shell编程之正则表达式与文本处理器(shell脚本)
2025/2/19 8:41:37
来源:https://blog.csdn.net/2401_85084312/article/details/139962861
浏览:
次
关键词:shell编程之正则表达式与文本处理器(shell脚本)


一、正则表达式
1、正则表达式的定义
正则表达式又称正规表达式、常规表达式。在代码中常简写为 regex、regexp
或 RE。正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说,是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
正则表达式一般用于脚本编程与文本编辑器中。很多文本处理器与程序设计语言均支持
正则表达式,例如 Linux 系统中常见的文本处理器(grep、egrep、sed、awk)以及应用比较广泛的 Python 语言。正则表达式具备很强大的文本匹配功能,能够在文本海洋中快速高效地处理文本。

2、正则表达式的组成
正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。其中普通字符包括大小写字母数字、标点符号及一些其他符号,元字符则是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式

3、正则表达式的分类和文本处理工具
正则表达式的字符串表达方法根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达式。基础正则表达式是常用正则表达式最基础的部分。在 Linux 系统中常见的文件处理工具中 grep 与 sed 支持基础正则表达式,而 egrep 与 awk 支持扩展正则表达式。

4、正则表达式与通配符的区别

二、基础正则表达式

1、基础正则表达式元字符

三、扩展正则表达式
grep 命令仅支持基础正则表达式,如果使用扩展正则表达式,需要使用 egrep
或 awk 命令。这里我们直接使用 egrep 命令。egrep 命令与 grep 命令的用法基本相似。egrep 命令是一个搜索文件获得模式,使用该命令可以搜索文件中的任意字符串和符号,也可以搜索一个或多个文件的字符串,一个提示符可以是单个字符、一个字符串、一个字或一个句子。

四、grep搜索工具
 1、grep命令格式和常用选项
1、grep命令格式和常用选项

例:-n:显示行号,sh开头的;rt结尾的,中间有i/o的。
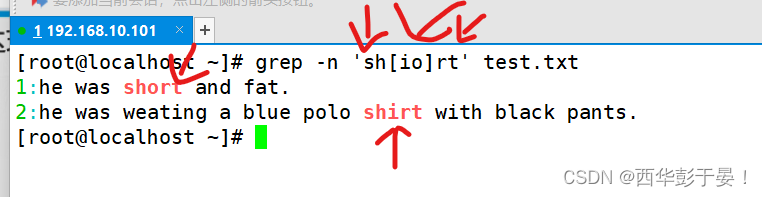
匹配中间有‘oo’的词语,但不以‘w’开头。
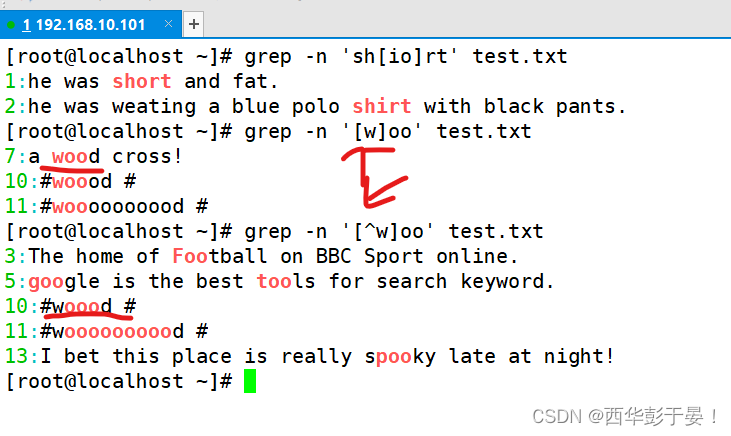
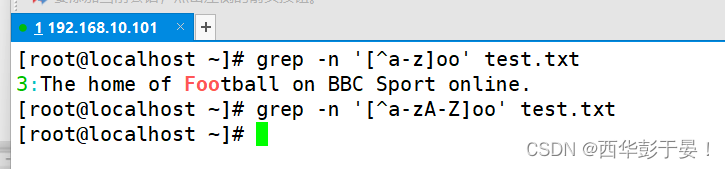
列出不以a-z开头的以及A-Z开头的,但是中有‘oo’的词语。
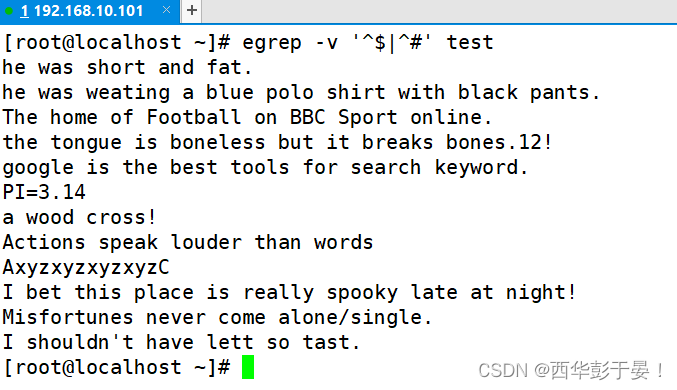
如何去掉文本中空白行以及注释行(#)?

