一、预测阶段(前向推断)
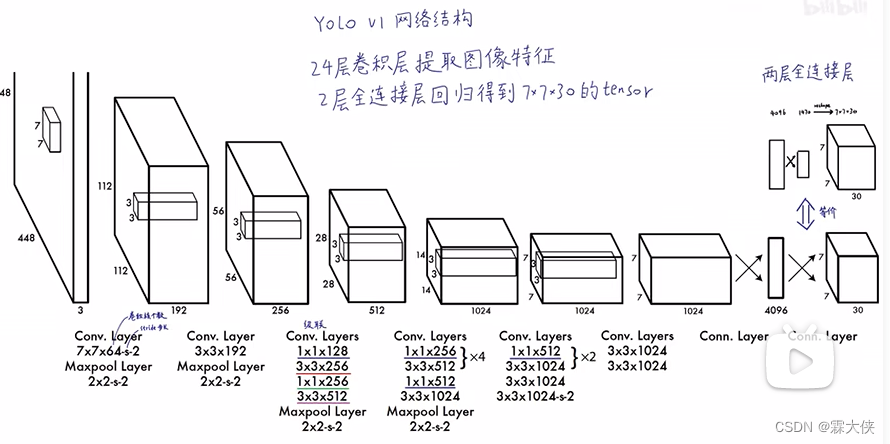
在预测阶段Yolo就相当于一个黑箱子,输入的是448*448*3的图像,输出是7*7*30的张量,包含了所有预测框的坐标、置信度和类别
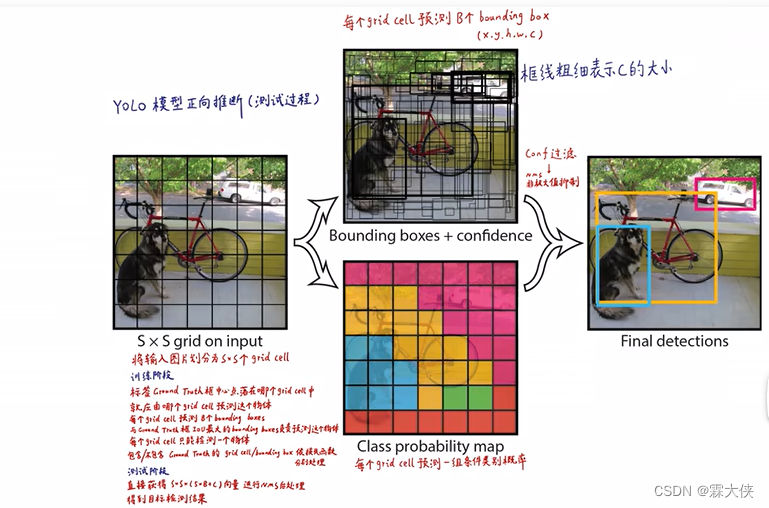
为什么是7*7*30呢?
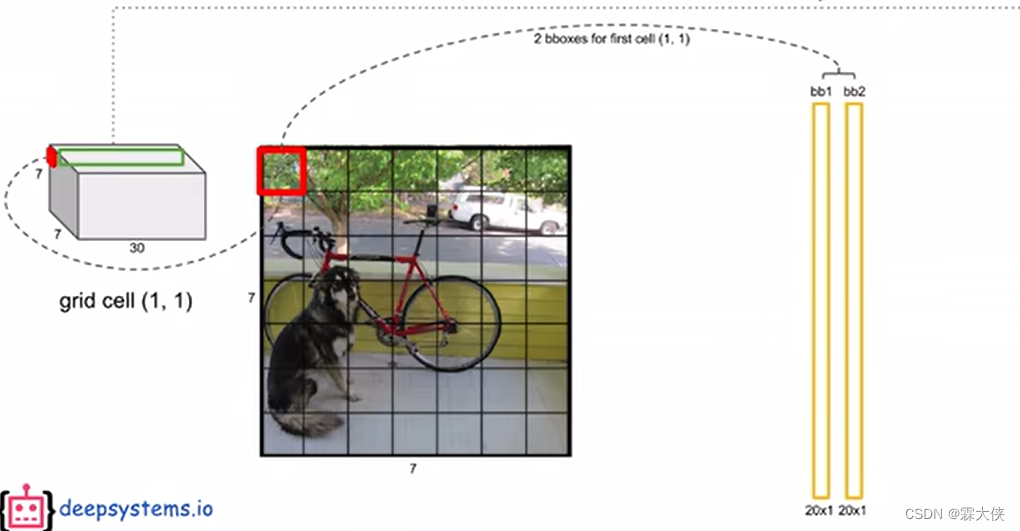
--将输入图像划分成s*s个grid cell,在yolov1中s=7,然后每个grid cell会预测B个bounding box,这个bounding box里包含4个位置参数和一个置信度参数,在yoolov1中B=2。
