文章目录
- 关系运算
- 并(Union)
- 差(Difference)
- 交(Intersection)
- 笛卡尔积(Extended Cartesian Product)
- 投影(projection)
- 选择(Selection)
- 除(Division)
- 连接(join)
- 外连接(outer join)
- 聚集函数
- 元组演算
- 查询优化
关系运算
关系代数运算符有集合运算符、专门的关系运算符、算术比较符和逻辑运算符,如下:
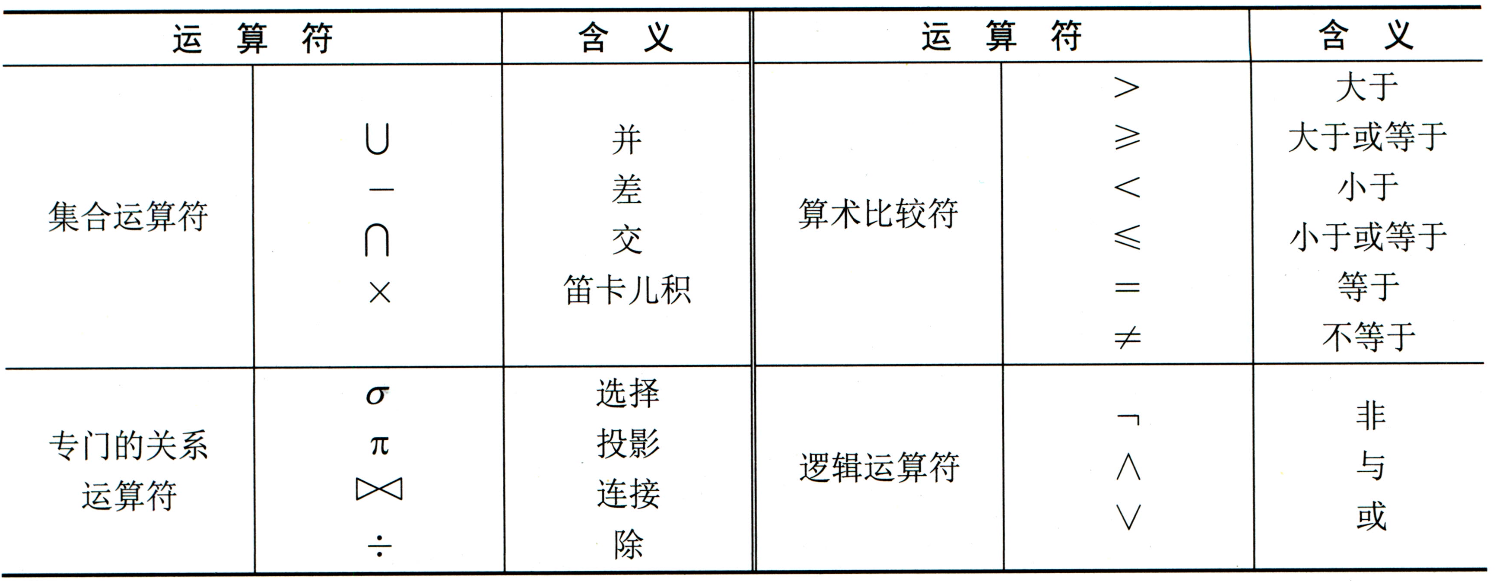
并(Union)
关系R与S的并由属于R或属于S的元组构成的集合组成,定义为 R ∪ S = { t ∣ t ∈ R ∨ t ∈ S } R\cup S=\{t|t\in R \vee t\in S\} R∪S={t∣t∈R∨t∈S},t为元组变量,R与S具有相同的关系模式(结构相同)。

等价SQL:
SELECT A,B,C FROM R
UNION
SELECT A,B,C FROM S;
差(Difference)
关系R与S的差由属于R但不属于S的元组构成的集合组成,定义为 R − S = { t ∣ t ∈ R ∧ t ∉ S } R - S=\{t|t\in R \wedge t\notin S\} R−S={t∣t∈R∧t∈/S},t为元组变量,R与S具有相同的关系模式(结构相同)。
等价SQL:
SELECT A,B,C FROM R
EXCEPT
SELECT A,B,C FROM S;
交(Intersection)
关系R与S的差由属于R同时又属于S的元组构成的集合组成,定义为 R ∩ S = { t ∣ t ∈ R ∧ t ∈ S } R \cap S=\{t|t\in R \wedge t\in S\} R∩S={t∣t∈R∧t∈S},t为元组变量,R与S具有相同的关系模式(结构相同)。也可以表示成 R ∩ S = R − ( R − S ) , 或者 R ∩ S = S − ( S − R ) R \cap S =R-(R-S), 或者R \cap S=S-(S-R) R∩S=R−(R−S),或者R∩S=S−(S−R)。

等价SQL:
SELECT A,B,C FROM R
INTERSECT
SELECT A,B,C FROM S;
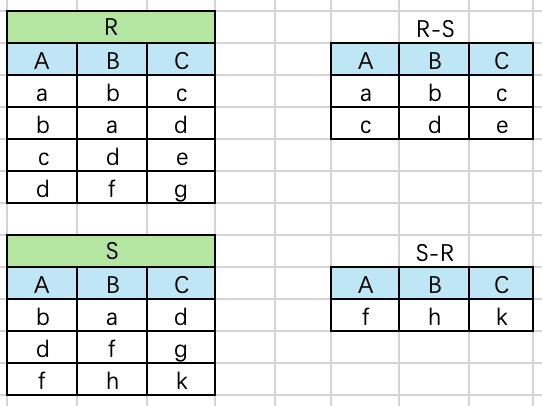
笛卡尔积(Extended Cartesian Product)
两个元数分别为n目和m目的关系R和S的广义笛卡尔积是一个(n+m)列的元组的集合。元组的前n列是关系R的一个元组,后m列是关系S的一个元组,形式定义 R × S = { t ∣ t = < t n , t m > ∧ t n ∈ R ∧ t m ∈ S } R \times S=\{t|t= < t^n,t^m > \wedge t^n\in R \wedge t^m \in S \} R×S={t∣t=<tn,tm>∧tn∈R∧tm∈S}。其中, < t n , t m > < t^n,t^m > <tn,tm>表示元组 t n 和 t m t_n和t^m tn和tm拼接成的一个元组,t为元组变量。
若R有 K 1 K_1 K1个元组,S有 K 2 K_2 K2个元组,则R和S的广义笛卡尔积有 K 1 × K 2 K_1 \times K_2 K1×K2个元组。
等价SQL:
SELECT * FROM R
CROSS JOIN S;