如何简化命令(使用扩展正则表达式)(去掉空白行和注释行(#开头的))
五、sed文本处理工具
sed(Stream EDitor)是一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑(删除、替换、添加、移动等),最后输出所有行或者仅输出处理的某些行。sed 也可以在无交互的情况下实现相当复杂的文本处理操作,被广泛应用于 Shell 脚本中,用以完成各种自动化处理任务。

1、sed的工作原理
读取:sed 从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)。
执行:默认情况下,所有的 sed 命令都在模式空间中顺序地执行,除非指定了行的地址,否则 sed 命令将会在所有的行上依次执行。
显示:发送修改后的内容到输出流。在发送数据后,模式空间将会被清空。
在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容被处理完。
注意:默认情况下所有的 sed 命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出。

2、sed的命令行格式和常用的选项
通常情况下调用 sed 命令有两种格式,如下所示。其中,“参数”是指操作的目标文件,当存在多个操作对象时用,文件之间用逗号“,”分隔;需要用“-f”选项指定,当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标文件。

3、sed的编辑命令格式
“操作”用于指定对文件操作的动作行为,也就是 sed 的命令。通常情况下是采用的“[n1[,n2]]”操作参数的格式。n1、n2 是可选的,代表选择进行操作的行数,如操作需要在 5~20 行之间进行,则表示为“5,20 动作行为”。

4、sed的编辑命令格式

5、sed的用法实例

例:如何替换关键字?不加‘g’只替换第一个关键字,加上‘g’替换所有。只是屏幕上显示更改后的效果,文件本身没有被更改,如果想要更改文件本间,需要在sed后面加‘-i’选项。 如:sed -i 's/the/THE/g' test.txt

如何选中行的区间替换?
将第二行到第十行所有‘the’替换为‘THE’

如何寻找单词?

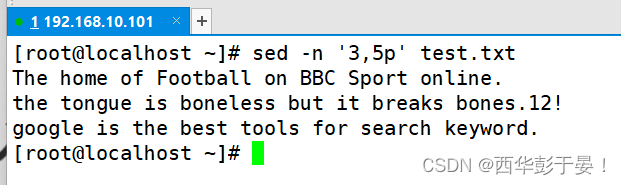
打印文本中3-5行内容。
如何输出偶数行?
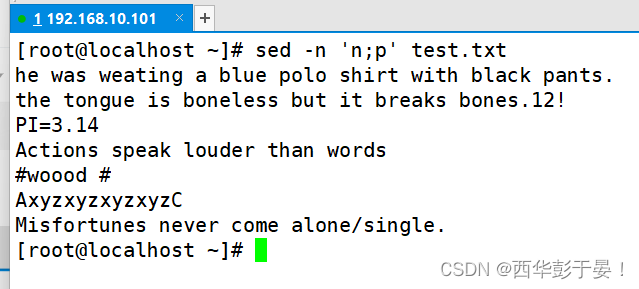
如何输出奇数行?
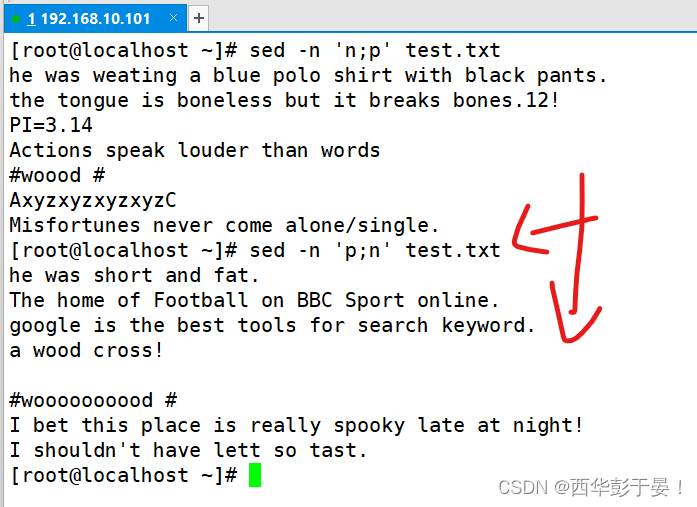
如何显示第几行到第几行偶数/奇数行?
显示第一行到第十行的偶数/奇数行。

