Abstract
随着对 CLIP 等大型视觉 - 语言模型的关注不断增加,人们在构建高效的提示(prompt)方面投入了大量精力。与传统方法仅学习单一提示不同,我们提出学习多个全面的提示,以描述类别的多样化特征,例如内在属性或外在上下文。然而,直接将每个提示与相同的视觉特征进行匹配是存在问题的,因为它会推动提示收敛到同一点。为了解决这一问题,我们提出应用最优传输(optimal transport)来匹配视觉和文本模态。具体而言,我们首先用视觉和文本特征集对图像和类别进行建模,然后应用两阶段优化策略来学习提示。在内循环中,我们通过 Sinkhorn 算法优化最优传输距离,以对齐视觉特征和提示;在外循环中,我们根据监督数据通过该距离学习提示。我们针对少样本识别任务进行了广泛的实验,结果表明我们的方法具有优越性。
1 INTRODUCTION
在过去的几年中,大规模视觉 - 语言预训练(VLP)模型,例如 CLIP(Radford 等人,2021 年)、ALIGN(Jia 等人,2021 年)和 BLIP(Li 等人,2022 年),在开放世界的视觉概念学习方面取得了显著的成功。这些方法带来了新的曙光,但也提出了一个新的问题:如何高效地将预训练的知识适应于下游任务,因为这些模型通常具有巨大的规模,普通用户无法重新训练。
利用预训练知识的传统范式之一是“预训练、微调”,它固定预训练神经网络的架构,并使用特定于任务的目标函数来调整其参数。除了微调参数之外,许多最近的方法(Zhou 等人,2021b;2022)将自然语言处理(NLP)领域的提示学习概念引入到视觉领域,并在少样本视觉分类中取得了显著的性能提升。这些方法固定模型参数,转而通过将模板句子转换为一组可学习的向量来学习合适的提示。然后,通过最小化视觉特征与基于提示的语言特征之间的距离来学习这些提示。
尽管与手动设计的提示相比有了显著改进,但仅学习一个句子直觉上是不足以表示一个类别的。一个类别可以通过许多内在特征甚至外在上下文关系来描述。因此,对于一个对象,我们可能会有多个关注不同属性的提示候选。如图1所示,我们可以从不同角度描述“ Brambling”(一种鸟)这一类别:比如翅膀的颜色、头顶和眼睛的颜色、尾巴的形状和颜色,甚至是生活环境信息。这促使我们学习多个提示,以全面地表示类别,从而促进分类。
最自然的解决方案是通过分别将每个提示与视觉特征进行匹配来直接学习多个提示。然而,这与将提示特征的均值与视觉特征进行匹配是相同的。这种解决方案存在问题,因为它鼓励所有提示都接近于同一点,从而倾向于学习相同的特征。这与我们学习全面提示的目的相矛盾。为了解决这一问题,我们尝试添加一些约束来使提示相互远离,但发现这种解决方案仍然无法学习到具有代表性和全面性的提示。这种解决方案将视觉表示视为一个单一的点,而这种对视觉特征的统一视图忽略了不同提示可能只关注一个或一组特征的事实。
为了解决这一问题,本文提出了基于最优传输的提示学习(Prompt Learning with Optimal Transport,简称 PLOT),它应用最优传输(OT)来对齐局部视觉特征和多个文本提示。最优传输可以在多种形式的多采样下计算两个分布之间的距离。在我们的提示学习框架中,我们将局部视觉特征和多个提示表述为两个离散分布的采样,并使用 OT 来促进细粒度的跨模态匹配。具体来说,为了获得具有不同语义线索的局部视觉特征,我们提取所有特征图作为视觉表示,而不是单一的全局表示。幸运的是,我们可以通过使用多头自注意力层的所有输出,轻松地从 CLIP 的视觉编码器中获得视觉特征图(Rao 等人,2021)。然后问题就变成了如何计算两组特征之间的距离。