投影(projection)
投影是从垂直方向进行运算,在关系R中选择出若干属性列A组成新的关系,形式定义为 π A ( R ) = { t ∣ t [ A ] ∣ t ∈ S } \pi_A(R) =\{t|t[A]|t\in S\} πA(R)={t∣t[A]∣t∈S}。

等价SQL:
SELECT A,C FROM R;
选择(Selection)
选择运算是从关系的水平方向进行运算,是从关系R中选择满足给定条件的诸元组,形式定义为 σ F ( R ) = { t ∣ t ∈ R ∧ F ( t ) = T r u e } \sigma_F(R)=\{t|t\in R \wedge F(t)=True\} σF(R)={t∣t∈R∧F(t)=True}。
其中,F中的运算对象是属性名(或列的序号)或常数,运算符是算术比较符(<、≤、>、≥)和逻辑运算符( ∧ 、 ∨ 、 − \wedge、\vee、- ∧、∨、−)。例如, σ 1 ≥ 6 ( R ) \sigma_{1≥6}(R) σ1≥6(R)表示选取R关系中第1个属性值大于等于第6个属性值的元组; σ 1 > 6 ( R ) \sigma_{1>6}(R) σ1>6(R)表示选取R关系中第1个属性值大于6的元组。
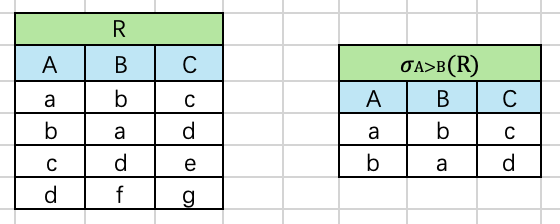
等价SQL:
SELECT A,B,C FROM R WHERE A>B;
除(Division)
除运算是同时从关系的水平方向和垂直方向进行运算。给定关系R(X,Y)和S(Y,Z),X、Y、Z为属性组。 R ÷ S R\div S R÷S应当满足元组在X上的分量值 x x x的象集 Y x Y_x Yx包含关系S在属性组Y上投影的集合。形式定义为 R ÷ S = { t n [ X ] ∣ t n ∈ R ∧ π y ( S ) ⊆ Y x R\div S=\{t_n[X]|t_n\in R \wedge \pi_y(S) \subseteq Y_x R÷S={tn[X]∣tn∈R∧πy(S)⊆Yx。
其中, Y x 为 x Y_x为x Yx为x在R的象集, x = t n [ X ] x=t_n[X] x=tn[X]。且 R ÷ S R\div S R÷S的结果集的属性组为X。
示例:已知R和S的关系,求 R ÷ S R\div S R÷S。
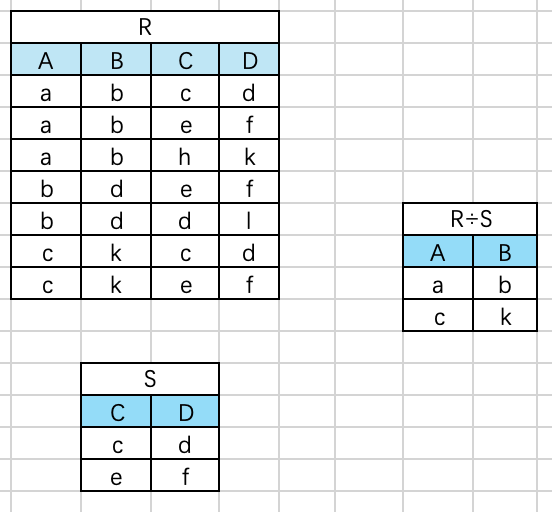
分析:根据定义,Y为属性CD,X为属性AB, R ÷ S R\div S R÷S应当满足元组在AB上的分量值 x x x的象集 Y x Y_x Yx包含关系S在属性组CD上投影的集合。关系S在Y上的投影为 π y ( S ) = { ( c , d ) , ( e , f ) } \pi_y(S)=\{(c,d),(e,f)\} πy(S)={(c,d),(e,f)},属性组X(即AB)可以取3个值 { ( a , b ) , ( b , d ) , ( c , k ) } \{(a,b),(b,d),(c,k)\} {(a,b),(b,d),(c,k)}
- 象集 C D ( a , b ) = { ( c , d ) , ( e , f ) , ( h , k ) } 象集CD_{(a,b)}=\{(c,d),(e,f),(h,k)\} 象集CD(a,b)={(c,d),(e,f),(h,k)}。
- 象集 C D ( b , d ) = { ( e , f ) , ( d , l ) } 象集CD_{(b,d)}=\{(e,f),(d,l)\} 象集CD(b,d)={(e,f),(d,l)}。
