主要内容:
部署Dashboard、部署Prometheus、部署HPA集群
一、Dashboard介绍
Dashboard是基于网页的Kubernetes用户界面,可以使用Dashboard将容器应用部署到Kubernetes集群中,也可以对容器应用排错,还能管理集群资源。可以使用Dashboard获取运行在集群中的应用的概览信息,也可以创建或者修改Kubernetes资源(如:Deployment、Job、DaemonSet等)
Dashboard同时展示了Kubernetes集群中的资源状态信息和所有报错信息。
官网下载软件包:GitHub - kubernetes/dashboard: General-purpose web UI for Kubernetes clusters
Dashboard安装流程:
① 下载镜像及资源文件(dashboard.tar.gz、metrics-scraper.tar.gz、recommended.yaml)
② 导入镜像,并上传到私有仓库
补充:Kubernetes Dashboard从v2.0.0-beta1版本开始,集成了一个metrics-scraper的组件,可通过Kubernetes的metrics API收集一些基础资源的监控信息,并在WEB页面展示;
③ 修改recommended.yaml资源文件,指定私有镜像仓库地址

④ 创建Service对外发布服务

⑤ 创建Token认证
- 格式:kubectl -n kubernetes-dashboard get secrets //查询上下文,找到管理员账户


部署Dashboard示例:
# 拷贝云盘的kubernetes/v1.17.6/dashboard目录到master上
[root@ecs-proxy ~]# rsync -av kubernetes/v1.17.6/dashboard 192.168.1.21:/root
[root@master ~]# tree dashboard/
dashboard/
├── admin-token.yaml //创建token资源对象文件
├── dashboard.tar.gz //dashboard镜像
├── metrics-scraper.tar.gz //metrics插件镜像(收集metrics监控信息插件)
└── recommended.yaml //发布服务资源文件
0 directories, 4 files步骤1:导入镜像,并上传镜像到私有仓库
① 上传dashboard镜像
[root@master ~]# cd dashboard/
[root@master dashboard]# docker load -i dashboard.tar.gz
[root@master dashboard]# docker tag kubernetesui/dashboard:v2.0.0 192.168.1.100:5000/dashboard:v2.0.0
[root@master dashboard]# docker push 192.168.1.100:5000/dashboard:v2.0.0② 上传metrics-scraper镜像
[root@master dashboard]# docker load -i metrics-scraper.tar.gz
[root@master dashboard]# docker tag kubernetesui/metrics-scraper:v1.0.4 192.168.1.100:5000/metrics-scraper:v1.0.4
[root@master dashboard]# docker push 192.168.1.100:5000/metrics-scraper:v1.0.4步骤2:安装发布服务
① 修改资源文件(修改私有镜像仓库地址)
[root@master dashboard]# vim recommended.yaml
190 image: 192.168.1.100:5000/dashboard:v2.0.0
274 image: 192.168.1.100:5000/metrics-scraper:v1.0.4② 执行资源文件
[root@master dashboard]# kubectl apply -f recommended.yaml# 查看命名空间,Dashboard会独立创建自己的命名空间kubernetes-dashboard
[root@master dashboard]# kubectl get namespaces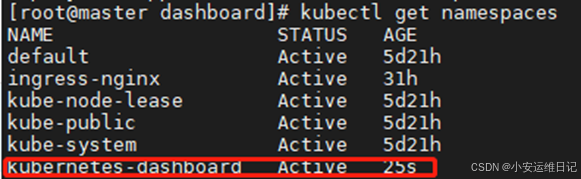
# 查询验证POD、SERVICE资源
[root@master dashboard]# kubectl -n kubernetes-dashboard get pod //查看Pod资源
[root@master dashboard]# kubectl -n kubernetes-dashboard get service //查看Service
步骤3:对外发布服务
① 编写Service资源文件
[root@master dashboard]# vim service.yaml
---
kind: Service //定义资源的类型(Service)
apiVersion: v1
metadata:labels:k8s-app: kubernetes-dashboardname: kubernetes-dashboardnamespace: kubernetes-dashboard
spec:ports:- port: 443 //前端访问容器服务的端口nodePort: 30443 //声明对外发布访问集群port端口(为防止地址变化)targetPort: 8443 //监听容器服务的端口selector: //选择为哪个资源提供服务(后端)k8s-app: kubernetes-dashboard //标签必须与recommended.yaml资源文件中一致type: NodePort //指定NodePort服务类型(容器外访问)② 执行资源文件
[root@master dashboard]# kubectl apply -f service.yaml
