@TOC
目录
序列化和反序列化
概念:
应用场景:
种类:
protobuf
特点:
使用特点:
标量数据类型:
编译xxx.proto文件后会生成什么
字段的定义以及使用
基础版:
编辑
添加enum类型
定义规则
添加Any类型
添加oneof类型
作用:
特点:
使用场景
添加map类型
ProtoBuf生成的方法的规则总结
1.如果是protobuf的内置标量类型,那么生成常用方法如下:
2.如果是message自定义类型,那么生成常用方法如下:
3.如果是数组字段,那么会生成常用方法如下:
4. enum枚举字段,生成常用方法:
5. Any字段,生成常用方法:
6. oneof字段,常用方法:
7. map字段,常用方法:
默认值
更新消息
保留字段reserved
未知字段
选项option
常用选项举例
序列化和反序列化
概念:
- 序列化:把对象转换为字节序列的过程,称为对象的序列化
- 反序列化:把字节序列恢复为对象的过程,称为对象的反序列化
应用场景:
- 存储数据 :当你想把内存中的对象状态保存到一个文件中或者存到数据库中时。
- 网络传输 :网络直接传输数据,但是无法直接传输对象,所以要在传输前序列化,传输完成后反序列化成对象。例如:socket编程中发送和接收数据
种类:
- xml
- json
- protobuf
protobuf
特点:
- 语言无关,平台无关:支持Java,C++,python 等多种语言,支持多个平台
- 高效:比XML更小,更快,更简单
- 扩展性,兼容性好:可以更新数据结构,不影响和破坏原有的旧程序。
使用特点:
- 编写.proto文件,目的是为了定义结构对象及属性内容。
- 使用protoc编译器编译.proto文件,生成一系列接口代码,存放在新生成头文件和源文件中。
- 依赖生成的接口,将编译生成的头文件包含进我们的代码中,实现对.proto文件中定义的字段进行设置和获取,和对message对象进行序列化和反序列化
总的来说:ProtoBuf是需要依赖通过编译⽣成的头⽂件和源⽂件来使⽤的。
有一个模板:
syntax = "proto3"; //指定proto3语法
package contacts; //声明命名空间//定义消息(message)
message 消息类型名{// 定义消息字段// 字段名称命名规范:全小写,多个字母之间用_连接。// 字段类型分为: 标量数据类型 和 特殊类型(包括枚举等)// 字段唯一编号:用来标识字段,一旦开始使用就不能够再改变。
}消息类型类型命名规范:使用驼峰法,首字母大写标量数据类型:
| .proto Type | Notes | C++ Type |
| double | double | |
| float | float | |
| int32 | 使用变长编码,负数的编码效率较低——若字段为负值,应使用sin32代替。 | int32 |
| int64 | 使用变长编码,负数的编码效率较低——若字段为负值,应使用sin64代替。 | int64 |
| uint32 | 使用变长编码 | uint32 |
| uint64 | 使用变长编码 | uint64 |
| sin32 | 使用变长编码,符号整型,负值的编码效率高于常规的int32类型 | int32 |
| sin64 | 使用变长编码,符号整型,负值的编码效率高于常规的int64类型 | int64 |
| fixed32 | 定长4字节,若值常大于2^28 则会比uint32更高效 | uint32 |
| fixed4 | 定长8字节,若值常大于2^56 则会比uint64更高效 | uint64 |
| sfixed32 | 定长4字节 | int32 |
| sfixed64 | 定长8字节 | int64 |
| bool | bool | |
| string | 包含UTF-8和ASCII编码的字符串,长度不能超过2^32 | string |
| bytes | 可包含任意的字节序列但长度不能超过2^32 | string |
变⻓编码是指:经过protobuf编码后,原本4字节或8字节的数可能会被变为其他字节数.
