
🌈个人主页:人不走空
💖系列专栏:算法专题
⏰诗词歌赋:斯是陋室,惟吾德馨

目录
🌈个人主页:人不走空
💖系列专栏:算法专题
⏰诗词歌赋:斯是陋室,惟吾德馨
2.1 架构设计
自注意力机制(Self-Attention Mechanism)
前馈神经网络(Feedforward Neural Network)
残差连接(Residual Connection)和层归一化(Layer Normalization)
最终输出
2.2 自注意力机制详解
2.3 多头注意力机制
2.4 位置编码
2.5 训练过程
2.5.1 预训练
2.5.2 微调
作者其他作品:

2.1 架构设计
ChatGPT的核心架构是基于Transformer解码器。Transformer解码器主要由多个堆叠的解码器层(Decoder Layer)组成,每个层包括以下几个关键组件:
自注意力机制(Self-Attention Mechanism)
自注意力机制是解码器的核心组件之一,用于捕捉输入序列中各个单词之间的关系。通过计算查询(Query)、键(Key)和值(Value)向量之间的相似度,自注意力机制能够为每个单词分配不同的权重,反映其在当前上下文中的重要性。这一机制使得模型能够在生成过程中考虑到整个输入序列的各个部分,从而生成连贯且上下文相关的文本。
前馈神经网络(Feedforward Neural Network)
前馈神经网络由两个线性变换和一个非线性激活函数(通常是ReLU)组成。它对每个位置的表示进行非线性变换,以增强模型的表达能力。具体步骤如下:
- 第一层线性变换:将输入向量映射到一个更高维度的隐空间。
- 激活函数:应用ReLU激活函数,增加模型的非线性特性。
- 第二层线性变换:将激活后的向量映射回原始维度。
这种双层结构能够捕捉复杂的特征和模式,进一步提升模型的生成质量。
残差连接(Residual Connection)和层归一化(Layer Normalization)
为了缓解深层神经网络中常见的梯度消失和梯度爆炸问题,Transformer解码器引入了残差连接和层归一化技术。
- 残差连接:在每个子层的输入和输出之间添加一个直接连接,使得输入能够跳跃式地传递到后面的层。这种连接方式不仅有助于梯度的反向传播,还能加快模型的收敛速度。
- 层归一化:对每一层的输入进行归一化处理,使得输入在不同训练阶段保持稳定,有助于加速训练过程和提高模型的稳定性。
每个解码器层的输入是前一层的输出,经过自注意力机制、前馈神经网络、残差连接和层归一化的处理后,传递给下一层。通过多层堆叠,模型能够逐层提取和整合更加抽象和高层次的特征。
最终输出
在所有解码器层处理完毕后,模型的输出被传递到一个线性层,该层将高维表示映射到词汇表的维度。接着,通过Softmax函数计算每个单词的概率分布。这一步骤将解码器的输出转换为一个概率分布,用于预测下一个单词。整个生成过程是自回归的,即每次生成一个单词,然后将其作为输入,用于生成下一个单词。
2.2 自注意力机制详解
自注意力机制是Transformer中最关键的部分,它通过计算查询、键和值的点积来捕捉输入序列中的依赖关系。具体步骤如下:
-
查询、键和值的生成:输入序列通过线性变换生成查询(Q)、键(K)和值(V)矩阵。
Q=XWQ,K=XWK,V=XWV
-
计算注意力权重:通过点积计算查询和键的相似度,然后除以一个缩放因子(通常是键的维度的平方根),最后通过Softmax函数将相似度转换为概率分布。
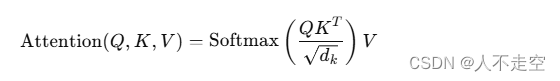
-
加权求和:用注意力权重对值进行加权求和,得到每个位置的注意力表示。
2.3 多头注意力机制
为了捕捉输入序列中的多种关系,Transformer引入了多头注意力机制(Multi-Head Attention)。具体来说,将查询、键和值矩阵分成多个头,每个头独立地计算注意力,然后将各头的输出拼接起来,再通过线性变换得到最终的输出。
多头注意力机制的公式如下:
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
其中,每个头的计算方法为:
headi=Attention(QWQi,KWKi,VWVi)
2.4 位置编码
Transformer没有循环结构,因此无法自然地捕捉序列中的位置信息。为了解决这个问题,Transformer引入了位置编码(Positional Encoding)。位置编码通过正弦和余弦函数生成,并加到输入序列的词嵌入中,使得模型能够区分序列中不同位置的单词。
位置编码的公式如下:
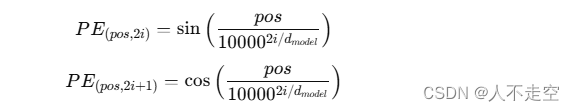
其中,pospospos表示位置,iii表示维度的索引,dmodeld_{model}dmodel表示词嵌入的维度。
2.5 训练过程
ChatGPT的训练过程包括两个主要阶段:预训练和微调。
2.5.1 预训练
在预训练阶段,模型在大规模的无监督文本数据上进行训练。训练目标是最大化给定上下文条件下生成下一个单词的概率。具体来说,模型通过计算预测单词与真实单词之间的交叉熵损失来进行优化。
预训练的公式如下:
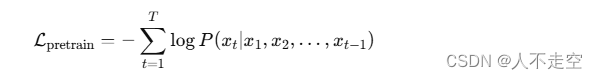
其中,xtx_txt表示序列中的第ttt个单词,TTT表示序列的长度。
2.5.2 微调
在微调阶段,模型通过监督学习和强化学习在特定任务或领域的数据上进行进一步训练。监督学习使用标注数据进行训练,强化学习则通过与环境的交互,优化特定的奖励函数。
微调过程包括以下步骤:
- 监督学习微调:使用人工标注的数据进行监督学习,优化模型在特定任务上的性能。
- 强化学习微调:使用强化学习算法(如策略梯度)进行优化,通过与环境的交互,最大化奖励函数。
强化学习微调的公式如下:
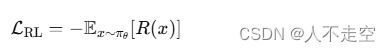
其中,πθ表示模型的策略,R(x)表示奖励函数。
作者其他作品:
【Java】Spring循环依赖:原因与解决方法
OpenAI Sora来了,视频生成领域的GPT-4时代来了
[Java·算法·简单] LeetCode 14. 最长公共前缀 详细解读
【Java】深入理解Java中的static关键字
[Java·算法·简单] LeetCode 28. 找出字a符串中第一个匹配项的下标 详细解读
了解 Java 中的 AtomicInteger 类
算法题 — 整数转二进制,查找其中1的数量
深入理解MySQL事务特性:保证数据完整性与一致性
Java企业应用软件系统架构演变史