如何显示第五行到结尾的偶数行?(奇数行同理) (¥为结尾行)

在sed中如何过滤关键字显示出来?
这一点不如grep专业,没有描红。
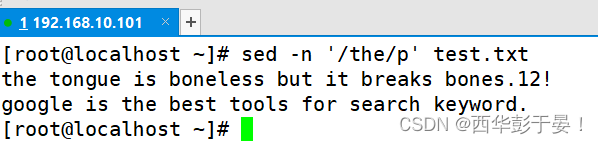
如何展示出从第四行开始包含the的行号?

如何利用sed工具写入脚本实现防火墙以及内核安全机制的永久关闭?

如何实现指定某一行与某一行的迁移(即剪切后粘贴到某一行)
H:复制到剪切板 d:删除原来位置的内容 $:末行 G:粘贴

如何指定行内添加一行内容?
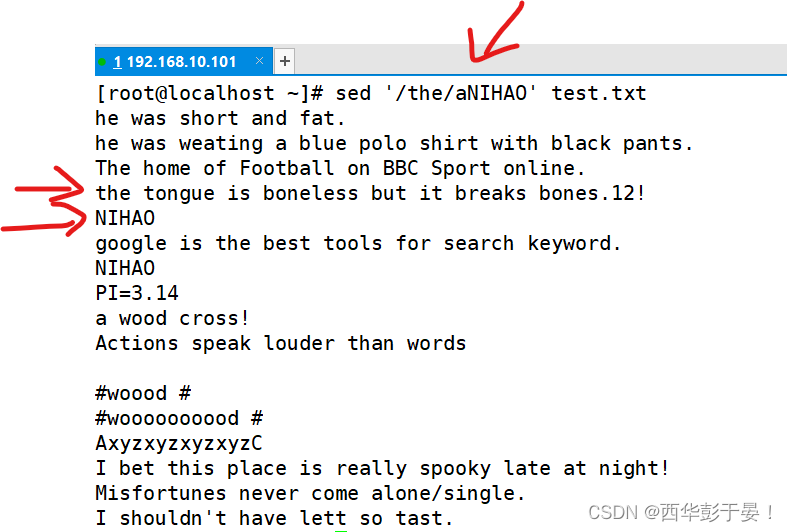
即:添加(NIHAO)到第三行的下一行。

如何指定包含关键字的下行添加内容?
六、awk 工具
在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,并根据指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,可以在无交互的情况下实现相当复杂的文本操作,被广泛应用于 Shell 脚本,完成各种自动化配置任务。