在这⾥还要特别讲解⼀下字段唯⼀编号的范围: 1~536,870,911 (2^29-1),其中19000~19999不可⽤。
19000~19999不可⽤是因为:在Protobuf协议的实现中,对这些数进⾏了预留。如果⾮要在.proto ⽂件中使⽤这些预留标识号,例如将name字段的编号设置为19000,编译时就会报警:
syntax = "proto3";package contacts;message contacts
{string name = 19000;
}
值得⼀提的是,范围为1~15的字段编号需要⼀个字节进⾏编码,16~2047内的数字需要两个字节 进⾏编码。编码后的字节不仅只包含了编号,还包含了字段类型。所以1~15要⽤来标记出现⾮常频 繁的字段,要为将来有可能添加的、频繁出现的字段预留⼀些出来。
编译命令行格式为:
protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.protoprotoc 是 Protocol Buffer 提供的命令⾏编译⼯具。
--proto_path 指定 被编译的.proto⽂件所在⽬录,可多次指定。可简写成 -I
IMPORT_PATH 。如不指定该参数,则在当前⽬录进⾏搜索。当某个.proto ⽂件 import 其他 .proto ⽂件时,或需要编译的 .proto ⽂件不在当前⽬录下,这时就要⽤-I来指定搜索 ⽬录。
--cpp_out= 指编译后的⽂件为 C++ ⽂件。
OUT_DIR 编译后⽣成⽂件的⽬标路径。
path/to/file.proto 要编译的.proto⽂件。编译xxx.proto文件后会生成什么
编译xxx.proto文件后,生成所选择语言的代码,我们选择的是C++,所以编译后生成了两个文件:xxx.pb.h和xxx.pb.cc。
对于编译生成的C++代码,包含了以下内容:
对于每个message,都会生成一个对应的消息类。
在消息类中,编译器为每个字段提供了获取和设置方法,以及其他能够操作字段的方法。
编译器会针对于每个.proto文件生成.h和.cc文件,分别用来存放类的声明和类的实现。
注意:
- 序列化的结果为二进制字段序列,而非文本格式
- 序列化的API函数均为const 成员函数,因为序列化不会改变类对象的内容,而是将序列化的结果保存到函数入参指定的地址中。
字段的定义以及使用
消息的字段可以用下面几种规则来修改:
- singular:消息中可以包含该字段零次或者一次。proto3语法中,字段默认使用该规则。
- repeated:消息中可以包含该字段任意多次(包含零次),其中重复值的顺序会被保存。可以理解为定义了一个数组。
基础版:
syntax = "proto3";package contact;message contact
{string name = 1;int age = 2;repeated string phone_number = 3;
}我们来看看生成的contact.pb.h
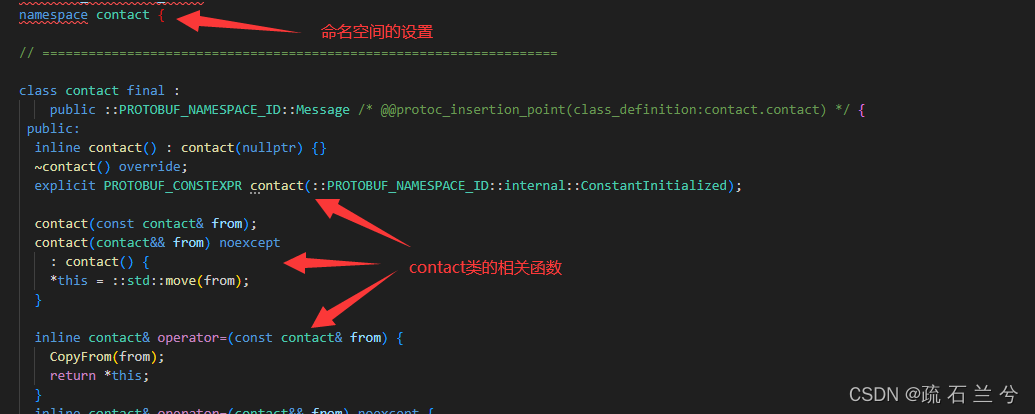
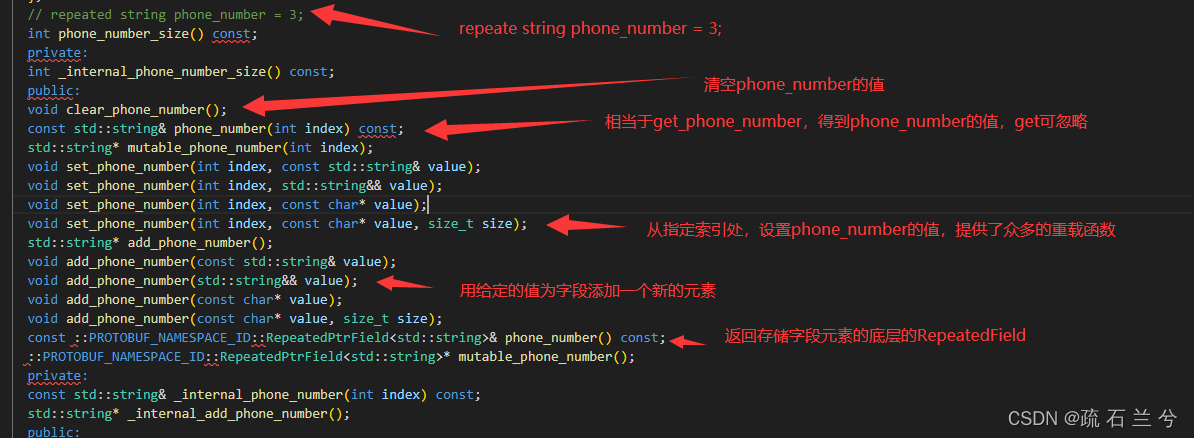
有几个函数还需要介绍以下:
std::string* mutable_name();作用:返回“name”字段的指针,允许直接修改该字段
用法:当你需要直接修改‘name’字段的内容的时候,使用这个函数
PROTOBUF_NODISCARD std::string* release_name();作用:释放‘name’字段的所有权,并返回指向该字符串的指针
用法:当你希望从‘name’字段中取出字符串的所有权,而不再由protobuf管理时,使用这个函数,
通常用于优化或特殊场景。
void set_allocated_name(std::string* name);
作用:设置‘name’字段的值,并接管传入的指针的所有权
用法:当你已经有一个指向‘std::string’的指针并希望将其直接交给‘Contact’对象来管理时,使用这个函数。这个函数避免字符串的复制,是和性能敏感的场景。
添加enum类型
定义规则
枚举类型名称:使用驼峰命名法,首字母大写。
常量值名称:全大写字母,多个字母之间用_连接。我们可以定义⼀个名为PhoneType的枚举类型,定义如下:
syntax = "proto3";package contact;message contact
{string name = 1;int age = 2;repeated string phone_number = 3;enum PhoneType{MP = 0; //移动电话TEL = 1; //固定电话}
}要注意枚举类型的定义有以下几种规则:
1. 0值常量必须存在,且要作为第一个元素。这是为了与proto2的语义兼容:第一个元素作为默认值,且值为0.
