Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。
一、数据集介绍

本例使用了一个垃圾邮件的数据集 Spambase - UCI Machine Learning Repository 实例数量: 4601(垃圾邮件1813封,占39.4%) 属性数量: 58(57个连续属性,1个名义类别标签) 属性信息: 最后一列'spam'(垃圾邮件数据)表示邮件是否被视为垃圾邮件(1)或非垃圾邮件(0),即 不受欢迎的商业电子邮件。多数属性指示特定单词或字符在邮件中是否经常出现。
数据集地址
Spambase - UCI 机器学习存储库
“垃圾邮件”的概念是多种多样的:产品/网站广告、快速赚钱计划、连锁信、色情内容...... 此数据集的分类任务是确定给定电子邮件是否为垃圾邮件。
我们收集的垃圾邮件来自我们的邮政管理员和提交垃圾邮件的个人。我们收集的非垃圾邮件来自归档的工作和个人电子邮件,因此单词“george”和区号“650”是非垃圾邮件的标志。在构建个性化垃圾邮件过滤器时,这些过滤器非常有用。要么必须盲目此类非垃圾邮件指示器,要么获取非常广泛的非垃圾邮件集合以生成通用垃圾邮件过滤器。
有关垃圾邮件的背景信息:Cranor, Lorrie F., LaMacchia, Brian A. Spam!, Communications of the ACM, 41(8):74-83, 1998.
| 变量名称 | 角色 | 类型 | 描述 | 单位 | 缺失值 |
|---|---|---|---|---|---|
| word_freq_make | 特征 | 连续的 | 不 | ||
| word_freq_address | 特征 | 连续的 | 不 | ||
| word_freq_all | 特征 | 连续的 | 不 | ||
| word_freq_3d | 特征 | 连续的 | 不 | ||
| word_freq_our | 特征 | 连续的 | 不 | ||
| word_freq_over | 特征 | 连续的 | 不 | ||
| word_freq_remove | 特征 | 连续的 | 不 | ||
| word_freq_internet | 特征 | 连续的 | 不 | ||
| word_freq_order | 特征 | 连续的 | 不 | ||
| word_freq_mail | 特征 | 连续的 | 不 | ||
| word_freq_receive | 特征 | 连续的 | 不 | ||
| word_freq_will | 特征 | 连续的 | 不 | ||
| word_freq_people | 特征 | 连续的 | 不 | ||
| word_freq_report | 特征 | 连续的 | 不 | ||
| word_freq_addresses | 特征 | 连续的 | 不 | ||
| word_freq_free | 特征 | 连续的 | 不 | ||
| word_freq_business | 特征 | 连续的 | 不 | ||
| word_freq_email | 特征 | 连续的 | 不 | ||
| word_freq_you | 特征 | 连续的 | 不 | ||
| word_freq_credit | 特征 | 连续的 | 不 | ||
| word_freq_your | 特征 | 连续的 | 不 | ||
| word_freq_font | 特征 | 连续的 | 不 | ||
| word_freq_000 | 特征 | 连续的 | 不 | ||
| word_freq_money | 特征 | 连续的 | 不 | ||
| word_freq_hp | 特征 | 连续的 | 不 | ||
| word_freq_hpl | 特征 | 连续的 | 不 | ||
| word_freq_george | 特征 | 连续的 | 不 | ||
| word_freq_650 | 特征 | 连续的 | 不 | ||
| word_freq_lab | 特征 | 连续的 | 不 | ||
| word_freq_labs | 特征 | 连续的 | 不 | ||
| word_freq_telnet | 特征 | 连续的 | 不 | ||
| word_freq_857 | 特征 | 连续的 | 不 | ||
| word_freq_data | 特征 | 连续的 | 不 | ||
| word_freq_415 | 特征 | 连续的 | 不 | ||
| word_freq_85 | 特征 | 连续的 | 不 | ||
| word_freq_technology | 特征 | 连续的 | 不 | ||
| word_freq_1999 | 特征 | 连续的 | 不 | ||
| word_freq_parts | 特征 | 连续的 | 不 | ||
| word_freq_pm | 特征 | 连续的 | 不 | ||
| word_freq_direct | 特征 | 连续的 | 不 | ||
| word_freq_cs | 特征 | 连续的 | 不 | ||
| word_freq_meeting | 特征 | 连续的 | 不 | ||
| word_freq_original | 特征 | 连续的 | 不 | ||
| word_freq_project | 特征 | 连续的 | 不 | ||
| word_freq_re | 特征 | 连续的 | 不 | ||
| word_freq_edu | 特征 | 连续的 | 不 | ||
| word_freq_table | 特征 | 连续的 | 不 | ||
| word_freq_conference | 特征 | 连续的 | 不 | ||
| char_freq_; | 特征 | 连续的 | 不 | ||
| char_freq_( | 特征 | 连续的 | 不 | ||
| char_freq_ | 特征 | 连续的 | 不 | ||
| char_freq_! | 特征 | 连续的 | 不 | ||
| char_freq_ 美元 | 特征 | 连续的 | 不 | ||
| char_freq_# | 特征 | 连续的 | 不 | ||