- 象集 C D ( c , k ) = { ( c , d ) , ( e , f ) } 象集CD_{(c,k)}=\{(c,d),(e,f)\} 象集CD(c,k)={(c,d),(e,f)}。
由于上述象集包含 π y ( S ) 有 { ( a , b ) } 和 { ( c , k ) } \pi_y(S)有\{(a,b)\}和\{(c,k)\} πy(S)有{(a,b)}和{(c,k)},所以 R ÷ S = { ( a , b ) , { ( c , k ) } R\div S=\{(a,b),\{(c,k)\} R÷S={(a,b),{(c,k)}$
连接(join)
- θ \theta θ连接
θ \theta θ连接是从R与S的笛卡尔积中选取属性间满足一定条件的元组,形式定义:
R ⋈ X θ Y S = { t ∣ t = < t n , t m > ∧ t n ∈ R ∧ t m ∈ S ∧ t n [ X ] θ t m [ Y ] } R \bowtie_{X\theta Y}S=\{t|t= < t^n,t^m > \wedge t^n \in R \wedge t^m \in S \wedge t^n[X] \theta t^m[Y]\} R⋈XθYS={t∣t=<tn,tm>∧tn∈R∧tm∈S∧tn[X]θtm[Y]}
其中, X θ Y X\theta Y XθY为连接的条件, θ \theta θ是比较运算符,X和Y分别为R和S上度数相等,且可比的属性组。 t n [ X ] t^n[X] tn[X]表示R中 t n t^n tn元组的对应于属性X的一个分量。 t n [ Y ] t^n[Y] tn[Y]表示R中 t m t^m tm元组的对应于属性Y的一个分量。
还可以表示为 R ⋈ X θ Y S = σ X θ Y ( R × S ) R \bowtie_{X\theta Y}S=\sigma_{X\theta Y}(R\times S) R⋈XθYS=σXθY(R×S)或者 R ⋈ i θ j S = σ i θ ( i + j ) ( R × S ) R \bowtie_{i\theta j}S=\sigma_{i\theta (i+j)}(R\times S) R⋈iθjS=σiθ(i+j)(R×S)。

等价SQL:
SELECT * FROM R
CROSS JOIN S
WHERE R.A<S.B;
- 等值连接
当 θ \theta θ为“=”时,称为等值连接,形式定义为 R ⋈ X = Y S = { t ∣ t = < t n , t m > ∧ t n ∈ R ∧ t m ∈ S ∧ t n [ X ] = t m [ Y ] } R \bowtie_{X= Y}S=\{t|t= < t^n,t^m > \wedge t^n \in R \wedge t^m \in S \wedge t^n[X] = t^m[Y]\} R⋈X=YS={t∣t=<tn,tm>∧tn∈R∧tm∈S∧tn[X]=tm[Y]}
- 自然连接
自然连接时一种特殊的等值连接,要求两个关系中进行比较的分量必须是相同的属性组,并且在结果集中将重复属性去掉。形式定义:
R ⋈ S = { t ∣ t = < t n , t m ∗ > ∧ t n ∈ R ∧ t m ∈ S ∧ S . B 1 = R . B 1 ∧ R . B 2 = S . B 2 ∧ . . . ∧ R . B n = S . B n } R \bowtie_S=\{t|t= < t^n,t^{m^\ast} > \wedge t^n \in R \wedge t^m \in S \wedge S.B_1=R.B_1\wedge R.B_2=S.B_2\wedge ... \wedge R.B_n=S.B_n \} R⋈S={t∣t=<tn,tm∗>∧tn∈R∧tm∈S∧S.B1=R.B1∧R.B2=S.B2∧...∧R.Bn=S.Bn}
其中 t n t_n tn表示关系R的元组变量, t m t_m tm表示关系S的元组变量。R和S具有相同的属性组B,且 B = ( B 1 , B 2 , . . . , B k ) B=(B_1,B_2,...,B_k) B=(B1,B2,...,Bk)。假定R的属性为 A 1 , A 2 , . . . , A n − k , B 1 , B 2 , . . . , B k A_1,A_2,...,A_{n-k},B_1,B_2,...,B_k A1,A2,...,An−k,B1,B2,...,Bk,假定S的属性为 B 1 , B 2 , . . . , B k , B k + 1 , B k + 2 , . . . , B m B_1,B_2,...,B_k,B_{k+1},B_{k+2},...,B_m B1,B2,...,Bk,Bk+1,Bk+2,...,Bm,S的元组变量去除重复属性B所组成新的元组为 t m ∗ t^{m^\ast} tm∗。

等价SQL:
SELECT R.A,R.B,R.C,R.D
FROM R,S
WHERE R.A=S.A AND R.C=S.C;
要求两个关系中进行比较的分量必须是相同的属性组并且在结果集中将重复属性列去掉。
外连接(outer join)
外连接是连接运算的扩展,可以处理缺失的信息。
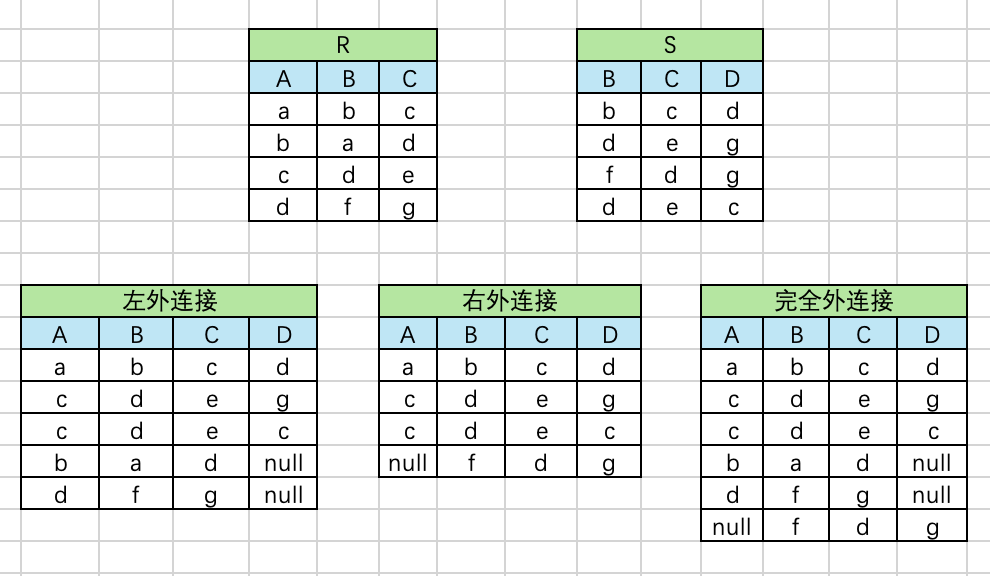
- 左外连接(left outer join)。取出左侧关系中所有与右侧关系中任一元组都不匹配的元组,用空值null填充所有来自右侧关系的属性。
等价SQL:
SELECT R.A,R.B,R.C,S.D
FROM R
LEFT JOIN S
ON R.B=S.B AND R.C=S.C;
- 右外连接(right outer join)。取出右侧关系中所有与左侧关系中任一元组都不匹配的元组,用空值null填充所有来自左侧关系的属性。
等价SQL:
SELECT R.A,S.B,S.C,S.D
FROM R
RIGHT JOIN S
ON R.B=S.B AND R.C=S.C;
- 完全外连接(full outer join)。完成左外连接和右外连接的操作。既填充左侧关系中所有与右侧关系中任一元组都不匹配的元组,又填充右侧关系中所有与左侧关系中任一元组都不匹配的元组,将产生的新元组加入自然连接的结果中。
等价SQL:
SELECT R.A,R.B,R.C,S.D
FROM R
LEFT JOIN S
ON R.B=S.B AND R.C=S.C
UNION
SELECT R.A,S.B,S.C,S.D
FROM R
RIGHT JOIN S
ON R.B=S.B AND R.C=S.C;
聚集函数
聚集函数输入一个值的集合,返回单一值作为结果。如集合12,4,6,8,10,15}。将聚集函数sum用于该集合时返回和45;将聚集函数avg用于该集合时返回平均值7.5;将聚集函数count用于该集合时返回集合中元数的个数6;将聚集函数min用于该集合时返回最小值2;将聚集函数max用于该集合时返回最大值15。
