文章目录
- 前言
- 一、多头注意力机制介绍
- 1.1 工作原理
- 1.2 优势
- 1.3 代码实现概述
- 二、代码解析
- 2.1 导入依赖
- 序列掩码函数
- 2.2 掩码 Softmax 函数
- 2.3 缩放点积注意力
- 2.4 张量转换函数
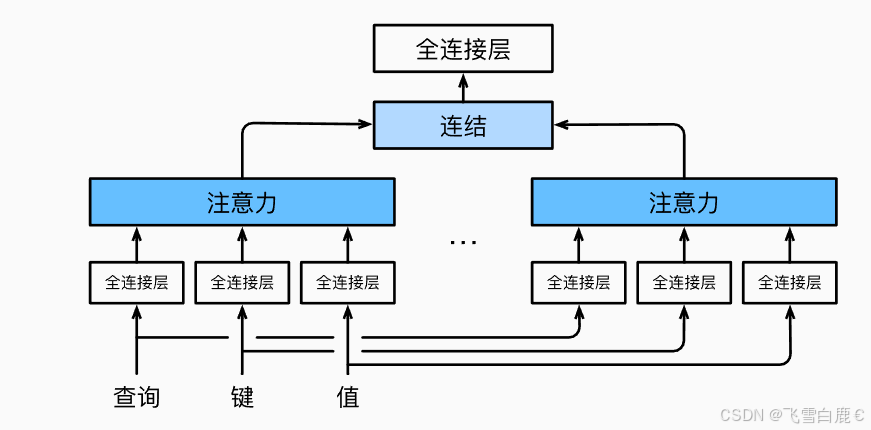
- 2.5 多头注意力模块
- 2.6 测试代码
- 总结
前言
在深度学习领域,注意力机制(Attention Mechanism)是自然语言处理(NLP)和计算机视觉(CV)等任务中的核心组件之一。特别是多头注意力(Multi-Head Attention),作为 Transformer 模型的基础,极大地提升了模型对复杂依赖关系的捕捉能力。本文通过分析一个完整的 PyTorch 实现,带你深入理解多头注意力的原理和代码实现。我们将从代码入手,逐步解析每个函数和类的功能,结合文字说明,让你不仅能运行代码,还能理解其背后的设计逻辑。无论你是初学者还是有一定经验的开发者,这篇博客都将帮助你更直观地掌握多头注意力机制。
完整代码:下载链接
一、多头注意力机制介绍
多头注意力(Multi-Head Attention)是 Transformer 模型的核心组件之一,广泛应用于自然语言处理(NLP)、计算机视觉(CV)等领域。它通过并行运行多个注意力头(Attention Heads),允许模型同时关注输入序列中的不同部分,从而捕捉更丰富的语义和上下文依赖关系。相比单一的注意力机制,多头注意力极大地增强了模型的表达能力,能够处理复杂的模式和长距离依赖。
1.1 工作原理
多头注意力的核心思想是将输入的查询(Queries)、键(Keys)和值(Values)通过线性变换映射到多个子空间,每个子空间由一个独立的注意力头处理。具体步骤如下:
- 线性变换:对输入的查询、键和值分别应用线性层,将其映射到隐藏维度(
num_hiddens),并分割为多个头的表示。 - 缩放点积注意力:每个注意力头独立计算缩放点积注意力(Scaled Dot-Product Attention),即通过查询和键的点积计算注意力分数,再与值加权求和。
- 并行计算:多个注意力头并行运行,每个头关注输入的不同方面,生成各自的输出。
- 合并与变换:将所有头的输出拼接起来,并通过一个线性层融合,得到最终的多头注意力输出。
这种设计允许模型在不同子空间中学习不同的特征,例如在 NLP 任务中,一个头可能关注句法结构,另一个头可能关注语义关系。
1.2 优势
- 多样性:多头机制使模型能够从多个角度理解输入,捕捉多样化的模式。
- 并行性:多头计算可以高效并行化,提升计算效率。
- 稳定性:通过缩放点积(除以特征维度的平方根),缓解了高维点积导致的数值不稳定问题。
1.3 代码实现概述
在本文的实现中,我们使用 PyTorch 构建了一个完整的多头注意力模块,包含以下关键部分:
- 序列掩码:处理变长序列,屏蔽无效位置。
- 缩放点积注意力:实现单个注意力头的计算逻辑。
- 张量转换:通过
transpose_qkv和transpose_output函数实现多头分割与合并。 - 多头注意力类:整合所有组件,完成并行计算和输出融合。
接下来的代码解析将详细展示这些部分的实现,帮助你从代码层面深入理解多头注意力的每一步计算逻辑。
二、代码解析
以下是代码的完整实现和详细解析,代码按照 Jupyter Notebook(在最开始给出了完整代码下载链接) 的结构组织,并附上文字说明,帮助你理解每个部分的逻辑。
2.1 导入依赖
首先,我们导入必要的 Python 包,包括数学运算库 math 和 PyTorch 的核心模块 torch 和 nn。
# 导入包
import math
import torch
from torch import nn
