大纲
1.ZooKeeper如何进行序列化
2.深入分析Jute的底层实现原理
3.ZooKeeper的网络通信协议详解
4.客户端的核心组件和初始化过程
5.客户端核心组件HostProvider
6.客户端核心组件ClientCnxn
7.客户端工作原理之会话创建过程
1.ZooKeeper如何进行序列化
(1)什么是序列化以及为什么要进行序列化操作
(2)ZooKeeper中的序列化方案
(3)如何使用Jute实现序列化
(4)Jute在ZooKeeper中的底层实现
(5)总结
要实现zk客户端与服务端的相互通信,就要解决通过网络传输数据的问题。而要通过网络传输定义好的Java对象数据,就必须要先对其进行序列化。
(1)什么是序列化以及为什么要进行序列化操作
一.什么是序列化
序列化是指将我们定义好的Java类型转化成数据流的形式。因为在网络传输过程中,TCP协议采用流通信方式,提供可读写的字节流。这种设计的好处是能避免在网络传输过程中经常出现的问题,比如消息丢失、消息重复和排序等问题。
二.什么时候需要序列化
通过网络传递对象或者将对象信息进行持久化时,就要将对象进行序列化。
三.Java中的序列化和反序列化
我们较为熟悉的序列化操作是:当需要序列化一个Java对象时,首先要实现一个Serializable接口。
public class User implements Serializable {private static final long serialVersionUID = 1L;private Long ids;private String name;...
}实现了Serializable接口后并没有做什么实际的工作。Serializable接口仅仅是一个没有任何内容的空接口,它的作用就是标识该类是需要进行序列化的。Serializable接口的序列化与zk序列化实现方法有很大的不同。
public interface Serializable {}定义好序列化接口后,再看看如何进行序列化和反序列化操作。Java中的序列化和反序列化,主要用到了ObjectInputStream和ObjectOutputStream两个IO类。其中ObjectOutputStream负责将对象进行序列化字节流然后存储到本地,ObjectInputStream负责从本地存储中读取出字节流信息然后反序列化出对象。
//序列化
ObjectOutputStream oo = new ObjectOutputStream();
oo.writeObject(user);//反序列化
ObjectInputStream ois = new ObjectInputStream();
User user = (User) ois.readObject();(2)ZooKeeper中的序列化方案
zk并没有采用和Java一样的序列化方式,而是采用Jute框架来处理zk中的序列化。
Jute框架最早作为Hadoop的序列化组件,之后Jute组件从Hadoop中独立出来,成为一个独立的序列化解决方案。
虽然zk一直使用Jute框架作为其序列化的解决方案,但这并不意味着Jute相对其他框架性能更好,反倒是Apache Avro、Thrift等框架在性能上优于Jute。zk之所以一直采用Jute作为序列化解决方案,主要是因为新老版本兼容问题。也许在之后的版本中,zk会选择更加高效的序列化解决方案。
(3)如何使用Jute实现序列化
一.要进行序列化或反序列化的类需实现Record接口
二.对实现Record接口的类进行序列化和反序列化需要构建一个序列化器
三.使用Jute进行序列化和反序列化的步骤总结
一.要进行序列化或反序列化的类需实现Record接口
如果在zk中要想将某个Java类进行序列化:那么首先需要该类实现Record接口的serialize()方法和deserialize()方法。serialize()和deserialize()这两个方法分别是序列化方法和反序列化方法。
下面定义了一个名为TestJute的类,给出了在zk中进行序列化的具体实现。为了能够对TestJute对象进行序列化,首先需要TestJute类实现Record接口,并在对应的serialize()方法和deserialize()方法中实现具体的逻辑。
在TestJute类的序列化方法serialize()中,要实现的逻辑是:首先通过字符类型参数tag传递标记序列化标识符,然后使用writeLong()和writeString()等方法分别将对象属性字段进行序列化。在TestJute类的反序列化方法derseralize()中,其实现过程则与序列化过程相反。
序列化和反序列化的实现逻辑编码方式其实是相对固定的:都是先通过startRecord()方法开启一段序列化操作,然后通过writeLong()、readLong()等方法执行序列化或反序列化。