--每一个grid cell还能生成所有类别的条件概率,假设已经包含物体的情况下,那它属于某个类别的概率。
--再把每个bounding box的置信度×类别的条件概率=每个bounding box的各类别的概率
--结合bounding box的信息和grid cell的类别信息就可以获得最后的预测结果
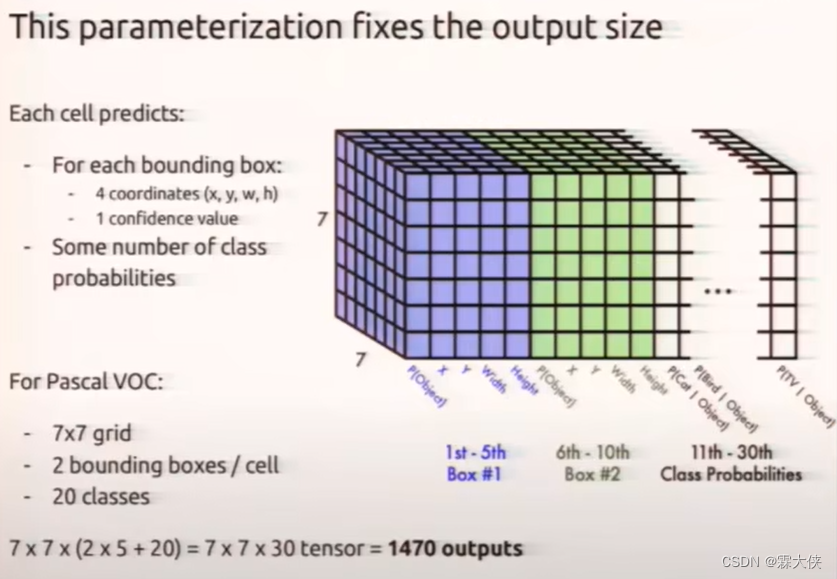
为什么是30?
过程可视化显示:




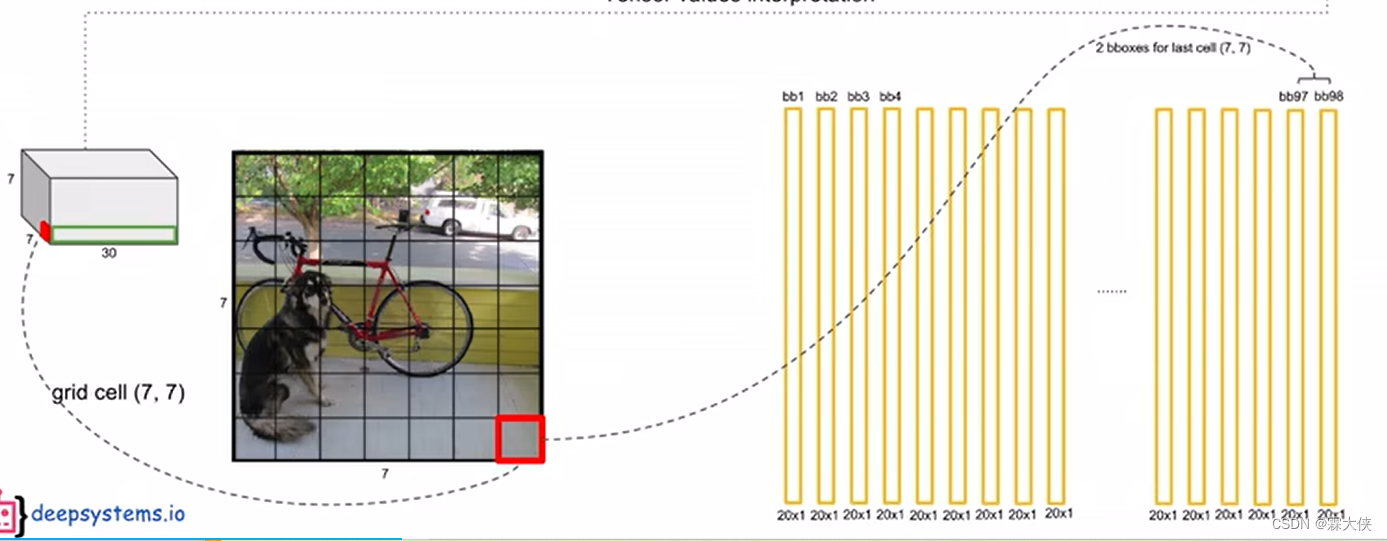