service/kubernetes-dashboard configured
[root@master dashboard]# kubectl -n kubernetes-dashboard get service
③ 在华为云上为任意node节点绑定弹性公网IP [ https://弹性公网IP:30443/ ]
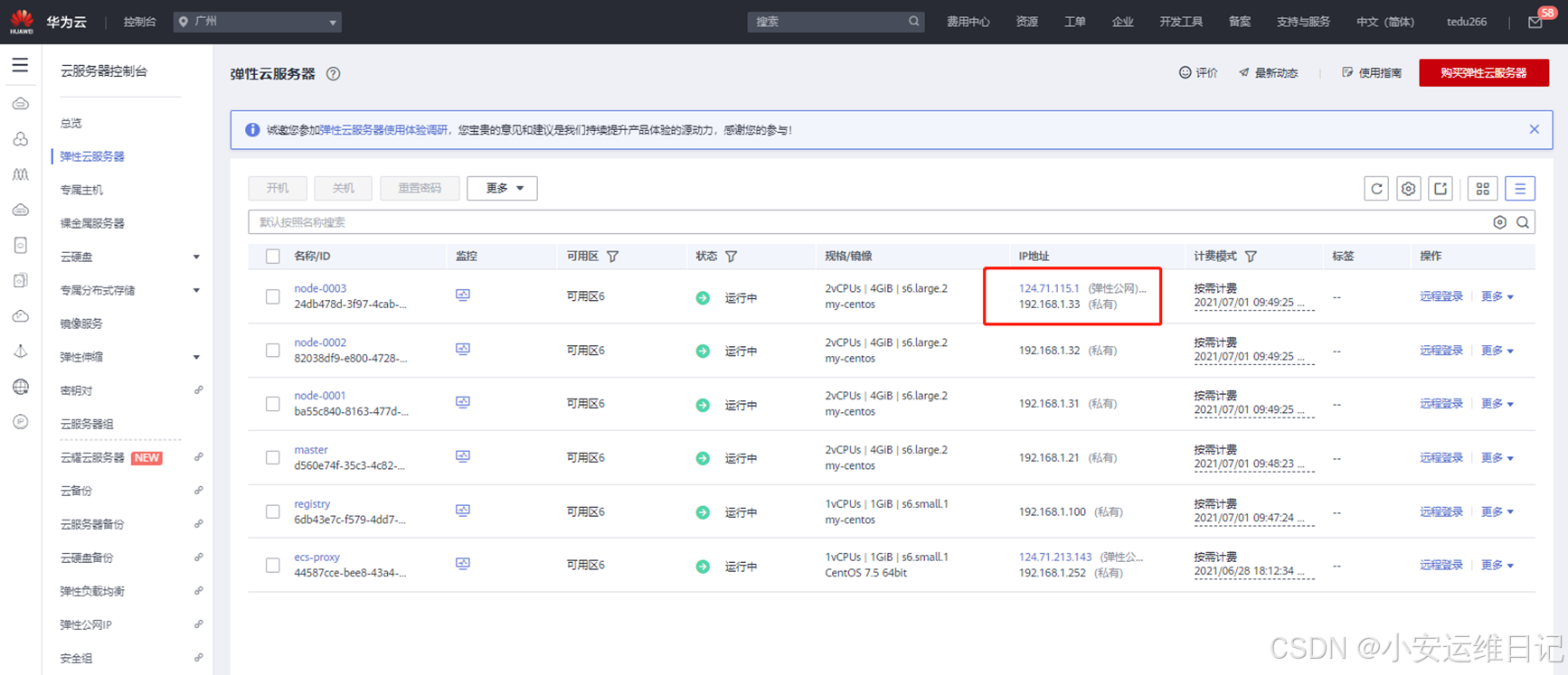
# 使用浏览器访问https://弹性公网IP:30443/
补充:首次登陆页面,要求提供Token或者kubeconfig才能有访问权限
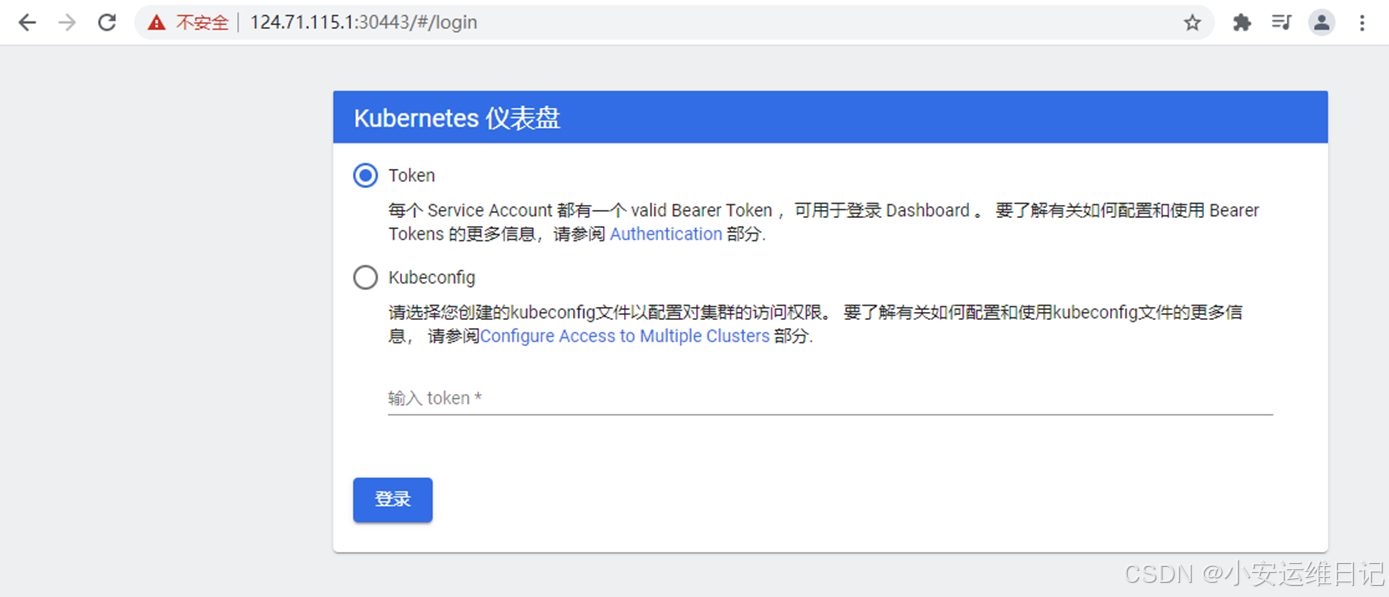
步骤4:token认证登录
① 执行admin-token.yaml资源文件,创建管理员admin-user账户
[root@master dashboard]# cat admin-token.yaml //查看即可,无需修改
---
apiVersion: v1
kind: ServiceAccount
metadata:name: admin-usernamespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: admin-user
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: cluster-admin
subjects:
- kind: ServiceAccountname: admin-usernamespace: kubernetes-dashboard[root@master dashboard]# kubectl apply -f admin-token.yaml
serviceaccount/admin-user created
clusterrolebinding.rbac.authorization.k8s.io/admin-user created② 查询上下文,找到管理员账户(admin-user-token-xxxxx)
[root@master dashboard]# kubectl -n kubernetes-dashboard get secrets
② 查询管理员账户的详细信息,找到Token登录信息
[root@master dashboard]# kubectl -n kubernetes-dashboard describe secrets admin-user-token-k478j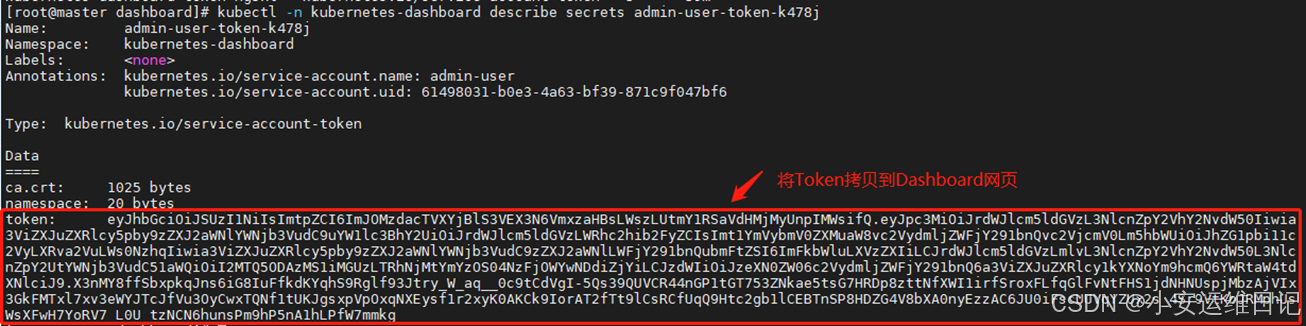
# 将Token拷贝到Dashboard
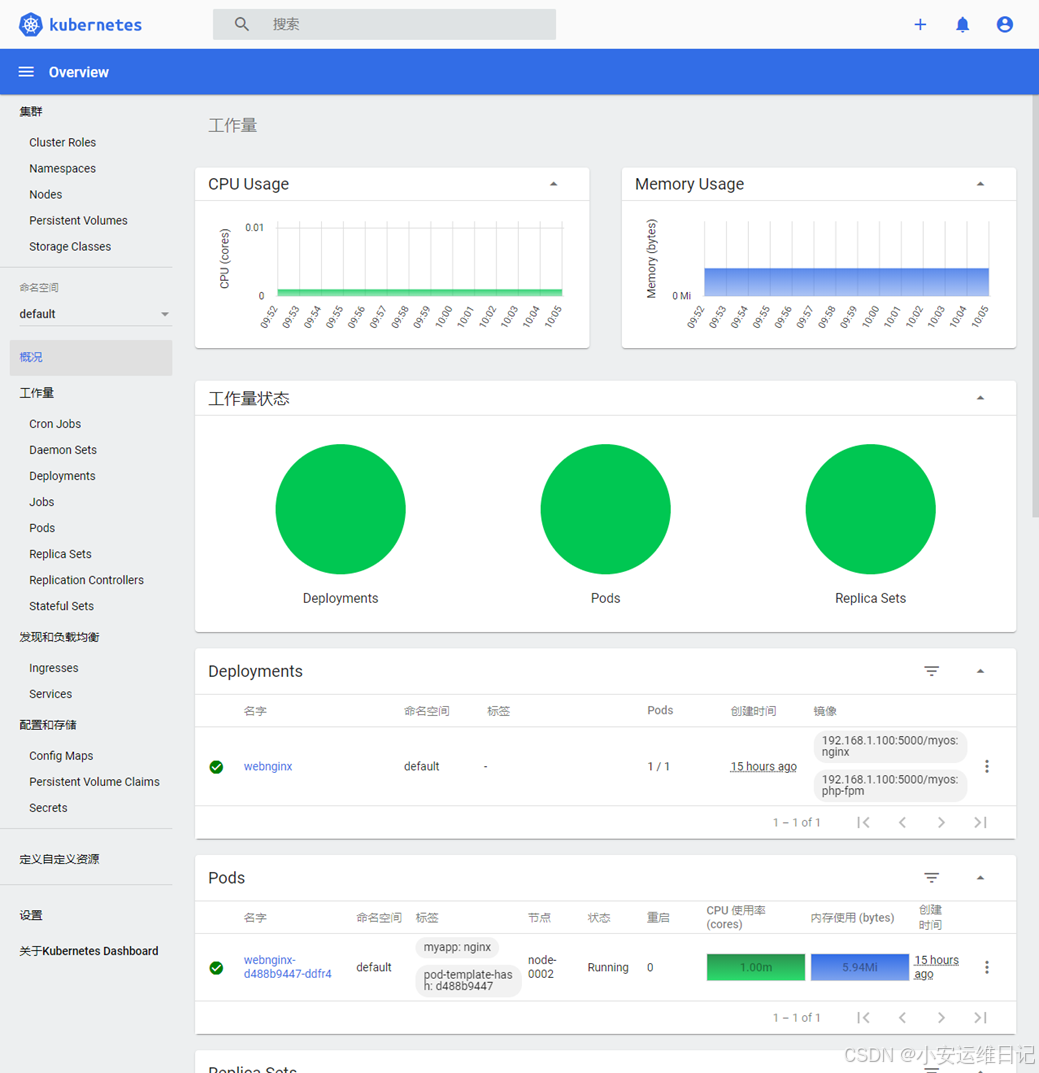
# 验证:首次登陆页面效果
① 工作量状态:运行的容器
② CPU、内存监控
二、Prometheus介绍
Prometheus是SoundCloud公司开发的一个监视系统和时间序列数据库,许多公司和组织接受和采用prometheus,之后他们便将它独立成开源项目,并且有专门的公司来运作,该项目有非常活跃的社区和开发人员,2016年Prometheus加入了云计算基金会,成为Kubernetes之后的第二个托管项目。现在最常见的K8S容器管理系统中,通常会搭配Promethus进行监控,可以把它看成Google BorgMon监控的开源版本。
Prometheus主要特点:
- ① 自定义多维数据模型
- ② 非常高效的存储,平均一个采样数据占约3.5bytes左右
- ③ 在多维度上灵活且强大的查询语言(PromQI)
- ④ 不依赖分布式存储,支持单主节点工作通过基于HTTP的Pull方式采集时序数据,可以通过Push gateway进行时序列数据推送(pushing),可以通过服务发现或者静态配置去获取要采集的目标服务器多种可视化图表及仪表盘;
Prometheus部署架构
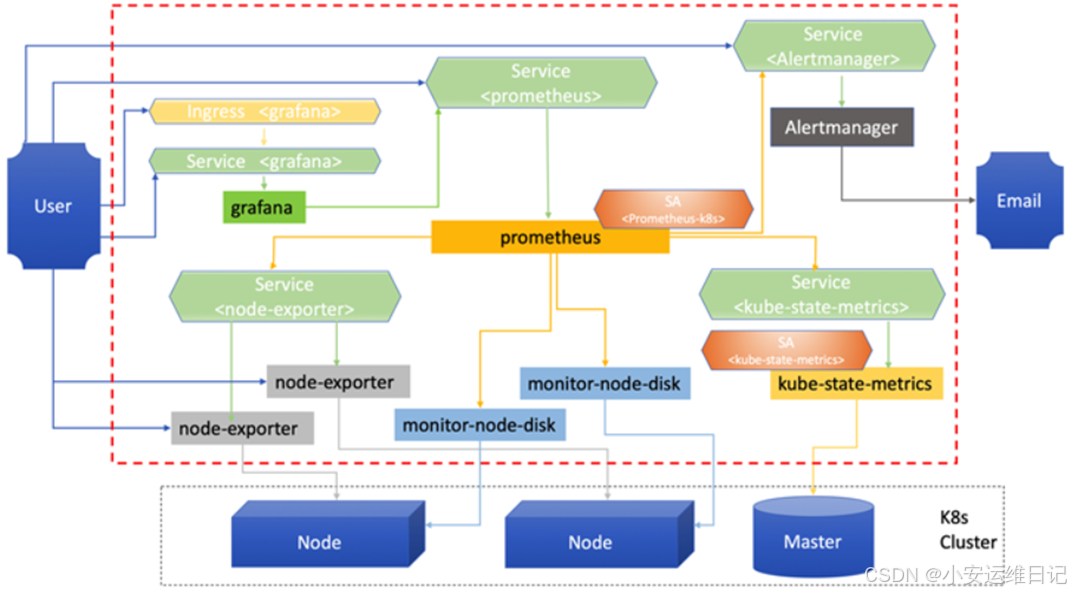
下载镜像及资源文件网址:GitHub - prometheus-operator/kube-prometheus: Use Prometheus to monitor Kubernetes and applications running on Kubernetes
其它方法:# git clone -b release-0.4 https://github,com/coreos/kube-prometheus.git
部署Prometheus示例:
步骤1:导入镜像,并上传到私有仓库
① 拷贝云盘kubernetes/v1.17.6/prometheus/下所有目录和镜像到master上
[root@ecs-proxy ~]# rsync -av kubernetes/v1.17.6/prometheus 192.168.1.21:/root
[root@master ~]# tree prometheus/
prometheus/
├── alertmanager //altermanage监控插件
│ ├── alertmanager-alertmanager.yaml
│ ├── alertmanager-secret.yaml
│ ├── alertmanager-serviceAccount.yaml
│ ├── alertmanager-serviceMonitor.yaml
│ └── alertmanager-service.yaml
├── grafana //grafana页面展示插件
│ ├── grafana-dashboardDatasources.yaml
│ ├── grafana-dashboardDefinitions.yaml
│ ├── grafana-dashboardSources.yaml
│ ├── grafana-deployment.yaml
│ ├── grafana-serviceAccount.yaml
│ ├── grafana-serviceMonitor.yaml
│ └── grafana-service.yaml
├── grafana-json // grafana-json脚本