2. 枚举类型可以在消息外定义,也可以在消息体内定义(嵌套)。
3. 枚举的常量值在32位整数的范围内。但因负值无效因而不建议使用。
4. 同级的枚举类型,各个枚举类型中的常量不能重名。
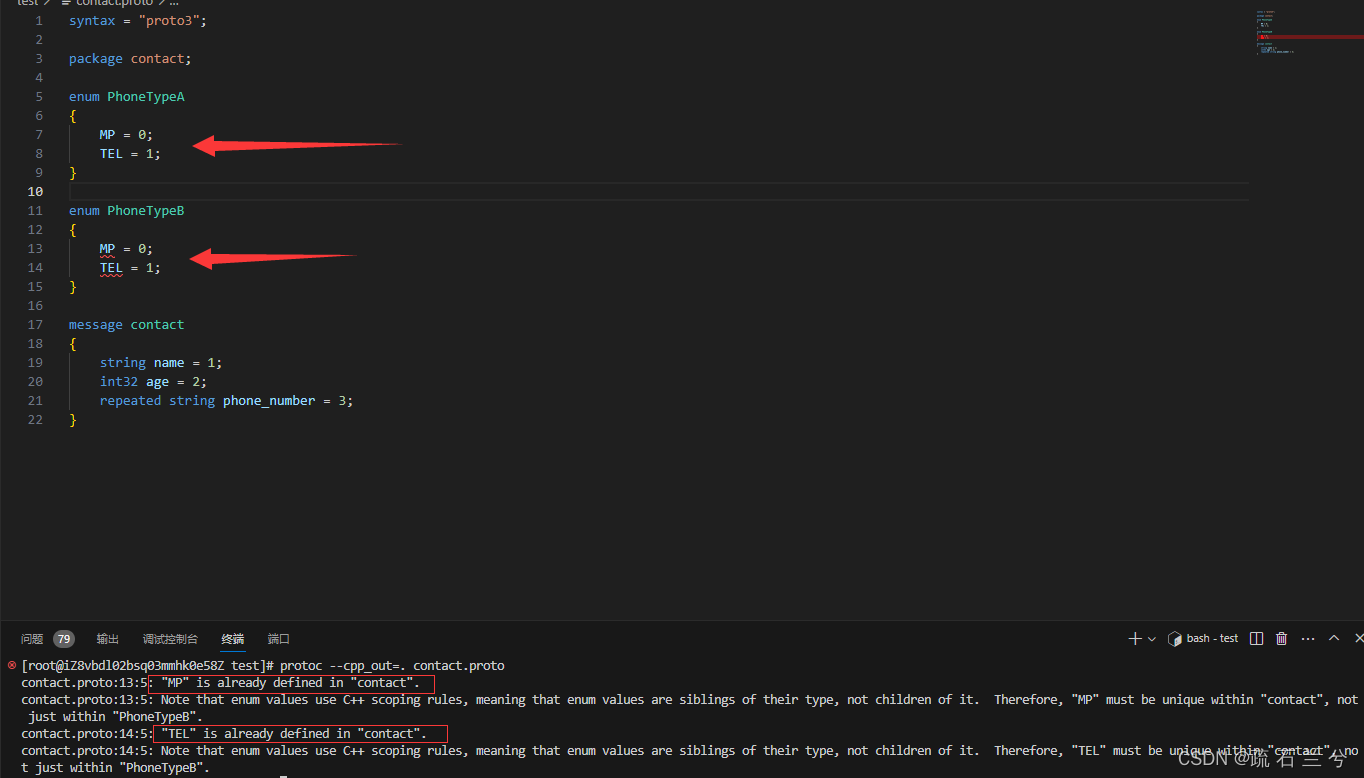
5. 单个.proto文件下,最外层枚举类型和嵌套枚举类型不算同级。
6. 多个.proto文件下,若一个文件引入了其他文件,且每个文件都未声明package, 每个proto文件中的枚举类型都在最外层,算同级。

7. 多个.proto文件下,若一个文件引入了其他文件,且每个文件都声明package,不算同级


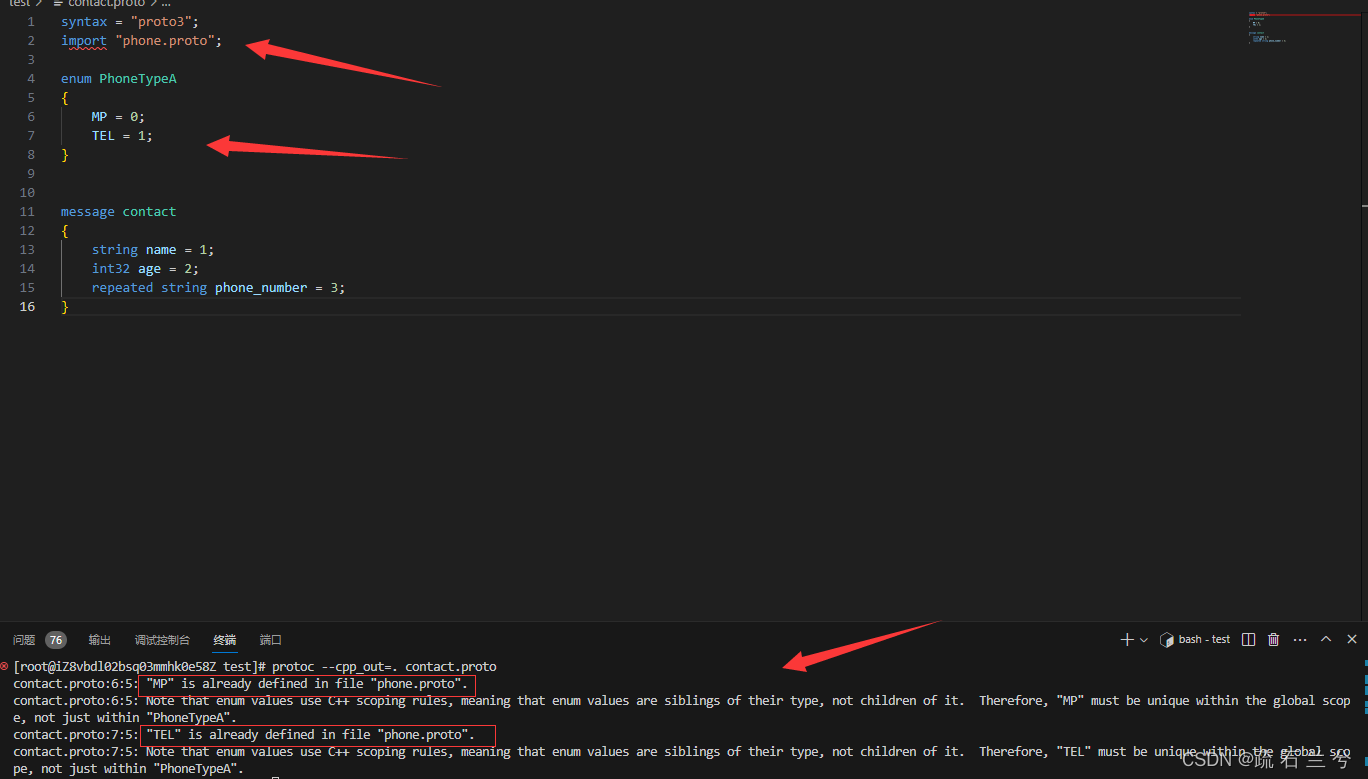
这样我们的编译就可以完美通过了,当然在编译的时候可能会出现:
这是由于我们在Contacts.proto中导入了enum A但是却没有使用它而报出的警告,我们忽略即可;
enum相关.pb.h的代码:

添加Any类型
Any可以理解为一个泛类型,利用Any类型定义的字段可以接收任意类型的值;
Any类型本质上就是Protobuf中的一个自定义message,由protobuf官方为我们定好了,因此要使用该类型的时候,我们需要导入Any.proto:
import "google/protobuf/any.proto";proto代码如下:
syntax = "proto3";
import "google/protobuf/any.proto";
package contact;message contact
{string name = 1;int32 age = 2;repeated string phone_number = 3;enum PhoneType{MP = 0;TEL = 1;} google.protobuf.Any data = 4;}
常用函数讲解:
bool has_data() const;- 作用:检查‘data’字段是否已被设置(即是否有有效数据)
- 用法:用于在访问‘data’字段前见检查它是否有值。
void clear_data();- 作用:清除‘data’字段的值,将其重置为空状态。
- 用法:当需要充值或删除‘data’字段的内容时使用。
const ::PROTOBUF_NAMESPACE_ID::Any& data() const;- 作用:返回‘data’字段的常量引用
- 用法:在需要读取‘data’字段的内容时使用
const ::PROTOBUF_NAMESPACE_ID::Any& data() const;- 作用: 释放
data字段的所有权,并返回指向该字段的指针,同时将data字段重置为空。 - 用法: 在需要转移
data字段的所有权时使用,避免拷贝数据。
::PROTOBUF_NAMESPACE_ID::Any* mutable_data();- 作用: 返回
data字段的可修改指针。 - 用法: 当需要修改
data字段的内容时使用。
