

首先,需要理解用户的需求。问题1需要数学模型来确定小行星的相对距离,而问题2需要预测短期轨道并计算特定时间的观测角度。这两个问题都需要结合天文学和数学建模的知识,涉及到轨道力学和几何定位的方法。
接下来,查阅提供的搜索结果,看看是否有相关信息。但用户的搜索结果主要关于小行星2024 YR4的威胁、联合国的应对措施、以及一些防御技术,比如DART任务。不过这些内容和轨道预测模型关联不大。因此,需要依靠自己的知识库来构建答案,但需要确保正确性。
对于问题1,确定相对距离。当多个天文台同时观测同一颗小行星时,每个天文台会记录下该小行星的方位角和高度角。这时候可以利用三角测量或视差法来确定距离。具体来说,每个天文台的位置已知(经纬度),通过测量同一时间的目标角度,可以构建空间中的视线方向,通过交叉点确定位置。这涉及到球面三角学或者三维几何的计算。例如,将各天文台的位置转换为地心坐标系,然后计算小行星的位置,从而得到距离。
问题2是关于轨道预测。根据多次观测数据,需要拟合小行星的轨道参数,然后根据轨道参数进行外推,预测未来的位置。常用的方法包括使用开普勒轨道根数,通过最小二乘法拟合观测数据,得到轨道参数。然后根据这些参数,使用轨道方程计算未来时刻的位置,再转换为各天文台的观测角度。这里需要考虑摄动因素,比如其他天体的引力影响,但用户提到的是短期预测(15或30天),摄动影响较小,可以忽略或用简化的模型处理。
现在需要考虑如何具体建立数学模型。对于问题1,可能需要使用视差法。两个天文台的位置差异形成基线,通过测量同一目标的角度差异,计算视差角,从而确定距离。公式可能涉及基线长度、角度差和视差之间的关系。例如,距离D = B / (2 * sin(θ/2)),其中B是基线长度,θ是视差角。
对于问题2,轨道预测需要确定六个轨道根数:半长轴、偏心率、轨道倾角、升交点经度、近地点幅角、平近点角。通过多次观测的位置数据,可以使用高斯方法或最小二乘法来拟合这些参数。一旦轨道参数确定,就可以根据时间计算小行星的位置,再转换为赤经赤纬,最后转换为各个天文台的方位角和高度角。
在算例部分,用户提到2024 YR4小行星,但根据搜索结果,尤其是网页6和7,该小行星的撞击概率已经被降为接近零,说明轨道数据已经被精确测定。可以引用该小行星的数据作为例子,比如从MPC获取其观测数据,应用上述模型进行计算,预测其轨道。
此外,需要注意数据来源,比如MPC官网提供的观测数据格式,需要解析这些数据来获取时间、位置等信息。例如,MPC的数据通常包括观测时间、观测站的位置、测量的赤经赤纬等。这些数据可以转换为地心坐标系,用于计算。
还需要考虑误差分析,比如观测误差对距离计算和轨道预测的影响。不过用户的问题更关注模型建立,而不是误差分析。
总结起来,问题1的模型基于多站观测的角度差异,利用几何方法计算距离;问题2则需要轨道力学模型,拟合轨道参数后进行预测。在回答时,需要详细说明数学模型,并以2024 YR4为例,引用MPC的数据作为支持。





首先,已知社交网络中用户之间的关注关系,探测到当前谣言的传播情况。平台只能使用澄清信息的手段,封禁用户或者其他方法暂时不考虑。问题一和问题二的区别在于澄清信息的投放方式不同:问题一中,选中的用户如果转发谣言,会自动附带澄清;问题二中,选中的用户无论是否转发谣言都会被要求发布澄清,但用户可能同意或拒绝,而平台最终只能选不超过m个用户。
针对问题一,需要建模选择哪m个用户作为关键节点,使得当他们在转发谣言时自动附带澄清信息,从而最大程度减少谣言的传播。思路是,找到那些在传播路径中处于关键位置的用户,这样他们的澄清能覆盖更多的后续传播路径。例如,选择那些在谣言传播网络中具有高中心性的节点,比如介数中心性高的节点,或者影响力大的节点。或者考虑阻断可能的传播路径,这需要用一些传播模型,比如独立级联模型(IC)或线性阈值模型(LT),然后选择最优的m个节点来最大化澄清的影响。