解释:每个grid cell只能有一个类别概率,从所有的预测的类别概率中选择最高的那一个代表这个格子的所属的类别,也就是说每个格子只能预测出一个类别。
--将中间的图进行处理,把置信度高额过滤掉,进行非极大值抑制得到最后的图
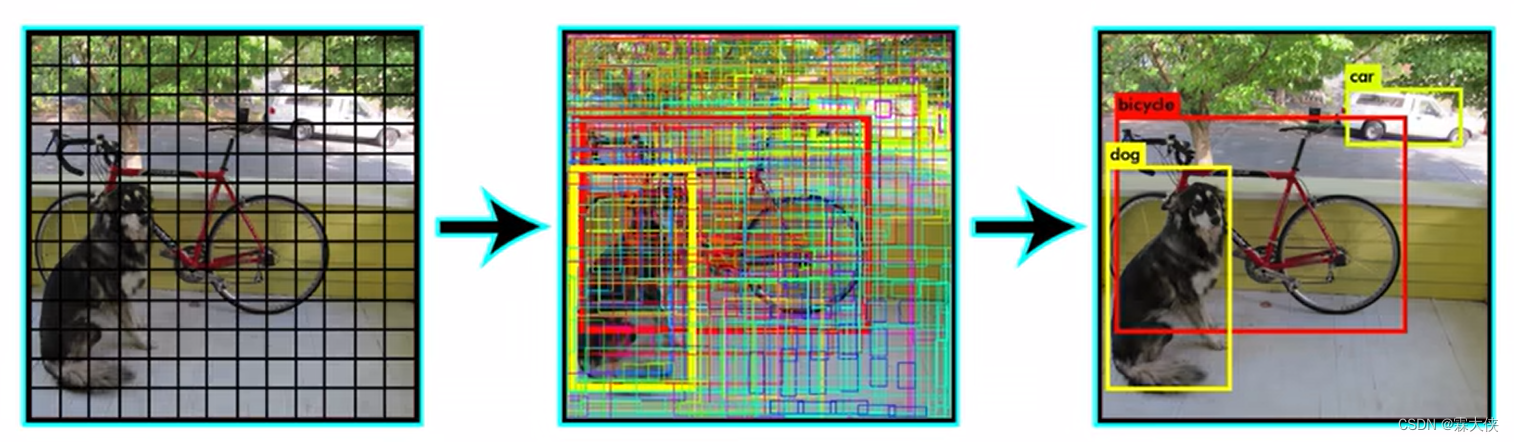
完整的过程:
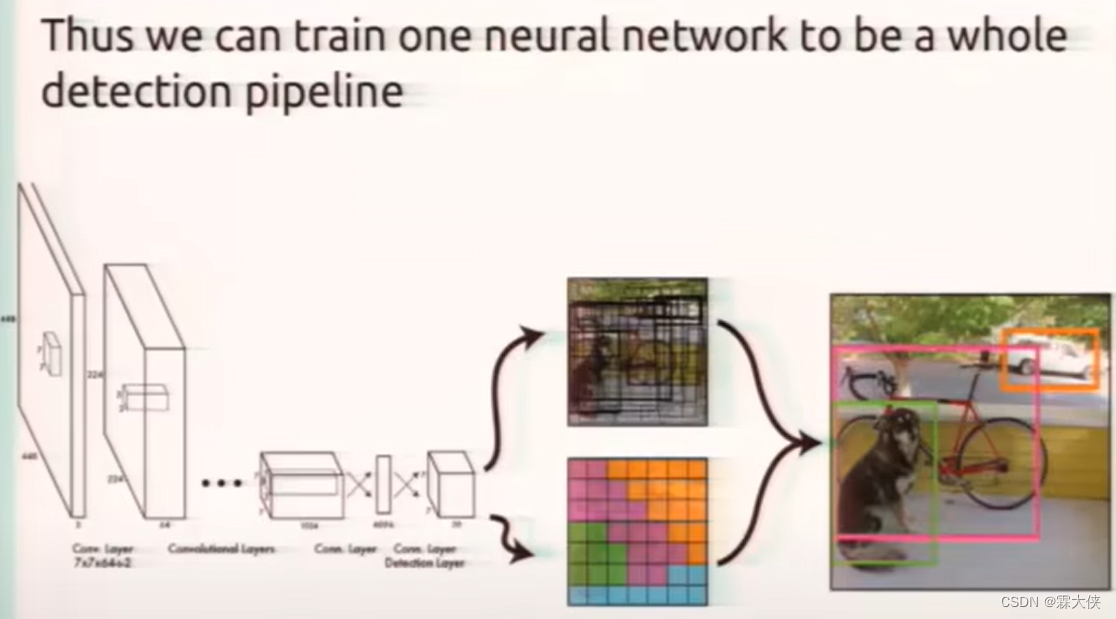
二、预测阶段 后处理(置信度过滤 非极大值抑制)
输入448*448*3的图像到生成7*7*30的张量的过程,这个过程可以看成是一个黑盒子进行处理的,那么我们现在要研究一下7*7*30的张量是怎么生成最后的结果的?
