterator<T> Iterator;Iterator begin(){// 找到第一个有存值的桶,传给迭代器for (size_t i = 0; i < _table.size(); i++) {if (_table[i] != nullptr) {return Iterator(_table[i], _table, i);}}// 找到最后还没有找到,证明是空哈希表return end();}Iterator end(){return Iterator(nullptr, _table, -1);}// ...
}
2.3 迭代器(2)
// 因为后面的__HTIterator使用了HashTable这个类,向上找找不到,所以需要前置声明
template <class K, class T, class KeyOfT, class Hash>
class HashTable;template <class K, class T, class KeyOfT, class Hash>
struct __HTIterator
{typedef HashNode<T> Node;typedef __HTIterator<K, T, KeyOfT, Hash> Self;Node* _node;HashTable<K, T, KeyOfT, Hash>* _ht; // 方便找下一个桶size_t _hashI; // 当前找到哪个桶了__HTIterator(Node* node, HashTable<K, T, KeyOfT, Hash>* ht, size_t hashI): _node(node), _ht(ht), _hashI(hashI){}Self& operator++(){if (_node->_next) {// 当前桶还有节点,走到下一个节点_node = _node->_next;}else {// 当前桶没有节点了,去找下一个桶++_hashI;while (_hashI < _ht->_table.size()) {if (_ht->_table[_hashI] != nullptr) {// 找到了非空节点_node = _ht->_table[_hashI];break;}++_hashI;}// 没有下一个有节点的桶了if (_hashI == _ht->_table.size()) {_node = nullptr; // 让nullptr充当end()}}return *this;}// ...
};template <class K, class T, class KeyOfT, class Hash>
class HashTable
{typedef HashNode<T> Node;template <class K, class T, class KeyOfT, class Hash>friend struct __HTIterator; // 让__HTIterator成为HashTable的友元,因为用到了_table这个私有属性
public:typedef __HTIterator<K, T, KeyOfT, Hash> Iterator;Iterator begin(){// 找到第一个有存值的桶,传给迭代器for (size_t i = 0; i < _table.size(); i++) {if (_table[i] != nullptr) {return Iterator(_table[i], this, i);}}// 找到最后还没有找到,证明是空哈希表return end();}Iterator end(){return Iterator(nullptr, this, -1);}// ...
}
const迭代器不再实现,太复杂了。
3. 位图
概念:所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。
3.1 问题引入
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
遍历,时间复杂度O(N)
排序(O(NlogN)),利用二分查找: logN
数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在。比如:
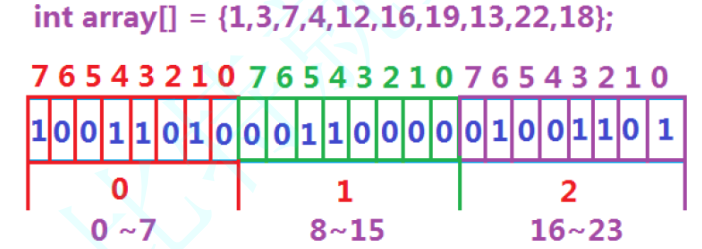
可以计算一下,40亿个数,需要开2^32bit,即512MB
3.2 左移和右移?
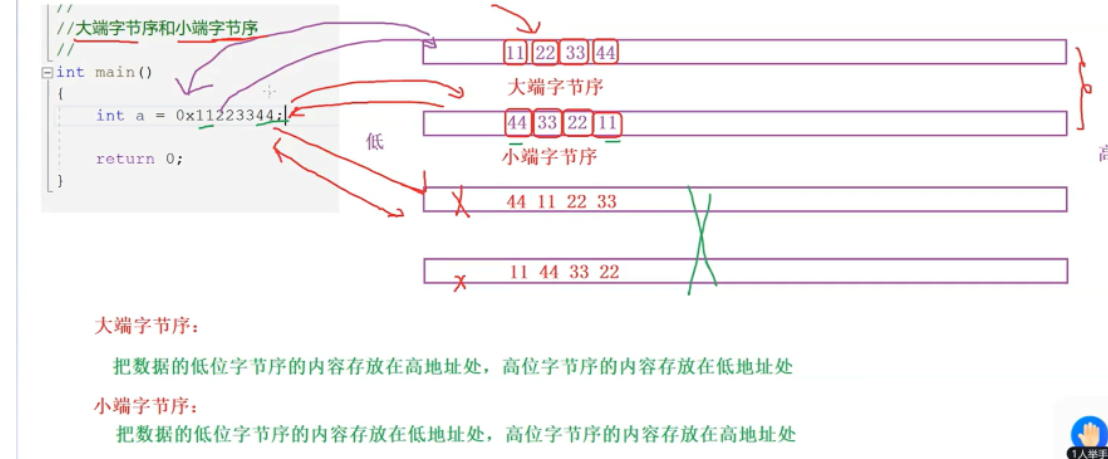
vs是以小端字节序存储的,左移指的是像高地址移动,右移是指向低地址移动,并不是按移动的方向定义的
执行完i = 1

执行完i <<= 8


3.3 位图的实现
// N表示需要多少bit位
template<size_t N>
class MyBitset
{
public:MyBitset(){_bits.resize(N / 32 + 1, 0);}/*把x映射的位置1* x在数组的第几个整形呢? i = x / 32* x在这个整形的第几个位呢? j = x % 32*/ void set(size_t x) {size_t i = x / 32;size_t j = x % 32;// 或等上1<<j_bits[i] |= (1 << j);}// 把x映射的位置0void reset(size_t x){size_t i = x / 32;size_t j = x % 32;// 与等上~(1<<j)_bits[i] &= (~(1 << j));}// 检查x所在的bit是0还是1bool test(size_t x){size_t i = x / 32;size_t j = x % 32;// 与上1return _bits[i] & (1 << j);}
private:vector<size_t> _bits;
};

上面的3.1的问题,我们可以开一个bitset来解决
// solution 1
MyBitset<0xffffffff> bs;
// solution 2
MyBitset<-1> bs2;
3.4 位图的题目
- 给定100亿个整数,设计算法找到只出现一次的整数?
使用两个bitset,00表示出现0次,01表示出现1次,10表示出现2次或者2次以上
template<size_t N> class TwoBitset { public:/** 00->01* 01->10* 10->same*/void set(size_t x){if (!_bs1.test(x) and !_bs2.test(x)) {_bs2.set(x);}else if (!_bs1.test(x) and _bs2.test(x)) {_bs1.set(x);_bs2.reset(x);}}/* 打印出现一次的数字 */void PrintOnce(){for (size_t i = 0; i < N; i++) {if (!_bs1.test(i) and _bs2.test(i))cout << i << ' ';}cout << endl;}private: MyBitset<N> _bs1;MyBitset<N> _bs2; };
- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
与上面类似:将这些整数各自映射到一个位图,一个值在两个位图都存在,则是交集
- 位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
也是一样,两个位图,00表示出现0次,01表示出现1次,10表示出现2次,11表示出现3次及以上
3.5 位图的应用
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记