目录
- 6.2 检索增强生成(RAG)架构
- 6.2.1 RAG 架构分类
- 6.2.2 黑盒增强架构
- 1)无微调
- 2)检索器微调
- 6.2.3 白盒增强架构
- 1)仅微调语言模型
- 2)检索器和语言模型协同微调
- 6.2.4 对比与分析
6.2 检索增强生成(RAG)架构
检索增强生成(RAG)系统是一个集成了外部知识库、检索器、生成器等多个功能模块的软件系统。针对不同的业务场景和需求,可以设计不同的系统架构来 组合、协调这些模块,以优化RAG的性能。
.
6.2.1 RAG 架构分类
考虑到大语言模型的开源/闭源、微调成本等问题,RAG中的大语言模型可以是参数不可感知/调节的“黑盒”模型,也可以是参数可感知和微调的“白盒”模型。
从是否对大语言模型进行微调的角度出发,将RAG架构分类两大类:黑盒增强架构和白盒增强架构
图6.9: 检索增强架构分类图。
其中含蓝色雪花的模块表示其参数被冻结、带红色 火焰的部分表示微调时其参数被更新。
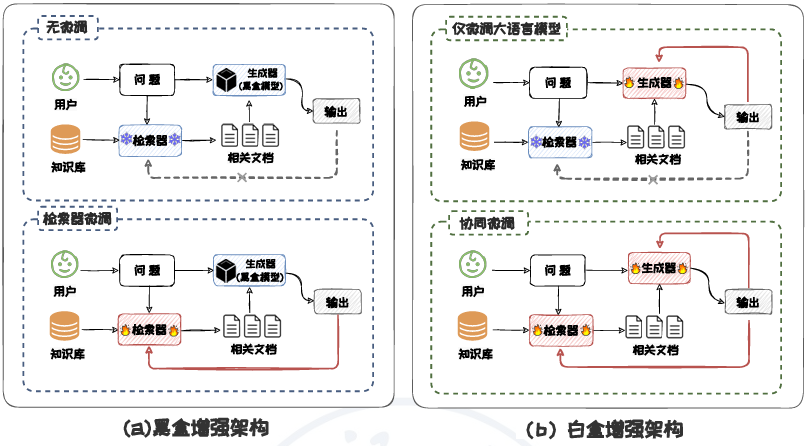
黑盒增强架构, 根据是否对检索器进行微调分为两类:
-
无微调、
-
检索器微调。
白盒增强架构,根据是否对检索器进行微调分为两类:
-
仅微调大语言模型、
-
检索器与大语言模型协同微调(下文简称为协同微调)。
在RAG系统中,除了调整检索器和大语言模型,我们也可对其他功能模块进行调整。调整其他功能模块与黑盒增强和白盒增强的分类是兼容的。
.
6.2.2 黑盒增强架构
某些情况下,无法获取大语言模型的结构和参数或者没有足够的算力对模型进行微调,此时,RAG 需要在黑盒增强架构的基础上构建。
在黑盒增强架构中,仅可对检索器进行策略调整与优化。其可以分为无微调架构和检索器微调两种架构。
.
1)无微调
无微调架构中,检索器和语言模型经过分别独立的预训练后参数不再更新,直接组合使用。
In-Context RALM 是该框架下的代表性方法。其直接将检索器检索到的文档前置到输入问题前作为上下文。
检索操作时,几个关键参数:
-
检索步长:模型在生成文本时,每隔多少个词进行一次检索。直接影响到模型的响应速度和信息的即时性。
-
检索查询长度:用于检索的文本片段的长度,常被设为语言模型输入中的最后几个词,以确保检索到的信息与当前的文本生成任务高度相关。
.
2)检索器微调
在检索器微调架构中,大语言模型的参数保持不变,仅用其输出指导检索器的微调。
REPLUG LSR 是检索器微调框架的代表性方法,它使用大语言模型的困惑度分数作为监督信号来微调检索器,使其能更有效地检索出能够显著降低语言模型困惑度的文档。
此过程涉及两个关键的概率分布:
-
检索器输出的文档分布:检索器在接收到当前上下文后,检索与之相关的文档,并形成一个文档概率分布。
-
文档对语言模型的贡献分布:如果某个文档对语言模型生成准确预测特别关键,它会被赋予更高的概率权重。
REPLUG LSR 在微调过程中将语言模型视为黑盒,仅通过模型输出指导检索器训练,避免修改内部结构。同时采用异步索引更新策略,在一定的训练步骤之后才进行更新,降低索引更新频率以减少计算成本。
此外,检索器微调框架中还可以引入代理模型(如小型语言模型)来增强检索器的微调效果,从而在不微调目标语言模型的情况下提升其在不同任务上的表现。
例如,AAR 方法通入引入额外小型语言模型,使用它的交叉注意力得分标注偏好文档,以此来微调检索器,使其能够在不微调目标语言模型的情况下增强其在不同任务上的表现。
.
6.2.3 白盒增强架构
通常,大语言模型和检索器是独立预训练的,二者可能存在匹配欠佳的情况。白盒增强架构通过微调大语言模型来配合检索器,以提升 RAG 的效果。
白盒增强架构可根据是否对检索器进行微调分为两类:仅语言模型微调、检索器和语言模型协同微调。
.
