简略版本
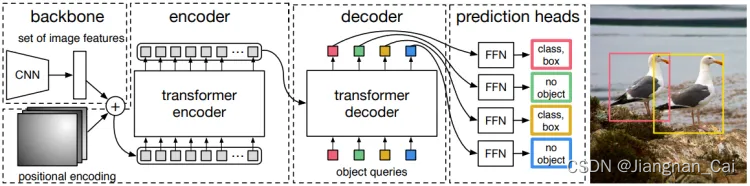
- Backbone:CNN backbone 学习图像的 2D 特征
- Positional Encoding:将 2D 特征展平,并对其使用位置编码(positional encoding)
- Encoder:经过 Transformer 的 encoder
- Decoder:encoder 的输出 + object queries 作为 Transformer 的 decoder 输入
- Prediction Heads:将 decoder 的每个输出都送到 FFN 去输出检测结果
细节版本
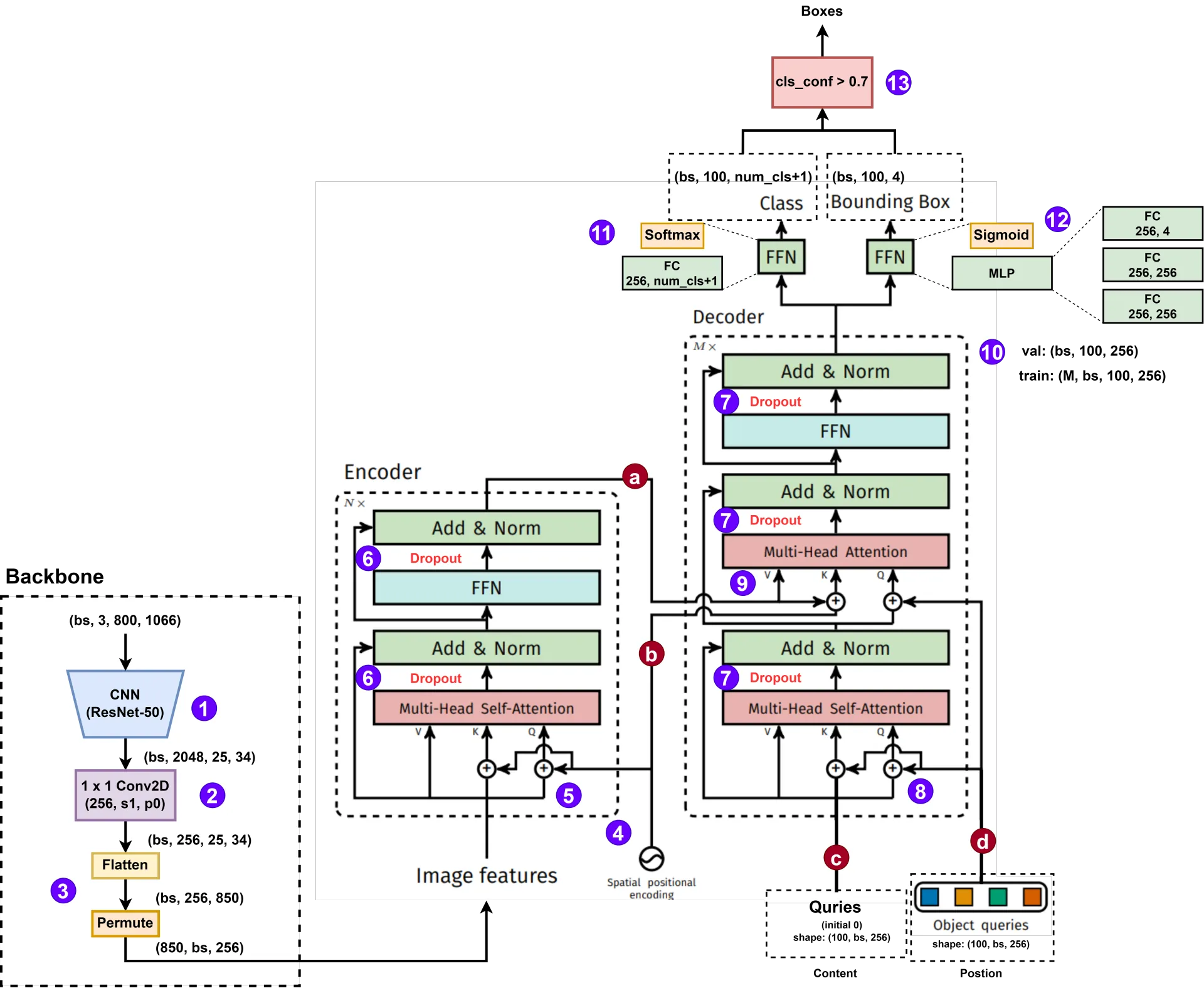
- Backbone:特征提取:CNN backbone 学习图像的 2D feature,输出 2048 个通道,32 倍下采样(输入为 ( C , H , W ) (C,H,W) (C,H,W) ,输出为 ( 2048 , H / 32 , W / 32 ) (2048, H/32,W/32) (2048,H/32,W/32) )
- Backbone:降维:通过一个 1 × 1 1 \times 1 1×1 的 Conv2D 卷积,将通道降为 256(为的是减少 Embedding 向量,即 token 的长度)。
- Backbone:展平:将 2D 特征展平,然后将展平的维度放置在第一个维度
- Encoding:位置编码(1):与普通的 Transformer 不同的地方在于,普通 Transformer 只需要在第一个 Encoder 的输入处进行一次位置编码即可,但是 DETR 这里,如果有 N N N 个 Encoder,则需要在 N N N 个 Encoder 输入的时候都要进行一次位置编码。官方代码的位置编码的生成有两种方式:(a)正弦位置编码;(b)可学习的位置编码;
- Encoding:位置编码(2): K = X P E ⋅ W K \mathbf{K} = \mathbf{X}_{PE}\cdot\mathbf{W}^K K=XPE⋅WK 和 Q = X P E ⋅ W Q \mathbf{Q} = \mathbf{X}_{PE}\cdot\mathbf{W}^Q Q=XPE⋅WQ 是通过经过位置编码处理的输入 X \mathbf{X} X 生成的;但是 V = X ⋅ W V \mathbf{V}=\mathbf{X}\cdot\mathbf{W}^V V=X⋅WV 的输入是没有经过位置编码的。
- Encoding:Dropout:在这两个部分都会先进行 Dropout 操作