│ ├── kubernetes-for-prometheus-dashboard-cn-v20201010_rev3.json
│ └── node-exporter-dashboard_rev1.json
├── images //10个镜像压缩包
│ ├── alertmanager.tar.gz
│ ├── configmap-reload.tar.gz
│ ├── grafana.tar.gz
│ ├── kube-metrics.tar.gz
│ ├── kube-rbac-proxy.tar.gz //授权插件
│ ├── node-exporter.tar.gz
│ ├── prometheus-adapter.tar.gz
│ ├── prometheus-config-reloader.tar.gz
│ ├── prometheus-operator.tar.gz
│ └── prometheus.tar.gz
├── metrics-state //采集数据监控插件
│ ├── kube-state-metrics-clusterRoleBinding.yaml
│ ├── kube-state-metrics-clusterRole.yaml
│ ├── kube-state-metrics-deployment.yaml
│ ├── kube-state-metrics-roleBinding.yaml
│ ├── kube-state-metrics-role.yaml
│ ├── kube-state-metrics-serviceAccount.yaml
│ ├── kube-state-metrics-serviceMonitor.yaml
│ └── kube-state-metrics-service.yaml
├── node-exporter //采集数据监控插件
│ ├── node-exporter-clusterRoleBinding.yaml
│ ├── node-exporter-clusterRole.yaml
│ ├── node-exporter-daemonset.yaml
│ ├── node-exporter-serviceAccount.yaml
│ ├── node-exporter-serviceMonitor.yaml
│ └── node-exporter-service.yaml
├── prom-adapter //采集数据监控插件
│ ├── prometheus-adapter-apiService.yaml
│ ├── prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml
│ ├── prometheus-adapter-clusterRoleBindingDelegator.yaml
│ ├── prometheus-adapter-clusterRoleBinding.yaml
│ ├── prometheus-adapter-clusterRoleServerResources.yaml
│ ├── prometheus-adapter-clusterRole.yaml
│ ├── prometheus-adapter-configMap.yaml
│ ├── prometheus-adapter-deployment.yaml
│ ├── prometheus-adapter-roleBindingAuthReader.yaml
│ ├── prometheus-adapter-serviceAccount.yaml
│ └── prometheus-adapter-service.yaml
├── prom-server // Prom-server数据库
│ ├── prometheus-clusterRoleBinding.yaml
│ ├── prometheus-clusterRole.yaml
│ ├── prometheus-operator-serviceMonitor.yaml
│ ├── prometheus-prometheus.yaml
│ ├── prometheus-roleBindingConfig.yaml
│ ├── prometheus-roleBindingSpecificNamespaces.yaml
│ ├── prometheus-roleConfig.yaml
│ ├── prometheus-roleSpecificNamespaces.yaml
│ ├── prometheus-rules.yaml
│ ├── prometheus-serviceAccount.yaml
│ ├── prometheus-serviceMonitorApiserver.yaml
│ ├── prometheus-serviceMonitorCoreDNS.yaml
│ ├── prometheus-serviceMonitorKubeControllerManager.yaml
│ ├── prometheus-serviceMonitorKubelet.yaml
│ ├── prometheus-serviceMonitorKubeScheduler.yaml
│ ├── prometheus-serviceMonitor.yaml
│ └── prometheus-service.yaml
└── setup // Setup基础工作工具和环境├── 0namespace-namespace.yaml├── prometheus-operator-0alertmanagerCustomResourceDefinition.yaml├── prometheus-operator-0podmonitorCustomResourceDefinition.yaml├── prometheus-operator-0prometheusCustomResourceDefinition.yaml├── prometheus-operator-0prometheusruleCustomResourceDefinition.yaml├── prometheus-operator-0servicemonitorCustomResourceDefinition.yaml├── prometheus-operator-clusterRoleBinding.yaml├── prometheus-operator-clusterRole.yaml├── prometheus-operator-deployment.yaml├── prometheus-operator-serviceAccount.yaml└── prometheus-operator-service.yaml
