系列文章目录
第六章 1:基于RNN生成文本
第六章 2:seq2seq模型的实现
第六章 3:seq2seq模型的改进
第六章 4:seq2seq模型的应用
目录
系列文章目录
文章目录
前言
一、反转输入数据(Reverse)
编辑
二、偷窥(Peeky)
总结
前言
本节我们对上一节的seq2seq进行改进,以改进学习的进展。为了达成 该目标,可以使用一些比较有前景的技术。本节我们展示其中的两个方案, 并基于实验确认它们的效果。
一、反转输入数据(Reverse)
第一个改进方案是非常简单的技巧。如下图所示,反转输入数据的顺序。
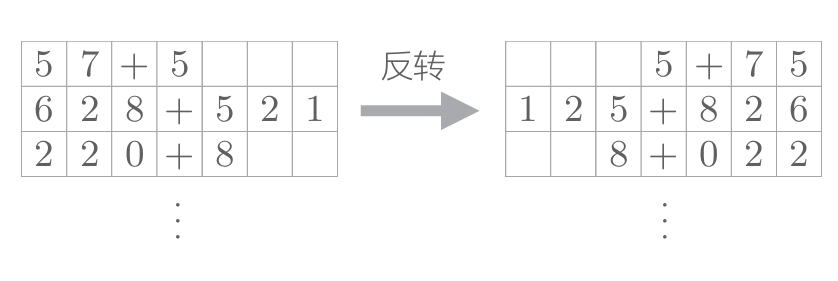
这个反转输入数据的技巧据研究,在许多情况下,使用这个技巧后,学习进展得更快,最终的精度也有提高。现在我们来做一下实验。 为了反转输入数据,在上一节的学习用代码的基础上(自然语言处理(22:(第六章2.)seq2seq模型的实现)-CSDN博客),在读入数据集之后,我们追加下面的代码。
is_reverse = True # True
if is_reverse:x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]如上所示,可以使用x_train[:, ::-1]反转数组的排列。那么,通过反转输入数据,正确率可以上升多少呢?先看修改后的整体代码:
# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from dataset import sequence
from common.optimizer import Adam
from common.trainer import Trainer
from common.util import eval_seq2seq
from seq2seq import Seq2seq
from peeky_seq2seq import PeekySeq2seq# 读入数据集
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
char_to_id, id_to_char = sequence.get_vocab()# Reverse input? =================================================
is_reverse = True # True
if is_reverse:x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