问题二的情况有所不同,这里的澄清信息是独立发布的,即使这些用户不转发谣言,他们也会发布澄清信息。这时候需要考虑这些用户自身的传播能力,即他们的澄清信息能够覆盖多少其他用户,或者如何通过他们的发布来覆盖那些容易被谣言影响的用户。需要考虑的是,如何选择m个用户,使得他们的澄清信息能够覆盖尽可能多的可能被谣言影响的用户群体,或者形成某种竞争,让澄清信息的传播能够抵消谣言的传播。
针对问题一,运用的数学模型需要确定每个候选用户被选中后对谣言传播的抑制效果。例如,模拟当某个用户被选中时,其后续传播的每个谣言信息都会附带澄清信息,这样可能降低该信息被继续转发的概率。或者,假设当用户u被选中后,所有经过u转发的谣言都会被附带澄清,从而使得这条信息的传播能力降低。这相当于在传播网络中,将用户u所在的边赋予更低的传播概率,或者直接阻断某些边。
这时候,问题转化为选择m个节点,使得阻断这些节点的传播路径或降低其传播效率,从而使得最终的谣言影响最小。这类似于经典的“影响最大化”问题,但相反,这里是“影响最小化”,也就是选择节点来最大程度地减少传播。这种情况下,需要使用类似贪心算法的方法,每次选择能够带来最大边际效益的节点,直到选满m个。
不过,这里挑战是如何量化每个节点被选中后的影响。例如,在独立级联模型中,每个活跃节点在下一步以一定概率p影响其邻居。如果某个节点被选中作为澄清节点,那么当它转发谣言时,附带澄清信息,可能使得该谣言被后续转发的概率降低。比如,原本p的传播概率可能变为p'=p*q,其中q是澄清信息带来的抑制因子。或者可能完全阻断该节点的传播,即p'=0。但题目中的描述是“自动附带澄清信息”,这让接收者在看到谣言的同时看到澄清,从而减少他们转发的可能性。这时候需要建模这种双重信息的影响。
需要将每个被选中的用户u的传播效果进行削弱。例如,原本用户u的每个被转发的谣言信息会附带澄清,导致其所有后续传播的可能性降低。例如,每个被u转发的谣言信息的传播概率乘以一个系数α(0<α<1),或者完全阻止该用户转发谣言(这类似于问题一中的用户被选中后,其无法传播谣言,但题目中说的是当转发时自动附带澄清,并不阻止转发,而是让接收者更可能不继续传播)。
对于这种情况,需要构建一个传播模型,其中被选中的节点在传播谣言时,其后续传播的有效性被降低。比如,在独立级联模型中,当用户v被u激活(即u转发了谣言到v),如果u是澄清节点,那么v被激活的概率会降低,或者当v收到来自澄清节点u的谣言时,v可能不会转发,或者转发的概率减少。或者,认为当v收到来自澄清节点u的谣言附带澄清信息,那么v即使被激活,也不会进一步传播。这需要不同的处理方式。
这需要调整传播模型中的参数,例如,当用户被选为澄清节点时,他们的传播成功率会降低。比如,原本每个边(u, v)有一个传播概率p_uv,如果u被选为澄清节点,那么当u传播谣言给v时,v被感染的概率变为p_uv * α,其中α是一个抑制因子,或者直接变为0,即澄清节点u的传播无效。或者,假设澄清信息的存在使得每个接收到来自澄清节点u的谣言的用户v,同时接收到澄清,因此不会被感染(即不转发谣言),或者以较低的概率转发。
这里需要明确模型假设。例如,假设当用户u被选为澄清节点,任何通过u转发的谣言都会被附带澄清信息,导致这条信息的接收者v在接收到后不会转发该谣言。或者,接收者v在接收到带有澄清的谣言后,其转发概率降低。这种情况下,如何量化这种影响是关键。