void set_allocated_data(::PROTOBUF_NAMESPACE_ID::Any* data);- 作用: 设置
data字段的内容,并拥有data的所有权。传入的指针data现在由MyMessage实例管理。 - 用法: 在分配好一个新的
Any对象后,将它的所有权转交给MyMessage实例。
添加oneof类型
作用:
‘oneof’用于在消息中定义一组字段,其中最多只有一个字段可以被设置,这种设计用于需要在多个字段中互斥选择其中一个的情况。
特点:
- 互斥字段:
oneof确保了一次只能有一个字段被设置,避免了消息中无意义的冗余数据。 - 节省空间: 只有被设置的字段会被序列化,从而减少了消息的大小。
- 自动清理: 设置一个
oneof中的字段会自动清除之前被设置的字段。
使用场景
- 可选字段互斥:如在用户联系信息中,只能选择一种联系方法。
- 变体类型:如定义一个数据结构可以是几种不同类型的变体。
oneof和enum,我在学习的时候觉得非常的接近,这里说一下这两个的区别
| 特性 | enum | oneof |
| 目的 | 定义一组固定的命名整数值 | 定义多个互斥字段 |
| 数据类型 | 整数 | 各种数据类型 |
| 存储空间 | 占用一个整数字段的大小 | 仅存储被设置的字段,占用最少的空间 |
| 使用场景 | 需要从一组固定选项中选择一个值 | 需要在多个字段中互斥选择一个 |
| 序列化 | 被序列化为整数值,通常占用较小的空间 | 只有被设置的字段会被序列化,未设置的字段不会 |
| 字段互斥 | 不互斥,‘enum’字段可以和其他字段一起被设置 | 互斥,一个‘oneof’中最多只能有一个字段被设置 |
| 自动清理 | 不适用 | 设置一个字段会自动清除‘oneof’中的其他字段 |
proto代码如下:
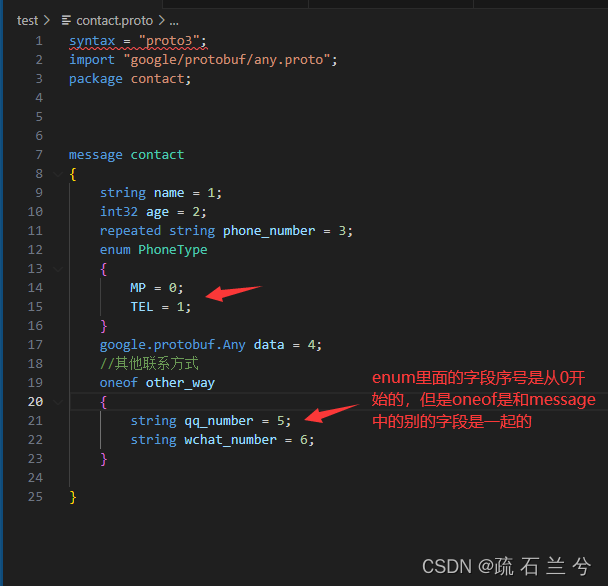
常用函数和其他的字段的常用函数类似。
添加map类型
声明格式:
map<key_type, value_type> map_field = N;其中:
- key_type:必须是除了float、bytes外的标量类型;
value_type: 无类型限制 - map字段不能使用repeated字段进行修饰
- map存入的元素是无序的;
常用函数类似上面介绍,不做过多介绍
ProtoBuf生成的方法的规则总结
1.如果是protobuf的内置标量类型,那么生成常用方法如下:
xxx();//获取字段(const 对象)
set_xxx();//设置字段
clear_xxx();//清除字段
mutable_xxx();//获取字段的地址(诸如string、bytes等类型才会生成,其它内置类型不会);2.如果是message自定义类型,那么生成常用方法如下:
xxx();//获取该字段(const 对象)
mutable_xxx();//获取该字段的地址;
clear_xxx();//清理该字段
has_xxx();//判断该字段是否被设置3.如果是数组字段,那么会生成常用方法如下:
xxx_size();//获取数组元素个数;
xxx(index);//获取第index个元素;
mutable_xxx(index);//获取第index个元素的下标;
clear_xxx();//清理数组
Add_xxx();//获取插入位置4. enum枚举字段,生成常用方法:
两个全局方法:
XXX_Name(values);//将枚举常量values变为字符串
XXX_IsValid(values);//判断values是不是枚举常量
常规方法:
clear_xxx();//清理
xxx();//获取
set_xxx();//设置5. Any字段,生成常用方法:
Any字段内部方法:
PackFrom(mes);//将mes设置给Any字段
UnpackTo(mes);//将Any字段还原成mes对象
template< class T>
bool Is();//判断挡墙Any字段中是不是存的T类型的值;
常规方法:
has_xxx();//Any字段是否被设置
clear_xxx();//清理
xxx();//获取Any字段
mutable_xxx();//获取any字段地址
6. oneof字段,常用方法:
子字段方法:
xxx();
clear_xx();
set_xxx();
mutable_xxx();
has_xxx();
针对oneof字段的方法:
clear_XXX();//清理oneof字段里放的值
XXX_case();//获取oneof字段使用的那个子字段,以枚举类型返回(oneof中的每个子字段都会被protoc编译成一个枚举常量,放在同一个枚举类型中);
7. map字段,常用方法:
clear_xxx();
xxx_size();
xxx();
mutable_xxx();8. 常用序列化和反序列化方法:
常用序列化方法:
bool SerializeToOstream(ostream * output) const;//将序列化结果放入流里面(标准流、文件流、字符串流);
bool SerializeToArray(void *data, int size) const;//将序列化结果放入字节流里面
bool SerializeToString(string* output) const;//将序列化结果放入字符串里面
常用反序列化方法:
bool ParseFromIstream(istream* input);//从流里面读取反序列化结果;
bool ParseFromArray(const void* data, int size);//从字节流里面读取反序列化结果;
bool ParseFromString(const string& data);//从字符串中读取反序列化结果
默认值
对于proto3的语法来说message中的字段默认是用singular来修饰的,被singular修饰的字段在序列化的时候如果没有被设置值,那么protobuf的序列化方法是不会将该字段进行编码的;同理在反序列化的时候,如果在反序列化序列中没有找到message中某一字段的值,那么protobuf会用该字段的默认值来填充该字段;