我们通过引入最优传输理论(Villani,2009)来解决这一问题,并将特征集表述为离散概率分布,其中每个特征具有相等的概率值。此外,为了降低计算成本并避免额外的模型参数,我们采用两阶段优化策略来学习提示。在内循环的第一阶段,我们固定视觉和文本特征,并通过快速Sinkhorn距离算法(Cuturi,2013)优化最优传输问题。然后,在外循环中,我们固定最优传输的所有参数,并通过反向传播梯度来学习具有不同特征的提示。与传统距离(例如平均特征的欧几里得距离)相比,最优传输可以为每个局部提示对齐不同的视觉特征,这在视觉错位方面更具鲁棒性,并且能够很好地容忍特征偏移(Rubner等人,2000)。这是因为OT学习了一个自适应的传输计划来对齐特征,从而实现了两个模态之间的细粒度匹配。我们在11个数据集上按照CLIP(Radford等人,2021)和CoOp(Zhou等人,2021b)的标准设置进行了实验,以评估我们的方法。这些实验涵盖了通用对象、场景、动作、细粒度类别等的视觉分类。显著的结果改进表明,PLOT能够有效地学习具有代表性和全面性的提示。
2 RELATED WORK
Optimal Transport 最优传输(Monge,1781)最初被引入来解决同时移动多个物品时如何降低运输成本的问题。近年来,最优传输理论因其能够方便地比较以特征集形式呈现的分布,而在机器学习和计算机视觉领域引起了广泛关注(Peyre & Cuturi,2019)。由于其出色的分布匹配特性,最优传输已被应用于许多理论和应用任务,包括生成模型(Arjovsky 等人,2017;Salimans 等人,2018;Zhao 等人,2021a)、结构匹配(Chen 等人,2019;Xu 等人,2020;Zhao 等人,2021b;Xu 等人,2019)(例如序列匹配(Chen 等人,2019)和图匹配(Xu 等人,2019),以及图像匹配(Zhang 等人,2020;Liu 等人,2021a;Zhao 等人,2021b)),以及其他基于分布的任务(如聚类(Laclau 等人,2017)、分布估计(Boissard 等人,2015)和因果发现(Tu 等人,2022))。在本文中,我们通过学习一个自适应的传输计划来对齐视觉和语言模态的特征(Rubner 等人,2000)。
Vision-Language Pre-trained Models 视觉 - 语言预训练(VLP)模型旨在通过大规模预训练探索视觉和语言模态之间的语义对应关系。最近,VLP 模型在少样本视觉识别方面取得了令人兴奋的性能提升(Radford 等人,2021 年;Gao 等人,2021 年;Zhou 等人,2021b;2022 年;Zhang 等人,2021b),这表明在语言的帮助下,这些模型有巨大的潜力来促进开放世界的视觉理解。从目标角度来看,VLP 方法可以分为重建(Li 等人,2019 年;Hong 等人,2021 年;Dou 等人,2021 年;Kim 等人,2021 年)、对比匹配(Radford 等人,2021 年;Jia 等人,2021 年;Jain 等人,2021 年)或两者的结合(Li 等人,2021 年;Wang 等人,2021b;Kamath 等人,2021 年)。此外,VLP 领域的最新进展也受益于大规模成对数据集。例如,CLIP(Radford 等人,2021 年)应用了 4 亿张图像 - 文本对进行对比学习。除了识别之外,这些 VLP 模型在其他下游应用方面也显示出巨大的潜力,例如密集预测(Rao 等人,2021 年;Zhou 等人,2021a)、图像生成(Nichol 等人,2021 年;Ramesh 等人,2022 年;Patashnik 等人,2021 年)和行为理解(Wang 等人,2021a;Tevet 等人,2022 年)。