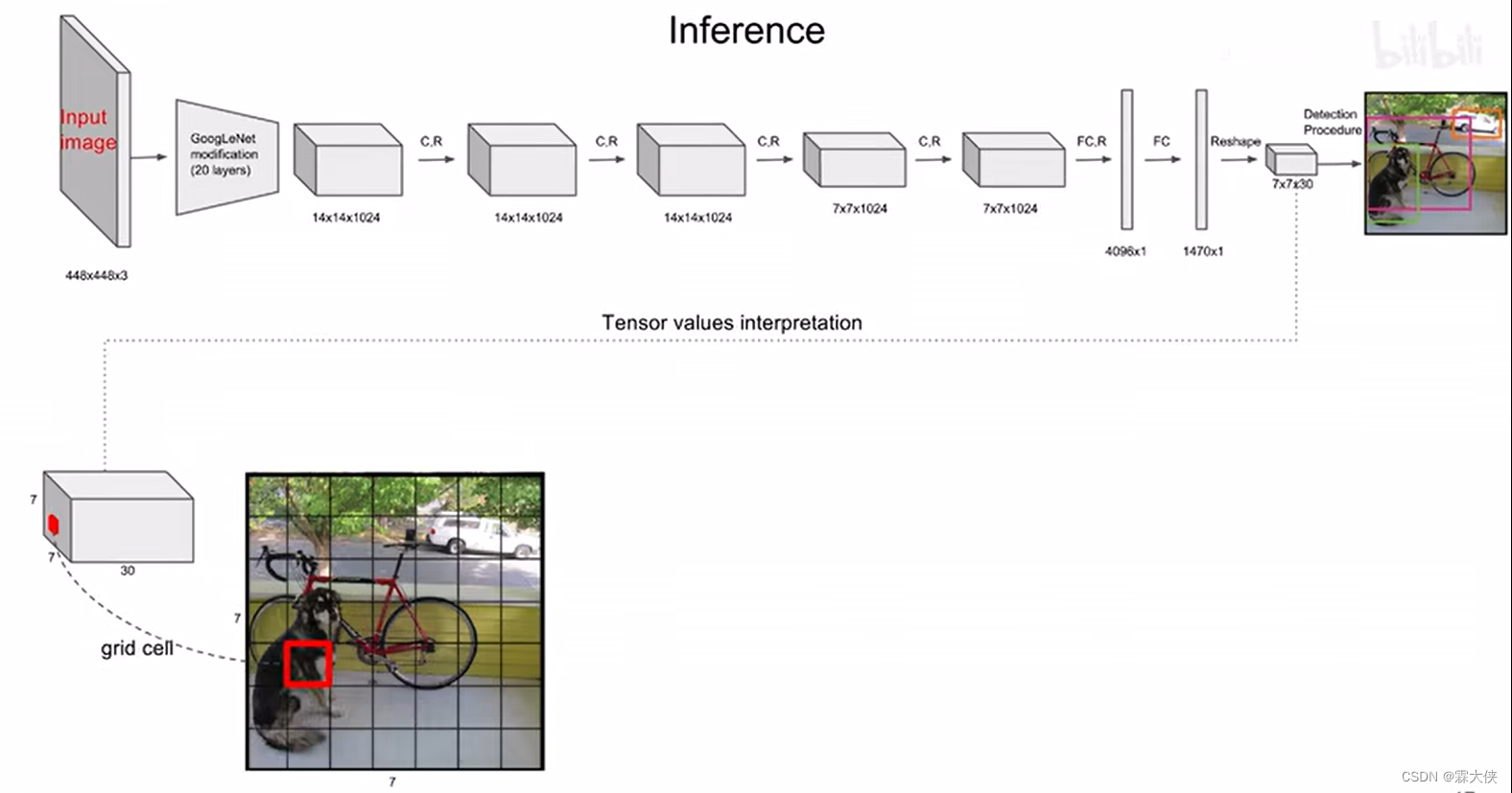
每个bounding box的有30个参数
每个grid cell预测两个bounding box
5:4个位置信息和1个置信度信息
20:20个类别,这个小框可能的所属的类别的概率
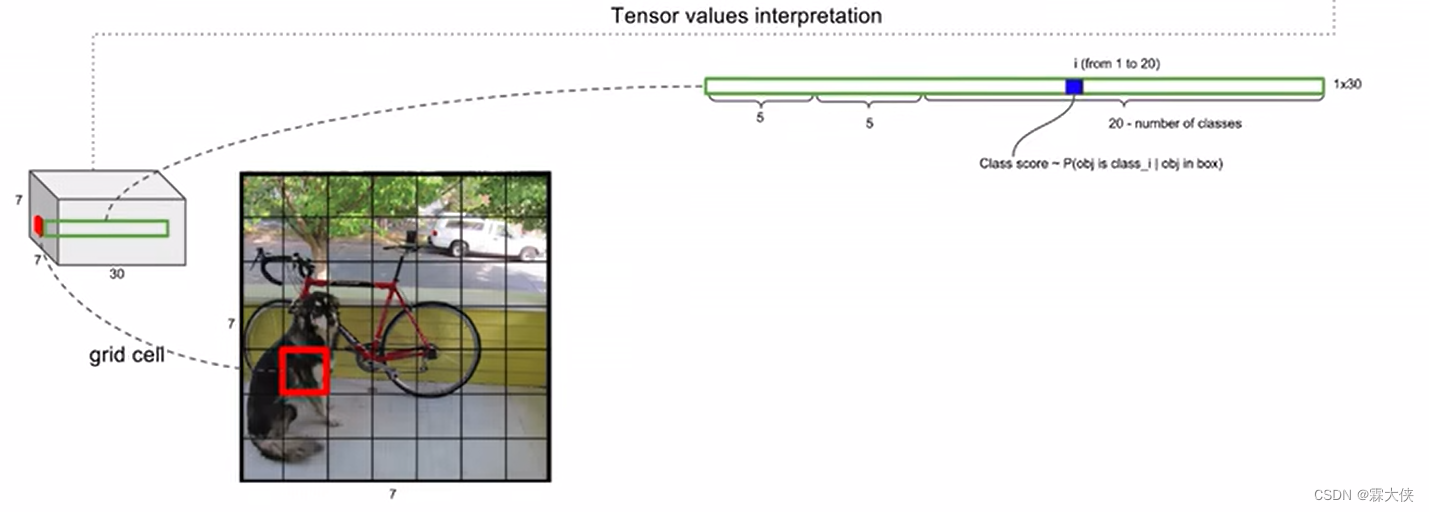