class TestJute implements Record {private long id;private String name;... public void serialize(OutputArchive a_, String tag) {a_.startRecord(this.tag);a_.writeLong(id, "id");a_.writeString(type, "name");a_.endRecord(this, tag);}public void deserialize(INputArchive a_, String tag) {a_.startRecord(tag);ids = a_.readLong("id");name = a_.readString("name");a_.endRecord(tag);}
}二.对实现Record接口的类进行序列化和反序列化需要构建一个序列化器
对TestJute对象进行序列化和反序列化的代码:
//开始序列化
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(baos);
new TestJute(1L, "demo").serialize(boa, "test") ;
//这里通常是TCP网络传输对象
ByteBuffer bb = ByteBuffer.wrap(baos.toByteArray());//开始反序列化
ByteBufferInputStream bbis = new ByteBufferInputStream(incomingBuffer);
BinaryInputArchive bbia = BinaryInputArchive.getArchive(bbis);
TestJute testJute = new TestJute();
testJute.deserialize(bbia, "test");三.使用Jute进行序列化和反序列化的步骤总结
步骤一:类需要实现Record接口的serialize()和deserialize()方法。
步骤二:构建一个序列化器BinaryOutputArchive或BinaryInputArchive。
步骤三:调用类的serialize()方法,将对象序列化到指定的tag中去。
步骤四:调用类的deserialize()方法,从指定的tag中反序列化出对象。
(4)Jute在ZooKeeper中的底层实现
Record接口是zk中专门用来进行网络传输或本地存储时使用的数据类型。因此zk中所有要进行网络传输或本地磁盘存储的类,都要实现Record接口。
public interface Record {public void serialize(OutputArchive archive, String tag) throws IOException;public void deserialize(InputArchive archive, String tag) throws IOException;
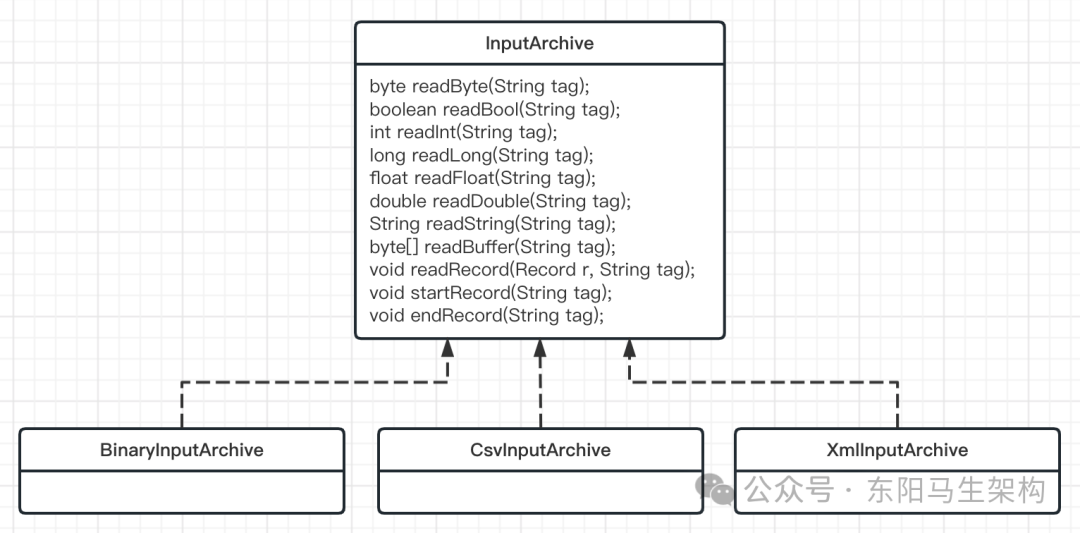
}Record接口的内部实现逻辑非常简单,只是定义了一个序列化方法serialize()和一个反序列化方法deserialize()。但起到关键作用的则是两个重要的类:OutputArchive和InputArchive。这两个类才是真正的序列化器和反序列化器,并且通过参数tag可以对多个序列化和反序列化的对象进行标识。
OutputArchive类定义了可以进行序列化的参数类型,使用方可以根据不同的序列化方式调用不同的实现类进行序列化操作。其中,Jute提供了Binary、CSV、XML等不同的序列化方式。
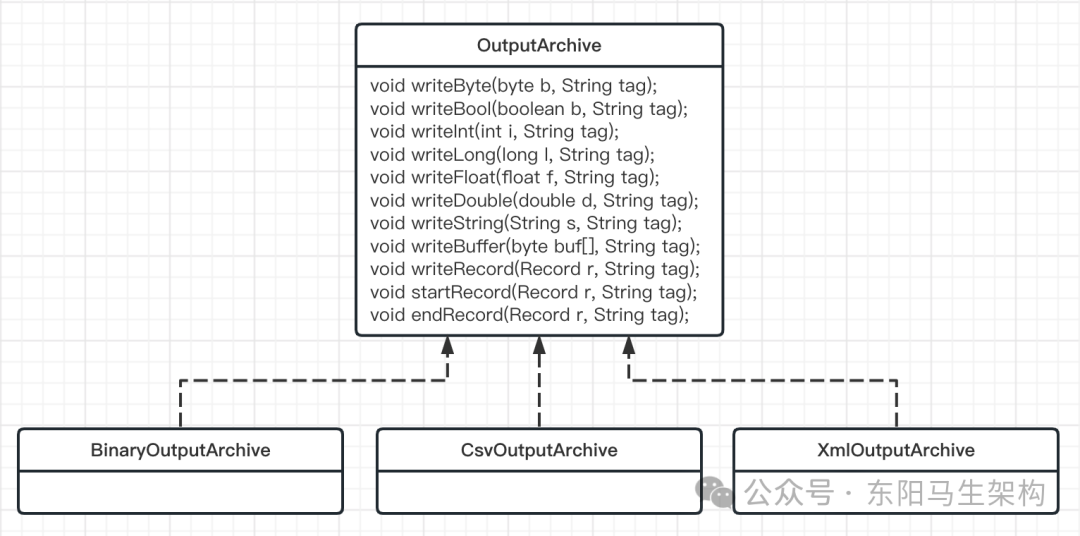
InputArchive类定义了可以进行反序列化的参数类型,使用方可以根据不同的反序列化方式调用不同的实现类进行反序列化操作。其中,Jute提供了Binary、CSV、XML等不同的反序列化方式。
注意:无论是序列化还是反序列化,都可以对多个对象进行操作。在调用Record的序列化和反序列化方法时,需要传入参数tag表示操作的是哪个对象。
(5)总结
一.什么是序列化以及为什么要进行序列化
序列化就是将对象编译成字节码,从而方便将对象信息存储到本地或者通过网络进行传输。
二.Java中和zk中的序列化方式
在Java中,Serializable接口是一个空接口,只是起到标识作用,用来标识实现了Serializable接口的对象是需要进行序列化的。
在zk中,要进行(反)序列化的对象需要实现Record接口里的两个方法,这两个方法分别是serialize()和deserialize()。
2.深入分析Jute的底层实现原理
(1)简述Jute序列化
(2)Jute的核心算法(底层原理)
(3)Binary方式的序列化
(4)XML方式的序列化