例如,在问题一中,当选中用户u作为澄清节点,那么所有通过u转发的谣言信息都会被附带澄清。这使得任何从u传播到其关注者v的信息,v的转发概率降低。例如,假设原本用户v在收到谣言后会以概率p转播,但如果谣言附带澄清信息,则v的转发概率变为p' = p * (1 - θ),其中θ是澄清信息带来的抑制效果。或者,可能完全阻止转发,即p' =0。这需要根据具体情况设定。
因此,问题一转化为:在给定的传播网络中,选择m个节点,使得当这些节点转发谣言时,其后续传播的概率被降低(比如每个这样的边传播概率变为原来的α倍,或者变为0),从而使最终的预期谣言传播范围最小。
这个问题类似于寻找网络中的关键节点,阻断它们的传播能力。可以转化为一个组合优化问题,目标函数是预期受影响节点数的最小化,约束是选m个节点。由于计算这个目标函数可能比较复杂,尤其是在大型网络中,需要使用启发式方法,例如贪心算法,或者利用影响函数的子模性等性质。
假设传播模型中的影响函数是子模的,那么贪心算法可以提供近似最优解。例如,每次选择那个能最大程度减少预期传播量的节点,直到选满m个。但需要验证这种情况下目标函数是否满足子模性,即边际递减效应。
对于问题二,澄清信息是独立发布的,即使这些用户没有转发谣言,他们也会发布澄清信息。此时,平台需要选择不超过m个用户,让这些用户发布澄清信息,以抵消谣言的影响。这里的澄清信息可能被他们的关注者看到,从而降低他们相信或传播谣言的可能性。此时,需要考虑澄清信息自身的传播路径和覆盖范围。例如,如果用户u发布澄清信息,那么他的关注者v可能会被澄清信息影响,从而对谣言免疫,或者在接收到谣言时不会转发。
这种情况下,需要建模澄清信息的传播和谣言传播的竞争关系。例如,当用户v接收到澄清信息后,可能不会被谣言感染,或者被感染的概率降低。例如,在独立级联模型中,可以假设如果用户v已经接收到了澄清信息,则当谣言传播到v时,v不会被激活。或者,澄清信息的传播可能需要与谣言传播竞争时间,即如果澄清信息先到达v,那么v对谣言免疫;反之,则可能被感染。
这种情况下,如何选择m个用户作为澄清信息的发布者,使得尽可能多的用户先接收到澄清信息,从而阻止谣言的传播。这类似于疫苗接种问题,选择一部分节点进行“免疫”,使得他们在被感染前已经被免疫,从而阻断传播路径。在这种情况下,问题转化为寻找最优的m个节点,使得免疫这些节点后,谣言的传播范围最小。这同样是一个组合优化问题,可以使用类似贪心算法的方法。
或者,如果澄清信息的发布可以独立于谣言的传播,那么需要考虑澄清信息自身的传播范围和影响力。例如,用户发布澄清信息后,他们的关注者可能被澄清信息影响,进而可能转发澄清信息,扩大其覆盖范围。这时候,澄清信息的传播也是一个级联过程,和谣言传播类似。此时,平台需要选择m个用户作为种子,使得澄清信息的传播能覆盖尽可能多的可能被谣言影响的用户,从而减少谣言的影响。
这种情况下,问题需要同时考虑谣言的传播和澄清信息的传播,并且选择m个澄清种子,使得两者的传播覆盖产生最大的重叠,或者澄清信息的覆盖能最大程度地减少谣言的影响。比如,预期被澄清信息覆盖的用户将不会被谣言影响,因此需要最大化澄清信息的覆盖,或者最大化两者的覆盖交集。
但问题二中,用户可能选择同意或拒绝发布澄清信息,但平台最终能找到不超过m个用户来发布。这里需要假设平台可以强制这些用户发布澄清信息(即最终能确保m个用户同意),或者需要考虑用户的接受概率,但题目中描述的是“平台最终将找到不超过m个用户”,意味着平台能够成功说服这些用户,所以可以假设这m个用户一定会发布澄清信息。