- math:用于计算缩放点积注意力中的归一化因子(即特征维度的平方根)。
- torch:PyTorch 的核心库,提供张量运算和自动求导功能。
- nn:PyTorch 的神经网络模块,包含
nn.Module和nn.Linear等工具,用于构建神经网络层。
序列掩码函数
在处理序列数据(如句子)时,不同序列的长度可能不同,我们需要通过掩码(Mask)来屏蔽无效位置,防止模型关注这些填充区域。以下是 sequence_mask 函数的实现:
def sequence_mask(X, valid_len, value=0):"""在序列中屏蔽不相关的项,使超出有效长度的位置被设置为指定值参数:X: 输入张量,形状 (batch_size, 最大序列长度, 特征维度) 或 (batch_size, 最大序列长度)valid_len: 有效长度张量,形状 (batch_size,),表示每个序列的有效长度value: 屏蔽值,标量,默认值为 0,用于填充无效位置返回:输出张量,形状与输入 X 相同,无效位置被设置为 value"""maxlen = X.size(1) # 最大序列长度,标量# 创建掩码,形状 (1, 最大序列长度),与 valid_len 比较生成布尔张量,形状 (batch_size, 最大序列长度)mask = torch.arange(maxlen, dtype=torch.float32, device=X.device)[None, :] < valid_len[:, None]# 将掩码取反后,X 的无效位置被设置为 valueX[~mask] = valuereturn X
解析:
- 输入:
X:输入张量,通常是序列数据,可能包含填充(padding)部分。valid_len:每个样本的有效长度,例如[3, 2]表示第一个样本有 3 个有效 token,第二个样本有 2 个。value:用于填充无效位置的值,默认为 0。
- 逻辑:
maxlen获取序列的最大长度(即张量的第二维)。torch.arange(maxlen)创建一个从 0 到maxlen-1的序列,形状为(1, maxlen)。- 通过广播机制,与
valid_len(形状(batch_size, 1))比较,生成布尔掩码mask,形状为(batch_size, maxlen)。 mask表示哪些位置是有效的(True),哪些是无效的(False)。- 使用
~mask选择无效位置,将其值设置为value。
- 输出:修改后的张量
X,无效位置被设置为value,形状不变。
作用:该函数用于在注意力计算中屏蔽填充区域,确保模型只关注有效 token。
2.2 掩码 Softmax 函数
在注意力机制中,我们需要对注意力分数应用 Softmax 操作,将其转换为概率分布。但由于序列长度不同,需要屏蔽无效位置的贡献。以下是 masked_softmax 函数的实现:
import torch
import torch.nn.functional as Fdef masked_softmax(X, valid_lens):"""通过在最后一个轴上掩蔽元素来执行softmax操作,忽略无效位置参数:X: 输入张量,形状 (batch_size, 查询个数, 键-值对个数),3D张量valid_lens: 有效长度张量,形状 (batch_size,) 或 (batch_size, 查询个数),1D或2D张量,表示每个序列的有效长度,即每个查询可以参考的有效键值对长度返回:输出张量,形状 (batch_size, 查询个数, 键-值对个数),softmax后的注意力权重"""if valid_lens is None:# 如果没有有效长度,直接在最后一个轴上应用softmaxreturn F.softmax(X, dim=-1)shape