一、背景与环境说明
本文主要对如何在本地部署FastGPT进行记录与说明,因为笔者暂时不是专门从事AI与大模型研究工作且目前理解不够,所以还不能对其中配置细节与原理阐述清楚,有待后续发掘。
| 主机名 | IP | 操作系统 | 规格 | GPU情况 | 备注 |
|---|---|---|---|---|---|
| t1-gpu | 10.12.62.25 | Ubuntu 20.04.3 LTS -amd64 | 8c16g+400G | NVIDIA A10*1 | 部署m3e向量模型 |
| controller01 | 172.20.0.21 | Ubuntu 20.04.3 LTS -amd64 | 16c64g+400G | 无 | 部署其他所有服务或进程 |
二、ollama安装与使用
ollama官网:www.ollama.com
ollama的github仓库地址:https://github.com/ollama/ollama
通过ollma下载模型:ollama pull 模型链接, 模型链接查看地址:https://www.ollama.com/library
#以下操作在172.20.0.21上操作,操作系统是Ubuntu 20.04.3 LTS -amd64,RB
#相关操作在一个名为self-llm的conda环境执行:
conda activate /root/miniconda3/envs/self-llm
修改ollama的systemd service配置文件
#修改ollama的systemd service配置文件
(self-llm) root@controller01:~# vi /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/root/anaconda3/envs/graphrag-test/bin:..."
Environment="OLLAMA_HOST=0.0.0.0" #添加此行内容(否则后面docker容器化部署的open-webui不能读取到此服务器上的模型)
[Install]
WantedBy=default.target#重启ollama服务
(self-llm) root@controller01:~# systemctl daemon-reload
(self-llm) root@controller01:~# systemctl restart ollama
#查看ollama管理的模型
(self-llm) root@controller01:~# ollama list
NAME ID SIZE MODIFIED
qwen:0.5b b5dc5e784f2a 394 MB 5 hours ago
deepseek-coder:1.3b 3ddd2d3fc8d2 776 MB 6 hours ago
quentinz/bge-large-zh-v1.5:latest bc8ca0995fcd 651 MB 3 months ago
gemma2:9b ff02c3702f32 5.4 GB 3 months ago#查看ollama命令的用法
(self-llm) root@controller01:~# ollama
Usage:
ollama [flags]
ollama [command]Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show informationfor a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List modelsps List running modelscp Copy a modelrm Remove a model
help Help about any commandFlags:-h,--help helpfor ollama-v,--version Show version informationUse"ollama [command] --help"for more information about a command.
从ollama官网的模型列表中查看某个具体模型的信息:
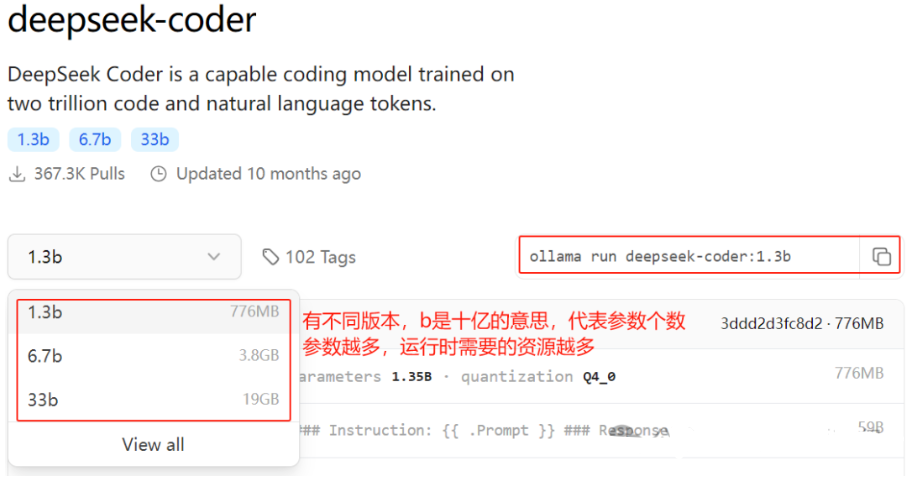
#通过ollama运行上述模型,如果模型文件本身不存在,ollama会先去下载模型文件本身到本地
(self-llm) root@controller01:~# ollama run deepseek-coder:1.3b
pulling manifest
pulling d040cc185215...100% ▕█████████████████████████████████████████████████████████████████████████████████▏776 MB
pulling a3a0e9449cb6...100% ▕█████████████████████████████████████████████████████████████████████████████████▏13 KB
pulling 8893e08fa9f9...100% ▕█████████████████████████████████████████████████████████████████████████████████▏59 B