因此,问题二转化为选择m个用户作为澄清信息的种子,他们的发布行为将启动澄清信息的传播,从而尽可能覆盖更多用户,减少谣言的传播。这时候,可能需要同时建模谣言和澄清信息的传播,并选择澄清种子使得两者的综合影响最小化谣言的影响。




现在要解决这个化工厂脱硫工艺的三个问题。首先,第一个问题:根据直到时刻t的输入数据预测时刻t的输出,不考虑反应延时。用时间序列或者回归模型。输入数据包括五种原料气体的输入速率,输出是二氧化硫和硫化氢的浓度。数据是时间序列,相邻间隔一致,所以需要利用历史输入来预测当前输出。不过题目说不考虑反应延时,所以当前时刻的输出只和当前时刻的输入有关?或者可能存在反应过程的延迟,但题目说不考虑,所以输入输出是即时的。这样的话,建立一个多输入多输出的回归模型,比如线性回归、神经网络之类的,用t时刻的输入变量预测t时刻的输出变量。但数据存在时间上的自相关性,所以需要考虑ARIMA模型或者结合输入的时间序列特征。不过题目明确说不考虑延时,所以模型结构比较简单。比如,每个时间点的输出只由当前输入决定,不需要历史输入数据。考虑特征工程,或者是否有其他因素影响。例如,是否反应釜的状态会积累,比如某些中间产物的浓度会影响当前输出?但题目里假设这些过程已经被包含在输入输出关系中。所以,直接用当前的输入参数(五个原料的输入速率)来预测当前的两个输出(二氧化硫和硫化氢浓度)。这个时候,模型是一个多输出的回归模型,比如多元线性回归,或者随机森林、支持向量回归,或者神经网络。不过需要看数据是否存在非线性关系。先尝试线性模型,如果效果不好再换复杂的模型。验证模型在历史数据上的表现。数据可能存在噪声,需要预处理,比如归一化、去除异常值等。对于问题一,需要建立一个监督学习模型,输入是五个变量的当前值,输出是两个变量的预测值。
接下来第二个问题,根据直到t时刻的输入和输出数据,预测t+10到t+70之间是否会出现不合格的情况。这里,不合格定义为二氧化硫超过k1或硫化氢超过k2。预测未来一段时间内的输出是否超标。此时,需要考虑时间序列的预测,不仅要预测未来的输出,还要判断是否有超过阈值的情况。阈值k1和k2可以根据模型性能自行设定,但要在保证正确率的前提下尽可能小。需要先确定合适的阈值,然后建立分类模型,判断在未来60个时间单位内是否会发生超标。这里问题是如何将时间序列预测转化为分类问题。思路是:利用历史数据(输入和输出)建立模型,预测未来t+10到t+70的输出值,然后检查这些预测值是否超过阈值k1或k2。如果其中任一时刻超过,则标记为不合格。但预测多个时间点的输出可能比较复杂。或者,将问题转化为预测未来某个窗口内的最大值是否超过阈值?例如,预测在t+10到t+70之间,二氧化硫的最大值和硫化氢的最大值是否超过各自的阈值。这样,模型可以输出这两个最大值,或者直接判断是否会有超过的情况。或者,建立一个时间序列模型,比如LSTM,来预测未来的多个时间步的输出,然后统计这些预测结果中的最大值是否超过阈值。或者,通过建立回归模型,预测每个未来时间点的输出,然后进行判断。不过时间跨度较长,需要考虑滞后效应或者动态系统的建模。比如,使用状态空间模型,或者基于时间序列的递归预测。例如,使用t时刻及之前的输入和输出数据,预测t+1的输出,然后用这个预测作为输入的一部分,继续预测t+2,直到t+70。但这样累计误差会比较大。或者,是否可以利用t时刻的输入数据(可能未来输入未知?题目中的输入数据可能是指历史输入,所以未来的输入是否可控?在问题二中,题目中说“根据从开始直至时刻t的输入数据和输出数据”,所以假设未来的输入在预测时是未知的?但实际情况中,工厂无法预知未来的输入,所以在预测未来输出时,需要假设未来的输入维持当前值,或者按照某种模式变化?但题目中的输入是原料的输入速率,由工厂控制,所以要根据当前的控制策略来预测未来的输入?