| capital_run_length_average | 特征 | 连续的 | 不 | ||
| capital_run_length_longest | 特征 | 连续的 | 不 | ||
| capital_run_length_total | 特征 | 连续的 | 不 | ||
| 类 | 目标 | 二元的 | 垃圾邮件 (1) 或非垃圾邮件 (0) | 不 |
其他变量信息
“spambase.data”的最后一列表示该电子邮件是否被视为垃圾邮件 (1) 或非 (0),即未经请求的商业电子邮件。大多数属性指示电子邮件中是否经常出现某个特定单词或字符。run-length 属性 (55-57) 测量连续大写字母序列的长度。有关每个属性的统计度量,请参阅此文件的末尾。以下是属性的定义:
48 个 word_freq_WORD 类型的连续实数 [0,100] 属性 = 电子邮件中与 WORD 匹配的单词百分比,即 100 * (WORD 在电子邮件中出现的次数)/ 电子邮件中的单词总数。在这种情况下,“word” 是由非字母数字字符或字符串结尾限定的任何字母数字字符字符串。
6 个 char_freq_CHAR] 类型的连续实数 [0,100] 属性 = 电子邮件中与 CHAR 匹配的字符百分比,即 100 *(CHAR 出现次数)/ 电子邮件中的字符总数
1 个 capital_run_length_average 类型的连续实数 [1,...] 属性 = 大写字母不间断序列的平均长度
1 个 capital_run_length_longest 类型的连续整数 [1,...] 属性 = 最长的不间断大写字母序列的长度 1 个 capital_run_length_total 类型的连续整数 [1,...] 属性 = 大写字母的不间断序列的长度之和 = 电子邮件中大写字母的总数
1 个 spam 类型的名义 {0,1} 类属性 = 表示该电子邮件是否被视为垃圾邮件 (1) 或非 (0),即未经请求的商业电子邮件。
二、设计思路
2.1、读取数据
import pandas as pd
df=pd.read_table('spambase.data',header=None,sep=',')
df2.2、划分特征
X=df.iloc[:,:-1]
y=df.iloc[:,-1]2.3、划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.75,random_state=42)2.4、标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X_train_scaler=scaler.fit_transform(X_train)
X_test_scaler=scaler.transform(X_test)2.5、转换为Tensor张量
import torch
X_train_tensor=torch.tensor(X_train_scaler,dtype=torch.float32)
y_train_tensor=torch.tensor(y_train.values,dtype=torch.float32)
X_test_tensor=torch.tensor(X_test_scaler,dtype=torch.float32)
y_test_tensor=torch.tensor(y_test.values,dtype=torch.float32)2.6、创建数据加载器
from torch.utils.data import DataLoader,TensorDataset
dataset=TensorDataset(X_train_tensor,y_train_tensor)
dataloader=DataLoader(dataset,shuffle=True,batch_size=64)2.7、定义逻辑回归模型
import torch.nn as nn
class LogisticRegression(nn.Module):def __init__(self,inputsize):super().__init__()self.liner=nn.Linear(inputsize,1)def forward(self,x):return torch.sigmoid(self.liner(x))
model=LogisticRegression(X_train_tensor.shape[1])2.8、定义损失函数和优化器
from torch.optim import Adam
cri=nn.BCELoss()
optimer=Adam(model.parameters(),lr=0.05)2.9、训练模型
for epoch in range(1,501):total_loss=0model.train()for x,y in dataloader:optimer.zero_grad()y_hat=model(x)loss=cri(y_hat,y.view(-1,1))loss.backward()optimer.step()total_loss+=lossavg_loss=total_loss/len(dataloader)if epoch%100==0 or epoch==1:print(epoch,avg_loss.item())2.10、模型评估
from sklearn.metrics import roc_curve,auc
import torch
with torch.no_grad():model.eval()y_pred=model(X_test_tensor)fpr, tpr, thresholds=roc_curve(y_test.values,y_pred.numpy())roc_auc=auc(fpr, tpr)2.11、可视化
from matplotlib import pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {roc_auc:.2f}')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()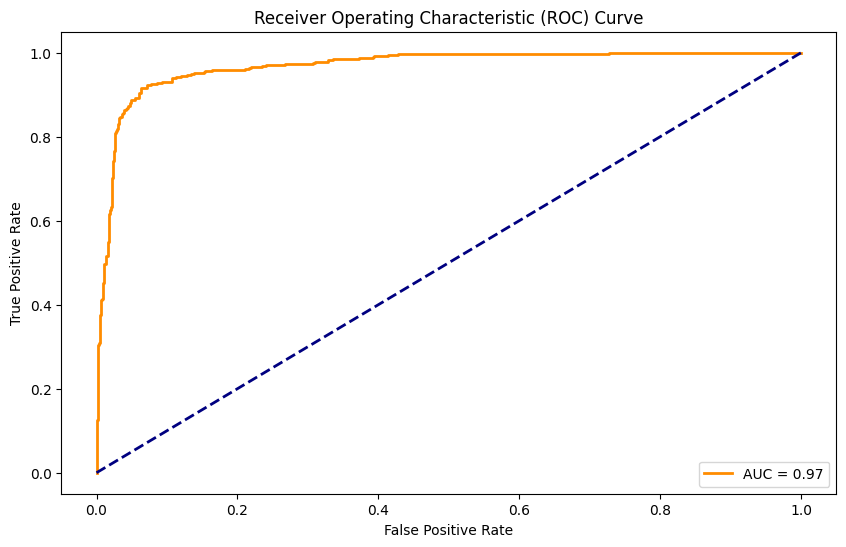 三、完整代码