Prompt Learning 提示学习(Prompt Learning)是从自然语言处理(NLP)领域引入的一种方法,用于高效地将大型语言模型适应于下游任务。与传统的“预训练、微调”范式不同,后者通过初始化预训练模型并使用下游任务特定的目标函数来调整网络的参数,提示学习通过应用文本提示将下游任务重新表述为原始的预训练任务(Liu 等人,2021b;Petroni 等人,2019)。通过提示,减少了预训练任务和下游应用之间的领域差异,从而使预训练的知识更容易适应下游任务。提示学习的概念(Petroni 等人,2019;Radford 等人,2019;Poerner 等人,2019)源于 GPT(Radford 等人,2019)系列的成功。早期的提示学习方法(例如 Petroni 等人(Petroni 等人,2019)和 Pörner 等人(Poerner 等人,2019))总是基于人类先验知识手动创建模板。此外,还提出了一些基于挖掘的方法(Jiang 等人,2020)和基于梯度的方法(Shin 等人,2020)来自动生成适当的模板。除了在离散空间中搜索之外,一些方法(Li & Liang,2021;Tsimpoukelli 等人,2021;Liu 等人,2021c)取消了提示是“单词”的约束,而是在连续的嵌入空间中学习提示。最近,CoOp(Zhou 等人,2021b)及其扩展版本(Zhou 等人,2022)将提示学习引入开放世界的视觉理解中,以适应来自大规模视觉 - 语言预训练模型的知识,并在少样本视觉识别方面取得了显著的性能提升。与 CoOp 相比,我们的 PLOT 方法通过引入最优传输距离来学习多个局部提示,并实现了细粒度的视觉 - 语言匹配,从而进一步改进了提示学习。PDL(Lu 等人,2022)也受到更多样化提示的启发,它假设提示具有参数化分布,并在训练期间拟合参数。与之不同的是,PLOT 不使用参数化分布来学习多个提示。
3 APPROACH
在本节中,我们首先回顾基线方法 CoOp(3.1),介绍最优传输的预备知识(3.2),然后介绍我们的 PLOT(3.3),展示我们如何学习多个全面的提示。
3.1 A REVISIT OF COOP
CoOp(Zhou 等人,2021b)是最早提出学习提示以利用视觉 - 语言预训练知识(例如 CLIP(Radford 等人,2021))进行下游开放世界视觉识别的方法之一。与手动设计提示模板的 CLIP 不同,CoOp 将模板中的一部分上下文词设置为连续可学习的参数,这些参数可以从少样本数据中学习。然后,分类权重可以通过学习到的提示与视觉特征之间的距离来表示。
CLIP中的Prompt:一个常见的提示形式是“a photo of [CLS]”,其中
[CLS]是类别标记,可以替换为具体的类别名称

上面的公式就是在计算图像属于类别k的概率
3.2 OPTIMAL TRANSPORT



最优传输问题的核心是找到一种最有效的方式将一个分布的质点移动到另一个分布的质点,同时最小化总成本。通过引入熵正则项,Sinkhorn 算法可以快速求解最优传输问题,适用于大规模数据集。这种方法在机器学习中广泛应用于比较分布的相似性,以及在不同分布之间转移知识
3.3 PROMPT LEARNING WITH OPTIMAL TRANSPORT
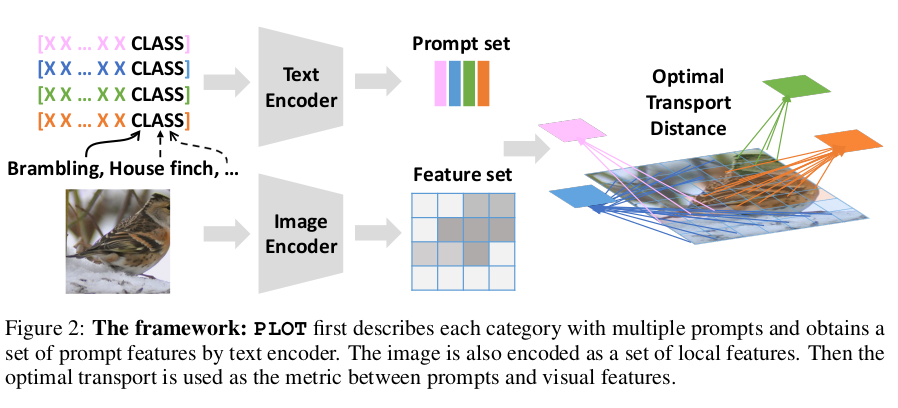
在本小节中,我们介绍了我们的 PLOT 的详细信息,它通过最小化最优传输(OT)距离来学习多个提示,以描述类别的不同特征。



尽管最优传输和提示的优化策略是两阶段的,但整个训练流程是端到端的。这是因为传输计划是通过少量的矩阵乘法作为前向模块计算得出的。这些矩阵乘法的梯度被记录下来,用于反向传播以实现端到端优化,这使得整个系统完全可微分(包括迭代算法),并且可以轻松地使用像 PyTorch 这样的自动梯度库来实现。在实验中,我们发现这种优化策略是自然且相对容易实现的。
再详细解释一下文中提到的两个循环:内循环和外循环