但题目中没有给出控制策略,所以如何处理未来的输入变量?这是一个关键问题。例如,在问题二中,预测未来t+10到t+70的输出,需要知道这段时间内的输入数据。但题目中的输入数据是直到t时刻的,所以未来的输入未知。这时候需要假设输入保持不变,或者基于历史数据进行预测?或者题目是否允许在问题二中,在预测时假设未来的输入是已知的?这需要仔细看问题描述。题目在第二阶段问题中的描述是:“根据从开始直至时刻t的输入数据和输出数据,预测在t + 10到t +70之间的输出是否不合格。”所以问题二的输入数据包括直到t的输入,而未来t+1到t+70的输入未知,因此需要根据现有的输入数据预测未来的输入?或者是否,输入变量在未来的时间点是被控制的,因此需要预测它们的变化?或者题目是否假设输入变量在未来是已知的?比如,在问题二中,是否输入变量在t+1到t+70之间已经被计划好,或者保持不变?或者是否题目中的输入数据指的是直到t时刻的历史输入,而未来的输入由控制策略决定?这时候需要进一步明确,但根据问题描述,需要假设未来的输入未知,因此需要利用历史输入数据来预测未来的输入趋势。比如,使用时间序列模型预测未来的输入变量,然后基于这些预测的输入变量来预测输出。或者,认为输入变量在预测的时间窗口内是保持不变的?或者,在问题二中,是否模型需要能够预测未来输出,不管输入如何变化?这比较复杂。例如,问题二中给出的输入数据是直到t时刻的,所以需要假设未来的输入变量如何变化。但题目中并没有说明,所以需要做某种假设。例如,假设输入变量在未来的时间段内保持t时刻的值,或者根据历史数据的趋势进行预测。这会影响模型的准确性。但题目中的输入变量是可控的,即在问题二中,当预测未来输出时,需要假设输入变量按照某种已知的方式变化?或者,题目中的输入数据指的是原料气的输入速率,而工厂可以调整这些输入,但问题是根据历史数据预测未来输出是否超标,这时候可能需要考虑输入变量在未来的变化情况。但题目没有给出关于未来输入如何变化的信息,所以需要假设未来的输入是已知的,或者需要根据历史数据进行预测。如果无法获得未来输入的信息,那么模型需要根据历史输入和输出的动态关系,预测未来的输出。例如,使用自回归模型,或者考虑输入和输出之间的时间滞后效应。例如,建立类似VAR(向量自回归)模型,或者状态空间模型,将输入和输出都作为时间序列变量,预测未来的输出。或者,可能将输入序列作为外生变量,建立ARIMAX模型或其他带有外生变量的时间序列模型。在这种情况下,未来的输入变量需要被预测或者假设。例如,如果输入变量在未来时间段内没有给出,需要假设它们保持不变,或者按照某种模式变化。但在实际应用中,如果工厂可以控制输入变量,那么未来输入的变化取决于控制策略,这在题目中可能未被提及。因此,需要明确模型是否应该考虑未来输入的预测,或者是否假设未来输入不变。如果题目中没有说明,需要做一个合理的假设,并在模型中说明。例如,假设未来的输入变量将保持最近一段时间的平均值,或者最后一个已知值,或者根据某种趋势预测。这对模型的准确性产生影响。不过题目希望我们利用历史输入和输出数据来建立模型,能够预测未来的输出,而不需要未来的输入数据。例如,输入变量和输出变量之间存在某种动态关系,可以用历史数据来捕捉这种关系。例如,使用LSTM等模型,通过历史输入和输出的序列来预测未来的输出,而不需要未来的输入。或者,这涉及到系统辨识的问题,建立一个动态模型,将历史输入和输出作为状态,预测未来的输出。例如,状态空间模型,其中系统的状态由过去的输入和输出决定,然后预测未来的输出。这种情况下,不需要未来的输入数据,而是通过系统的动态方程来递推得到未来的输出。