(5)CSV方式的序列化
(6)总结
(1)简述Jute序列化
Jute框架给出了3种具体的序列化方式:Binary方式、CSV方式、XML方式。序列化方式可以理解成将Java对象转化成特定格式,从而更加方便进行网络传输和本地化存储。
之所以提供这3种方式的格式化文件,是因为这3种方式可以跨平台和具有普遍性。
(2)Jute的核心算法(底层原理)
使用Jute实现序列化时需要实现Record接口。而在Record接口的内部,真正起作用的是两个工具类:分别是OutputArchive序列化器和InputArchive反序列化器。
OutputArchive只是一个接口,规定了一系列序列化相关的操作。Jute通过三个具体实现类分别实现了Binary、CSV、XML方式下的序列化操作。
(3)Binary方式的序列化
Binary序列化方式其实就是二进制的序列化方式。采用这种方式的序列化就是将Java对象信息转化成二进制的文件格式。
在Jute框架中实现Binary序列化方式的类是BinaryOutputArchive。在Jute框架中采用二进制方式进行序列化时,便会采用该类作为具体实现类。
这里以调用Record接口中的writeString()方法为例,writeString()方法会将Java对象的String字符类型进行Binary序列化。
当调用BinaryOutputArchive的writeString()方法时,首先会判断要进行序列化的字符串是否为空。如果为空,则调用writeInt()方法,将空字符串当作值为-1的int进行序列化。如果不为空,则调用BinaryOutputArchive的stringToByteBuffer()方法对字符串进行序列化。
除了writeString()方法外,其他的如writeInt()、wirteDoule()等方法,则是通过调用DataOutput接口中的相关方法来实现具体的序列化操作的。
BinaryOutputArchive的stringToByteBuffer()方法在将字符串转化成二进制字节流的过程中,首先会将字符串转化成字符数组CharSequence对象,然后根据ASCII编码判断字符类型:如果是字母,那么就使用1个byte进行存储。如果是诸如"¥"等符号,那么就采用两个byte进行存储。如果是汉字,那么就采用3个byte进行存储。
public class BinaryOutputArchive implements OutputArchive {private ByteBuffer bb = ByteBuffer.allocate(1024); private DataOutput out;public static BinaryOutputArchive getArchive(OutputStream strm) {return new BinaryOutputArchive(new DataOutputStream(strm));}...public void writeString(String s, String tag) throws IOException {if (s == null) {//如果为空,则调用writeInt方法,将空字符串当作值为-1的int进行序列化writeInt(-1, "len");return;}//如果不为空,则调用stringToByteBuffer方法对字符串进行序列化操作ByteBuffer bb = stringToByteBuffer(s);writeInt(bb.remaining(), "len");out.write(bb.array(), bb.position(), bb.limit());}final private ByteBuffer stringToByteBuffer(CharSequence s) {bb.clear();final int len = s.length();for (int i = 0; i < len; i++) {if (bb.remaining() < 3) {ByteBuffer n = ByteBuffer.allocate(bb.capacity() << 1);bb.flip();n.put(bb);bb = n;}char c = s.charAt(i);if (c < 0x80) {bb.put((byte) c);} else if (c < 0x800) {bb.put((byte) (0xc0 | (c >> 6)));bb.put((byte) (0x80 | (c & 0x3f)));} else {bb.put((byte) (0xe0 | (c >> 12)));bb.put((byte) (0x80 | ((c >> 6) & 0x3f)));bb.put((byte) (0x80 | (c & 0x3f)));}}bb.flip();return bb;}...