把这20个所属类别概率单独拿出来,跟每个bounding box的置信度相乘,(条件概率*这个条件本身发生的概率=全概率),就得到了它真正是哪个类别的概率
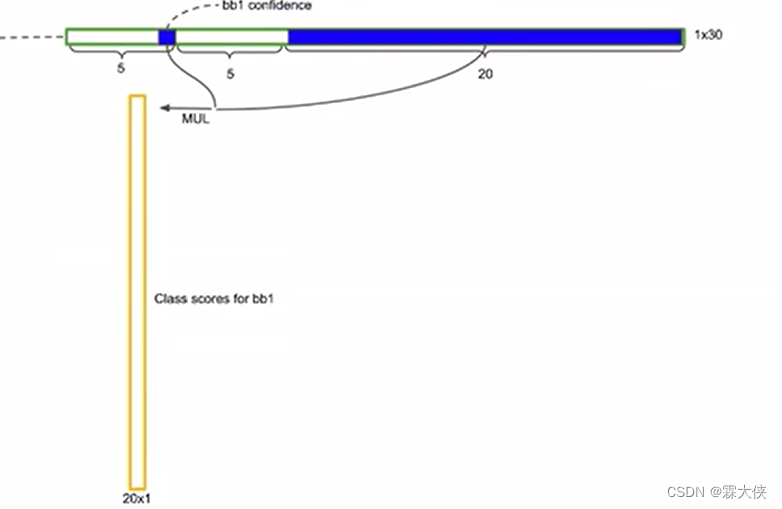
每个grid cell都可以获得连个全概率