9 directories, 77 files② 将拷贝到master的images目录下所有镜像导入本地,并上传到私有仓库
[root@master ~]# cd prometheus/images/
[root@master images]# ls
[root@master images]# for i in *.gz;do docker load -i ${i};done //导入本地镜像仓库[root@master images]# img="prom/node-exporter v1.0.0
> quay.io/coreos/prometheus-config-reloader v0.35.1
> quay.io/coreos/prometheus-operator v0.35.1
> quay.io/coreos/kube-state-metrics v1.9.2
> grafana/grafana 6.4.3
> jimmidyson/configmap-reload v0.3.0
> quay.io/prometheus/prometheus v2.11.0
> quay.io/prometheus/alertmanager v0.18.0
> quay.io/coreos/k8s-prometheus-adapter-amd64 v0.5.0
> quay.io/coreos/kube-rbac-proxy v0.4.1"[root@master images]# while read _f _v;do
> docker tag ${_f}:${_v} 192.168.1.100:5000/${_f##*/}:${_v} //创建标签
> docker push 192.168.1.100:5000/${_f##*/}:${_v} //上传私有镜像仓库
> docker rmi ${_f}:${_v}
> done <<<"${img}"[root@master images]# curl http://192.168.1.100:5000/v2/_catalog //查看私有镜像仓库的镜像
{"repositories":["alertmanager","configmap-reload","coredns","dashboard","etcd","flannel","grafana","k8s-prometheus-adapter-amd64","kube-apiserver","kube-controller-manager","kube-proxy","kube-rbac-proxy","kube-scheduler","kube-state-metrics","metrics-scraper","metrics-server","myos","nginx-ingress-controller","node-exporter","pause","prometheus","prometheus-config-reloader","prometheus-operator"]}步骤2:Operator安装
以扩展Kubernetes API的形式,帮助用户创建配置和管理复杂的有状态应用程序;
需使用的镜像:configmap-reload、ometheus-config-reloader、prometheus-operator
① 查看私有镜像仓库,检查镜像
[root@master ~]# curl http://192.168.1.100:5000/v2/configmap-reload/tags/list
{"name":"configmap-reload","tags":["v0.3.0"]}
[root@master ~]# curl http://192.168.1.100:5000/v2/prometheus-config-reloader/tags/list
{"name":"prometheus-config-reloader","tags":["v0.35.1"]}
[root@master ~]# curl http://192.168.1.100:5000/v2/prometheus-operator/tags/list
{"name":"prometheus-operator","tags":["v0.35.1"]}② 修改资源文件(setup/prometheus-operator-deployment.yaml)
[root@master prometheus]# cd
[root@master ~]# cd prometheus/
[root@master prometheus]# vim setup/prometheus-operator-deployment.yaml
27: - --config-reloader-image=192.168.1.100:5000/configmap-reload:v0.3.0 //启动参数镜像地址
28: - --prometheus-config-reloader=192.168.1.100:5000/prometheus-config-reloader:v0.35.1
29: image: 192.168.1.100:5000/prometheus-operator:v0.35.1③ 执行资源文件(执行setup基础环境下的所有资源文件)
[root@master prometheus]# kubectl apply -f setup/# 查看命名空间,Operator会独立创建自己的命名空间monitoring
[root@master prometheus]# kubectl get namespaces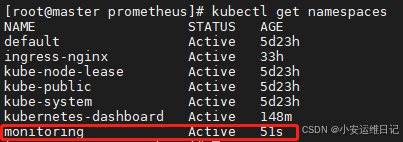