}总结:Binary二进制序列化方式的底层实现相对简单,只是将对应的Java对象转化成二进制字节流的方式。Binary方式序列化的优点有很多,因为各操作系统的底层都是对二进制文件进行操作的,而且各操作系统对二进制文件的编译与解析也是一样的。所以优点是各系统都能对二进制文件进行操作,跨平台的支持性更好,缺点就是会存在不同操作系统下,产生大端小端的问题。
(4)XML方式的序列化
XML是一种可扩展的标记语言,当初设计的目的就是用来传输和存储数据。XML很像HTML语言,而与HTML语言不同的是XML需要自己定义标签。在XML文件中每个标签都是自定义的,而每个标签就对应一项内容。一个简单的XML的格式如下所示:
<note><to>全班同学</to><from>王老师</form><heading>下周数学课</heading><body>伽罗瓦群论</body>
</note>在Jute框架中实现XML序列化方式的类是XmlOutputArchive。在Jute框架中采用XML方式实现序列化时,便会采用该类作为具体实现类。
这里以调用Record接口中的writeString()方法为例,writeString()方法会将Java对象的String字符类型进行XML序列化。
当调用XmlOutputArchive的writeString()方法时,首先会调用printBeginEnvelope()方法。通过printBeginEnvelope()方法来标记要序列化的字段名称,之后使用"<string>"和"</string>"作为自定义标签,来封装传入的字符串。
class XmlOutputArchive implements OutputArchive {private PrintStream stream;private Stack<String> compoundStack;...public void writeString(String s, String tag) throws IOException {printBeginEnvelope(tag);stream.print("<string>");stream.print(Utils.toXMLString(s));stream.print("</string>");printEndEnvelope(tag);}private void printBeginEnvelope(String tag) {if (!compoundStack.empty()) {String s = compoundStack.peek();if ("struct".equals(s)) {putIndent();stream.print("<member>\n");addIndent();putIndent();stream.print("<name>"+tag+"</name>\n");putIndent();stream.print("<value>");} else if ("vector".equals(s)) {stream.print("<value>");} else if ("map".equals(s)) {stream.print("<value>");}} else {stream.print("<value>");}}...
}可见,XmlOutputArchive的基本原理就是根据XML格式的要求解析传入的参数,并将参数按Jute定义好的格式,采用Jute设定好的默认标签,将传入的信息封装成对应的序列化文件。
采用XML方式进行序列化的优点是:通过可扩展标记协议,不同平台对序列化和反序列化的方式都是一样的。所以XML方式的优点是不会存在因为平台不同而产生差异,也不会出现如Binary二进制序列化方式中产生的大端小端问题。XML方式的缺点则是序列化和反序列化的性能不如二进制方式。在序列化后产生的文件相比与二进制方式,同样的信息所产生的文件更大。
(5)CSV方式的序列化
CSV方式和XML方式很像,只是所采用的转化格式不同,CSV格式采用逗号将文本进行分割。
在Jute框架中实现CSV序列化的类是CsvOutputArchive,在Jute框架采用CSV方式实现序列化时,便会采用该类作为具体实现类。
这里以调用Record接口中的writeString()方法为例,writeString()方法会将Java对象的String字符类型进行CSV序列化。
当调用CsvOutputArchive的writeString()方法时,首先会调用printCommaUnlessFirst()方法生成一个逗号分隔符,然后将需要序列化的字符串值转换成CSV编码格式追加到字节数组中。
public class CsvOutputArchive implements OutputArchive {private PrintStream stream;private boolean isFirst = true;...public void writeString(String s, String tag) throws IOException {printCommaUnlessFirst();stream.print(Utils.toCSVString(s));throwExceptionOnError(tag);}private void printCommaUnlessFirst() {if (!isFirst) {stream.print(",");}isFirst = false;}...
}(6)总结
一.三种方式比较
Binary方式最为简单、性能也最好,但有大端小端问题。XML方式作为可扩展的标记语言跨平台性更强,占用空间大。CSV方式介于两者之间实现起来也相比XML格式更加简单。
之所以需要深入了解Jute的底层实现原理,是为了在开发中更好使用zk。在发生诸如客户端与服务端通信中信息发送不完整或解析错误等情况时,能通过底层序列化模块入手排查信息错误,进一步提高日常设计和解决问题的能力。
二.zk默认的序列化实现方式
zk默认的序列化实现方式是Binary二进制方式,这是因为二进制具有更好的性能。
3.ZooKeeper的网络通信协议详解
(1)ZooKeeper协议简述
(2)ZooKeeper通信协议的底层实现之请求协议
(3)ZooKeeper协议的底层实现之响应协议
(4)总结
(1)ZooKeeper协议简述
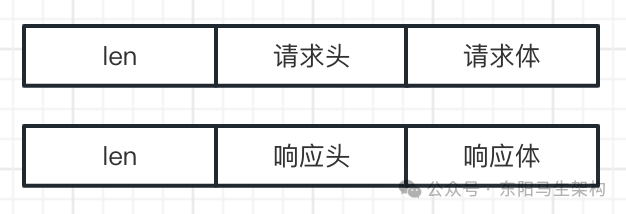
zk基于TCP/IP协议,实现了自己的通信协议来完成网络通信。zk通信协议整体上的设计非常简单。
一次客户端的请求,主要由请求头和请求体组成。
一次服务端的响应,主要由响应头和响应体组成。
(2)ZooKeeper通信协议的底层实现之请求协议
一.请求头RequestHeader
二.请求体Request
实现一:会话创建请求ConnectRequest
实现二:节点数据查询请求GetDataRequest
实现三:节点数据更新请求SetDataRequest
请求协议就是客户端向服务端发送请求的协议,比如常用的会话创建、数据节点查询等操作,都会使用请求协议来完成客户端与服务端的网络通信。
一.请求头RequestHeader
在zk中请求头是通过RequestHeader类实现的,RequestHeader类实现了Record接口,用于网络传输时进行序列化操作。可以看到RequestHeader类中只有两个属性字段,分别是xid和type。其中xid字段表示客户端序号用于记录客户端请求的发起顺序,type字段表示请求操作的类型。
class RequestHeader implements Record {private int xid;//客户端序号用于记录客户端请求的发起顺序private int type;//请求操作的类型...public void serialize(OutputArchive a_, String tag) throws java.io.IOException {a_.startRecord(this,tag);a_.writeInt(xid,"xid");a_.writeInt(type,"type");a_.endRecord(this,tag);}public void deserialize(InputArchive a_, String tag) throws java.io.IOException {a_.startRecord(tag);xid=a_.readInt("xid");type=a_.readInt("type");a_.endRecord(tag);}...