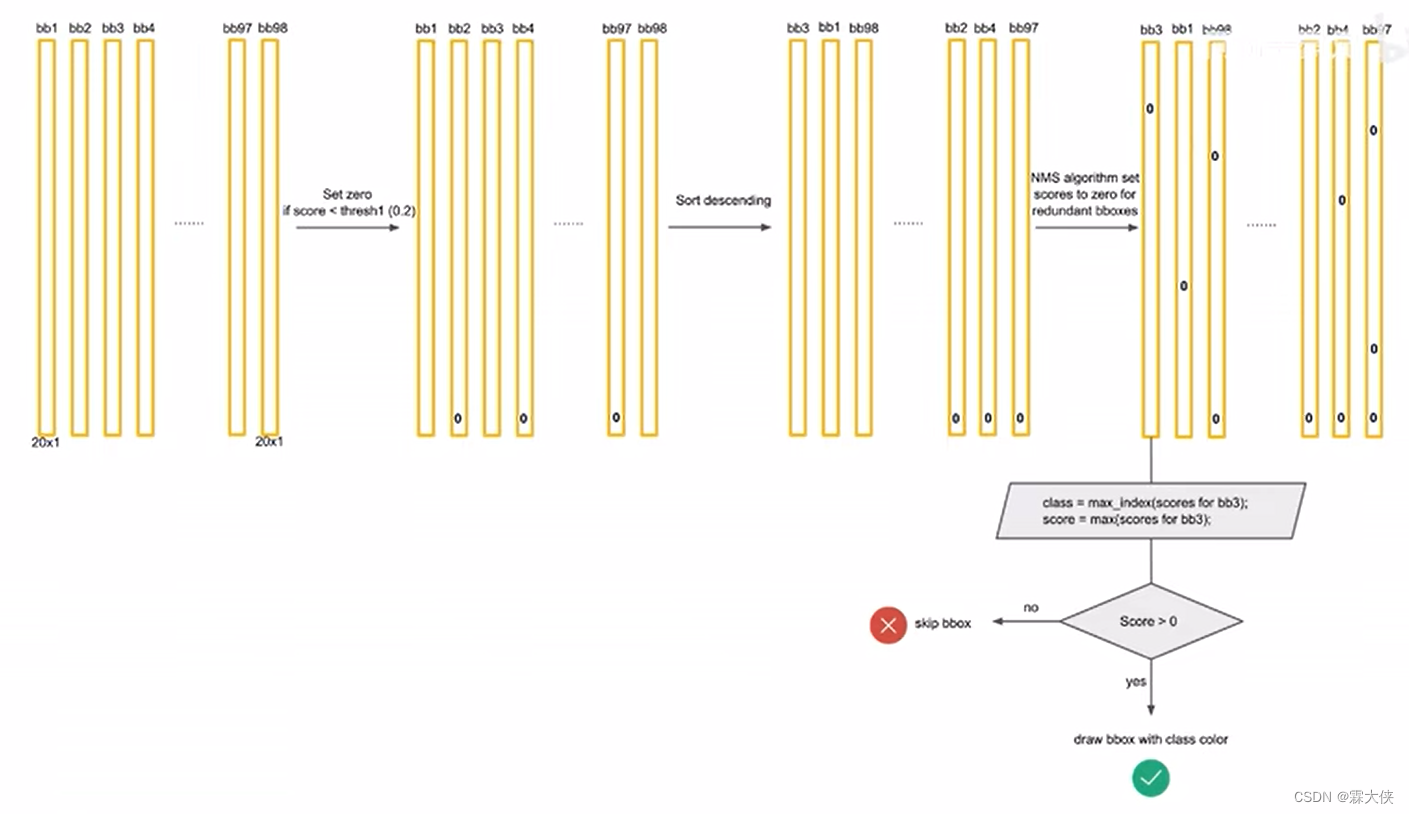
将某个类别的概率从大到小排序,然后在进行非极大值抑制
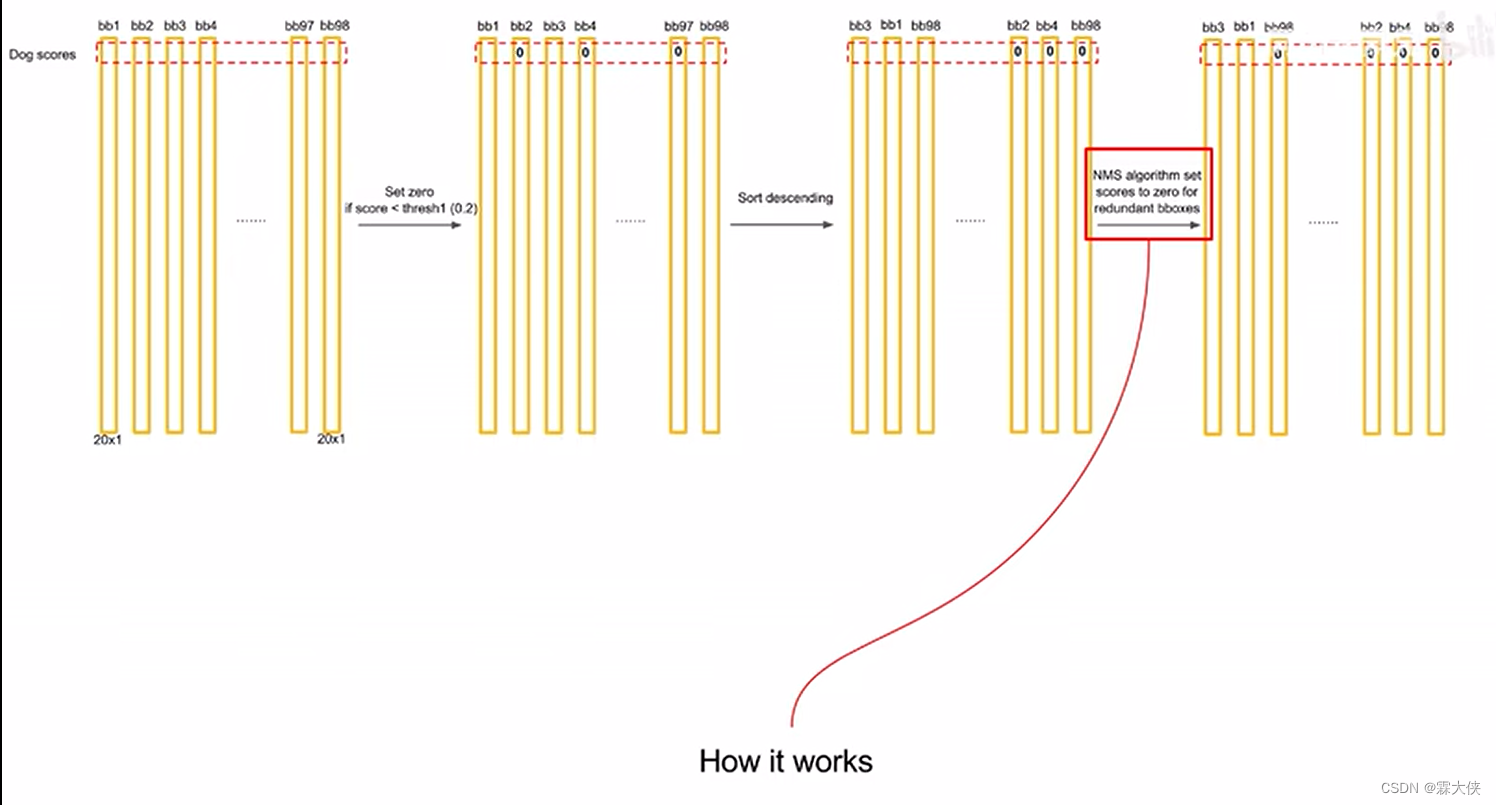
比较预测框的IoU,如果大于某个阈值,我们认为他们两个在重复识别一个物体,就将低概率的值置为0

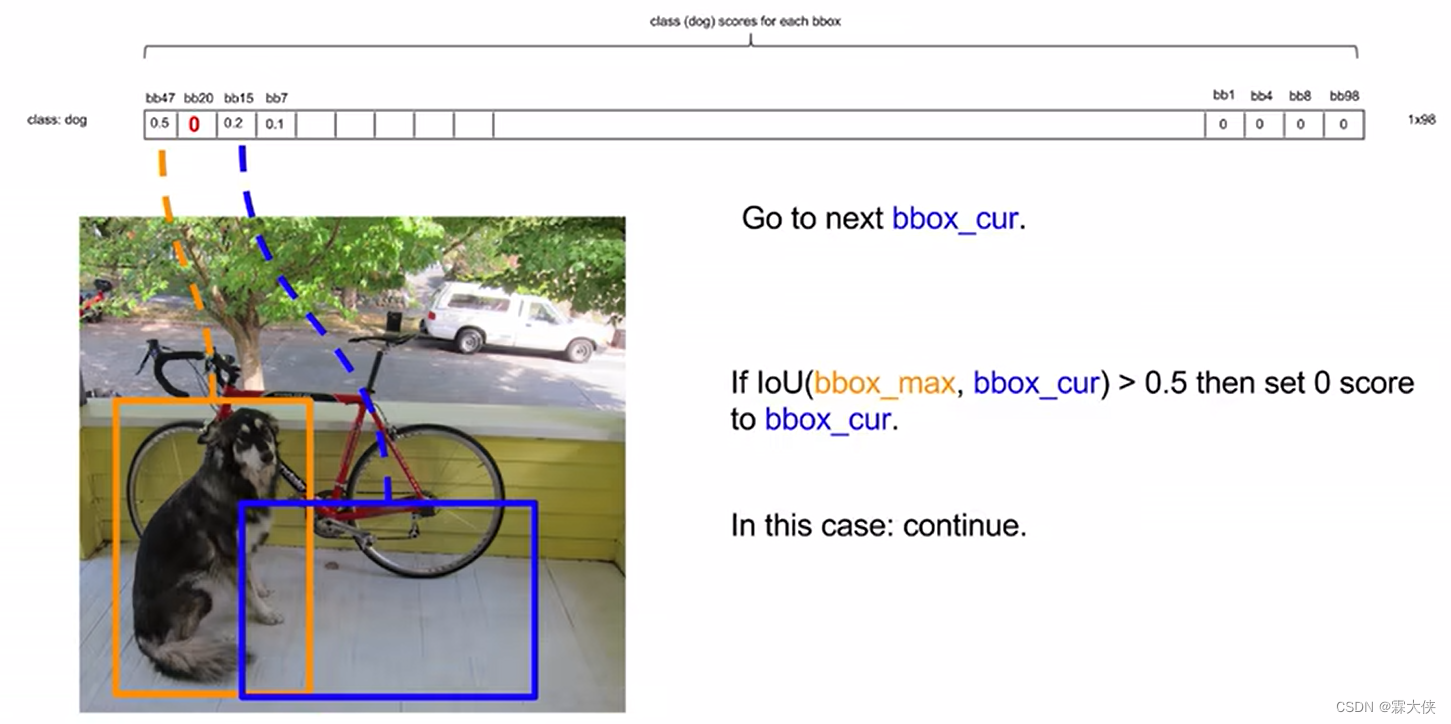