元组演算
表现形式为 { t ∣ P ( t ) } \{t|P(t)\} {t∣P(t)}。其中,t是元组变量, P ( t ) P(t) P(t) 是元组关系演算公式,公式是由原子公式组成的。
原子公式有如下三种形式:
- R ( t ) R(t) R(t)。R是关系名,t是元组变量,表示命题为“t是关系R的一个元组”。
- t [ i ] θ C 或 C θ t [ i ] t[i]\theta C 或C\theta t[i] t[i]θC或Cθt[i]。 t [ i ] t[i] t[i]表示元组变量t的第i个分量,C是常量, θ \theta θ为算术比较运算符。表示命题为“元组变量t的第i个分量与C直接满足 θ \theta θ运算“。如 t [ 3 ] < ′ 8 ′ t[3]<'8' t[3]<′8′表示t的第三个分量小于8。
- t [ i ] θ u [ j ] t[i]\theta u[j] t[i]θu[j]。t、u是两个元组变量,表示命题为“元组变量t的第i个分量与元组变量u的第j个分量直接满足 θ \theta θ运算”。如 t [ 2 ] ≥ u [ 4 ] t[2]\geq u[4] t[2]≥u[4]表示t的第二个分量大于等于u的第四个分量。
若一个公式中的一个元组变量前有全称量词 ∀ \forall ∀或存在量词 ∃ \exists ∃符号,则称该变量为约束变量,否则称之为自由变量。公式可递归定义:
- 原子公式是公式。
- 如果是 φ 1 \varphi_1 φ1和 φ 2 \varphi_2 φ2公式,那么, ¬ φ 1 、 φ 1 ∨ φ 2 、 φ 1 ∧ φ 2 、 φ 1 ⇒ φ 2 \lnot \varphi_1、\varphi_1 \vee \varphi_2、\varphi_1 \wedge \varphi_2、\varphi_1 \Rightarrow \varphi_2 ¬φ1、φ1∨φ2、φ1∧φ2、φ1⇒φ2 也都是公式。分别表示命题: ¬ φ 1 \lnot \varphi_1 ¬φ1表示“ φ 1 \varphi_1 φ1不是真“; φ 1 ∨ φ 2 \varphi_1 \vee \varphi_2 φ1∨φ2表示“ φ 1 \varphi_1 φ1或 φ 2 \varphi_2 φ2或 φ 1 和 φ 2 \varphi_1和\varphi_2 φ1和φ2为真”; φ 1 ∧ φ 2 \varphi_1 \wedge \varphi_2 φ1∧φ2表示“ φ 1 \varphi_1 φ1和 φ 2 \varphi_2 φ2都为真”; φ 1 ⇒ φ 2 \varphi_1 \Rightarrow \varphi_2 φ1⇒φ2表示“若 φ 1 \varphi_1 φ1为真则 φ 2 \varphi_2 φ2为真”。
- 如果是 φ 1 \varphi_1 φ1公式,那么, ∃ t ( φ 1 ) \exists t(\varphi_1) ∃t(φ1)是公式。表示命题为“若有一个t使 φ 1 \varphi_1 φ1为真,则 ∃ t ( φ 1 ) \exists t(\varphi_1) ∃t(φ1)为真,否则 ∃ t ( φ 1 ) \exists t(\varphi_1) ∃t(φ1)为假”。