Decoder 的 4 个输入:
a. Encoder Memory:也就是 Encoder 的输出,应该和输入是一样的维度,也就是 ( 850 , b s , 256 ) (850, bs, 256) (850,bs,256)。
b. Spatial positional encoding:空间位置编码,应该也是 256 维度的一维向量
c. Decoder received queries (Queries):表示内容信息 content(可理解为 label 信息),初始设置成 0,shape 是 100 × 256 100 \times 256 100×256。
d. Output positional encoding (object queries):输出位置编码,表示位置信息 position(可理解为 box 位置信息),shape 也是 100 × 256 100 \times 256 100×256。
- Decoding:Dropout:解码器部分的 Dropout,与编码器的部分一样。
- Decoding:位置编码:进入第一个多头注意力模块,与步骤 6 中的位置编码一样,进入第二个多头注意力模块,仅对上一个注意力的输出进行位置编码。
- Decoding:第二层多头注意力:假设 V \mathbf{V} V 和 K \mathbf{K} K 在不考虑 batchsize 的情况下都是 ( 850 , 256 ) (850, 256) (850,256),而 Q \mathbf{Q} Q 的维度是 ( 100 , 256 ) (100, 256) (100,256)。经过过头注意力机制之后,输出的维度和 Q \mathbf{Q} Q 一样,还是 ( 100 , 256 ) (100, 256) (100,256) 。
- Decoding:输出维度:分为验证和训练两种情况,在训练阶段,会将 M M M 个 decoder 模块 FNN 层后的接出来,放到辅助解码损失里,一起计算损失,实现深监督(deep supervise),验证阶段就直接输出一个 ( b s , 100 , 256 ) (bs, 100, 256) (bs,100,256) 的矩阵。
- Prediction heads:Class:分类头,通过一个 FC 全连接层接一个 Softmax 函数实现的 FFN。这里的
num_cls + 1多出来的一种分类是背景 background。 - Prediction heads:Bounding box:位置头,通过一个 MLP 网络,内含三个 FC 全连接层,结尾是 Sigmoid 函数进行归一化。
- 筛选:根据分类头得到的分类置信度和设定的阈值进行筛选,保留大于 0.7 的。