# ================================================================# 设定超参数
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 128
batch_size = 128
max_epoch = 25
max_grad = 5.0# Normal or Peeky? ==============================================
model = Seq2seq(vocab_size, wordvec_size, hidden_size)# ================================================================
optimizer = Adam()
trainer = Trainer(model, optimizer)acc_list = []
for epoch in range(max_epoch):trainer.fit(x_train, t_train, max_epoch=1,batch_size=batch_size, max_grad=max_grad)correct_num = 0for i in range(len(x_test)):question, correct = x_test[[i]], t_test[[i]]verbose = i < 10correct_num += eval_seq2seq(model, question, correct,id_to_char, verbose, is_reverse)acc = float(correct_num) / len(x_test)acc_list.append(acc)print('val acc %.3f%%' % (acc * 100))# 绘制图形
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.ylim(0, 1.0)
plt.show()结果如下图所示。
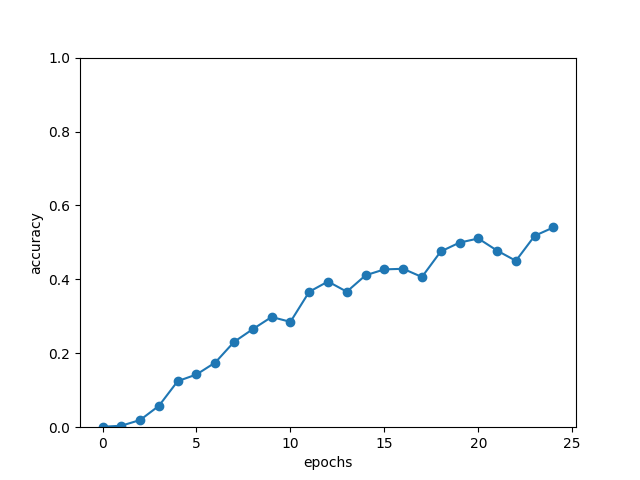