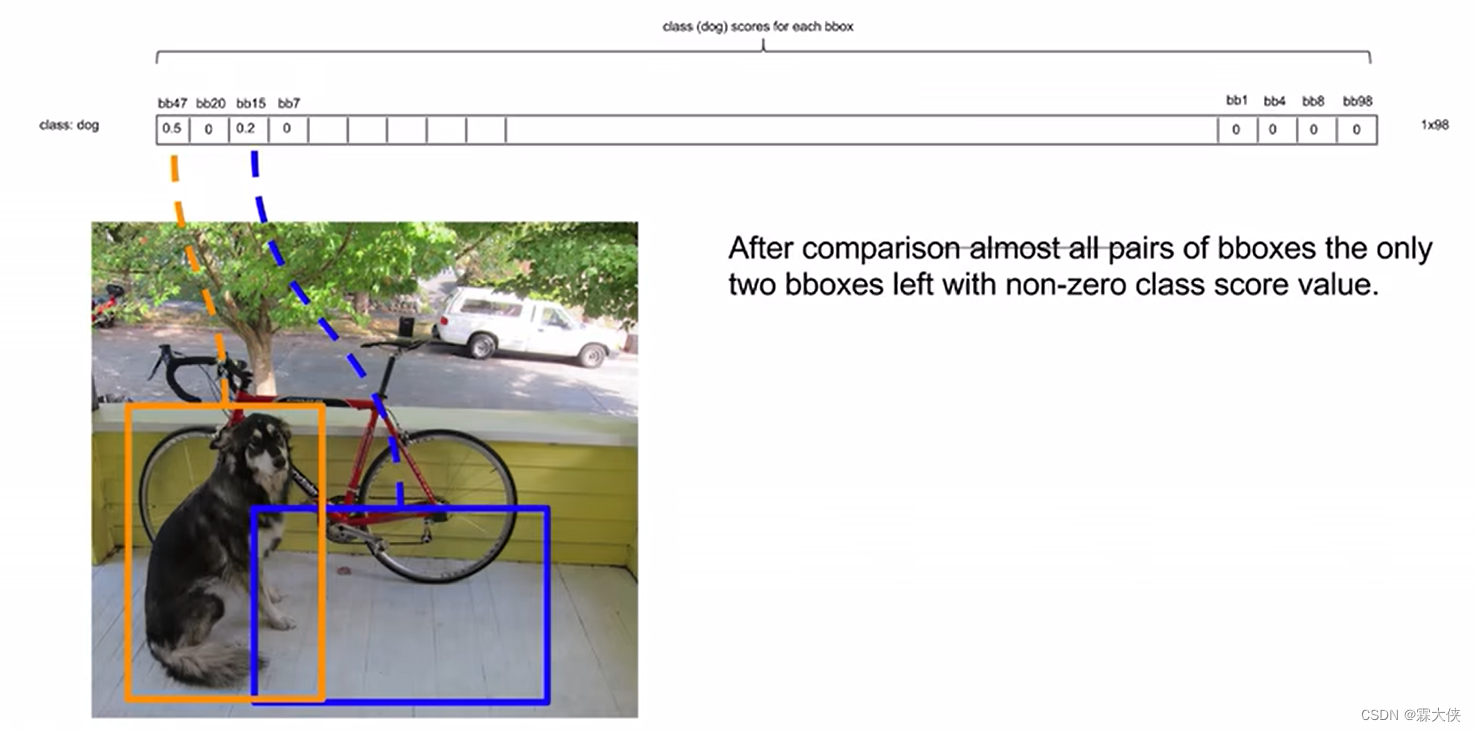
把所有框跟第一高的比对完了之后,再和第二高的框进行比对

最后就剩下了两个框
20个类别就进行20次非极大值抑制
三、训练阶段
已经人工的标注好了真实的框(ground truth),我们要让预测结果尽量拟合这个框,使得损失函数最小化。