内循环:就是在寻找一个最优传输距离,也就是一个传输计划,个计划描述了如何将文本提示特征(prompt features)与视觉特征(visual features)进行最佳匹配。

外循环:优化提示特征,通过固定的传输计划来优化提示特征

总结:
内循环 专注于学习一个传输计划,该计划描述了如何将文本提示特征与视觉特征进行最佳匹配。
外循环 则利用内循环学习到的传输计划,通过优化提示特征来提高分类性能。
4 EXPERIMENTS
为了评估我们的方法,我们进行了广泛的实验,包括与 CoOp 的比较、消融研究、参数分析、可扩展性分析、计算成本分析和可视化。
4.1 DATASETS
我们遵循 CoOp(Zhou 等人,2021b)中的实验设置来进行少样本学习评估。实验在 11 个视觉识别数据集上进行,包括 Caltech101(Fei-Fei 等人,2004)、DTD(Cimpoi 等人,2014)、EuroSAT(Helber 等人,2019)、FGVCAircraft(Maji 等人,2013)、Flowers102(Nilsback & Zisserman,2008)、Food101(Bossard 等人,2014)、ImageNet(Deng 等人,2009)、OxfordPets(Parkhi 等人,2012)、StanfordCars(Krause 等人,2013)、SUN397(Xiao 等人,2010)和 UCF101(Soomro 等人,2012)。这些数据集涵盖了通用物体、场景、动作、细粒度类别的视觉分类等,构成了对我们方法的全面评估。所有实验都采用了 CLIP(Radford 等人,2021)和 CoOp(Zhou 等人,2021b)中使用的少样本评估协议,我们分别选择 1、2、4、8 和 16 个样本进行模型训练,并使用原始测试集进行评估。此外,我们还评估了我们方法在领域偏移情况下的鲁棒性。按照 CoOp 的做法,我们使用 ImageNet 作为源域,并使用基于 ImageNet 的鲁棒性评估数据集,包括 ImageNetV2(Recht 等人,2019)、ImageNet-Sketch(Wang 等人,2019)、ImageNet-A(Hendrycks 等人,2019)和 ImageNet-R(Hendrycks 等人,2020)。每个数据集的详细介绍可以在附录中找到。
4.2 IMPLEMENTATION DETAILS
我们选择 CoOp(Zhou 等人,2021b)作为主要竞争对手来评估我们的方法。与 CoOp 仅学习一个类别的全局提示不同,我们的 PLOT 方法学习多个局部提示,并应用最优传输(OT)距离进行细粒度对齐。此外,我们还报告了使用 CLIP(Radford 等人,2021)特征训练线性分类器的性能,以及 CoOp 的条件版本,称为 CoCoOp(Zhou 等人,2022)。它们也是广泛使用的方法,用于将预训练知识适应于下游任务。请注意,我们在相同的设置下评估 CoCoOp,以进行公平比较(基本到新的设置可以在附录中找到)。原始的 CoOp 方法有不同的版本,具有不同的类别标记位置和参数初始化策略。为了便于比较,我们直接选择了其中一个版本作为我们的基线,具有“end”标记位置,“random”初始化,16个上下文标记和 RN50 主干。更多的实现细节可以在第 A2 节中找到。
4.3 COMPARISON WITH COOP