}二.请求体Request
请求协议的请求体部分是指请求的主体内容部分,包含了请求的所有内容。不同的请求类型,其请求体部分的结构是不同的。接下来介绍会话创建、数据节点查询、数据节点更新的三种请求体实现。
实现一:会话创建请求ConnectRequest
zk客户端发起会话时,会向服务端发送一个会话创建请求。该请求的作用就是通知zk服务端需要处理一个来自客户端的访问连接。服务端处理会话创建请求时所需要的所有信息都包括在请求体内。
会话创建请求的请求体是通过ConnectRequest类实现的。ConnectRequest类实现了Record接口,用于网络传输时进行序列化操作。可以看到,ConnectRequest类一共有五种属性字段,分别是:protocolVersion表示该请求协议的版本信息,lastZxidSeen表示最后一次接收到的服务器的zxid序号,timeOut表示会话的超时时间,sessionId表示会话标识符,password表示会话密码。zk服务端在接收一个请求时,就会根据请求体的这些信息进行相关操作。
public class ConnectRequest implements Record { private int protocolVersion;//表示该请求协议的版本信息private long lastZxidSeen;//表示最后一次接收到的服务器的zxid序号private int timeOut;//表示会话的超时时间private long sessionId;//表示会话标识符private byte[] passwd;//表示会话的密码...public void serialize(OutputArchive a_, String tag) throws java.io.IOException {a_.startRecord(this,tag);a_.writeInt(protocolVersion,"protocolVersion");a_.writeLong(lastZxidSeen,"lastZxidSeen");a_.writeInt(timeOut,"timeOut");a_.writeLong(sessionId,"sessionId");a_.writeBuffer(passwd,"passwd");a_.endRecord(this,tag);}public void deserialize(InputArchive a_, String tag) throws java.io.IOException {a_.startRecord(tag);protocolVersion=a_.readInt("protocolVersion");lastZxidSeen=a_.readLong("lastZxidSeen");timeOut=a_.readInt("timeOut");sessionId=a_.readLong("sessionId");passwd=a_.readBuffer("passwd");a_.endRecord(tag);}
}实现二:节点数据查询请求GetDataRequest
当zk客户端向服务端发送一个节点数据查询请求时,节点数据查询请求的请求体是通过GetDataRequest类实现的。GetDataRequest类实现了Record接口,用于网络传输时进行序列化操作。可以看到,GetDataRequest类具有两个属性字段,分别是:path表示要请求的数据节点路径,watch表示该节点是否注册Watcher事件。
public class GetDataRequest implements Record { private String path;//表示要请求的数据节点路径private boolean watch;//表示该节点是否注册Watcher事件...public void serialize(OutputArchive a_, String tag) throws java.io.IOException {a_.startRecord(this,tag);a_.writeString(path,"path");a_.writeBool(watch,"watch");a_.endRecord(this,tag);}public void deserialize(InputArchive a_, String tag) throws java.io.IOException {a_.startRecord(tag);path=a_.readString("path");watch=a_.readBool("watch");a_.endRecord(tag);}...
}实现三:节点数据更新请求SetDataRequest
当zk客户端向服务端发送一个节点数据更新请求时,节点数据更新请求的请求体是通过SetDataRequest类实现的。SetDataRequest类实现了Record接口,用于网络传输时进行序列化操作。可以看到,SetDataRequest类具有三个属性,分别是:path表示节点的路径,data表示节点数据信息,version表示节点数据的期望版本号,用于乐观锁的验证。
public class SetDataRequest implements Record {private String path;//表示节点的路径private byte[] data;//表示节点数据信息private int version;//表示节点数据的期望版本号,用于乐观锁的验证...public void serialize(OutputArchive a_, String tag) throws java.io.IOException {a_.startRecord(this,tag);a_.writeString(path,"path");a_.writeBuffer(data,"data");a_.writeInt(version,"version");a_.endRecord(this,tag);}public void deserialize(InputArchive a_, String tag) throws java.io.IOException {a_.startRecord(tag);path=a_.readString("path");data=a_.readBuffer("data");version=a_.readInt("version");a_.endRecord(tag);}...