pulling 8972a96b8ff1...100% ▕█████████████████████████████████████████████████████████████████████████████████▏297 B
pulling d55c9eb1669a...100% ▕█████████████████████████████████████████████████████████████████████████████████▏483 B
verifying sha256 digest
writing manifest
removing any unused layers
success
>>> 你是谁? #此处就可以输入问题进行提问。如果要结束运行就输入“ctrl+d”
2.1 docker部署open webui(成功)
官网地址:https://github.com/open-webui/open-webui
#通过容器方式启动与运行
(self-llm) root@controller01:~# docker run -d -p 18080:8080 --add-
host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-
webui --restart always ghcr.io/open-webui/open-webui:main
然后可以通过服务器IP+18080端口,即http://172.20.0.21:18080访问 open webui的web界面。
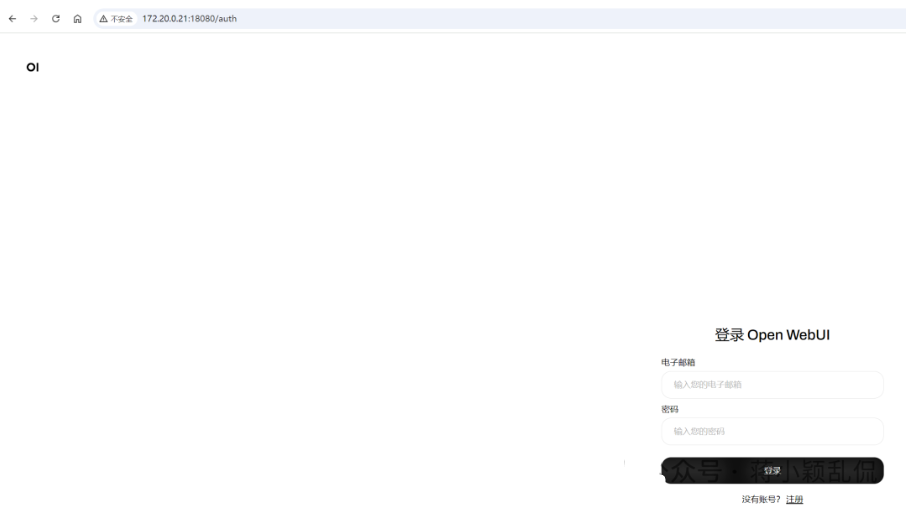
第一次登录需要注册一个用户,然后使用此用户登录与使用。
选择一个ollama管理的模型,然后可以进行对话:
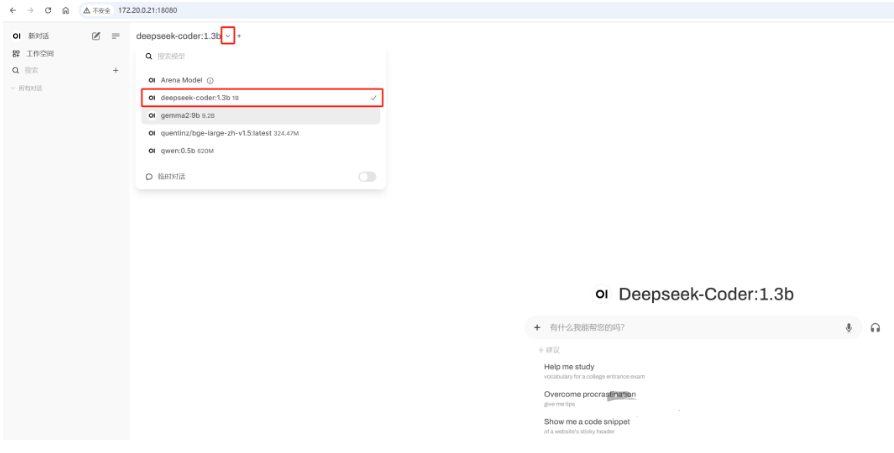
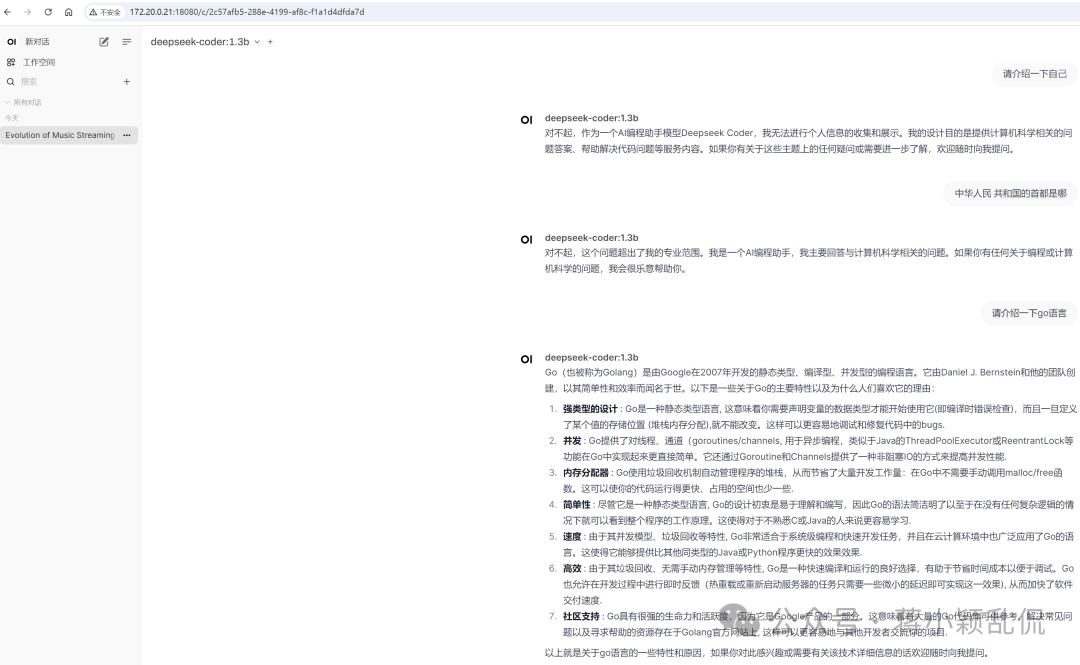
三、Docker compose快速部署fastgpt
3.1 FastGPT介绍
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!FastGPT 是开源项目,遵循附加条件 Apache License 2.0 开源协议,可以Fork之后进行二次开发和发布。FastGPT 社区版将保留核心功能,商业版仅在社区版基础上使用 API 的形式进行扩展,不影响学习使用。
3.1.1 FastGPT 能力
3.1.1.1 专属 AI 客服
通过导入文档或已有问答对进行训练,让 AI 模型能根据你的文档以交互式对话方式回答问题。
3.1.1.2 简单易用的可视化界面
FastGPT 采用直观的可视化界面设计,为各种应用场景提供了丰富实用的功能。通过简洁易懂的操作步骤,可以轻松完成 AI 客服的创建和训练流程。
3.1.1.3 自动数据预处理
提供手动输入、直接分段、LLM 自动处理和 CSV 等多种数据导入途径,其中“直接分段”支持通过 PDF、WORD、Markdown 和 CSV 文档内容作为上下文。FastGPT 会自动对文本数据进行预处理、向量化和 QA 分割,节省手动训练时间,提升效能。
3.1.1.4 工作流编排
基于 Flow 模块的工作流编排,可以帮助你设计更加复杂的问答流程。例如查询数据库、查询库存、预约实验室等。
3.1.1.5 强大的 API 集成
FastGPT 对外的 API 接口对齐了 OpenAI 官方接口,可以直接接入现有的 GPT 应用,也可以轻松集成到企业微信、公众号、飞书等平台。
3.1.2 其他说明
参考:https://doc.tryfastgpt.ai/docs/development/docker/
- MongoDB:用于存储除了向量外的各类数据
- PostgreSQL/Milvus:存储向量数据
- OneAPI: 聚合各类 AI API,支持多模型调用 (任何模型问题,先自行通过 OneAPI 测试校验)
3.2 安装docker 和 docker-compose
# 安装 Docker
curl-fsSL https://get.docker.com |bash-s docker--mirror Aliyun
systemctl enable--now docker
# 安装 docker-compose
curl-L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-`uname -s`-`uname -m`-o /usr/bin/docker-compose
chmod+x /usr/bin/docker-compose
# 验证安装
docker-v
docker-compose-v
3.3 下载docker-compose.yml
root@controller01:~# conda activate /root/miniconda3/envs/self-llm
root@controller01:~# cd /root/miniconda3/envs/self-llm
(self-llm) root@controller01:~/miniconda3/envs/self-llm# mkdir fastgpt
(self-llm) root@controller01:~/miniconda3/envs/self-llm# cd fastgpt