[root@master prometheus]# kubectl -n monitoring get pod
步骤3:Prometheus server安装
对监控数据的获取、存储以及查询;
需使用的镜像:prometheus
① 查看私有镜像仓库,检查镜像
[root@master prometheus]# curl http://192.168.1.100:5000/v2/prometheus/tags/list
{"name":"prometheus","tags":["v2.11.0"]}② 修改资源文件(prom-server/prometheus-prometheus.yaml)
[root@master prometheus]# vim prom-server/prometheus-prometheus.yaml
14: baseImage: 192.168.1.100:5000/prometheus //BaseImage镜像没有标签,使用版本作为标签
34: version: v2.11.0③ 执行资源文件(执行prom-server数据库下的所有文件)
[root@master prometheus]# kubectl apply -f prom-server/
[root@master prometheus]# kubectl -n monitoring get pod
步骤4:Prom-adapter安装
获取APIserver的资源指标,提供给Prom Server数据库
需使用的镜像:prometheus-adapter
① 查看私有镜像仓库,检查镜像
[root@master prometheus]# curl http://192.168.1.100:5000/v2/k8s-prometheus-adapter-amd64/tags/list
{"name":"k8s-prometheus-adapter-amd64","tags":["v0.5.0"]}② 修改资源文件(prom-adapter/prometheus-adapter-deployment.yaml)
[root@master prometheus]# vim prom-adapter/prometheus-adapter-deployment.yaml
28: image: 192.168.1.100:5000/k8s-prometheus-adapter-amd64:v0.5.0③ 执行资源文件(执行prom-adapter下的所有文件)
[root@master prometheus]# kubectl apply -f prom-adapter/
[root@master prometheus]# kubectl -n monitoring get pod
步骤5:Metrics-state安装
获取各种资源的最新状态(pod、deploy)
需使用的镜像:kube-state-metrics、kube-rbac-proxy
① 查看私有镜像仓库,检查镜像
[root@master prometheus]# curl http://192.168.1.100:5000/v2/kube-state-metrics/tags/list
{"name":"kube-state-metrics","tags":["v1.9.2"]}
[root@master prometheus]# curl http://192.168.1.100:5000/v2/kube-rbac-proxy/tags/list
{"name":"kube-rbac-proxy","tags":["v0.4.1"]}② 修改资源文件(metrics-state/kube-state-metrics-deployment.yaml)
[root@master prometheus]# vim metrics-state/kube-state-metrics-deployment.yaml
24: image: 192.168.1.100:5000/kube-rbac-proxy:v0.4.1
41: image: 192.168.1.100:5000/kube-rbac-proxy:v0.4.1
58: image: 192.168.1.100:5000/kube-state-metrics:v1.9.2③ 执行资源文件(执行metrics-state下的所有文件)
[root@master prometheus]# kubectl apply -f metrics-state/
[root@master prometheus]# kubectl -n monitoring get pod
步骤6:Node-exporter安装
采集Node节点的数据,提供该Prom Server数据库
需使用的镜像:node-exporter、kube-rbac-proxy
① 查看私有镜像仓库,检查镜像
[root@master prometheus]# curl http://192.168.1.100:5000/v2/node-exporter/tags/list
{"name":"node-exporter","tags":["v1.0.0"]}
[root@master prometheus]# curl http://192.168.1.100:5000/v2/kube-rbac-proxy/tags/list
{"name":"kube-rbac-proxy","tags":["v0.4.1"]}② 修改资源文件(node-exporter/node-exporter-daemonset.yaml)
[root@master prometheus]# vim node-exporter/node-exporter-daemonset.yaml
27: image: 192.168.1.100:5000/node-exporter:v1.0.0
57: image: 192.168.1.100:5000/kube-rbac-proxy:v0.4.1③ 执行资源文件(执行node-exporter下的所有文件)
[root@master prometheus]# kubectl apply -f node-exporter/