}(3)ZooKeeper协议的底层实现之响应协议
一.响应头ReplyHeader
二.响应体Response
实现一:会话创建响应ConnectResponse
实现二:节点数据查询响应GetDataResponse
实现三:节点数据更新响应SetDataResponse
响应可理解为服务端在处理完客户端的请求后,返回相关信息给客户端。服务端采用的响应协议类型需要根据客户端的请求协议类型来选择。在zk服务端向客户端返回的响应中,包括了响应头和响应体,所以响应协议包含了响应头和响应体两部分。
一.响应头ReplyHeader
与客户端的请求头不同的是,服务端的响应头多了一个错误状态字段,服务端的响应头的具体实现类是ReplyHeader。
public class ReplyHeader implements Record {private int xid;private long zxid;private int err;...public void serialize(OutputArchive a_, String tag) throws java.io.IOException {a_.startRecord(this,tag);a_.writeInt(xid,"xid");a_.writeLong(zxid,"zxid");a_.writeInt(err,"err");a_.endRecord(this,tag);}public void deserialize(InputArchive a_, String tag) throws java.io.IOException {a_.startRecord(tag);xid=a_.readInt("xid");zxid=a_.readLong("zxid");err=a_.readInt("err");a_.endRecord(tag);}...
}二.响应体Response
响应协议的响应体部分是指响应的主体内容部分,包含了响应的所有数据。不同的响应类型,其响应体部分的结构是不同的。接下来介绍会话创建、数据节点查询、数据节点更新的三种响应体实现。
实现一:会话创建响应ConnectResponse
针对客户端的会话创建请求,服务端会返回一个会话创建响应。会话创建响应的响应体是通过ConnectRespose类来实现的。ConnectRespose类实现了Record接口,用于网络传输时进行序列化操作。可以看到,ConnectRespose类具有四个属性,分别是:protocolVersion表示请求协议的版本信息,timeOut表示会话超时时间,sessionId表示会话标识符,passwd表示会话密码。
public class ConnectResponse implements Record {private int protocolVersion;//请求协议的版本信息private int timeOut;//会话超时时间private long sessionId;//会话标识符private byte[] passwd;//会话密码...public void serialize(OutputArchive a_, String tag) throws java.io.IOException {a_.startRecord(this,tag);a_.writeInt(protocolVersion,"protocolVersion");a_.writeInt(timeOut,"timeOut");a_.writeLong(sessionId,"sessionId");a_.writeBuffer(passwd,"passwd");a_.endRecord(this,tag);}public void deserialize(InputArchive a_, String tag) throws java.io.IOException {a_.startRecord(tag);protocolVersion=a_.readInt("protocolVersion");timeOut=a_.readInt("timeOut");sessionId=a_.readLong("sessionId");passwd=a_.readBuffer("passwd");a_.endRecord(tag);}...
}实现二:节点数据查询响应GetDataResponse
针对客户端的节点数据查询请求,服务端会返回一个节点数据查询响应。节点数据查询响应的响应体是通过GetDataResponse类来实现的。GetDataResponse类实现了Record接口,用于网络传输时进行序列化操作。可以看到,GetDataResponse类具有两个属性,分别是:data表示节点数据的内容,stat表示节点的状态信息。
public class GetDataResponse implements Record { private byte[] data;//节点数据的内容private org.apache.zookeeper.data.Stat stat;//表示节点的状态信息...public void serialize(OutputArchive a_, String tag) throws java.io.IOException {a_.startRecord(this,tag);a_.writeBuffer(data,"data");a_.writeRecord(stat,"stat");a_.endRecord(this,tag);}public void deserialize(InputArchive a_, String tag) throws java.io.IOException {a_.startRecord(tag);data=a_.readBuffer("data");stat= new org.apache.zookeeper.data.Stat();a_.readRecord(stat,"stat");a_.endRecord(tag);}...
}实现三:节点数据更新响应SetDataResponse
针对客户端的节点数据更新请求,服务端会返回一个节点数据更新响应。节点数据更新响应的响应体是通过SetDataResponse类来实现的。SetDataResponse类实现了Record接口,用于网络传输时进行序列化操作。可以看到,SetDataResponse类只有一个属性:stat表示该节点数据更新后的最新状态信息。
public class SetDataResponse implements Record {private org.apache.zookeeper.data.Stat stat;//表示该节点数据更新后的最新状态信息...public void serialize(OutputArchive a_, String tag) throws java.io.IOException {a_.startRecord(this,tag);a_.writeRecord(stat,"stat");a_.endRecord(this,tag);}public void deserialize(InputArchive a_, String tag) throws java.io.IOException {a_.startRecord(tag);stat= new org.apache.zookeeper.data.Stat();a_.readRecord(stat,"stat");a_.endRecord(tag);}...