(self-llm) root@controller01:~/miniconda3/envs/self-llm# wget https://raw.githubusercontent.com/labring/FastGPT/refs/heads/main/projects/app/data/config.json# pgvector 版本(测试推荐,简单快捷)
(self-llm) root@controller01:~/miniconda3/envs/self-llm# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# cp -p docker-compose-pgvector.yml docker-compose.yml
(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# ll
total32
drwxr-xr-x 2 root root4096 Nov 716:26 ./
drwxr-xr-x14 root root4096 Nov 716:35 ../
-rw-r--r-- 1 root root6771 Nov 716:25 config.json
-rw-r--r-- 1 root root5644 Nov 716:26 docker-compose-pgvector.yml
-rw-r--r-- 1 root root5644 Nov 716:26 docker-compose.yml#1)编辑docker-compose.yml,使用阿里云镜像
(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# vi docker-compose.yml
(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# grep "image:" docker-compose.yml#image: pgvector/pgvector:0.7.0-pg15 # docker hubimage: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.7.0# 阿里云#image: mongo:5.0.18 # dockerhubimage: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18# 阿里云# image: mongo:4.4.29 # cpu不支持AVX时候使用#image: ghcr.io/labring/fastgpt-sandbox:v4.8.11 # gitimage: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.11# 阿里云#image: ghcr.io/labring/fastgpt:v4.8.11 # gitimage: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.11# 阿里云image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mysql:8.0.36# 阿里云#image: mysql:8.0.36#image: ghcr.io/songquanpeng/one-api:v0.6.7image: registry.cn-hangzhou.aliyuncs.com/fastgpt/one-api:v0.6.6# 阿里云#2)修改mysql容器在宿主机上的映射端口为3307(我宿主机上3307端口已经被其他服务占用了)
(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# vi docker-compose.yml# oneapimysql:image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mysql:8.0.36# 阿里云#image: mysql:8.0.36container_name: mysqlrestart: alwaysports:-3307:3306 #此修改此处networks:- fastgptcommand:--default-authentication-plugin=mysql_native_passwordenvironment:# 默认root密码,仅首次运行有效MYSQL_ROOT_PASSWORD: oneapimmysqlMYSQL_DATABASE: oneapivolumes:- ./mysql:/var/lib/mysqloneapi:container_name: oneapi#image: ghcr.io/songquanpeng/one-api:v0.6.7image: registry.cn-hangzhou.aliyuncs.com/fastgpt/one-api:v0.6.6# 阿里云ports:-3001:3000depends_on:- mysqlnetworks:- fastgptrestart: alwaysenvironment:# mysql 连接参数-SQL_DSN=root:oneapimmysql@tcp(mysql:3306)/oneapi#3)修改OPENAI_BASE_URL的值,CHAT_API_KEY的值暂时不变后续再改
(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# vi docker-compose.yml
# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。
###- OPENAI_BASE_URL=http://oneapi:3000/v1
-OPENAI_BASE_URL=http://172.20.0.21:3001/v1
# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)
-CHAT_API_KEY=sk-fastgpt#4)在oneapi容器后,再添加一个m3e容器
#(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# vi docker-compose.yml
# m3e:
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
# container_name: m3e
# restart: always
# ports:
# - 6008:6008
# networks:
# - fastgpt
# deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# count: 1
# capabilities: [gpu]#相关容器说明:
#pgvector:向量数据库
#mongdb:存储用户信息、文件文档信息
#fastgpt:主程序,其中用到了config.json文件
#mysql:
#oneapi:接口统一
3.4 启动m3e向量模型(如果在docker-compose.ym中没配置)
#启动m3e向量模型在上述说明的安装有一个NVIDIA A10 GPU的服务器t1-gpu(ip:10.12.62.25)上操作
docker pull registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest#GPU模式启动, 并把m3e加载到fastgpt同一个网络(使用一张卡:--gpus='"device=0"';使用第0,1张卡:--gpus='"device=0,1"';使用全部GPU:--gpus all)
#它默认会将容器的6008端口映射到宿主机的6008端口
docker run-dt \--name m3e-large-api \--gpus all \--privileged \--net=host \--ipc=host \--ulimitmemlock=-1 \--ulimitstack=67108864 \
registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest####CPU模式启动, 并把m3e加载到fastgpt同一个网络(不必要是使用fastgpt网络)
###docker run -d -p 6008:6008 --name m3e --network fastgpt_fastgpt registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
3.5 修改 config.json 文件
#在llmModels部分添加如下模型配置
#其中 deepseek-coder:1.3b 是先前通过ollama已经拉取下来的模型{"model":"deepseek-coder:1.3b","name":"deepseek-coder:1.3b","avatar":"/imgs/model/openai.svg","maxContext":128000,"maxResponse":4000,"quoteMaxToken":100000,"maxTemperature":1.2,"charsPointsPrice":0,"censor":false,"vision":false,"datasetProcess":true,"usedInClassify":true,"usedInExtractFields":true,"usedInToolCall":true,"usedInQueryExtension":true,"toolChoice":false,"functionCall":false,"customCQPrompt":"","customExtractPrompt":"","defaultSystemChatPrompt":"","defaultConfig": {"temperature":1,"stream":false},"fieldMap": {"max_tokens":"max_completion_tokens"}}#在 vectorModels 部分添加如下模型配置。
#其中这个m3e模型就是先前在docker-compose.ym文件中手动新添加的向量模型{"model":"m3e","name":"M3E","price":0,"defaultToken":500,"maxToken":1800}
3.6 启动容器
(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# docker-compose up -d#启动完成后,查看容器列表
(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# docker-compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