下面是各个类型对应的默认值:
更新消息
- 如果现有的消息类型已经不再满⾜我们的需求,例如需要扩展⼀个字段,在不破坏任何现有代码的情 况下更新消息类型⾮常简单。遵循如下规则即可:
- 禁止修改已有字段的编号
- 如果我们只更改message 中字段的类型,那么对于如下更改反序列化的字段值是兼容;int32,uint32,int64, bool等是完全兼容的,可以从这些类中的一个转换成另一个
- sin32和sin64兼容,但是和其他整型是不兼容的,fixed32和sfix32兼容但是与其他整型不兼容,fixed64与sfixed64兼容但是与其他整型不兼容;
- string和bytes在合法UTF-8字节下是兼容的
- enum与int32,uint32,int64和uint64兼容(注意若值不匹配会被截断)。但要注意当反序列化消息时会根据语言采用不同的处理方案
- oneof:
- 将一个独立的字段移动到新的oneof成员之一是安全的且二进制兼容的
- 若确定没有代码一次性设置多个值那么将多个字段移入一个新的oneof也是可行的
- 将任何字段移入已存在的oneof类型是不安全的
保留字段reserved
如果通过删除或注释掉字段来更新消息类型,未来的用户在添加新字段时,有可能会使⽤以前已经 存在,但已经被删除或注释掉的字段编号。将来使⽤该.proto的旧版本时的程序会引发很多问题:数 据损坏、隐私错误等等。 确保不会发⽣这种情况的⼀种⽅法是:使⽤reserved 将指定字段的编号或名称设置为保留项。当 我们再使⽤这些编号或名称时,protocolbuffer的编译器将会警告这些编号或名称不可⽤。
message Message {// 设置保留项 reserved 100, 101, 200 to 299;reserved "field3", "field4";// 注意:不要在⼀⾏ reserved 声明中同时声明字段编号和名称。 // reserved 102, "field5";// 设置保留项之后,下⾯代码会告警 int32 field1 = 100; //告警:Field 'field1' uses reserved number 100 int32 field2 = 101; //告警:Field 'field2' uses reserved number 101 int32 field3 = 102; //告警:Field name 'field3' is reserved int32 field4 = 103; //告警:Field name 'field4' is reserved
}未知字段
未知字段:解析结构良好的protocolbuffer已序列化数据中的未识别字段的表示方式。例如,当 旧程序解析带有新字段的数据时,这些新字段就会成为旧程序的未知字段。
MessageLite类:
MessageLite从名字看是轻量级的message,仅仅提供序列化、反序列化功能
类定义在google提供的message_lite.h中.