从上图中可知,仅仅通过反转输入数据,学习的进展就得到了改善! 在25个epoch时,正确率为54%左右。再次重复一遍,这里和上一次(图中的baseline)的差异只是将数据反转了一下。仅仅这样,就产生了这么大的差异,真是令人吃惊。当然,虽然反转数据的效果因任务而异,但是通常 都会有好的结果。 为什么反转数据后,学习进展变快,精度提高了呢?虽然理论上不是很清楚,但是直观上可以认为,反转数据后梯度的传播可以更平滑。比如,考虑将“吾輩 は 猫 で ある”翻译成“I am a cat”这一问题,单词“吾輩”和单词“I”之间有转换关系。此时,从“吾輩”到“I”的路程必须经 过“は”“猫”“で”“ある”这4个单词的LSTM层。因此,在反向传播时, 梯度从“I”抵达“吾輩”,也要受到这个距离的影响。
那么,如果反转输入语句,也就是变为“ある で 猫 は 吾輩”,结果会怎样呢?此时,“吾輩”和“I”彼此相邻,梯度可以直接传递。如此,因为通过反转,输入语句的开始部分和对应的转换后的单词之间的距离变近 (这样的情况变多),所以梯度的传播变得更容易,学习效率也更高。不过, 在反转输入数据后,单词之间的“平均”距离并不会发生改变。
二、偷窥(Peeky)
接下来是seq2seq的第二个改进。在进入正题之前,我们再看一下编码器的作用。如前所述,编码器将输入语句转换为固定长度的向量h,这个h集中了解码器所需的全部信息。也就是说,它是解码器唯一的信息源。但是,如下图所示,当前的seq2seq只有最开始时刻的LSTM层利用了h。 我们能更加充分地利用这个h吗?
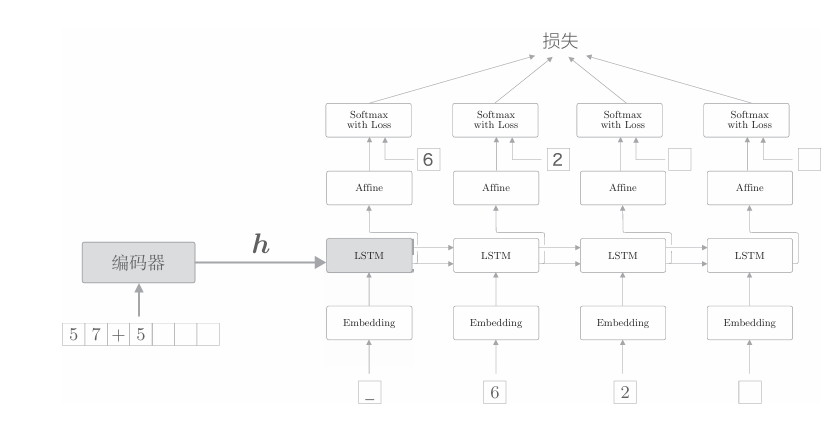
为了达成该目标,seq2seq的第二个改进方案就应运而生了。具体来说, 就是将这个集中了重要信息的编码器的输出h分配给解码器的其他层。我 们的解码器可以考虑下图中的网络结构。
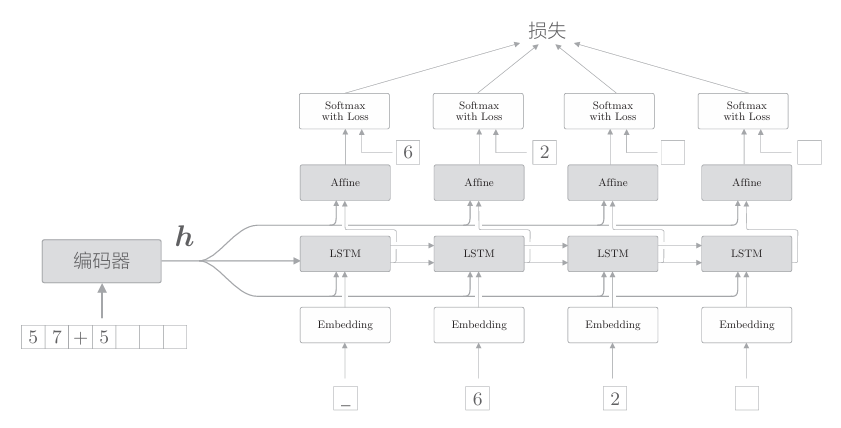
如上图所示,将编码器的输出h分配给所有时刻的Affine层和 LSTM层。比较上面两幅图可知,之前LSTM层专用的重要信息h现在在多个层(在这个例子中有8个层)中共享了。重要的信息不是一个人专有,而是多人共享,这样我们或许可以做出更加正确的判断。
在上图中,有两个向量同时被输入到了LSTM层和Affine层,这实际上表示两个向量的拼接(concatenate)。因此,在刚才的图中,如果使用 concat 节点拼接两个向量,则正确的计算图可以绘制成下图:
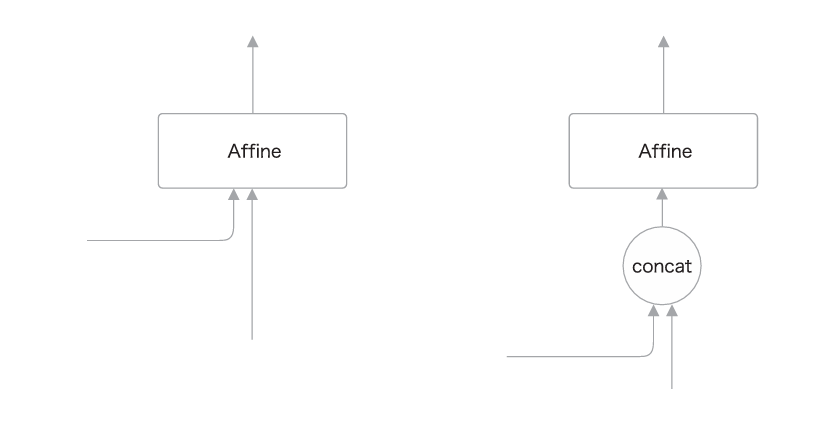
下面给出PeekyDecoder 类的实现。这里仅显示初始化__init__()方法和 正向传播forward()方法。因为没有特别难的地方,所以这里省略了反向传播 backward() 方法和文本生成generate() 方法
import sys
sys.path.append('..')
