一、Sqoop介绍
Sqoop是一款开源的工具,主要用于在Hadoop(HDFS/Hive/HBase)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
二、安装
1).解压
tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/installs
2).重命名
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop1.4.6
3).修改配置文件
cd /opt/installs/sqoop1.4.6/conf
mv sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
#增加配置,注意修改路径
export HADOOP_COMMON_HOME=/opt/installs/hadoop3.1.4
export HADOOP_MAPRED_HOME=/opt/installs/hadoop3.1.4
export ZOOCFGDIR=/opt/installs/zookeeper3.4.6
export HIVE_HOME=/opt/installs/hive3.1.24).将mysql的驱动jar复制到sqoop的lib目录下 (底层需要用JDBC操作MySQL数据库)
cp /opt/installs/hive3.1.2/lib/mysql-connector-java-8.0.26.jar /opt/installs/sqoop1.4.6/lib/5).配置sqoop环境变量
export PATH=$PATH:/opt/installs/sqoop1.4.6/bin三、sqoop-import
在Sqoop中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE,HBASE)中传输数据,叫做:导入,即使用import关键字。
-- 测试数据库的表是否可以连接,显示库中的所有表
sqoop list-tables --connect jdbc:mysql://hadoop10:3306/test1 --username root --password 1234561). RDBMS(mysql) -> HDFS
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_sex \
--num-mappers 4 \
--fields-terminated-by '\t' \
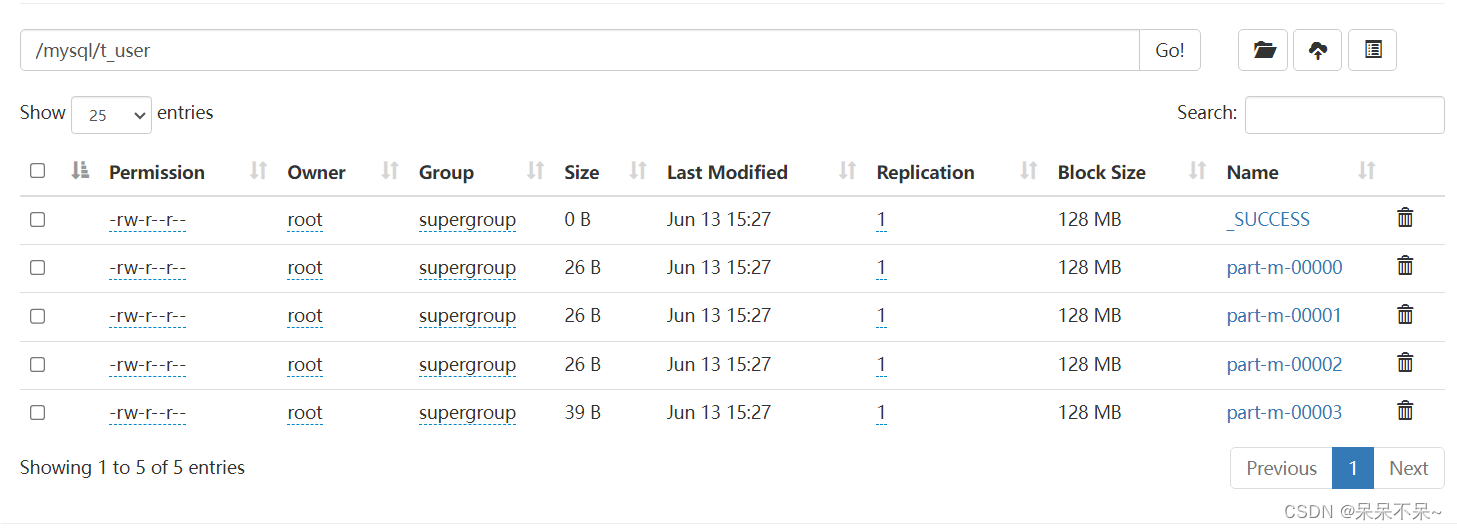
--target-dir /mysql/t_user \
--delete-target-dir参数 作业
--driver mysql驱动
--connect 数据库连接url jdbc:mysql://ip:3306/数据库
--username 连接mysql数据库用户名
--password 连接mysql数据库密码
--table mysql中test1数据库中表名
--num-mappers sqoop底层是mapreduce, 指定启动的maptask个数,海量数据可以并 行抽取