这个ground truth的中心点落到哪个grid cell的中心点处,就应该由该grid cell生成的bounding box来负责拟合ground truth。选择和ground truth的交并比较大的。

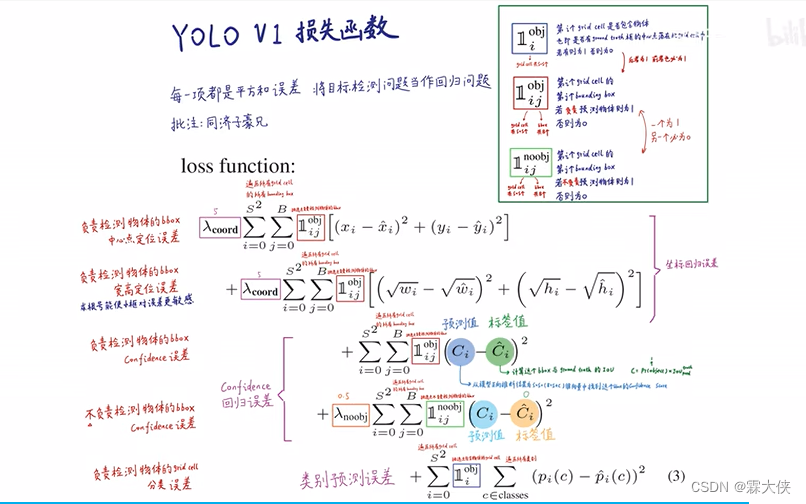
yolov1的损失函数