- 如果是 φ 1 \varphi_1 φ1公式,那么, ∀ t ( φ 1 ) \forall t(\varphi_1) ∀t(φ1)是公式。表示命题为“若对所有t使 φ 1 \varphi_1 φ1为真,则 ∀ t ( φ 1 ) \forall t(\varphi_1) ∀t(φ1)为真,否则 ∀ t ( φ 1 ) \forall t(\varphi_1) ∀t(φ1)为假”。
公式中运算符优先级(低到高):算术比较运算符 θ \theta θ、 ∃ \exists ∃和 ∀ \forall ∀、 ¬ \lnot ¬、 ∧ \wedge ∧和 ∨ \vee ∨、 ⇒ \Rightarrow ⇒。加括号时,括号中的运算符优先。
关系代数转化为元组演算:
- 并。 R ∪ S = { t ∣ R ( t ) ∨ S ( t ) } R\cup S=\{t|R(t) \vee S(t)\} R∪S={t∣R(t)∨S(t)}
- 差。 R − S = { t ∣ R ( t ) ∧ ¬ S ( t ) } R - S=\{t|R(t) \wedge \lnot S(t)\} R−S={t∣R(t)∧¬S(t)}
- 笛卡尔积。 R × S = { t ∣ ( ∃ u ) ( ∃ v ) ( R ( u ) ∧ S ( v ) ∧ t [ 1 ] = u [ 1 ] ∧ . . . ∧ t [ n ] = u [ n ] ∧ t [ n + 1 ] = v [ 1 ] ∧ . . . ∧ t [ n + m ] = v [ m ] ) } R \times S=\{t|(\exists u)(\exists v)(R(u)\wedge S(v)\wedge t[1]=u[1]\wedge ... \wedge t[n]=u[n]\wedge t[n+1]=v[1]\wedge ... \wedge t[n+m]=v[m])\} R×S={t∣(∃u)(∃v)(R(u)∧S(v)∧t[1]=u[1]∧...∧t[n]=u[n]∧t[n+1]=v[1]∧...∧t[n+m]=v[m])}
- 投影。 π i 1 , i 2 , . . . , i k ( R ) = { t ∣ ( ∃ u ) ( R ( u ) ∧ t [ 1 ] = u [ i 1 ] ∧ t [ 2 ] = u [ i 2 ] ∧ . . . ∧ t [ k ] = u [ i k ] } \pi_{i_1,i_2,...,i_k}(R) =\{t|(\exists u)(R(u)\wedge t[1]=u[i_1]\wedge t[2]=u[i_2]\wedge ... \wedge t[k]=u[i_k]\} πi1,i2,...,ik(R)={t∣(∃u)(R(u)∧t[1]=u[i1]∧t[2]=u[i2]∧...∧t[k]=u[ik]}
- 选择。 σ F ( R ) = { t ∣ R ( t ) ∧ F } \sigma_F(R)=\{t|R(t) \wedge F\} σF(R)={t∣R(t)∧F}
查询优化
查询处理是从数据库中提取数据的一系列活动。
查询处理的代价:总代价=I/O代价+CPU代价+内存代价(多用户环境)。
查询优化:为查询选择最有效的查询计划的过程。
优化的准则:
- 提早执行选取运算。
- 合并乘积与其后的选择运算为连接运算。
- 将投影运算与其后的其他运算同时进行,以避免重复扫描关系。
- 将投影运算和其前后的二木运算结合起来,使得没有必要为去掉某些字段再扫描一遍关系。
- 在执行连接前对关系做适当的预处理,就能快速地找到要连接的元组。方法有两种:索引连接法、排序合并连接法。
- 存储公共子表达式。