[root@master prometheus]# kubectl -n monitoring get pod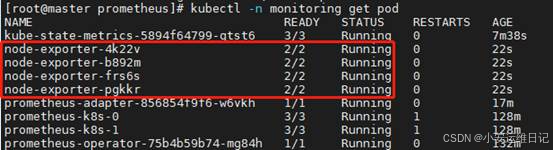
步骤7:Alertmanager安装
Prometheus体系中的告警处理中心
需使用的镜像:altermanager
① 查看私有镜像仓库,检查镜像
[root@master prometheus]# curl http://192.168.1.100:5000/v2/alertmanager/tags/list
{"name":"alertmanager","tags":["v0.18.0"]}② 修改资源文件(metrics-state/kube-state-metrics-deployment.yaml)
[root@master prometheus]# vim alertmanager/alertmanager-alertmanager.yaml
09: baseImage: 192.168.1.100:5000/alertmanager
18: version: v0.18.0③ 执行资源文件(执行alertmanager下的所有文件)
[root@master prometheus]# kubectl apply -f alertmanager/
[root@master prometheus]# kubectl -n monitoring get pod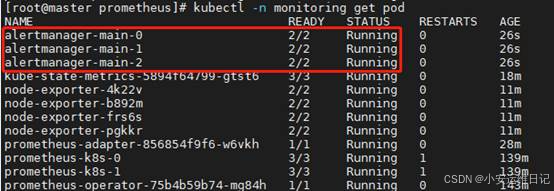
步骤8:grafana安装
支持多种图形和Dashboard的展示
需使用的镜像:grafana
① 查看私有镜像仓库,检查镜像
[root@master prometheus]# curl http://192.168.1.100:5000/v2/grafana/tags/list
{"name":"grafana","tags":["6.4.3"]}② 修改资源文件(grafana/grafana-deployment.yaml)
[root@master prometheus]# vim grafana/grafana-deployment.yaml
19: - image: 192.168.1.100:5000/grafana:6.4.3③ 执行资源文件(执行grafana下的所有文件)
[root@master prometheus]# kubectl apply -f grafana/
[root@master prometheus]# kubectl -n monitoring get pod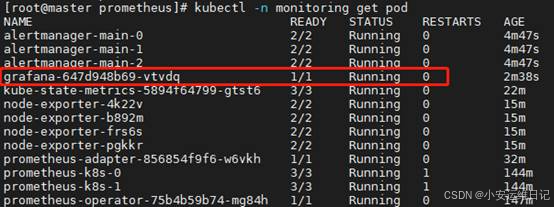
总结:部署Prometheus需安装7个服务插件,需使用10个镜像
1)插件Prometheus operator
用途:以扩展Kubernetes API的形式,帮助用户创建配置和管理复杂的有状态应用程序;
需使用的镜像:configmap-reload、ometheus-config-reloader、prometheus-operator
资源文件:setup/prometheus-operator-deployment.yaml
2)插件Prometheus server
用途:对监控数据的获取、存储以及查询
需使用的镜像:prometheus
资源文件:prom-server/prometheus-prometheus.yaml
3)插件Prometheus adapter
用途:获取APIserver的资源指标,提供给Prom Server数据库
需使用的镜像:prometheus-adapter
资源文件:prom-adapter/prometheus-adapter-deployment.yaml
4)插件metrics-state
用途:获取各种资源的最新状态(pod、deploy)
需使用的镜像:kube-state-metrics、kube-rbac-proxy
资源文件:metrics-state/kube-state-metrics-deployment.yaml
5)插件node-exporter
用途:采集Node节点的数据,提供该Prom Server数据库
需使用的镜像:node-exporter、kube-rbac-proxy
资源文件:node-exporter/node-exporter-daemonset.yaml
6)插件altermanager
用途:Prometheus体系中的告警处理中心
需使用的镜像:altermanager
资源文件:alertmanager/alertmanager-alertmanager.yaml
7)插件grafana
用途:支持多种图形和Dashboard的展示
需使用的镜像:grafana
资源文件:grafana/grafana-deployment.yaml
步骤9:发布Prometheus服务
# Grafana默认的服务使用Cluster IP,对外发布服务需使用nodePort
[root@master prometheus]# kubectl -n monitoring get service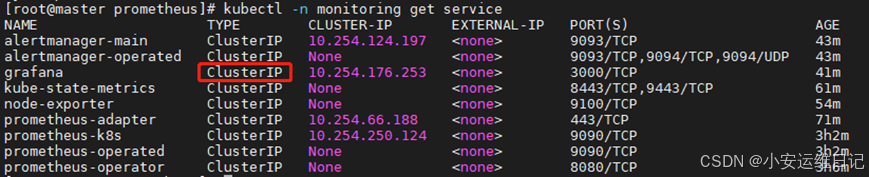
① 修改Service资源文件
[root@master prometheus]# cp grafana/grafana-service.yaml ./
[root@master prometheus]# vim grafana-service.yaml
---
apiVersion: v1
kind: Service
metadata:labels:app: grafananame: grafananamespace: monitoring
spec:type: NodePort //指定NodePort服务类型(容器外访问)ports:- name: httpport: 3000targetPort: httpnodePort: 30000 //指定对外发布访问集群port端口(也可不指定)selector: //选择为哪个资源提供服务(后端)app: grafana② 执行资源文件