Message类:
我们自定义的message类都是继承于Message类;
Message类中最重要的两个接口GetDescriptor/GetReflection,可以获取该类型对应的Descriptor对象指针和Reflection对象指针。
类定义在google提供的message.h中。
Descriptor类:
是对与我们自定义的message类的描述,包括自定义message的名字、所有字段的描述、原始的proto文件等;
类定义在google提供的descriptor.h中
Reflection类:
主要提供了动态读写消息字段的接⼝,对消息对象的⾃动读写主要通过该类完成。
提供⽅法来动态访问/修改message中的字段,对每种类型,Reflection都提供了⼀个单独的接⼝⽤于读写字段对应的值。
针对所有不同的field类型 FieldDescriptor::TYPE_* ,需要使⽤不同的 Get*()/Set*()/Add*() 接⼝;
repeated类型需要使⽤ GetRepeated*()/SetRepeated*() 接⼝,不可以和⾮repeated类型接口混⽤;
message对象只可以被由它⾃⾝的 reflection(message.GetReflection()) 来操作;类中还包含了访问/修改未知字段的⽅法
定义在google提供的message.h中
UnknownFieldSet类:
UnknownFieldSet包含在分析消息时遇到但未由其类型定义的所有字段;
若要将UnknownFieldSet附加到任何消息,请调⽤Reflection::GetUnknownFields()。
类定义在unknown_field_set.h中;
UnknownField类:
表⽰未知字段集中的⼀个字段;
类定义在unknown_field_set.h中;
选项option
proto⽂件中可以声明许多选项,使⽤ option 标注。选项能影响proto编译器的某些处理⽅式。
选项分为⽂件级、消息级、字段级等等,但并没有⼀种选项能作⽤于所有的类型。
常用选项举例
- optimize_for:该选项为⽂件选项,可以设置protoc编译器的优化级别,分别为SPEED CODE_SIZE 、 LITE_RUNTIME 。受该选项影响,设置不同的优化级别,编译.proto⽂件后⽣成的代码内容不同。
- SPEED: protoc编译器将⽣成的代码是⾼度优化的,代码运⾏效率⾼,但是由此⽣成的代码编译后会占⽤更多的空间。 SPEED是默认选项。
- CODE_SIZE :proto编译器将⽣成最少的类,会占⽤更少的空间,是依赖基于反射的代码来实现序列化、反序列化和各种其他操作。但和 SPEED 恰恰相反,它的代码运⾏效率较低。这种⽅式适合⽤在包含⼤量的.proto⽂件,但并不盲⽬追求速度的应⽤中。
- LITE_RUNTIME :⽣成的代码执⾏效率⾼,同时⽣成代码编译后的所占⽤的空间也是⾮常少。这是以牺牲ProtocolBuffer提供的反射功能为代价的,仅仅提供encoding+序列化功能,所以我们在链接BP库时仅需链接libprotobuf-lite,⽽⾮libprotobuf。这种模式通常⽤于资源有限的平台,例如移动⼿机平台中。