三、完整代码
import pandas as pd
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader, TensorDataset
import torch.nn as nn
from sklearn.metrics import roc_curve, auc
import torch
from torch.optim import Adam
from sklearn.preprocessing import StandardScaler # 读取数据集,使用制表符作为分隔符
df = pd.read_table('spambase.data', header=None, sep=',') # 分离特征和标签
X = df.iloc[:, :-1] # 特征
y = df.iloc[:, -1] # 标签 # 划分训练集和测试集,训练集占75%
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=42) # 数据标准化
scaler = StandardScaler()
X_train_scaler = scaler.fit_transform(X_train) # 拟合并转换训练数据
X_test_scaler = scaler.transform(X_test) # 仅转换测试数据 # 将数据转换为 PyTorch 张量
X_train_tensor = torch.tensor(X_train_scaler, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test_scaler, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32) # 创建数据集和数据加载器
dataset = TensorDataset(X_train_tensor, y_train_tensor)
dataloader = DataLoader(dataset, shuffle=True, batch_size=64) # 定义逻辑回归模型
class LogisticRegression(nn.Module): def __init__(self, inputsize): super().__init__() self.liner = nn.Linear(inputsize, 1) # 单层线性回归 def forward(self, x): return torch.sigmoid(self.liner(x)) # 使用sigmoid激活函数 # 实例化模型
model = LogisticRegression(X_train_tensor.shape[1]) # 定义损失函数和优化器
cri = nn.BCELoss() # 二元交叉熵损失
optimer = Adam(model.parameters(), lr=0.05) # Adam优化器 # 训练模型
for epoch in range(1, 501): total_loss = 0 # 初始化总损失 model.train() # 切换到训练模式 for x, y in dataloader: optimer.zero_grad() # 清空梯度 y_hat = model(x) # 前向传播 loss = cri(y_hat, y.view(-1, 1)) # 计算损失 loss.backward() # 反向传播 optimer.step() # 更新参数 total_loss += loss # 累加损失 avg_loss = total_loss / len(dataloader) # 计算平均损失 if epoch % 100 == 0 or epoch == 1: print(epoch, avg_loss.item()) # 每100个epoch打印损失 # 评估模型
with torch.no_grad(): model.eval() # 切换到评估模式 y_pred = model(X_test_tensor) # 预测测试数据 fpr, tpr, thresholds = roc_curve(y_test.values, y_pred.numpy()) # 计算ROC曲线 roc_auc = auc(fpr, tpr) # 计算AUC值 # 绘制ROC曲线
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {roc_auc:.2f}') # 绘制ROC曲线
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') # 绘制随机猜测的对角线
plt.xlabel('假阳率 (False Positive Rate)')
plt.ylabel('真阳率 (True Positive Rate)')
plt.title('接收者操作特征 (ROC) 曲线')
plt.legend(loc='lower right')
plt.show() 设计思路
-
数据预处理:
首先读取数据集,并将其分为特征和标签两部分。接着划分训练集和测试集,这里使用了75%的数据用于训练,25%用于测试。使用
StandardScaler对特征进行标准化,使其均值为0,方差为1,有助于提高模型训练的稳定性和收敛速度。 -
数据加载:
将训练数据转换为PyTorch的张量格式,并使用
DataLoader创建可迭代的数据集,以便在训练期间批量加载数据。 -
模型构建:
定义了一个简单的逻辑回归模型,该模型只包含一个线性层,有一层sigmoid激活函数用于二分类任务。
-
训练模型:
使用二元交叉熵损失(
BCELoss)和Adam优化器进行模型训练。训练过程中,使用循环遍历每个epoch,并计算损失,从而逐步优化模型参数。 -
模型评估:
训练完成后,在测试集上进行评价,计算ROC曲线和AUC值,以便直观显示模型的分类性能。
-
可视化结果:
使用Matplotlib绘制ROC曲线,帮助分析模型的表现和分类效果。