}(4)总结
zk中的网络通信协议是通过不同的类具体实现的。
ZooKeeper通信协议的底层实现之请求协议:
一.请求头RequestHeader
二.请求体Request
实现一:会话创建请求ConnectRequest
实现二:节点数据查询请求GetDataRequest
实现三:节点数据更新请求SetDataRequest
ZooKeeper协议的底层实现之响应协议:
一.响应头ReplyHeader
二.响应体Response
实现一:会话创建响应ConnectResponse
实现二:节点数据查询响应GetDataResponse
实现三:节点数据更新响应SetDataResponse
问题:一个会话如果超时,服务器端就会主动关闭会话,zk可以在会话请求的请求体中设置会话超时时间。但为什么经常会遇到明明已通过客户端设置了指定的超时时间,而在实际执行时会话时的超时时间却远小于指定设置的时间?
这是因为zk服务端处理会话超时时间不仅使用客户端传来的超时时间,还会根据配置的minSessionTimeout和maxSessionTimeout来调整时间,这在日常开发设置中是需要注意的。
4.客户端的核心组件和初始化过程
(1)zk的客户端的核心组件
(2)客户端的初始化过程
(1)zk的客户端的核心组件
一.ZooKeeper
二.ZKWatchManager
三.HostProvider
四.ClientCnxn
一.ZooKeeper
public class ZooKeeper implements AutoCloseable {protected final ZKWatchManager watchManager;protected final HostProvider hostProvider;protected final ClientCnxn cnxn;...
}二.ZKWatchManager
public class ZooKeeper implements AutoCloseable {...static class ZKWatchManager implements ClientWatchManager {private final Map<String, Set<Watcher>> dataWatches = new HashMap<String, Set<Watcher>>();private final Map<String, Set<Watcher>> existWatches = new HashMap<String, Set<Watcher>>();private final Map<String, Set<Watcher>> childWatches = new HashMap<String, Set<Watcher>>();protected volatile Watcher defaultWatcher;...}...
}三.HostProvider
public interface HostProvider {public int size();public InetSocketAddress next(long spinDelay);public void onConnected();
}四.ClientCnxn
public class ClientCnxn {private final ZooKeeper zooKeeper;private final ClientWatchManager watcher;final SendThread sendThread;final EventThread eventThread;private final HostProvider hostProvider;...
}(2)客户端的初始化过程
一.设置默认Watcher实例
二.设置zk服务器地址列表
三.创建ClientCnxn实例
如果在zk的构造方法中传入一个Watcher对象,那么zk就会将该Watcher对象保存在ZKWatchManager的defaultWatcher,作为整个客户端会话期间的默认Watcher实例。
public class ZooKeeper implements AutoCloseable {protected final ZKWatchManager watchManager;protected final HostProvider hostProvider;protected final ClientCnxn cnxn;...public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, long sessionId, byte[] sessionPasswd, boolean canBeReadOnly, HostProvider aHostProvider, ZKClientConfig clientConfig) throws IOException {...//1.设置默认Watcher watchManager = defaultWatchManager();watchManager.defaultWatcher = watcher;...//2.设置zk服务器地址列表hostProvider = aHostProvider;//3.创建ClientCnxncnxn = new ClientCnxn(connectStringParser.getChrootPath(), hostProvider, sessionTimeout, this, watchManager, getClientCnxnSocket(), sessionId, sessionPasswd, canBeReadOnly);...}...
}5.客户端核心组件HostProvider
(1)HostProvider的创建
(2)HostProvider的next()方法
(1)HostProvider的创建
在使用zk的构造方法时会传入zk服务器地址列表,即connectString参数。zk客户端内部接收到这个服务器地址列表后,会首先将该列表放入ConnectStringParser解析器中封装起来。ConnectStringParser解析器会对传入的connectString进行如下处理:
一.解析chrootPath
通过设置chrootPath,可以让客户端应用与zk服务端的一棵子树相对应。在多个应用共用一个zk集群的场景下,可以实现不同应用间的相互隔离。
二.保存服务器地址列表
在ConnectStringParser解析器中会对服务器地址进行如下处理:先将服务器地址和相应的端口封装成一个InetSocketAddress对象,然后以ArrayList的形式保存在ConnectStringParser的serverAddresses属性中。
经过ConnectStringParser解析器对connectString解析后,便获取处理好的服务器地址列表,然后封装到StaticHostProvider中。
public class ZooKeeper implements AutoCloseable {...public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, long sessionId, byte[] sessionPasswd, boolean canBeReadOnly) throws IOException {this(connectString, sessionTimeout, watcher, sessionId, sessionPasswd, canBeReadOnly, createDefaultHostProvider(connectString));}private static HostProvider createDefaultHostProvider(String connectString) {//将经过处理的服务器地址列表封装到StaticHostProvider中return new StaticHostProvider(new ConnectStringParser(connectString).getServerAddresses());}...