1)仅微调语言模型
仅微调语言模型:
-
指的是检索器作为一个预先训练好的组件其参数保持不变,
-
大语言模型根据检索器提供的上下文信息,对自身参数进行微调。
RETRO 是仅微调语言模型的代表性方法之:
- 该方法通过修改语言模型的结构,使其在微调过程中能够将从知识库中检索到的文本直接融入到语言模型中间状态中,从而实现外部知识对大语言模型的增强。
SELF-RAG:
- 通过在微调语言模型时引入反思标记,使语言模型在生成过程中动态决定是否需要检索外部文本,并对生成结果进行自我批判和优化。
图 6.12: RETRO 模型架构图

以 RETRO 为例,其结构如图:
-
RETRO 将知识库切块并用 BERT 生成嵌入向量。
-
在微调模型时的自回归过程中,模型生成一段文本块后,就去知识库中检索出与之最相似的嵌入向量。
-
然后,这些嵌入向量和模型注意力层的输出一起被送入一个外部的 Transformer 编码器进行编码。
-
得到的编码向量直接输入给模型的块交叉编码器的键(key)和值(value),以捕捉外部知识的关键信息。
-
通过交叉编码,模型能够结合检索到的相关信息来生成新的文本块。
.
2)检索器和语言模型协同微调
在检索器和语言模型协同微调的架构中,检索器和语言模型的参数更新同步进行。
这种微调的方式使得检索器能够在检索的同时,学习如何更有效地支持语言模型的需求,而语言模型则可以更好地适应并利用检索到的信息,以进一步提升 RAG 的性能。
图 6.13: Atlas 模型架构图
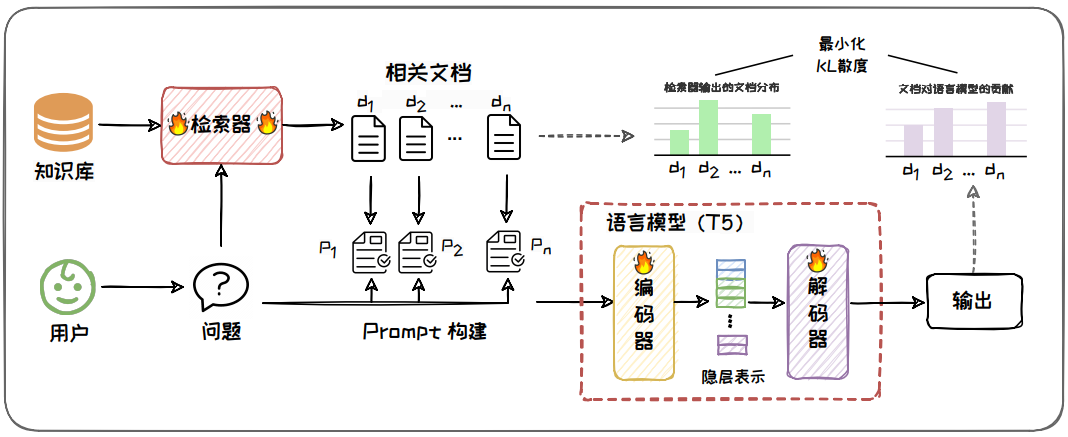
Atlas 是检索器和语言模型协同微调的架构的代表性工作,其架构如图所示。
-
与 REPLUG LSR 类似,其在预训练和微调阶段使用 KL 散度损失函数,来联合训练检索器和语言模型, 以确保检索器输出的文档相关性分布与文档对语言模型的贡献分布相一致。
-
不同之处在于,Atlas 在预训练和微调过程中,检索器和语言模型参数同步被更新,检索器学习向语言模型提供最相关的文档,而语言模型则学习如何利用这些文档来 改善其对查询的响应。
为确保检索结果与模型最新状态保持同步,Atlas 同样需要定期更新语料库文档的向量编码,从而维持检索的准确性。
.
6.2.4 对比与分析
黑盒增强架构:闭源模型的背景下提出,限制了对模型内部参数的直接调整。两种策略如下:
-
无微调:简单实用,直接利用预训练的语言模型和检索器,不进行任何更新,适合快速部署。缺点在于无法对语言模型进行优化以适应新的任务需求。
-
检索器微调:调整检索器来适应语言模型输出,无法修改语言模型的情况下,有了提升性能的可能性。这种方法的效果在很大程度上取决于调整后的检索器的准确性。
白盒增强架构:利用开源模型优势,允许调整语言模型结构和参数,可更好协调检索器和大语言模型。两种微调形式:
-
仅微调语言模型:根据检索到的信息仅调整语言模型结构和参数,以提升特定任务上的性能。
-
检索器和语言模型协同微调:同步更新检索器和语言模型,使得两者能够在训练过程中相互适应,从而提高整体系统的性能。
尽管白盒增强架构可以有效改善 RAG 的性能,但也存在明显缺点。这种架构通常需要大量计算资源和时间来训练,特别是协同微调策略,需要大量的运算资源来实现语言模型和检索器的同步更新。
.
其他参考:【大模型基础_毛玉仁】系列文章
声明:资源可能存在第三方来源,若有侵权请联系删除!