from common.time_layers import *
from seq2seq import Seq2seq, Encoderclass PeekyDecoder:def __init__(self, vocab_size, wordvec_size, hidden_size):V, D, H = vocab_size, wordvec_size, hidden_sizern = np.random.randnembed_W = (rn(V, D) / 100).astype('f')lstm_Wx = (rn(H + D, 4 * H) / np.sqrt(H + D)).astype('f')lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')lstm_b = np.zeros(4 * H).astype('f')affine_W = (rn(H + H, V) / np.sqrt(H + H)).astype('f')affine_b = np.zeros(V).astype('f')self.embed = TimeEmbedding(embed_W)self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)self.affine = TimeAffine(affine_W, affine_b)self.params, self.grads = [], []for layer in (self.embed, self.lstm, self.affine):self.params += layer.paramsself.grads += layer.gradsself.cache = Nonedef forward(self, xs, h):N, T = xs.shapeN, H = h.shapeself.lstm.set_state(h)out = self.embed.forward(xs)hs = np.repeat(h, T, axis=0).reshape(N, T, H)out = np.concatenate((hs, out), axis=2)out = self.lstm.forward(out)out = np.concatenate((hs, out), axis=2)score = self.affine.forward(out)self.cache = Hreturn scorePeekyDecoder 的初始化和上一节的Decoder基本上是一样的,不同之处 仅在于LSTM层权重和Affine层权重的形状。因为这次的实现要接收编码 器编码好的向量,所以权重参数的形状相应地变大了。 接着是forward() 的实现。这里首先使用np.repeat()根据时序大小复 制相应份数的h,并将其设置为hs。然后,将hs和Embedding层的输出用 np.concatenate() 拼接,并输入LSTM层。同样地,Affine层的输入也是hs 和LSTM层的输出的拼接。
最后,我们来实现PeekySeq2seq,不过这和上一节的Seq2seq类基本相 同,唯一的区别是Decoder层。上一节的Seq2seq类使用了Decoder类,与 此相对,这里使用PeekyDecoder,剩余的逻辑完全一样。因此,PeekySeq2seq 类的实现只需要继承上一章的Seq2seq类,并修改一下初始化部分
class PeekySeq2seq(Seq2seq):def __init__(self, vocab_size, wordvec_size, hidden_size):V, D, H = vocab_size, wordvec_size, hidden_sizeself.encoder = Encoder(V, D, H)self.decoder = PeekyDecoder(V, D, H)self.softmax = TimeSoftmaxWithLoss()self.params = self.encoder.params + self.decoder.paramsself.grads = self.encoder.grads + self.decoder.grads
至此,准备工作就完成了。现在我们使用这个PeekySeq2seq类,再次 挑战加法问题。学习用代码仍使用上一节的代码,只需要将Seq2seq类换成 PeekySeq2seq 类。
# model = Seq2seq(vocab_size, wordvec_size, hidden_size)
model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size)这里,我们在第一个改进(反转输入)的基础上进行实验,结果如图
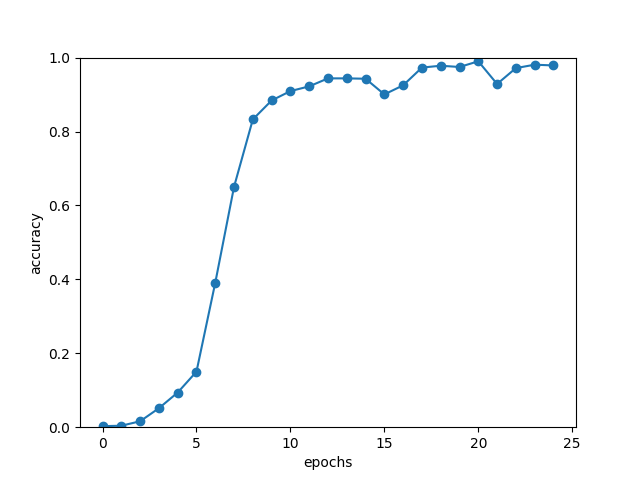
如上图所示,加上了Peeky的seq2seq的结果大幅变好。刚过10个 epoch 时,正确率已经超过97%,最终的正确率接近100%。 从上述实验结果可知,Reverse和Peeky都有很好的效果。借助反转输入语句的Reverse和共享编码器信息的Peeky,我们获得了令人满意的结果! 这样我们就结束了对seq2seq的改进,不过故事仍在继续。实际上,本节的改进只能说是“小改进”,下一次我们将对seq2seq进行“大改进”。届时将使用名为Attention的技术,它能使seq2seq发生巨大变化。 这里的实验有几个需要注意的地方。因为使用Peeky后,网络的权重参数会额外地增加,计算量也会增加,所以这里的实验结果必须考虑到相应地增加的“负担”。另外,seq2seq的精度会随着超参数的调整而大幅变化。 虽然这里的结果是可靠的,但是在实际问题中,它的效果可能还是不稳定。