或者,问题中的反应过程存在一定的惯性,即当前的输出不仅由当前输入决定,还由之前的输入和输出状态决定。例如,存在反应物积累的情况,所以模型需要考虑时间上的依赖关系。因此,对于问题一,应该使用当前输入来预测当前输出,而问题二则需要考虑时间序列的动态,建立能够预测未来输出的模型。问题一比较简单,使用回归模型即可,而问题二和问题三需要更复杂的时间序列预测模型。比如,问题一中,模型输入是t时刻的五个输入变量,输出是两个输出变量。问题二中,需要预测未来60个时间单位的输出,是否其中任何一个超过阈值。这时候需要预测每个未来时间点的输出,然后判断是否超过阈值。或者,是否可以将问题转化为分类,直接判断在这段时间内是否会有超过阈值的情况。对于时间序列预测,需要使用多步预测的方法,比如递归预测,或者直接预测多个时间点。例如,使用seq2seq模型,或者LSTM进行多步预测。或者,采用滑动窗口的方式,将历史数据作为输入,预测未来的多个时间步。对于问题二,需要先设定阈值k1和k2,然后调整它们,使得在保证正确率的情况下,阈值尽可能小。需要通过ROC曲线或者其他方法来选择最佳阈值。或者,可以将问题视为二分类问题(合格/不合格),并优化阈值的选择,使得在分类准确率最高的情况下,阈值尽可能小。或者,需要将预测的连续输出转换为是否超过阈值的事件,然后评估模型的预测性能。问题三则需要进一步预测不合格事件发生的具体时间,即在t+10到t+70之间,何时会发生超标。这比问题二更复杂,需要预测每个时间点的输出,并找到首次超过阈值的时间点。或者,需要回归模型来预测事件发生的时间。或者,可以将其视为时间点预测,例如分类每个时间点是否超标,或者回归预测最早超标的时刻。总之,这三个问题需要逐步建立模型,从简单的回归到复杂的时间序列预测和事件检测。




# 问题一:随机森林回归from sklearn.ensemble import RandomForestRegressormodel_rf = RandomForestRegressor()model_rf.fit(X_train, y_train)# 问题二:LSTM时间序列预测from tensorflow.keras.models import Sequentialmodel_lstm = Sequential()model_lstm.add(LSTM(50, input_shape=(window_size, n_features)))model_lstm.add(Dense(60 * 2)) # 预测60步,每步两个浓度# 问题三:时间点预测def predict_event_time(predictions, k1, k2): for i, (so2, h2s) in enumerate(predictions): if so2 > k1 or h2s > k2: return i + 10 # t+10为起始点 return None

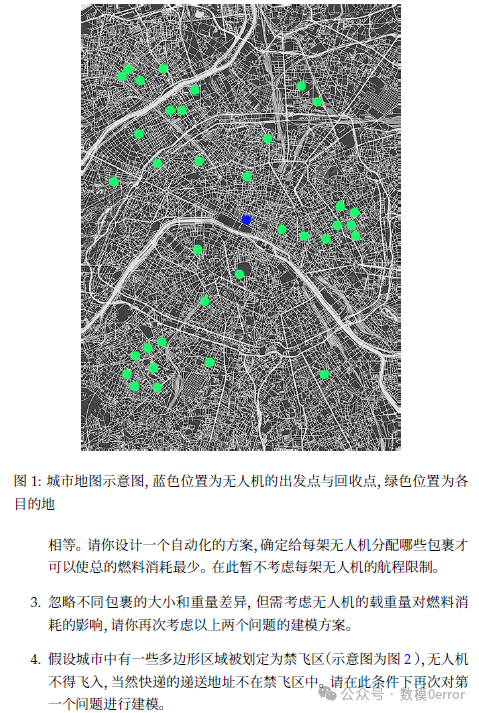

首先是第一阶段的问题1:在忽略天气、禁飞区、高度差和载重影响的情况下,如何安排单个无人机的目的地列表最合理?这里的关键词是合理,指的是路径最短,或者燃料消耗最少。因为燃料和时间通常和飞行距离相关,所以转化为旅行商问题(TSP),也就是寻找访问所有目的地并返回仓库的最短路径。但要考虑的是,无人机每次卸货后需要再次起飞,所以顺序的安排会影响总距离。这时候,最优的路线是经过所有点且总距离最短的环路,也就是经典的TSP。不过,是否可能有更优的考虑?比如,卸货时是否需要考虑顺序对后续路径的影响?例如,如果在某个点卸货后,剩下的路径是否更优?还是TSP的解,因为TSP已经是最短回路。所以问题1的答案是将目的地列表按TSP的最优路径排序,这样可以最小化总飞行距离,从而节省燃料和时间。