[root@master prometheus]# kubectl apply -f grafana-service.yaml
service/grafana configured
[root@master prometheus]# kubectl -n monitoring get service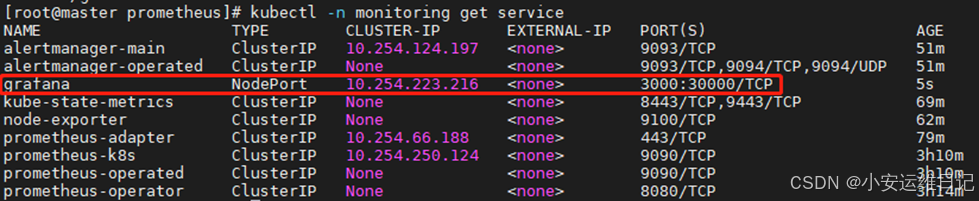
③ 服务发布以后可以通过华为云弹性公网IP直接访问即可
使用浏览器访问https://弹性公网IP:30000/,首次Grafana登陆页面,第一次默认登录的用户名/密码(admin/admin),第一次登陆需修改密码;

步骤10:Grafana配置管理
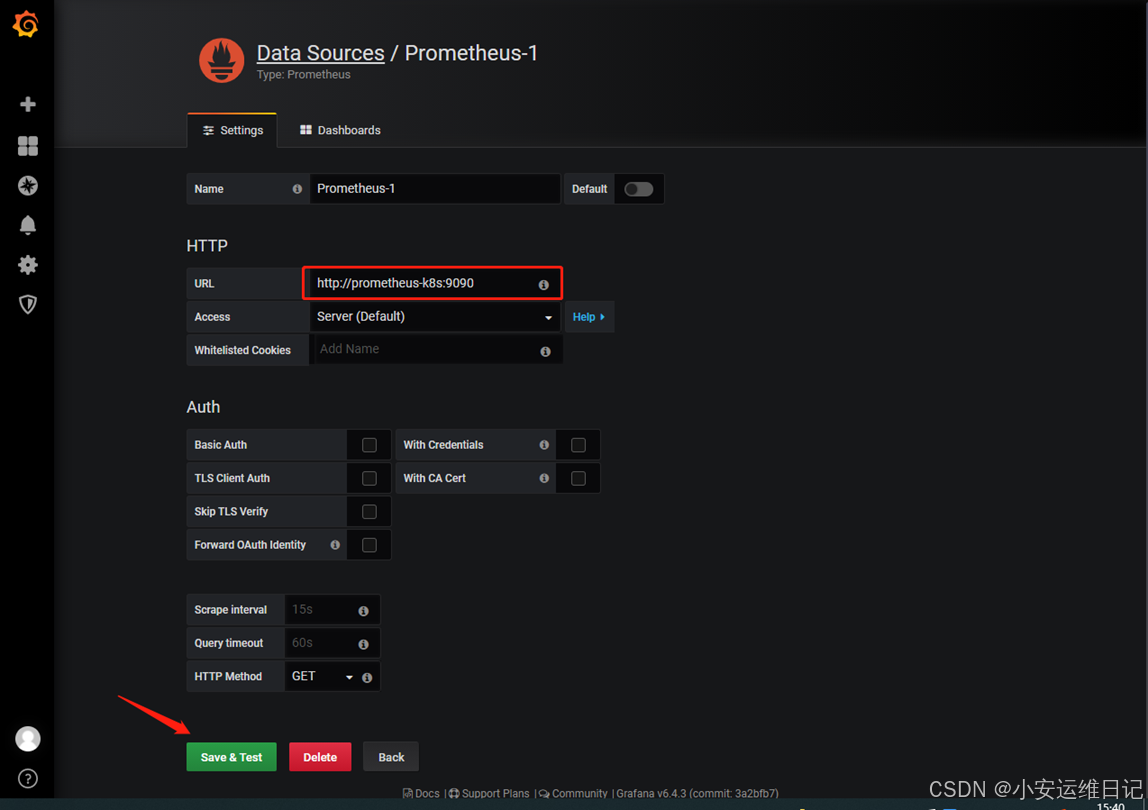
① 添加Prometheus数据

② 添加数据源(可使用Prometheus-k8s的Service内部解析的DNS域名代替NodePort地址)

URL填写:http://prometheus-k8s.monitoring.svc.cluster.local:9090(可简写)
③ 导入数据模板(kubernetes\v1.17.6\prometheus\grafana-json)
# 给模板配置数据源(Prometheus-1)
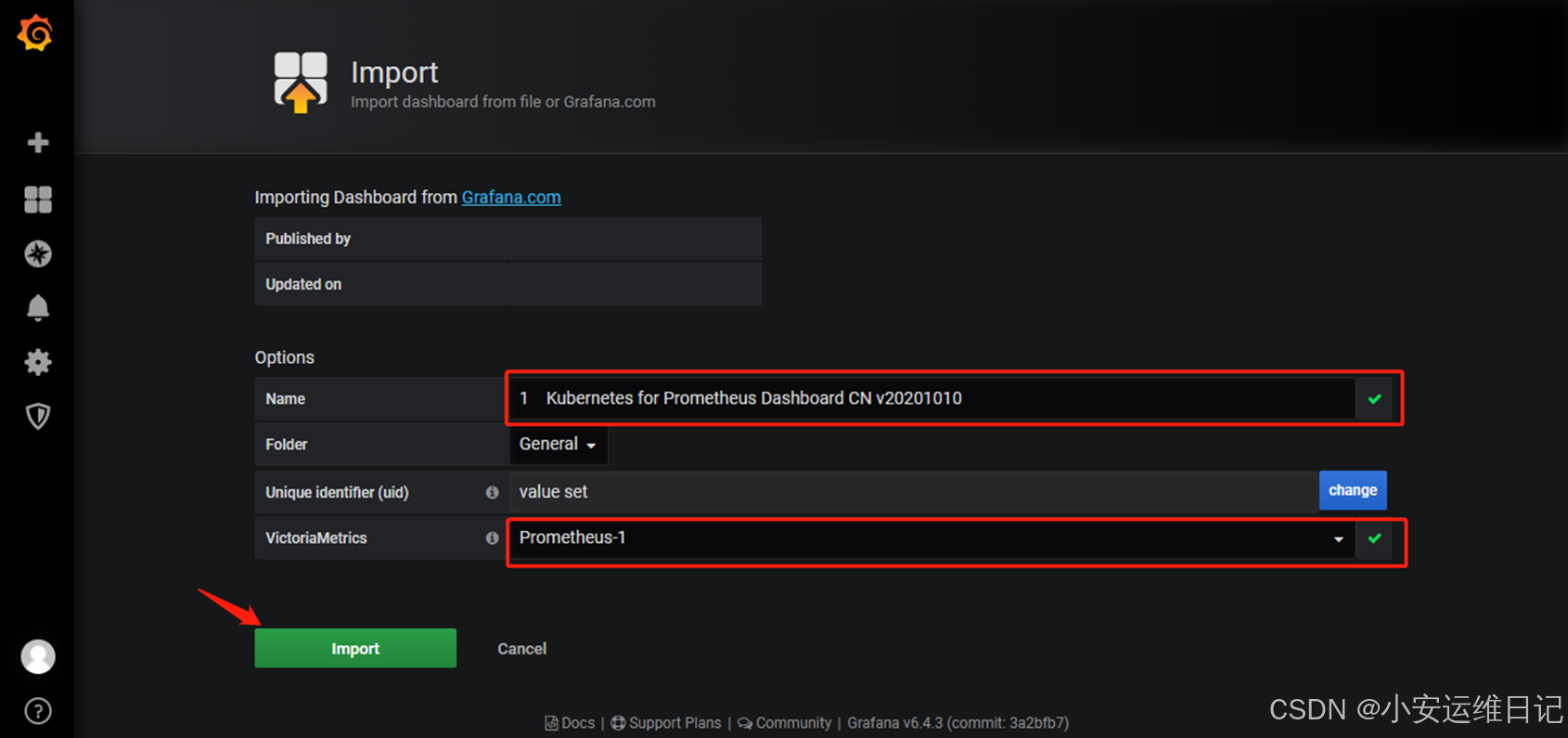
④ 查看监控页面效果
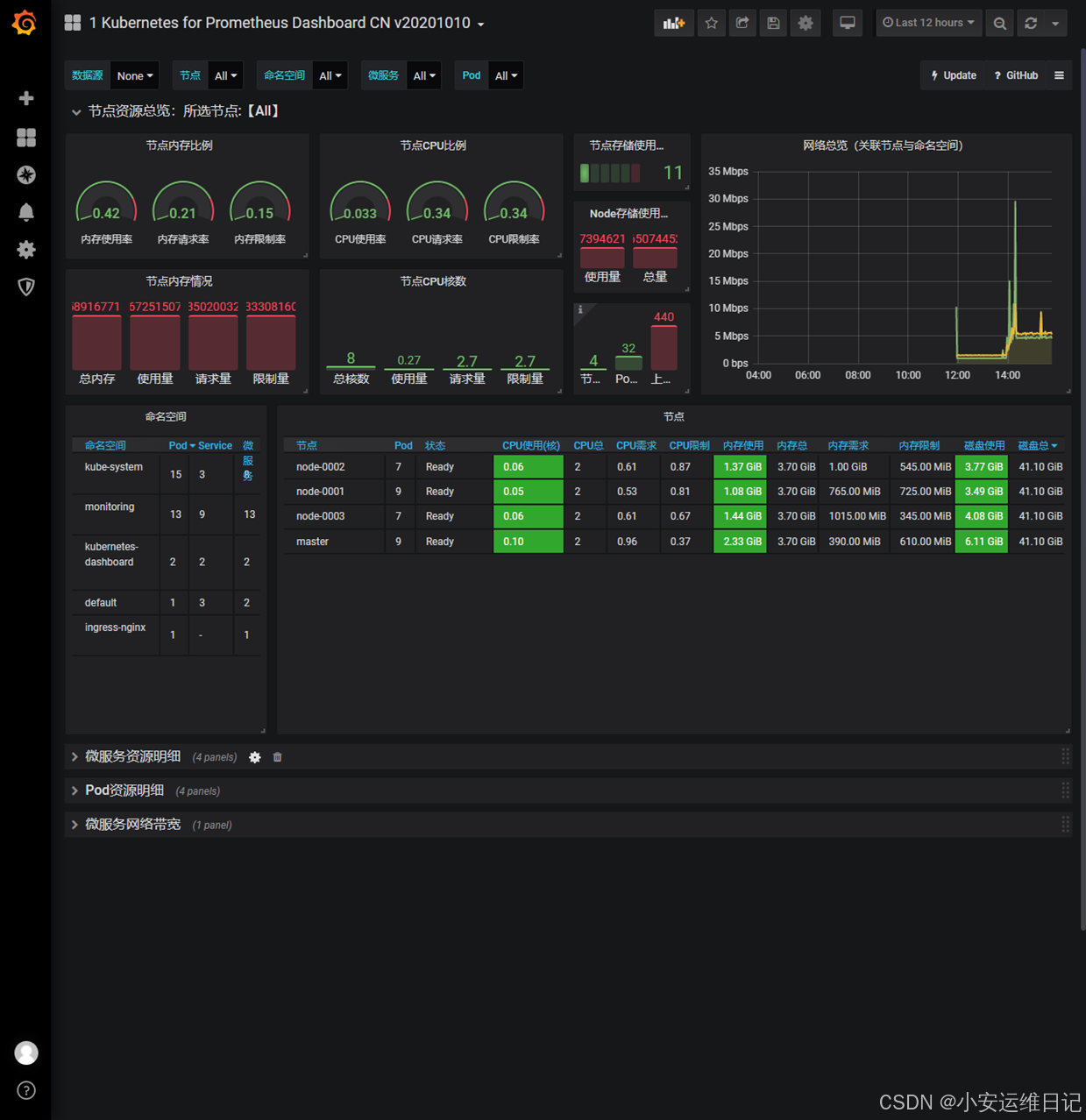
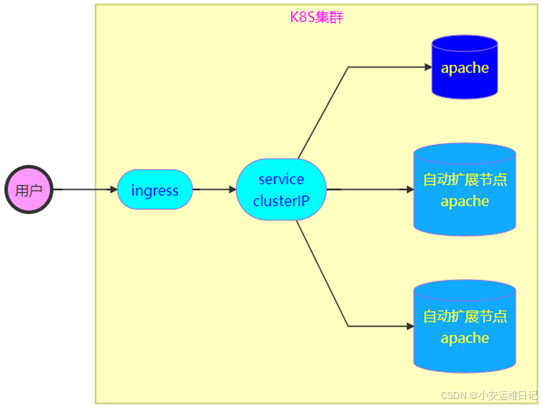
三、HPA控制器
Horizontal Pod Autoscaling,简称HPA,是Kubernetes中实现POD水平自动伸缩的功能,HPA可以基于CPU利用率或其他应程序提供的度量指标自动缩放POD的数量;例如通过metrics-server动态获取CPU的资源利用率,根据资源利用率来判断需要多少个POD;
Pod水平自动伸缩特性由Kubernetes API资源和控制器实现,资源决定了控制器的行为,控制器会周期性的获取平均利用率,并与定义的度量值相比较后来调整副本数量。
限制:适用于Deployment管理副本的控制器,不适用于无法缩放的对象(如DaemonSet,因DaemSet的绑定节点)
- 格式:kubectl get hpa //查看hpa资源控制器
使用Deployment控制器创建Apache应用


HPA资源文件模板:

部署HPA自动伸缩POD的集群示例:
① 查看metrics-server资源占用率服务是否启动(HPA依赖监控资源利用率插件)
[root@master ~]# kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
metrics-server-67fbd5bb7b-qbgkx 1/1 Running 0 30h
[root@master ~]# kubectl -n kube-system get service
[root@master ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 104m 5% 1303Mi 35%
node-0001 50m 2% 855Mi 23%
node-0002 64m 3% 1075Mi 29%
node-0003 59m 2% 1109Mi 30%② 编写HPA资源文件
[root@master ~]# vim myhpa.yaml
---
apiVersion: apps/v1 //类型的版本
kind: Deployment //定义资源的类型(Deployment控制器)
metadata:name: myweb //控制器的名称(集群名称)
spec:selector: //声明资源匹配选择器matchLabels: //资源方式:匹配标签app: apache //为服务的后端选择标签(标签1)replicas: 1 //副本数template: //POD资源模板metadata:labels: //声明定义标签app: apache //标签名,与matchLabels要一致(标签1)spec: //POD的详细定义containers: //容器定义- name: apacheimage: 192.168.1.100:5000/myos:httpdports:- containerPort: 80resources: //计算此容器所需的资源(监控的资源)requests: //描述所需的最小计算资源量(目标监控什么资源)cpu: 200m //计量单位毫核,可以看做100milli(监控CPU,200毫核)restartPolicy: Always---
apiVersion: v1
kind: Service //定义Service资源类型
metadata:name: web-service //类型的名称
spec:ports:- protocol: TCP //后端服务所使用的协议,需要一致port: 80 //前端监听的服务端口号targetPort: 80 //后端目标主机的服务端口号selector: //选择为哪个deployment提供服务(后端)app: apache //标签名必须与 deployment的labels要一致(标签1)type: ClusterIP //定义服务类型(ClusertIP)---
apiVersion: extensions/v1beta1 //类型的版本
kind: Ingress //定义Ingress资源类型(对外访问服务)
metadata:name: my-appannotations:kubernetes.io/ingress.class: "nginx"
spec:backend:serviceName: web-service //指定Service名称servicePort: 80---
apiVersion: autoscaling/v1 //类型的版本
kind: HorizontalPodAutoscaler //定义HPA资源类型
metadata:name: myweb //HPA资源的名称