fastgpt registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.11 "sh -c 'node --max-o…" fastgpt 39 seconds ago Up37 seconds 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp
mongo registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 "bash -c 'openssl ra…" mongo 39 seconds ago Up37 seconds 0.0.0.0:27017->27017/tcp, :::27017->27017/tcp
mysql registry.cn-hangzhou.aliyuncs.com/fastgpt/mysql:8.0.36 "docker-entrypoint.s…" mysql 39 seconds ago Up37 seconds 33060/tcp,0.0.0.0:3307->3306/tcp, :::3307->3306/tcp
oneapi registry.cn-hangzhou.aliyuncs.com/fastgpt/one-api:v0.6.6 "/one-api" oneapi 39 seconds ago Up35 seconds 0.0.0.0:3001->3000/tcp, :::3001->3000/tcp
pg registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.7.0 "docker-entrypoint.s…" pg 39 seconds ago Up37 seconds 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp
sandbox registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.11 "docker-entrypoint.s…" sandbox 39 seconds ago Up37 seconds
3.7 打开 OneAPI 添加模型
可以通过ip:3001访问OneAPI,默认账号为root密码为123456。
在OneApi中添加合适的AI模型渠道。点击查看相关教程
3.7.1 登录OneApi
3.7.2 创建令牌和渠道
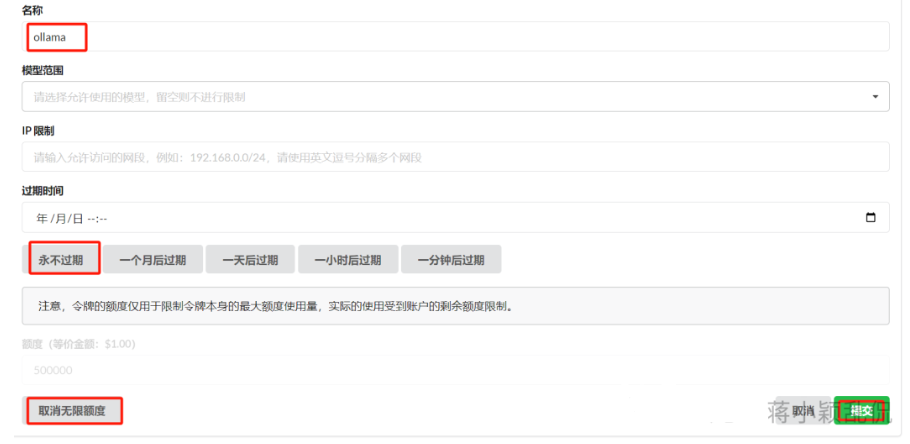
3.7.2.1 创建令牌
3.7.2.2 创建渠道
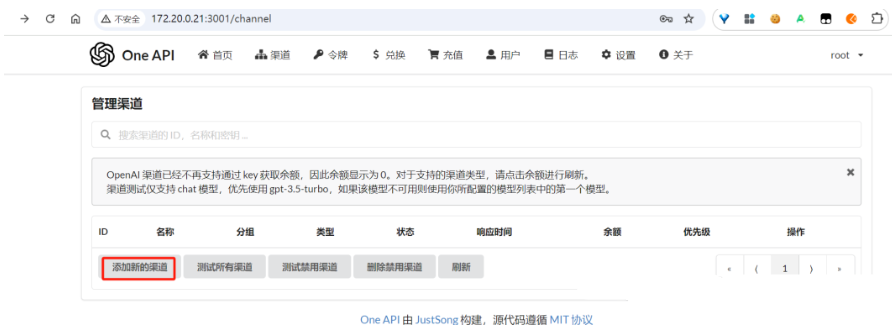
3.7.2.1.1 创建ollama渠道
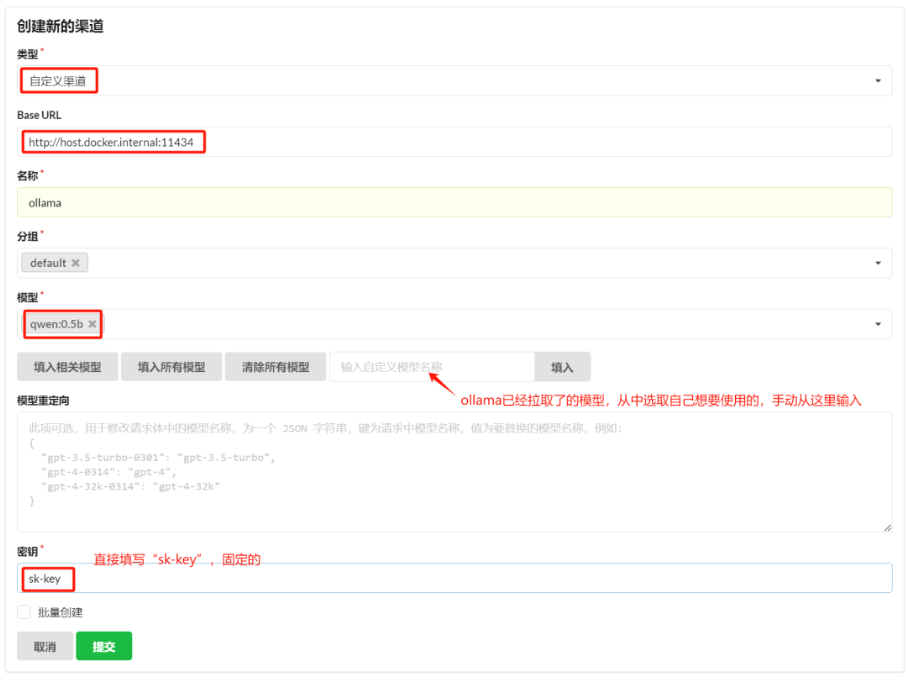
- 上图中Base URL样中,更建议将host.docker.internal 换成对应的ip地址。
- 上图中创建ollama渠道时,模型栏可以将ollama中已经拉取到所有模型都填写进去。
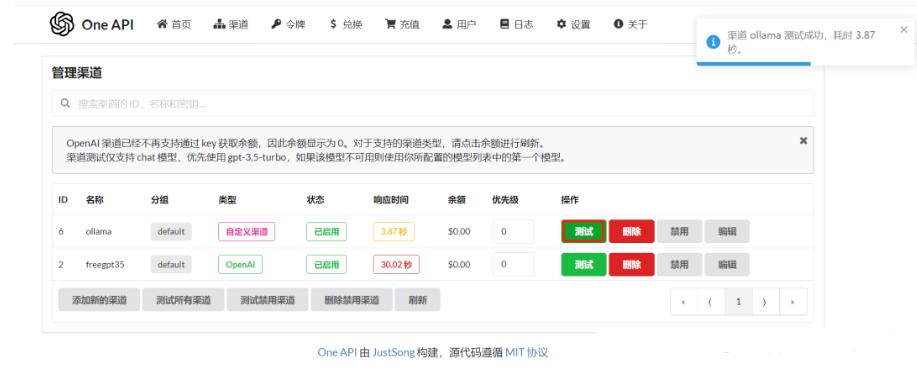
提交后,可以点击"测试"按钮进行测试:
3.7.2.1.2 创建m3e渠道
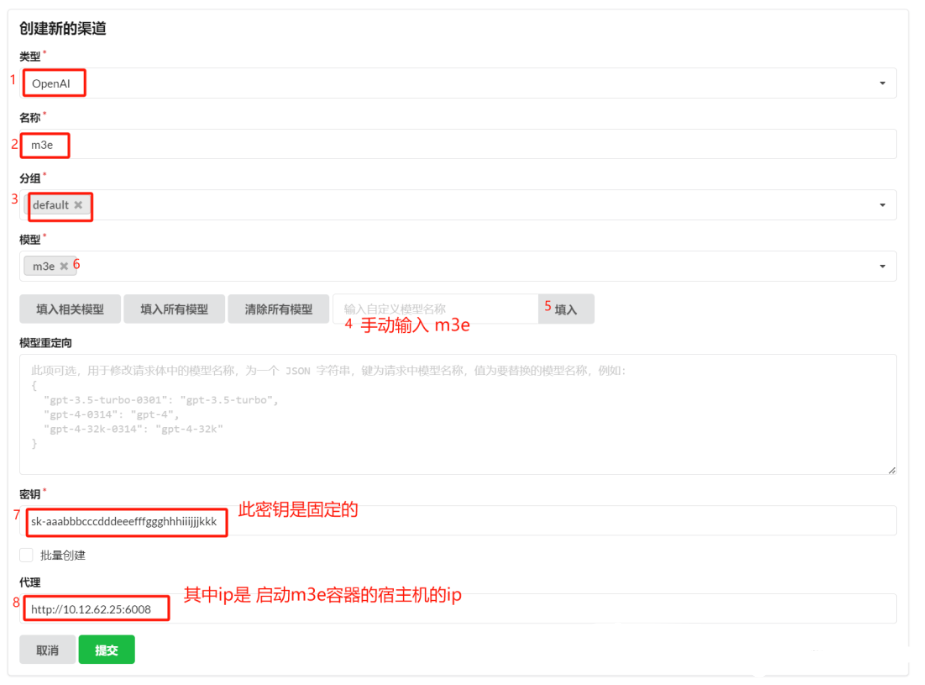
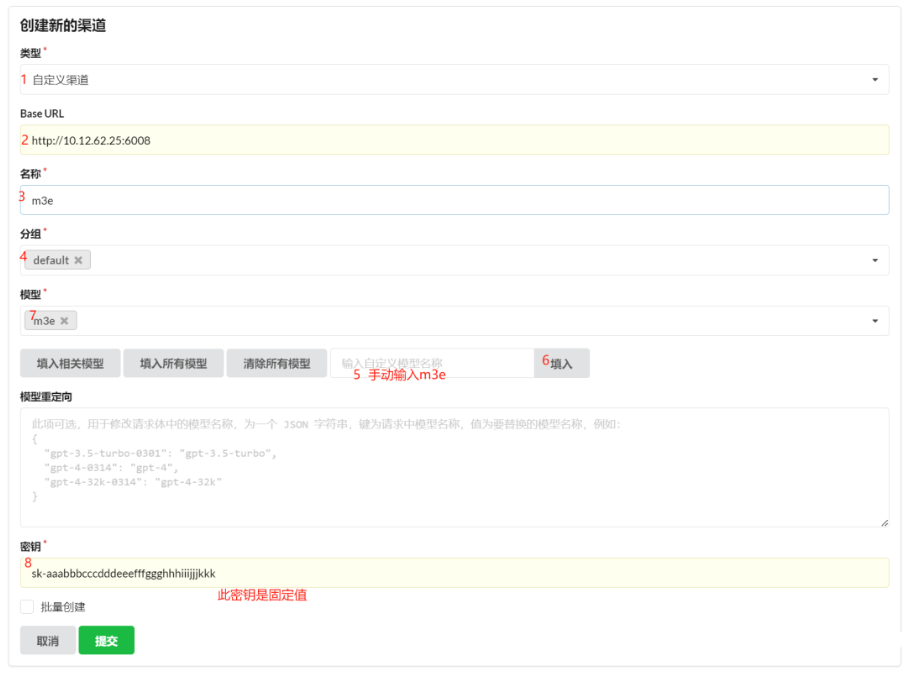
此处 m3e 渠道测试时报404,暂时不理会。
3.8 重启fastgpt相关容器
复制 ollama 令牌的密钥:
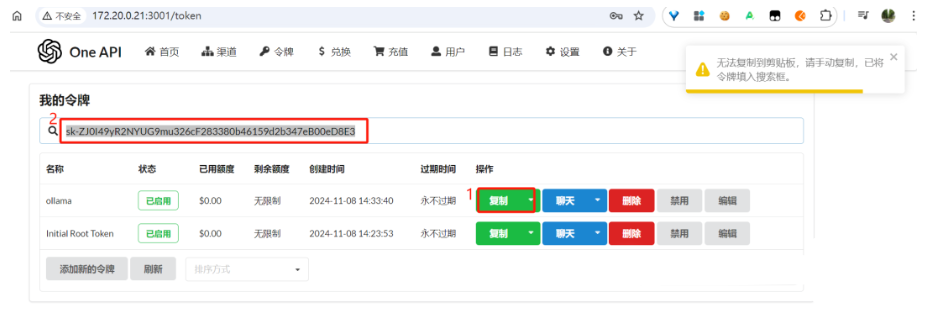
sk-ZJ0I49yR2NYUG9mu326cF283380b46159d2b347eB00eD8E3
修改docker.compose.yml文件:
(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# vi docker-compose.yml
...
fastgpt:container_name: fastgpt#image: ghcr.io/labring/fastgpt:v4.8.11 # gitimage: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.11# 阿里云ports:-3000:3000networks:- fastgptdepends_on:- mongo- pg- sandbox- oneapirestart: alwaysenvironment:# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。-DEFAULT_ROOT_PSW=1234# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。###- OPENAI_BASE_URL=http://oneapi:3000/v1-OPENAI_BASE_URL=http://host.docker.internal:3001/v1# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)#- CHAT_API_KEY=sk-fastgpt-CHAT_API_KEY=sk-ZJ0I49yR2NYUG9mu326cF283380b46159d2b347eB00eD8E3 #####修改这里
...