接下来是问题2:多架无人机分配包裹,使得总燃料消耗最少,且每架装载量大致相等。这时候需要考虑多旅行商问题(mTSP)。目标是将所有目的地分成若干组,每组由一架无人机负责,每组内的路径是TSP的最优解,同时各组之间的分配要平衡包裹数量或总任务量(比如路径长度可能不同,但题目说装载量大致相等,可能更侧重包裹数量)。但题目中不考虑航程限制,所以只需要考虑如何将包裹分配到各无人机,使得总行驶距离之和最小。这时候,这类似于将城市中的点聚类,每个类由一个无人机服务,然后在每个类中求解TSP。如何聚类?需要使用聚类算法,比如K-means,根据仓库的位置,将各个目的地分成K个簇,每个簇对应一个无人机,然后每个簇内部走TSP。这样总距离更小。但如何确定簇的数量?题目中说“若干架无人机”,包裹数量已经确定,或者需要根据包裹总数和每架的最大装载量来确定。但问题2中不考虑航程限制,所以需要将包裹尽可能平均分配,同时总路径之和最小。这时候,最佳的方法是将邻近的包裹分配给同一无人机,这样每个无人机的路径较短。因此,解决方案是先将所有目的地进行聚类,分成与无人机数量相等的簇,每个簇内的点距离较近,然后每个簇求解TSP。但问题中没有给定无人机数量,需要假设无人机数量由包裹总数和每架的大致装载量决定。或者题目要求,给定一定数量的无人机,如何分配包裹。这时候,需要用mTSP模型,其中总路程之和最小化,同时各无人机的任务量(包裹数量)大致相等。所以问题2的模型是一个组合优化问题,结合聚类和路径优化。例如,使用启发式算法,如遗传算法,或者先聚类再优化路径。
问题3:考虑载重量对燃料消耗的影响。此时,无人机的燃料消耗不仅与飞行距离有关,还与载重量有关。比如,无人机在携带更多包裹时,每公里的耗油量会增加。因此,在安排路线时,需要优先卸下较远的包裹,或者优化路线顺序以减少载重时的飞行距离。例如,如果无人机携带多个包裹,先送远的点,后面的行程载重减少,总消耗可能更小。这种情况下,问题1的单无人机路径规划不再是简单的TSP,而需要考虑载重变化的影响。比如,类似于车辆路径问题(VRP)中的考虑,当载重影响油耗时,路线安排需要先访问较远且较重的点,以减轻后续飞行的负担。对于问题3的第一问,单无人机的路径安排需要结合载重对燃料的影响。每个包裹的重量相同(因为题目忽略不同包裹的大小和重量差异),但载重量是包裹的数量。因此,无人机在飞行中的载重量随着包裹的逐个卸下而减少。例如,假设每个包裹重量相同,无人机出发时载有n个包裹,每卸下一个,载重减少一个单位。那么,总燃料消耗等于每段飞行距离乘以当时的载重量之和。例如,从仓库出发到第一个目的地,载重量是n,飞行距离d1;然后到第二个目的地,载重量是n-1,飞行距离d2;依此类推,直到返回仓库时的载重量是0。这时候,总燃料消耗是Σ(d_i * w_i),其中w_i是当前载重量。因此,为了最小化总消耗,需要调整访问顺序,使得高载重的阶段飞行的距离更短,或者合理安排顺序,让较远的点在载重较小时飞行。这类似于TSP问题的一个变种,其中目标函数不是总距离,而是带权的距离总和,权重是当前的载重量。比如,每个路径段的权重取决于在该段飞行时的载重量。这种情况下,最优路线是先访问近的点,然后访问远的点?或者相反?需要具体分析。例如,假设有两个点,A距离仓库10km,B距离20km。如果先送A,再送B,那么到A是10km带2单位重量,到B是20-10=10km带1单位重量,返回是20km带0。总消耗是2*10 +1*10 +0*20=30。