在少样本学习方面,我们在图3中总结了实验结果,其中红线代表我们的 PLOT 方法,蓝线代表 CoOp,紫线代表 CoCoOp(Zhou 等人,2022),绿线是 CLIP 线性探测。由于CoCoOp 和 CoOp 的设置不同,我们在 CoOp 的设置中重新运行了 CoCoOp 方法。我们观察到所有提示学习方法都大幅度优于线性探测方法。此外,PLOT 在大多数数据集上可以进一步优于CoOp 和 CoCoOp。以平均准确率(左上角)为例,PLOT 在 1、2、4、8、16 个样本上分别比CoOp 提高了 3.03%、3.45%、2.13%、1.38%、0.61%。在所有数据集中,PLOT 在FOOD101 和DTD数据集上比 CoOp 取得了更大的改进,并在 StanfordCars 数据集上取得了相当性能。这可能是因为 StanfordCars 中的区分性特征相互重合,以至于一个全局提示和一个全局视觉特征就可以很好地工作。请注意,我们没有使用类别特定的上下文,因此在细粒度分类数据集上的性能较低,例如,没有类别特定上下文的 CoOp 和 PLOT 在 FGVCAircraft 上的性能都低于线性探测。所有这些性能比较都可以作为实验证据,证明多个局部提示和 OT 距离有助于视觉-语言模型的提示学习。详细的准确率可以在附录中找到。
类别特定的上下文:
假设你正在处理一个鸟类分类任务,其中包含多个鸟类类别,如“麻雀”、“鹰”和“鹦鹉”。类别特定的上下文可能包括:
对于“麻雀”:"小型棕色鸟类,常见于城市公园"。
对于“鹰”:"大型猛禽,具有锐利的视力和强壮的爪子"。
对于“鹦鹉”:"色彩鲜艳的热带鸟类,能模仿人类语言"。
在模型训练时,这些描述可以作为提示或额外的输入信息,帮助模型学习每个类别的独特特征。
领域泛化:模型在实际应用中的鲁棒性也起着至关重要的作用,因为真实世界的环境可能与训练数据存在较大的领域差异。因此,我们进行了鲁棒性评估,以研究由 PLOT 学习到的模型的可迁移性。表1总结了我们的 PLOT 方法和 CoOp 在四个基于 ImageNet 的鲁棒性评估数据集上的结果。对于这两种方法,我们分别在每个类别有16个样本的 ImageNet 上训练模型。对于 PLOT,我们将提示的数量设置为 N=4。我们可以观察到 PLOT 在源域和目标域上都一致性地优于 CoOp。这些实验结果表明,学习多个提示的性能提升并不依赖于单一领域的过拟合。

4.4 ABLATION STUDIES AND MORE ANALYSIS
在本小节中,我们进行了消融研究(ablation studies),以调查不同组件的有效性,目的是为了回答以下问题。
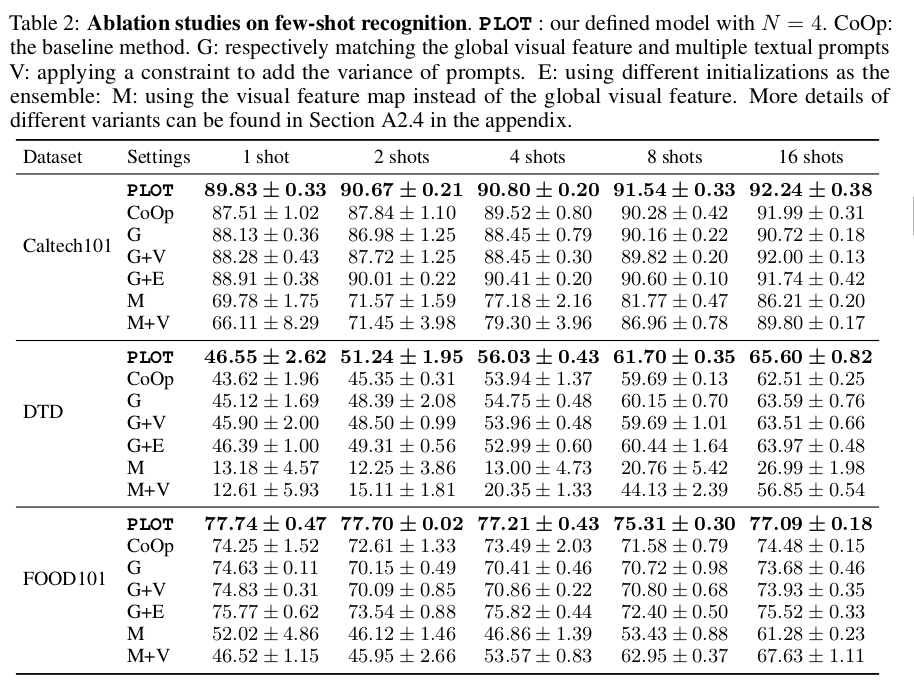
问:我们能否通过将提示集合与全局视觉特征匹配来直接学习多个提示?答:不可以。如表2所示,我们报告了直接将提示集合与全局视觉特征匹配(标记为“G”)在包括Caltech101、DTD和FOOD101在内的三个数据集上的性能。这种方法相对于CoOp的性能提升有限,并且远远低于PLOT。这可能是因为这种“G”方法倾向于学习难以区分的提示,这与我们学习多个全面提示的目的相矛盾。
问:能否通过集成方法来鼓励提示的多样性,并且取得良好效果?答:并不尽然。 如表2所示,我们进一步应用了两种方法来增加提示的多样性,然后使用集成方法来匹配全局特征。在“V”方法中,我们添加了一个目标函数,将每两个提示之间的距离作为正则化项添加进去。在“E”方法中,我们使用预定义的不同初始化来替换随机初始化,例如“a photo of a”(一张照片的)、“this is a photo”(这是一张照片)、“this is a”(这是一个)和“one picture of a”(一张……的照片)。然而,“G+V”并没有在“G”方法上取得一致的改进。尽管“G+E”带来了明显的性能提升,但我们的PLOT方法在“G+E”方法上显示出了一致的优越性,这进一步证明了最优传输距离的有效性。