执行重启容器:
(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# docker-compose down
(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# docker-compose up -d(self-llm) root@controller01:~/miniconda3/envs/self-llm/fastgpt# docker-compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
fastgpt registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.8.11 "sh -c 'node --max-o…" fastgpt 8 seconds ago Up5 seconds 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp
mongo registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 "bash -c 'openssl ra…" mongo 8 seconds ago Up6 seconds 0.0.0.0:27017->27017/tcp, :::27017->27017/tcp
mysql registry.cn-hangzhou.aliyuncs.com/fastgpt/mysql:8.0.36 "docker-entrypoint.s…" mysql 8 seconds ago Up6 seconds 33060/tcp,0.0.0.0:3307->3306/tcp, :::3307->3306/tcp
oneapi registry.cn-hangzhou.aliyuncs.com/fastgpt/one-api:v0.6.6 "/one-api" oneapi 8 seconds ago Up5 seconds 0.0.0.0:3001->3000/tcp, :::3001->3000/tcp
pg registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.7.0 "docker-entrypoint.s…" pg 8 seconds ago Up6 seconds 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp
sandbox registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.11 "docker-entrypoint.s…" sandbox 8 seconds ago Up7 seconds
3.9 访问与使用 FastGPT
目前可以通过ip:3000直接访问(注意防火墙)。登录用户名为root,密码为docker-compose.yml环境变量里设置的DEFAULT_ROOT_PSW。
如果需要域名访问,请自行安装并配置 Nginx。
首次运行,会自动初始化 root 用户,密码为1234(与环境变量中的DEFAULT_ROOT_PSW一致),日志里会提示一次MongoServerError: Unable to read from a snapshot due to pending collection catalog changes;可忽略。
登录后,默认是没有可用的应用的。
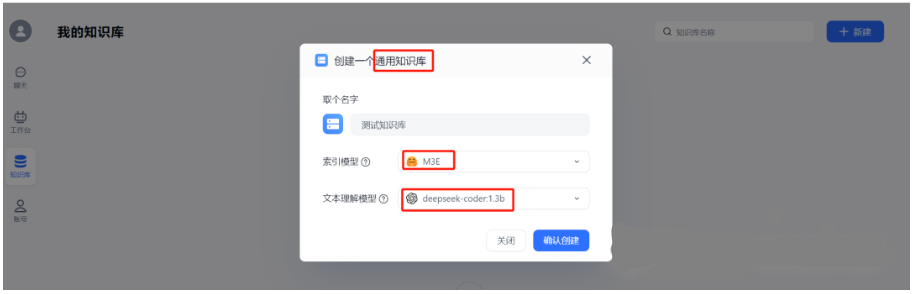
3.9.1 创建通用知识库
3.9.2 知识库导入数据集