spec:minReplicas: 1 //最小保留POD副本数量maxReplicas: 3 //最大保留POD副本数量(集群节点:1~3)scaleTargetRef: //发现利用率变化通知控制器apiVersion: apps/v1 //监视资源类型的版本kind: Deployment //监视资源的类型name: myweb //监视Deployment控制器targetCPUUtilizationPercentage: 50 //CPU度量阈值,百分比50%③ 执行资源文件
[root@master ~]# kubectl apply -f myhpa.yaml
[root@master ~]# kubectl get hpa //查看hpa资源控制器
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myweb Deployment/myweb 0%/50% 1 3 1 16m补充:创建资源对象后,TARGETS会有一个unknow不会立即生效,因需要metrics-server服务监测占用率耗费几分钟时间,才能获取到CPU等信息,属于正常现象;
④ 验证测试服务
# 持续访问Apache,模拟增加CPU负载,当容器的监测的CPU占用率TARGETS超过 50% 的时候,自动扩展一个POD,当占用率次序增大,会依次扩展直到最大保留POD数量值;
# 如果CPU访问不足 50% 的时候,让CPU处于空闲状态,副本数不会立即释放,而是每180~300秒(5分钟左右)开始释放POD副本,直到最小保留POD数量值时停止。
补充:为防止黑客通过高并发攻击,所以设置300秒延迟时间,当小于CPU度量值300秒后,才开始进行副本释放;(利用率统计的是POD之间的和)
补充:访问测试可以使用镜像内提供的 info.php增加系统负载,从而查看状态信息;
例如:http://ip/info.php?id=1000000,id为计算结果集的数量,id 越大,占用内存和CPU越高,设置特别大容易死机
[root@master ~]# watch -n 1 "kubectl get hpa"
结果:测试访问Apache前,CPU的占用率为0,副本数REPLICAS为1
# 保留当前终端,并打开另一个终端测试
[root@master ~]# kubectl exec -it myweb-7f89fc7b66-fx24j -- /bin/bash
[root@myweb-7f89fc7b66-fx24j html]# curl http://10.254.231.161/info.php?id=100000
<pre>
Array
([REMOTE_ADDR] => 10.244.2.1[REQUEST_METHOD] => GET[HTTP_USER_AGENT] => curl/7.29.0[REQUEST_URI] => /info.php?id=100000[id] => 100000
)
php_host: myweb-7f89fc7b66-fx24j
9592
结果:测试访问Apache后,CPU的占用率为114,副本数REPLICAS为3
# 查看当前已创建的POD副本
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myweb-7f89fc7b66-fx24j 1/1 Running 0 53m
myweb-7f89fc7b66-ldlfg 1/1 Running 0 3m4s
myweb-7f89fc7b66-t9glf 1/1 Running 0 2m19s# 测试轮询(Ingress的7层负载均衡)
[root@master ~]# kubectl get service
[root@myweb-7f89fc7b66-fx24j html]# curl http://10.254.231.161/info.php?id=100000
<pre>
Array
([REMOTE_ADDR] => 10.244.2.29[REQUEST_METHOD] => GET[HTTP_USER_AGENT] => curl/7.29.0[REQUEST_URI] => /info.php?id=100000[id] => 100000
)
php_host: myweb-7f89fc7b66-t9glf
9592[root@myweb-7f89fc7b66-fx24j html]# curl http://10.254.231.161/info.php?id=100000
<pre>
Array
([REMOTE_ADDR] => 10.244.2.29[REQUEST_METHOD] => GET[HTTP_USER_AGENT] => curl/7.29.0[REQUEST_URI] => /info.php?id=100000[id] => 100000
)
php_host: myweb-7f89fc7b66-ldlfg
9592[root@myweb-7f89fc7b66-fx24j html]# curl http://10.254.231.161/info.php?id=100000
<pre>
Array
([REMOTE_ADDR] => 10.244.2.1[REQUEST_METHOD] => GET[HTTP_USER_AGENT] => curl/7.29.0[REQUEST_URI] => /info.php?id=100000[id] => 100000
)
php_host: myweb-7f89fc7b66-fx24j
9592# 等待CPU空闲后,副本数恢复为1

[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myweb-7f89fc7b66-fx24j 1/1 Running 0 31h小结:
本篇章节为【第五阶段】CLOUD-DAY10 的学习笔记,这篇笔记可以初步了解到 如何去部署Dashboard、部署Prometheus、部署HPA集群。
Tip:毕竟两个人的智慧大于一个人的智慧,如果你不理解本章节的内容或需要相关笔记、视频,可私信小安,请不要害羞和回避,可以向他人请教,花点时间直到你真正的理解。