}public final class ConnectStringParser {private static final int DEFAULT_PORT = 2181;private final String chrootPath;private final ArrayList<InetSocketAddress> serverAddresses = new ArrayList<InetSocketAddress>();public ConnectStringParser(String connectString) {int off = connectString.indexOf('/');//解析chrootPathif (off >= 0) {String chrootPath = connectString.substring(off);if (chrootPath.length() == 1) {this.chrootPath = null;} else {PathUtils.validatePath(chrootPath);this.chrootPath = chrootPath;}connectString = connectString.substring(0, off);} else {this.chrootPath = null;}//2.保存服务器地址列表List<String> hostsList = split(connectString,",");for (String host : hostsList) {int port = DEFAULT_PORT;String[] hostAndPort = NetUtils.getIPV6HostAndPort(host);if (hostAndPort.length != 0) {host = hostAndPort[0];if (hostAndPort.length == 2) {port = Integer.parseInt(hostAndPort[1]);}} else {int pidx = host.lastIndexOf(':');if (pidx >= 0) {if (pidx < host.length() - 1) {port = Integer.parseInt(host.substring(pidx + 1));}host = host.substring(0, pidx);}}serverAddresses.add(InetSocketAddress.createUnresolved(host, port));}}public String getChrootPath() {return chrootPath;}public ArrayList<InetSocketAddress> getServerAddresses() {return serverAddresses;}
}(2)HostProvider的next()方法
一.StaticHostProvider的next()方法需要返回已解析的地址
需要注意的是:在ConnectStringParser的serverAddresses属性中保存的服务器地址列表,都是还没有被解析的InetSocketAddress。
所以HostProvider的方法就会负责对InetSocketAddress列表进行解析,然后HostProvider的next()方法返回的必须是已被解析的InetSocketAddress。
public interface HostProvider {public int size();public InetSocketAddress next(long spinDelay);public void onConnected();
}二.StaticHostProvider解析服务器地址时会随机打散列表
针对ConnectStringParser.serverAddresses中没有被解析的服务器地址,StaticHostProvider会对这些地址逐个解析然后放入其serverAddresses中,同时会使用Collections.shuffle()方法来随机打散服务器地址列表。
调用StaticHostProvider的next()方法时,会从其serverAddresses中获取一个可用的地址。这个next()方法会先将随机打散后的地址列表拼装成一个环形循环队列。然后在之后的使用过程中,一直按拼装的顺序来获取服务器地址。这个随机打散的过程是一次性的。
public final class StaticHostProvider implements HostProvider {private List<InetSocketAddress> serverAddresses = new ArrayList<InetSocketAddress>(5);private int lastIndex = -1;private int currentIndex = -1;...public StaticHostProvider(Collection<InetSocketAddress> serverAddresses) {init(serverAddresses, System.currentTimeMillis() ^ this.hashCode(),new Resolver() {@Overridepublic InetAddress[] getAllByName(String name) throws UnknownHostException {return InetAddress.getAllByName(name);}});}private void init(Collection<InetSocketAddress> serverAddresses, long randomnessSeed, Resolver resolver) {...//随机打散传入的服务器地址列表this.serverAddresses = shuffle(serverAddresses);currentIndex = -1;lastIndex = -1;}private List<InetSocketAddress> shuffle(Collection<InetSocketAddress> serverAddresses) {List<InetSocketAddress> tmpList = new ArrayList<>(serverAddresses.size());tmpList.addAll(serverAddresses);Collections.shuffle(tmpList, sourceOfRandomness);return tmpList;}...
}三.StaticHostProvider中的环形循环队列实现
StaticHostProvider会为循环队列创建两个游标:currentIndex和lastIndex。currentIndex表示循环队列中当前遍历到的那个元素位置,初始值为-1。lastIndex表示当前正在使用的服务器地址位置,初始值为-1。每次执行next()方法时,都会先将currentIndex游标向前移动1位。如果发现游标移动超过了整个地址列表的长度,那么就重置为0。
对于服务器地址列表提供得比较少的场景:如果发现当前游标的位置和上次已经使用过的地址位置一样,也就是currentIndex和lastIndex游标值相同时,就进行spinDelay毫秒等待。
public final class StaticHostProvider implements HostProvider {private List<InetSocketAddress> serverAddresses = new ArrayList<InetSocketAddress>(5);private int lastIndex = -1;private int currentIndex = -1;...public InetSocketAddress next(long spinDelay) {boolean needToSleep = false;InetSocketAddress addr;synchronized(this) {... ++currentIndex;if (currentIndex == serverAddresses.size()) {currentIndex = 0;} addr = serverAddresses.get(currentIndex);needToSleep = needToSleep || (currentIndex == lastIndex && spinDelay > 0);if (lastIndex == -1) { // We don't want to sleep on the first ever connect attempt.lastIndex = 0;}}if (needToSleep) {try {Thread.sleep(spinDelay);} catch (InterruptedException e) {LOG.warn("Unexpected exception", e);}}return resolve(addr);}public synchronized void onConnected() {lastIndex = currentIndex;reconfigMode = false;}...
}