深度学习优化技巧
- 导语
- 参数更新
- SGD
- Momentum
- AdaGrad
- Adam
- 方法比较
- 权重初始化
- 关于置0
- 隐藏层激活值分布
- ReLU权重初值
- 权重比较
- Batch Normalization
- 处理过拟合
- 权值衰减
- Dropout
- 超参数验证
- 验证数据
- 最优化和实现
- 总结
- 参考文献
导语
在深度学习中,除了上一章所涉及到的反向传播这样的大方向,还有一些其他更细化的可优化的地方,例如如何选取最优初值,权重应该如何分配等,书上在本章对常用的优化方法和实现进行了介绍。
参数更新
神经网络学习的目的是找到使得损失函数尽量小的参数,这个过程被称为最优化,书上的前几章提到的SGD就属于这一种,但实际上,可以进行优化的方法不止SGD这一种,许多方法比SGD更加高效。
SGD
SGD在书上先前的章节已经详细论述过,这里不再赘述,只给出式子: W ← W − η ∂ L ∂ W W←W-η\frac{∂L}{∂W} W←W−η∂W∂L,W为权重,η为学习率,所得偏导为梯度方向。
SGD的缺点也很明显,由于SGD关注的永远是极小值,所以梯度下降的方向往往不一定是最小值的方向,以书上的说法,如果函数形状非均向,例如延伸状,搜索的路径就会低效,下面的几个方法都以不同的角度尝试解决这个问题。
Momentum
Momentum的式子如下:
v ← α v − η ∂ L ∂ W W ← W + v \begin{aligned} v←αv-η\frac{∂L}{∂W} \\ \\ W←W+v\quad \end{aligned} v←αv−η∂W∂LW←W+v
这个式子参考了物理学中速度、加速度、力之间的关系, W W W为需要更新的权重参数, η \eta η是学习率, v v v为速度,这个速度是有方向的, α α α是一个预参数,当梯度较小的时候,该参数负责减速,可以类比摩擦力的作用, ∂ L ∂ W \frac{∂L}{∂W} ∂W∂L是梯度,有点类似加速度。
可以联想小球在碗中的运动来理解这个式子,当小球往从碗口向碗底走时,梯度起到主要作用,用以加速,当逐渐接近碗底时,α起到主要作用,用于减速。可以看到的是,当速度越大的时候,参数的变化也就越大,并且,速度在整体结果不到达最小值时是不会置0的,这就保证了宏观上收敛方向的正确性,相较于SGD只考虑局部的极小值,Momentum通过速度这一变量加快了最终值向最小值的收敛(因为存在一直向最小方向的加速或者速度)。
下面给出书上对Momentum的实现:
class Momentum:def __init__(self, lr=0.01, momentum=0.9):self.lr = lr#学习率self.momentum = momentum#αself.v = Nonedef update(self, params, grads):#移动if self.v is None:#初始为0self.v = {}for key, val in params.items(): self.v[key] = np.zeros_like(val)for key in params.keys():self.v[key] = self.momentum*self.v[key] - self.lr*grads[key] params[key] += self.v[key]
AdaGrad
AdaGrad利用了学习率衰减的思想(随着学习进行,学习率逐渐减小),它会为参数的每个元素适当地调整学习率,并且会基于过去的结果对当下学习率的变化进行考察,式子如下:
h ← h + ∂ L ∂ W × ∂ L ∂ W W ← W − η 1 h ∂ L ∂ W \begin{aligned} h←h+\frac{∂L}{∂W}×\frac{∂L}{∂W} \\ \\ W←W-\eta \frac{1}{\sqrt{h}} \frac{∂L}{∂W} \end{aligned} h←h+∂W∂L×∂W∂LW←W−ηh1∂W∂L
这里新加了一个变化 h h h,用以记录过去所有梯度值的平方和,更新参数时使用 1 h \frac{1}{\sqrt{h}} h1控制变化的大小,当参数元素变化大,平方和就会变大,那么 η 1 h \eta \frac{1}{\sqrt{h}} ηh1作为新的学习率就会变小。
但是AdaGrad也有自己的问题,当更新次数越来越多时,更新的幅度就会降低,到最后甚至很难更新,而RMSProp解决了问题,它使用类似滑动窗口的方法,只选取最近的一部分梯度 ,逐渐抛弃过去的梯度,保证每次都能有较大更新。
书上给出的实现代码如下:
class AdaGrad:def __init__(self, lr=0.01):self.lr = lr#主要是处理学习率self.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] += grads[key] * grads[key]#累平方和params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)#修改权重,加上微小值是为了防止h为0,把0作为除数
Adam
Adam采用了Momentum和AdaGrad的思想,它设置了三个超参数,学习率,一次Momentum系数和二次Momentum系数,但是书上并没有解释它的详细思想,具体可以参考Adam优化器算法详解及代码实现和
Adam优化器(通俗理解),书上只给了实现:
class Adam:def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):self.lr = lrself.beta1 = beta1self.beta2 = beta2self.iter = 0self.m = Noneself.v = Nonedef update(self, params, grads):if self.m is None:self.m, self.v = {}, {}for key, val in params.items():self.m[key] = np.zeros_like(val)self.v[key] = np.zeros_like(val)self.iter += 1lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter) for key in params.keys():self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
方法比较
书上给出了四种更新参数的方法,每个方法有自己的适用情况,SGD简单,但是相比之下收敛较慢,Adam似乎是最好,但其实它容易在最优值附近震荡,书上以MNIST数据集为实验对象,使用一个5层神经网络进行了学习比较,结果如下:

可以直观的看到,在MNIST数据集上,SGD学习的最慢,AdaGrad最快,但这样的比较其实不完全准确,因为实验的结果会随超参数和神经网络结构的不同而变化,一般而言,其他方法都优于SGD。
权重初始化
权重的初始化对神经网络的学习很重要,有时可以关系到神经网络的学习是否成功。
关于置0
权重初始值是不能设置为0的,可以以乘法节点来理解,如果都是0输入,在反向传播时,由于乘法节点传播回去的数据为偏导乘上输入,输入是0,那么偏导无论是多少结果都是0,权重全部被更新成相同的值,这使得神经网络不再拥有许多不同的权重,也就无法学习了。
隐藏层激活值分布
一般来说,权重初始值是随机的,书上给出一个向5层神经网络(激活用sigmod)传入随机初始值的实验,代码如下:
import numpy as np
import matplotlib.pyplot as pltdef sigmoid(x):return 1 / (1 + np.exp(-x))input_data = np.random.randn(1000, 100) # 1000个数据,符合高斯分布
node_num = 100 # 各隐藏层的节点(神经元)数
hidden_layer_size = 5 # 隐藏层有5层
activations = {} # 激活值的结果保存在这里x = input_datafor i in range(hidden_layer_size):if i != 0:x = activations[i-1]w = np.random.randn(node_num, node_num) * 1#标准差为1a = np.dot(x, w)z = sigmoid(a)activations[i] = z# 绘制直方图
for i, a in activations.items():plt.subplot(1, len(activations), i+1)plt.title(str(i+1) + "-layer")if i != 0: plt.yticks([], [])plt.hist(a.flatten(), 30, range=(0,1))
plt.show()
运行结果如图:
 可以发现激活值在每一层的分布像一个U型,位于0和1的值很多,这有什么问题呢?让我们回想一下sigmod函数,它的图像是一个拉伸的S型,在靠近0或1的时候,函数的导数是趋近于0的,而神经网络学习时是要靠偏导反向传播的,偏导很小或者趋于0,会使得梯度在反向传播过程中逐渐减小,造成梯度消失这一现象,层次越高,这种减小的量就越多,梯度消失就更严重。
可以发现激活值在每一层的分布像一个U型,位于0和1的值很多,这有什么问题呢?让我们回想一下sigmod函数,它的图像是一个拉伸的S型,在靠近0或1的时候,函数的导数是趋近于0的,而神经网络学习时是要靠偏导反向传播的,偏导很小或者趋于0,会使得梯度在反向传播过程中逐渐减小,造成梯度消失这一现象,层次越高,这种减小的量就越多,梯度消失就更严重。
如果把标准差变小,取0.02,结果如下:

可以发现数据都在0.5附近,梯度消失的问题似乎解决了,但另一个问题接踵而来,激活值的分布有集中的倾向,随着层数增加,区间越来越小,也就是随机性减小了,如果有多个神经元的输出值一样,那么完全可以删除多余的神经元,只保留少量的。这种情况叫做表现力受限。
可见初始值的设定对神经网络是非常重要的,书上给出了解决上述两种情况的方案:使用Xavier初始值(如果前一层的节点数为 n n n,则初始值使用标准差为 1 n \frac{1}{\sqrt{n}} n1的分布),具体的适用结果如下图:

可以看到,随着层数的增加,既没有出现梯度消失的问题,也没有出现表现力受限的情况,数据分布的广度较好,也很随机。
如果将sigmod替换成tanh函数,会得到更好的结果(激活函数最好关于原点对称):

ReLU权重初值
Xavier初始值是以激活函数为线性函数或者类线性函数推出来的,当激活函数为纯非线性函数时,就需要更换选择的初始值分布,以ReLU来说,它就有专用的He初始值,He在Xavier的基础上将 2 n \frac{2}{\sqrt{n}} n2替换了 1 n \frac{1}{\sqrt{n}} n1。
下面给出采用ReLU函数作为激活函数,分别用标准差为0.01的高斯分布,初始值为Xavier,初始值为He的结果:

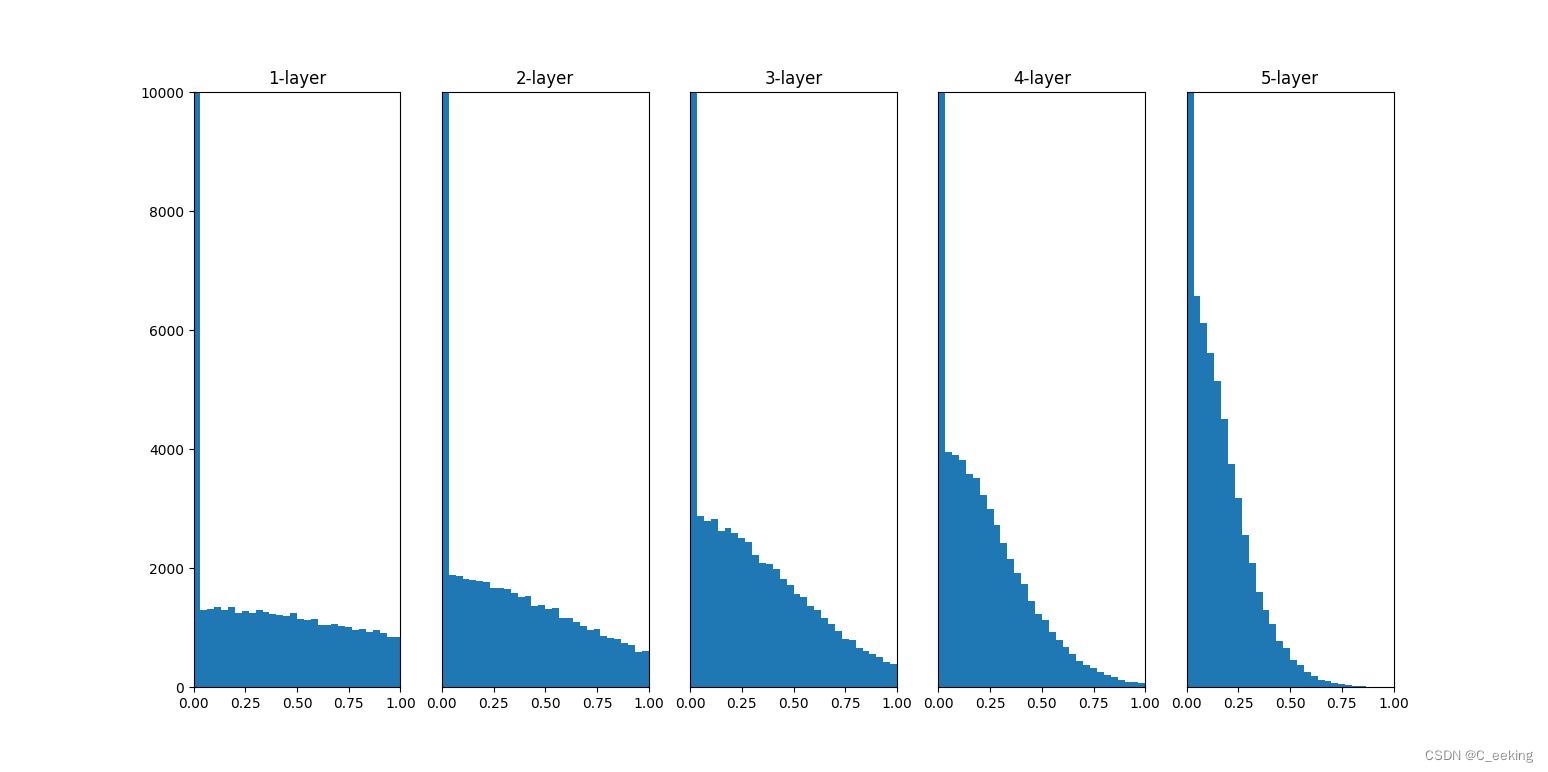

可以看到,第一种有严重的梯度消失,第二种,即Xavier有梯度消失的倾向,当层数变多时也会变成类似第一种的情况,只有第三种即使层数加深后依然保持稳定。
权重比较
以实际的MNIST数据集为例,对上述的三种初始权重进行比较,得到的图如下:

可以用看到,0.01的高斯分布表现很差,完全无法学习,He的表现最好,Xavier其次。
Batch Normalization
为了使各层拥有适当广度,除了在初始的数据分布上尝试,也可以直接强制调整激活值的分布,Batch Normalization就是利用的这个思想。
为了实现Batch Normalization,需要在神经网络中插入Batch Normalization层,具体如下:

书上给出了对Batch Normalization更具体的解释,该方法以学习时的mini-batch为单位,把每一个mini-batch都进行正规化,是的数据分布均值为0,方差为1,数学式子如下:
μ B ← 1 m ∑ i = 1 m x i σ B 2 ← 1 m ∑ i = 1 m ( x i − μ B ) 2 x ^ ← x i − μ B σ B 2 + ε \begin{aligned} μ_B←\frac{1}{m}\sum_{i=1}^mx_i \\ σ_B^2←\frac{1}{m}\sum_{i=1}^m(x_i-μ_B)^2 \\ \hat{x}←\frac{x_i-μ_B}{\sqrt{σ_B^2+ε}} \end{aligned} μB←m1i=1∑mxiσB2←m1i=1∑m(xi−μB)2x^←σB2+εxi−μB
得到的分别是均值,方差,x估计,微小值ε是防止除数为0。
该方法将输入数据均值变成0,方差变成1,将处理插在激活函数前,之后对正规化后的数据进行缩放和平移变换: y i = γ x i ^ + β y_i=γ\hat{x_i}+β yi=γxi^+β,计算图过于复杂,这里直接给出书上的图:

如图是权重初始值的标准差为各种不同值的学习过程图,可以看到使用之后的准确率明显更高:

处理过拟合
过拟合的概念前面已经提到过多次,这里只说明过拟合的两个原因:模型拥有大量参数、表现力强以及训练数据过少。
权值衰减
权值衰减的思路很简单,在学校过程中,对取值过大的权重进行“惩罚”,以L2范数(权重的平方和开开方)为例,权重为 W W W,则权值衰减就是 1 2 λ W 2 \frac{1}{2}λW^2 21λW2,之后这个衰减会加在损失函数上。这里的λ是控制正则化的超参数,越大则惩罚越重,½是用于求导之后变成λW调整常用量。对于所有权重,衰减都会被加在损失函数上,因此求梯度时候,反向传播的结果也要加上λW。
书上以一个7层网络为例(数据量为300),探讨了使用权值衰减和不使用的情况,结果如下图:


第一张为没有使用权值衰减,第二章为使用λ=0.1的权值衰减,可以看到,在使用了权值衰减之后,模型在测试集和数据集上的差距变小了。
书上给出权值衰减相关部分的代码如下:
def loss(self, x, t):#损失函数y = self.predict(x)weight_decay = 0for idx in range(1, self.hidden_layer_num + 2):W = self.params['W' + str(idx)]weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2)#1/2 λ W^2,weight_decay_lambda 就是λreturn self.last_layer.forward(y, t) + weight_decaydef gradient(self, x, t):# forwardself.loss(x, t)# backwarddout = 1dout = self.last_layer.backward(dout)layers = list(self.layers.values())layers.reverse()for layer in layers:dout = layer.backward(dout)# 设定grads = {}for idx in range(1, self.hidden_layer_num+2):grads['W' + str(idx)] = self.layers['Affine' + str(idx)].dW + self.weight_decay_lambda * self.layers['Affine' + str(idx)].Wgrads['b' + str(idx)] = self.layers['Affine' + str(idx)].dbreturn grads
Dropout
权值衰减实现简单,也易于理解,但是当网络模型变得很复杂的时候,权值耍贱的作用就很难体现了,这时候,Dropout就成为了更好的选择。
Dropout的思路很简单,复杂模型在经过多轮的学习后,可能会出现类似路径依赖的后果,这个时候可以随机的删除神经元,迫使模型重新学习,被删除的神经元不再进行信号的传递。训练过程中,每传递一次数据,就会随机删除一定数目的神经元,测试时,对于所有神经元的信号照常传递,但是对输出需要乘上删除的比例,书上给出的图如下:

书上给出的代码实现如下:
class Dropout:def __init__(self, dropout_ratio=0.5):#设定概率self.dropout_ratio = dropout_ratioself.mask = Nonedef forward(self, x, train_flg=True):#传播if train_flg:self.mask = np.random.rand(*x.shape) > self.dropout_ratio#随机生成和x形状相同的数组,比预设值大的元素设为1return x * self.maskelse:return x * (1.0 - self.dropout_ratio)def backward(self, dout):return dout * self.mask#反向保持原样
使用之后的结果如下,可以看到两者较为接近。

机器学习中常使用集成学习(多个模型单独学习,推理取输出平均值),这和Dropout的思想不谋而合,Dropout每次随机删除一些神经元,就相当于用一个新的模型学习了一次,可以理解为它将集成学习的效果通过一个网络实现了。
超参数验证
除了权重偏置等,超参数也是需要考虑的优化参数之一,如果超参数没有取到合适的值,模型的性能就会很差(如学习率取过大过小)。
验证数据
对于超参数,是不能用测试数据评估的,因为如果使用测试数据评估,超参数的值就会对测试数据发生过拟合,因此,对于超参数需要使用专用的确认数据,这种数据被称为验证数据。
最优化和实现
超参数其实是试出来的,因此在进行最优化时,选择一个恰当的其实范围进行尝试是很重要的,在选取好范围之后,在范围内进行随机取样,然后进行小数量的训练(步骤不多)进行观察,根据结果再判断选取的值是否合适,循环往复(存在更加优化的方法,如贝叶斯最优化)。
书上超参数的随机采样实现如下:
weight_decay = 10 ** np.random.uniform(-8, -4)#这里是权值衰减系数,随机范围为1e-8到1e-4lr = 10 ** np.random.uniform(-6, -2)#这里是学习率,随机范围为1e-6到1e-2
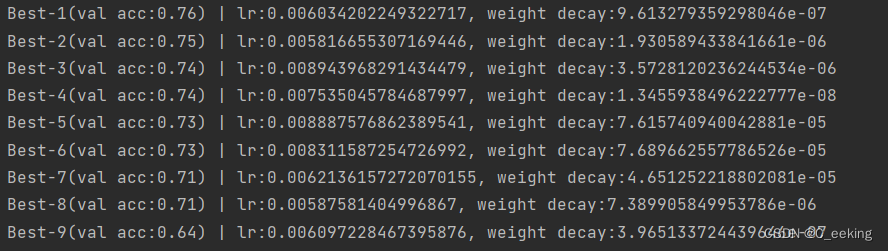
对于不同随机的学习率和权值衰减系数,得到的验证数据的精度如下(虚线为训练数据精度,实线为验证数据精度):

当我们细看结果时(图片如下),可以看到,根据结果,我们可以缩小区间和变化的幅度(例如选取Best-1到Best-6之间的取值)进行尝试,类似寻找极值的方法来找到最优的超参数。
总结
可以看到,当使用了一些深度学习优化上的技巧之后(Dropout、初始值赋值等),不仅是学习过程,甚至在结果上,所得到的模型的泛化能力和数据准确度都可以得到一定程度的加强,因此,深度学习的优化技巧是非常重要的。
参考文献
- 《深度学习入门——基于Python的理论与实现》