如果先送B,再到A,到B是20带2,到A是20+10=30?或者飞行顺序是仓库→B→A→仓库。飞行距离是20(到B)+从B到A的距离(假设是d) +从A到仓库的距离10。总消耗是2*20(到B) +1*d(B到A) +0*10(A到仓库)。假设B到A的距离是比如25,那么总消耗是40 +25=65,这比之前的情况更差。但如果B到A的距离更短,比如如果是直线,总距离更小?这可能比较复杂。或者是否应该先送远的点,从而在返回时载重更小?例如,先送B,再送A,这样到B的飞行是20带2,然后从B到A假设是距离d,带1,最后A到仓库10带0。如果d是更短?比如假设A和B在相反方向,那总距离更长。所以这时候需要一个数学模型来计算不同顺序下的总消耗,并找到最优顺序。对于问题3中的单无人机问题,需要将目标函数改为各段距离乘以当前载重量之和的最小化,而路径是访问所有点并返回。这类似于旅行商问题的一个变体,需要动态规划或其他优化方法。对于多无人机的问题3的第二部分,同样需要考虑分配包裹到各无人机,使得总消耗(各无人机路径的加权距离之和)最小,同时每架无人机的装载量大致相等。此时,除了路径长度,还要考虑载重量的分布,所以需要不同的聚类方式,或者在分配包裹时考虑各无人机路径中的载重变化带来的消耗。
问题4:考虑禁飞区的情况下重新考虑问题1。此时,无人机不能进入禁飞区,但包裹的目的地都不在禁飞区。所以路径规划需要绕过禁飞区,找到两点之间的最短可行路径。这时候,原来的直线距离可能不可行,需要绕道。此时,TSP的模型需要将两点之间的距离计算为避开禁飞区的最短路径长度。比如,对于每对点,计算避开禁飞区的最短路径长度,然后在这个新的距离矩阵上求解TSP。但如何计算这些最短路径?需要使用路径规划算法,如A*算法或Dijkstra算法,在考虑禁飞区的情况下找到两点间的最短路径。或者,可以将城市地图建模为图,其中节点是可行点,边是可行路径,避开禁飞区。然后,对于所有目的地点,计算它们之间的最短路径,形成新的距离矩阵,再在这个矩阵上求解TSP。因此,问题4的建模需要先预处理各点之间的最短路径(避开禁飞区),然后在这个基础上应用TSP模型。这会增加计算的复杂度,因为每个点对之间的距离需要单独计算。




2025年第十八届“认证杯”数学中国数学建模网络挑战赛C题完整word论文+代码+结果![]() https://download.csdn.net/download/qq_52590045/905927612025年第十八届“认证杯”数学中国数学建模网络挑战赛B题完整word论文+代码+结果
https://download.csdn.net/download/qq_52590045/905927612025年第十八届“认证杯”数学中国数学建模网络挑战赛B题完整word论文+代码+结果![]() https://download.csdn.net/download/qq_52590045/905927492025年第十八届“认证杯”数学中国数学建模网络挑战赛A题完整word论文+代码+结果
https://download.csdn.net/download/qq_52590045/905927492025年第十八届“认证杯”数学中国数学建模网络挑战赛A题完整word论文+代码+结果![]() https://download.csdn.net/download/qq_52590045/90592745
https://download.csdn.net/download/qq_52590045/90592745
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