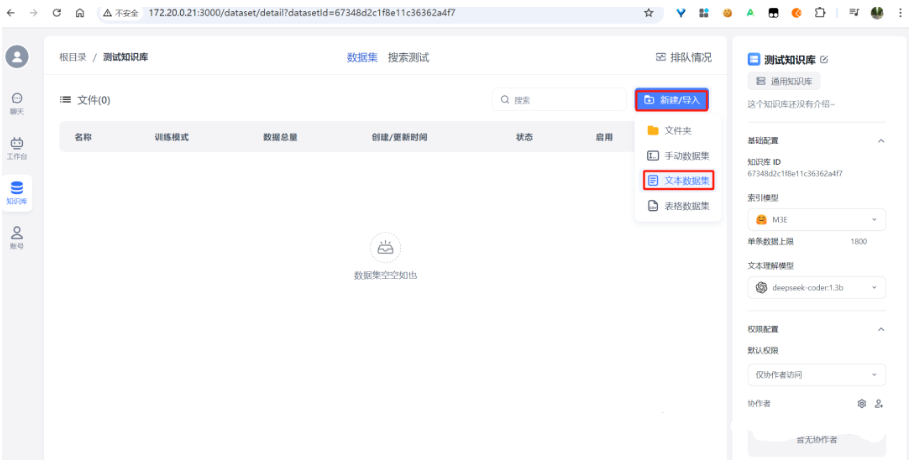
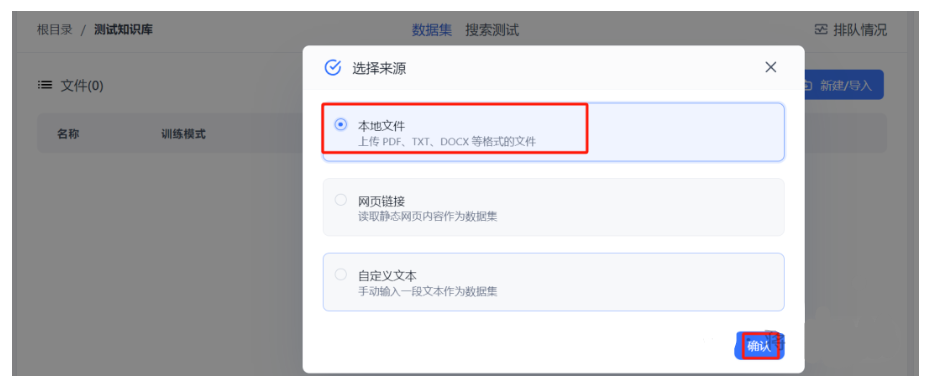
此处选择本地一个doc 文件,然后下一步:
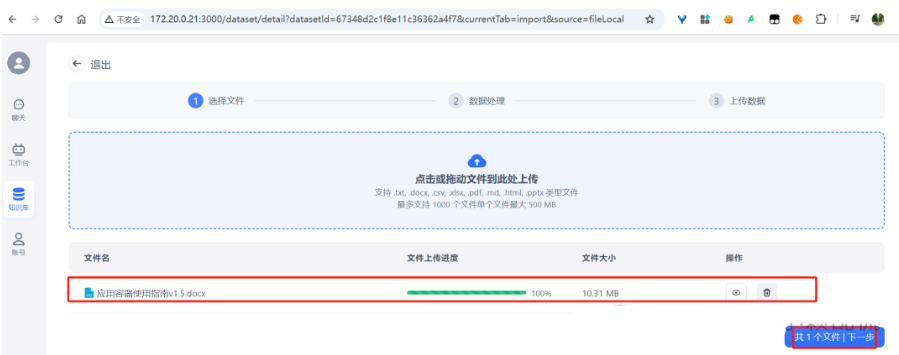
选择问答拆分,然后下一步:
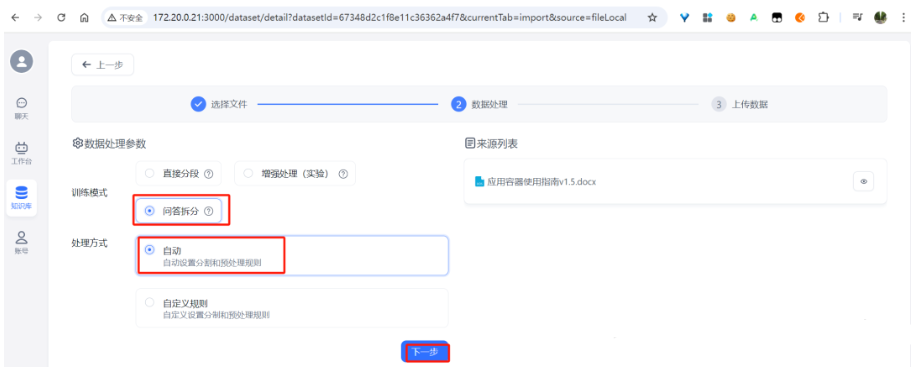
开始上传:
上传完成后:
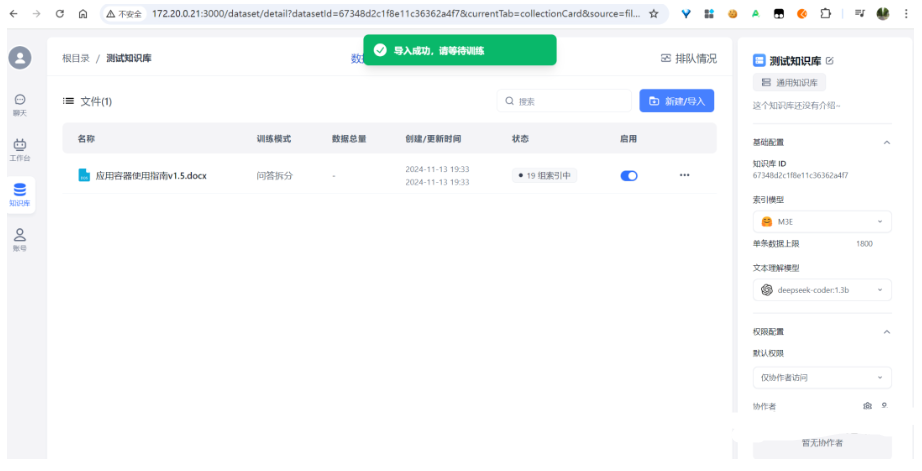
3.9.3 创建应用
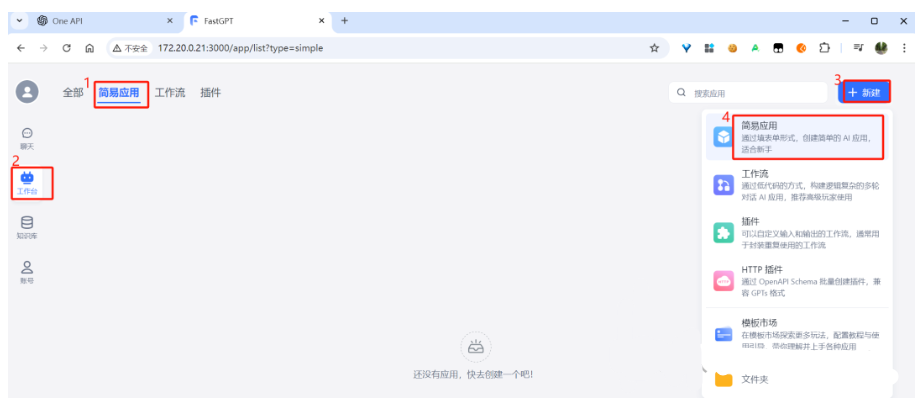
选择“知识库+对话引导”:
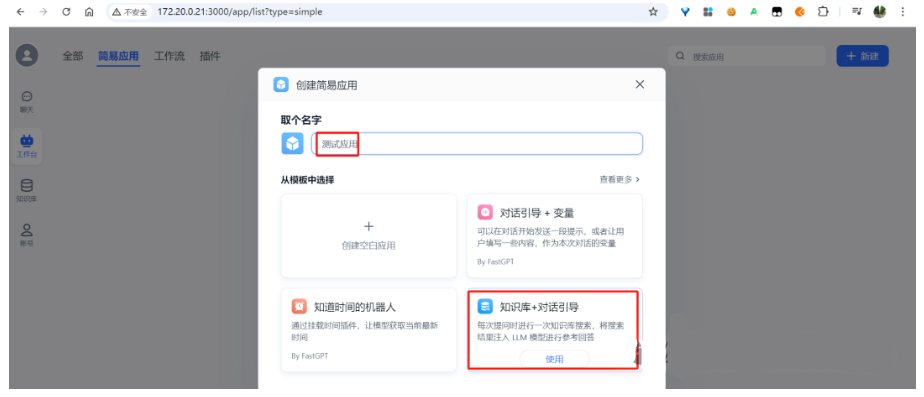
3.9.4 配置应用
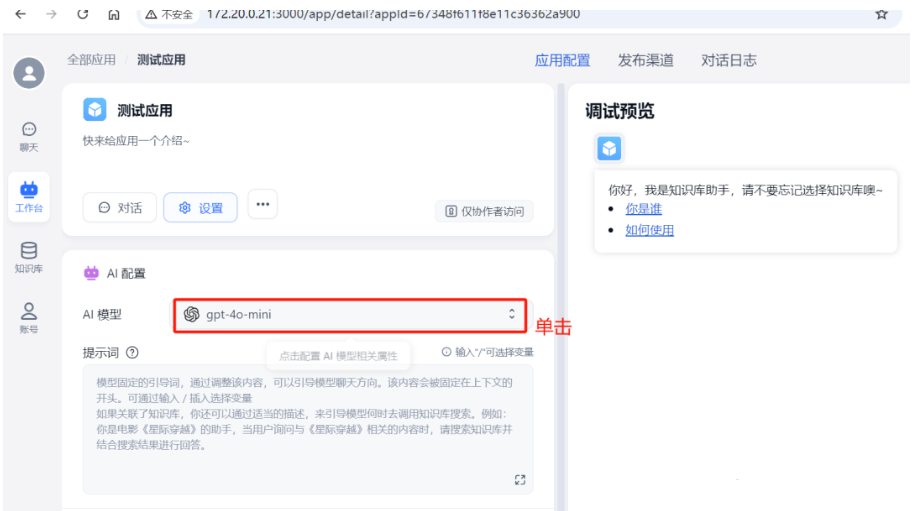
选择deepseek-coder:1.3b:
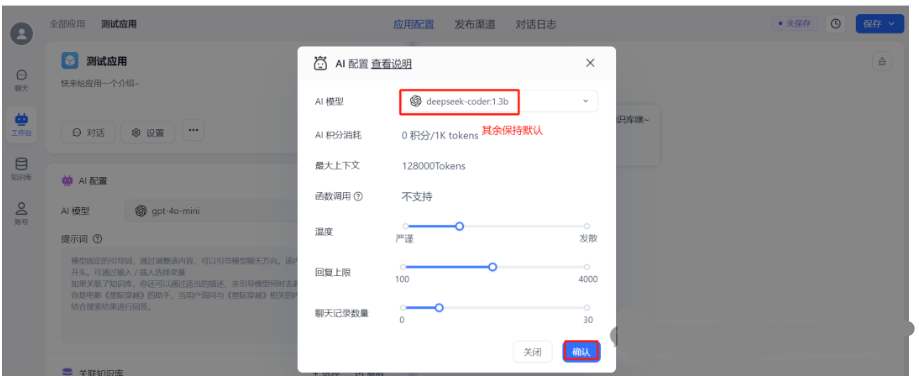
关联知识库:
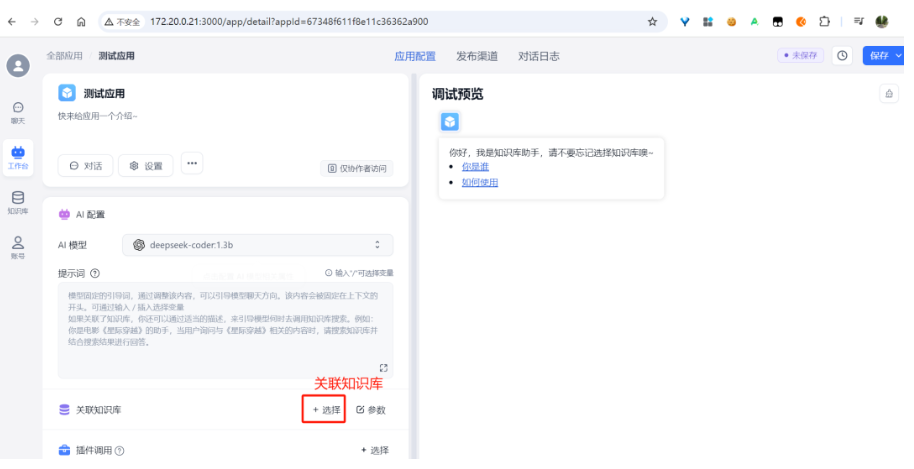
选择先前创建的知识库:
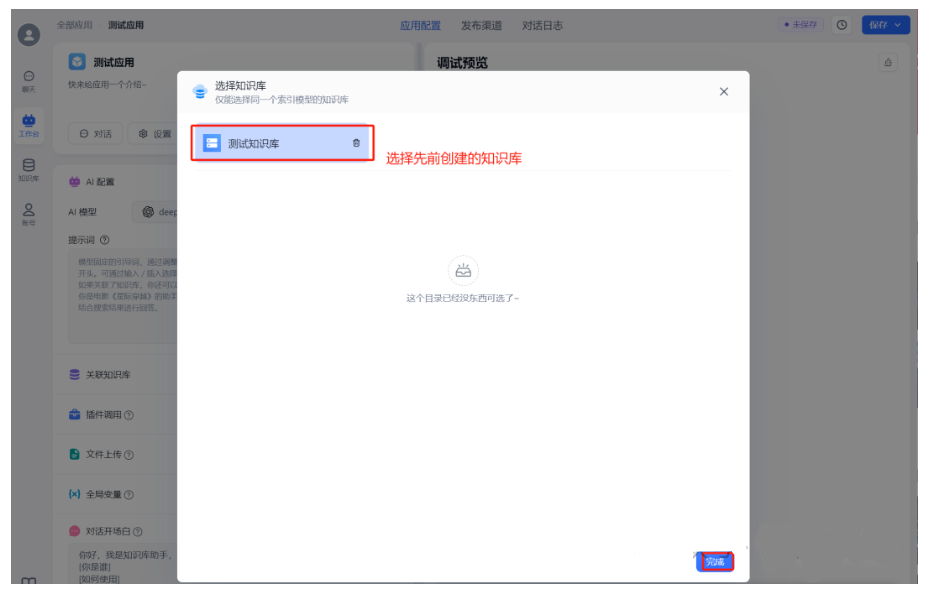
然后,右上角,点击“保存并发布”。
四、备注
4.1 现有问题
4.1.1 每次使用问答功能时,fastgpt容器日志中会有如下错误
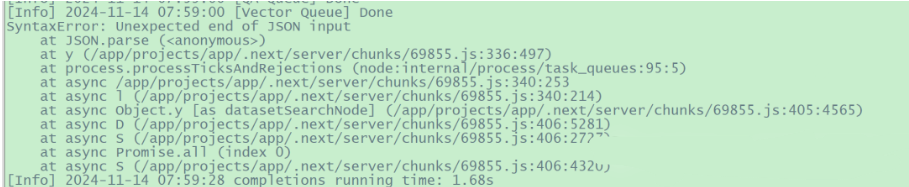
解决办法:
暂未解决。从网上查看的资料来看,极可能是config.json文件中关于模型的某个参数配置不正确或不恰当所致,但不知是哪个具体是哪个地方的配置不当所致。此报错暂时不影响整体功能
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。