1、awk的工作原理

2、awk 常见用法
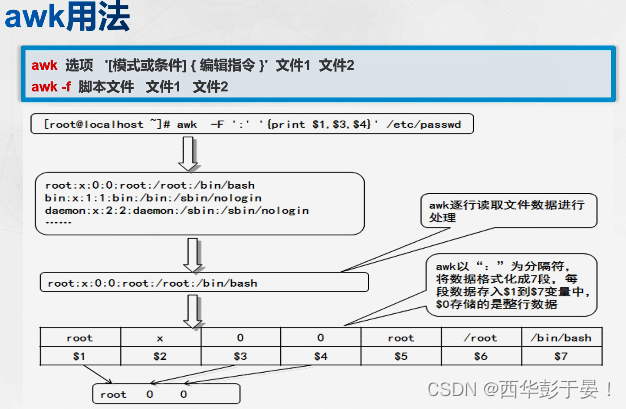
通常情况下 awk 所使用的命令格式如下所示,其中,单引号加上大括号“{}”用于设置对数据进行的处理动作。awk 可以直接处理目标文件,也可以通过“-f”读取脚本对目标文件进行处理。
awk 从输入文件或者标准输入中读入信息,与 sed 一样,信息的读入也是逐行读取的。不同的是 awk 将文本文件中的一行视为一个记录,而将一行中的某一部分(列)作为记录中的一个字段(域)。为了操作这些不同的字段,awk 借用 shell 中类似于位置变量的方法,用$1、$2、$3…顺序地表示行(记录)中的不同字段。另外 awk 用$0 表示整个行(记录)。不同的字段之间是通过指定的字符分隔。awk 默认的分隔符是空格。awk 允许在命令行中用“-F 分隔符”的形式来指定分隔符。
3、awk的内置变量

4、awk的用法示例

如何显示偶数行/奇数行?
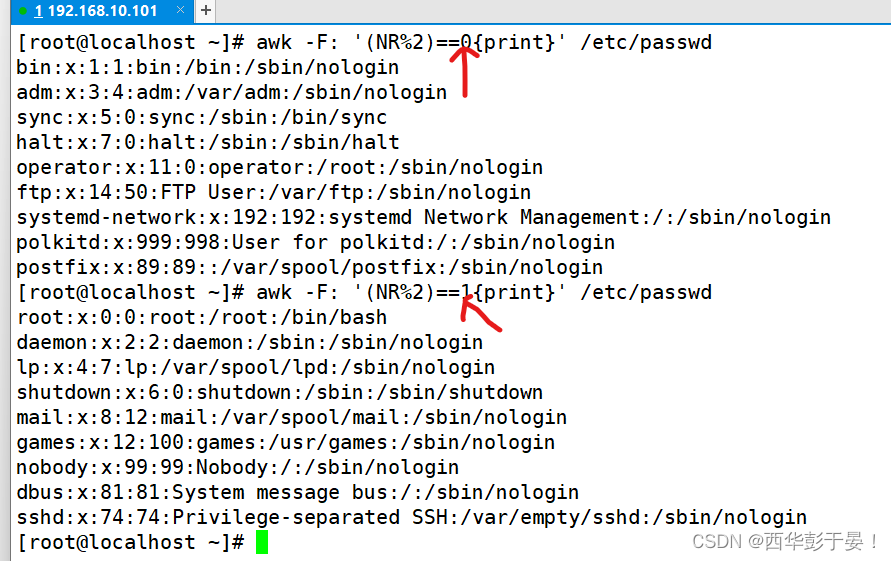
显示以关键字开头的行

七、sort 工具
在 Linux 系统中,常用的文件排序工具有三种:sort、uniq、wc 。
sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序例如数据和字符的排序就不一样。sort 命令的语法为“sort [选项] 参数”

1、sort的常用选项

2、sort的用法示例

八、uniq 工具
Uniq 工具在 Linux 系统中通常与 sort 命令结合使用,用于报告或者忽略文件中的重复行。具体的命令语法格式为:uniq [选项] 参数 。

1、uniq的用法示例

九、tr 工具
tr 命令常用来对来自标准输入的字符进行替换、压缩和删除。可以将一组字符替换之后变成另一组字符,经常用来编写优美的单行命令,作用很强大。

1、tr的用法示例

十、cut工具

1、cut的用法示例


版权声明:
本网仅为发布的内容提供存储空间,不对发表、转载的内容提供任何形式的保证。凡本网注明“来源:XXX网络”的作品,均转载自其它媒体,著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处。
我们尊重并感谢每一位作者,均已注明文章来源和作者。如因作品内容、版权或其它问题,请及时与我们联系,联系邮箱:809451989@qq.com,投稿邮箱:809451989@qq.com