问:性能提升是否主要来自于使用了所有的特征图?答:不是的。在PLOT中,我们应用了视觉编码器分支的所有特征图,其中每个特征都是一个空间位置上的局部嵌入。然而,我们证明了PLOT的性能提升并不仅仅依赖于使用所有特征图。相反,直接使用特征图来替代全局特征会导致性能大幅下降。例如,在所有三个数据集上,直接使用特征图(“M”或“M+V”)相比于使用全局视觉特征,少样本准确率下降了大约20%。这并不奇怪,因为原始的CLIP模型是通过匹配全局视觉特征和语言特征来训练的。如果不使用最优传输方法,特征图与多个文本提示之间的距离会退化为每个特征-提示对的平均距离。
问:需要多少个提示?答:4个提示就足够了。PLOT 中的一个重要超参数是提示的数量。为了分析提示数量的影响,我们在三个数据集上进行了1、2、4、8个提示的实验。结果总结在表3的白色部分。我们可以观察到,当提示数量从1增加到4时,性能明显提高。例如,在三个数据集上,PLOT(N=4)相比于PLOT(N=1)分别获得了1.36%、2.64%和1.68%的1次尝试(1-shot)准确率提升。此外,当我们进一步增加提示数量时,性能提升并不一致。为了平衡性能提升和计算成本,我们将 N = 4 设置为我们 PLOT 模型的默认配置。在实验中,我们在 Caltech101 数据集上调整了这个超参数,并将其应用于其他数据集。
问:PLOT能否使基于适配器(Adapter-based)的方法受益?答:是的。基于适配器的方法(Gao et al., 2021; Zhang et al., 2021a)是另一种高效适应预训练视觉-语言模型的研究方向。与提示学习不同,后者固定模型参数并调整语言提示,基于适配器的方法允许对网络的一部分进行微调或添加额外模型进行训练。最近,基于适配器的方法也在少样本视觉识别上取得了良好的性能。因此,我们希望探索我们的PLOT方法是否能使它们受益,以及如何受益。
我们采用Tip-Adapter-F(Zhang等人,2021a)作为我们的基线方法,它学习一个线性模型 \( Linear(d, N_cls * K_shots) 来通过与所有训练样本的相似性描述一张图像,其中d是视觉特征的维度,N_cls 是类别的数量(例如 ImageNet 中的 1000),K_shots是样本的数量。然后,最终的相似性由视觉特征和提示集成之间的原始距离以及通过学习到的特征和标签的独热向量(其维度是 \( (N_cls * K_shots,N_cls)计算出的新距离组成。详情请参见Tip-Adapter-F(Zhang等人,2021a)。为了将PLOT引入这个框架,我们首先使用特征图替换全局特征,然后学习多个线性模型。因此,通过不同的局部特征和不同的线性模型,我们可以获得一个M*N的距离矩阵,并应用Sinkhorn算法(Cuturi,2013)来计算最优传输距离。此外,我们可以将学习到的提示作为集成提示的合作伙伴来优化最终的相似性。表4总结了原始Tip-Adapter-F方法和我们的基于适配器的PLOT方法在所有11个数据集上的少样本识别结果。
问:PLOT能否使零样本学习受益?答:不能。详细的分析和讨论可以在附录中找到。
问:与CoOp基线相比,PLOT的额外计算时间成本是多少?答:推理速度大约增加10%,训练时间大约增加5%。请参见附录中的详细分析。
4.5 VISUALIZATION
在本小节中,我们在图4中提供了一些与不同提示(N=4)相关的传输计划T的可视化示例。对这些可视化示例的详细分析以及更多的可视化结果,包括对学习到的提示的解释、提示的T-SNE可视化,以及错误案例的可视化,可以在附录的A3节中找到。

5 CONCLUSION
在本文中,我们提出了一种名为 PLOT 的方法,用于学习多个全面的提示来描述一个类别的多样化特征。为了避免收敛到一个点,我们提出应用最优传输来实现视觉和语言领域之间的细粒度对齐。我们采用了两阶段优化策略,其中内循环固定提示并学习传输计划来计算跨模态距离,外循环使用这个距离来优化提示学习器。我们在 CoOp 的基础上构建了我们的方法,并在各种数据集上的少样本识别任务中取得了显著的改进,这证明了学习多个提示而不是单一提示的优势。