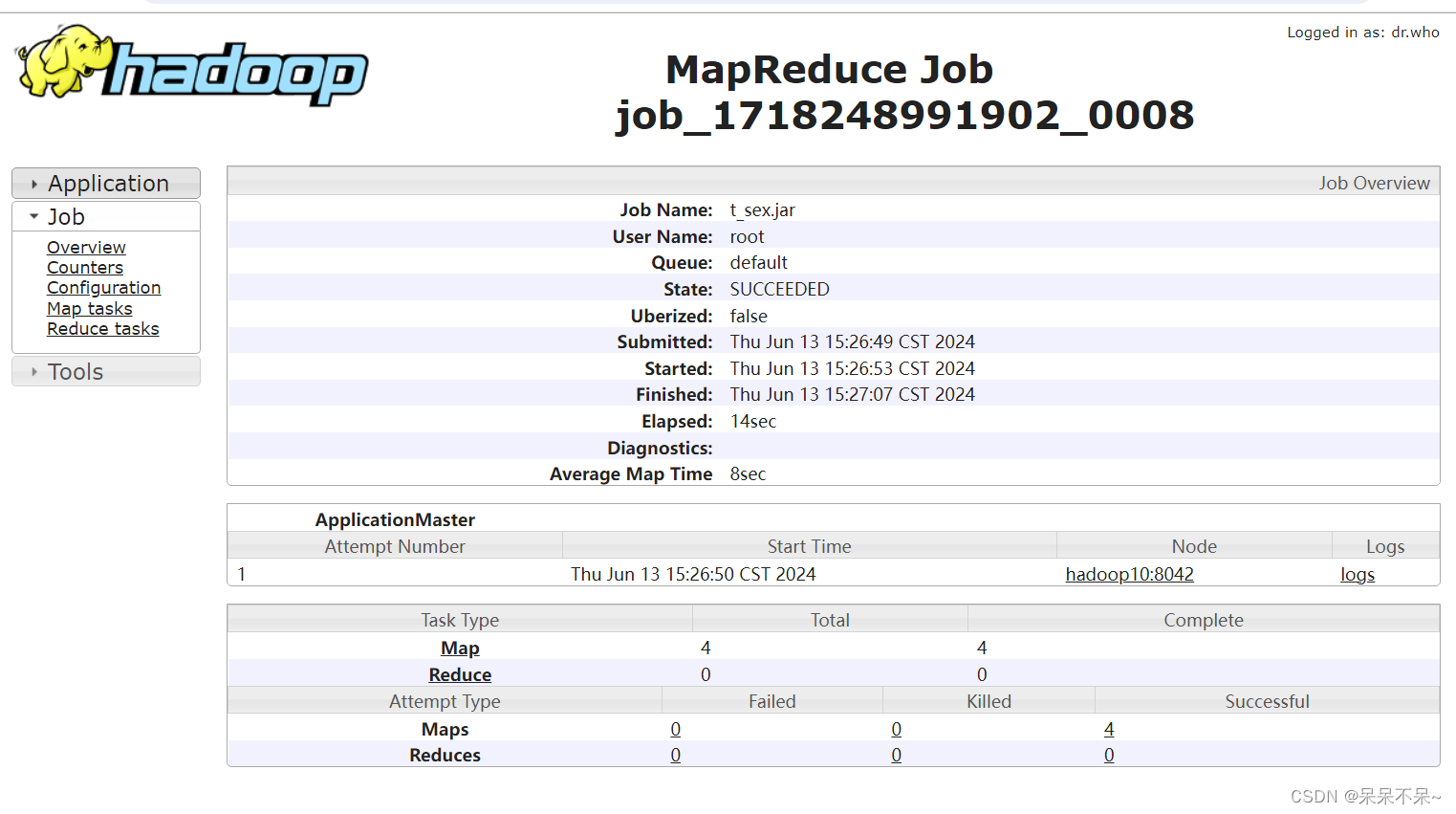
解释:sqoop抽取任务会转换成mr作业,该mr作业由于不需要对数据进行聚合,所有只需要保留maptask阶段,没有reduceTasksqoop,需要依赖hadoop的HDFS和Yarn
--fields-terminated-by 数据写入HDFS存储到文件中,列与列之间的分隔符
--target-dir 存储到HDFS的目标路径,配置的是目录,并且该目录应该不存在
--delete-target-dir 如果存在,则提前删除
mysql中的表:
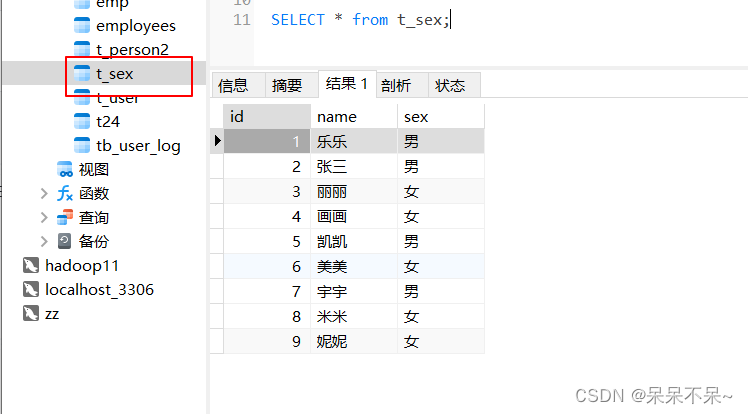
运行1:
 查看:
查看:
yarn:
hdfs:
运行2:
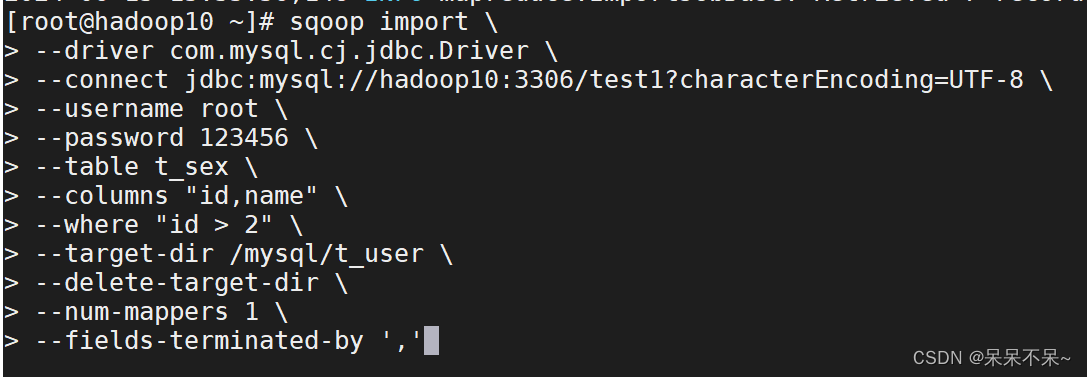
sqoop import \
--driver com.mysql.cj.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_sex \
--columns "id,name" \
--where "id > 2" \
--target-dir /mysql/t_user \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by ','参数
--columns 指定列名
--where 指定查询条件
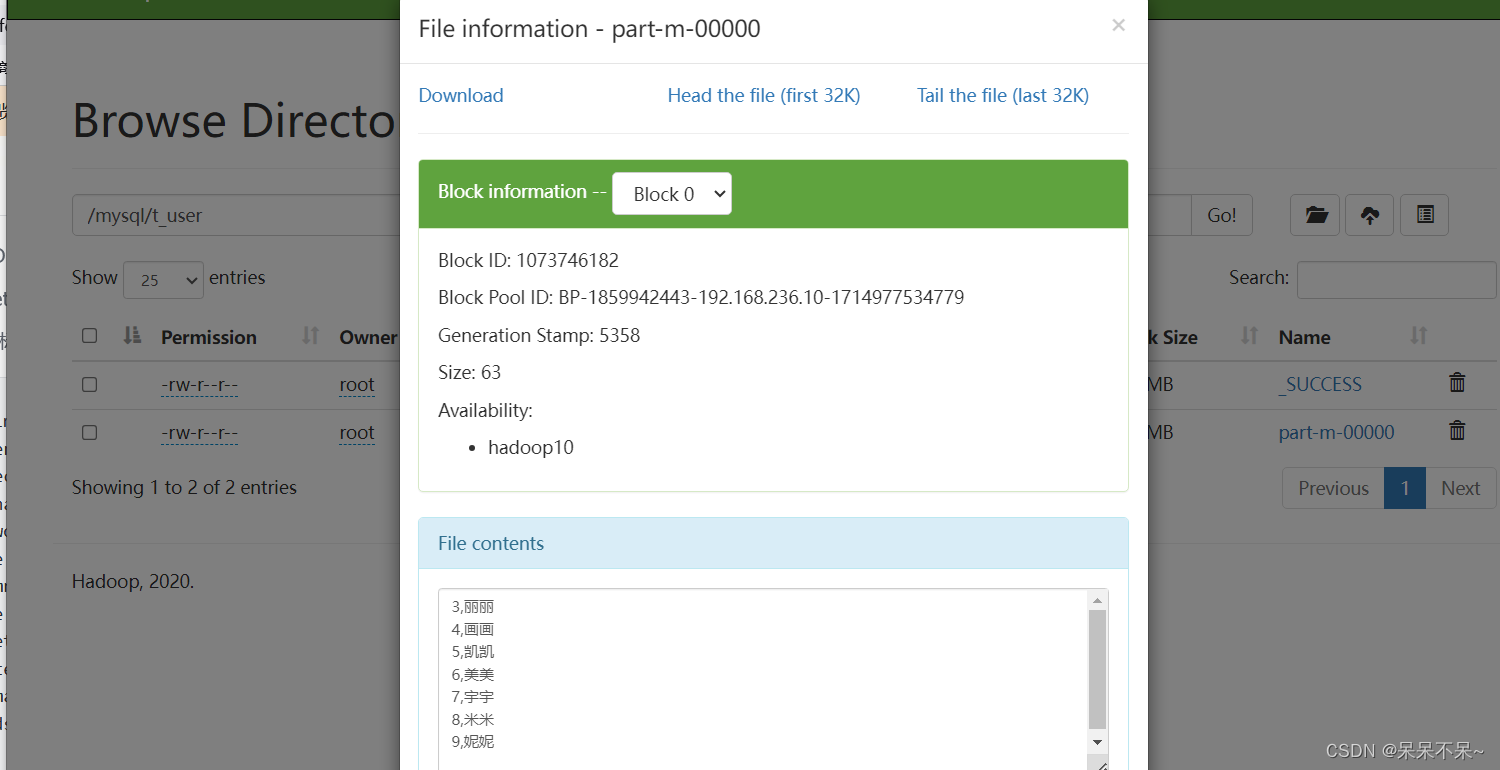
查看hdfs:
运行3:
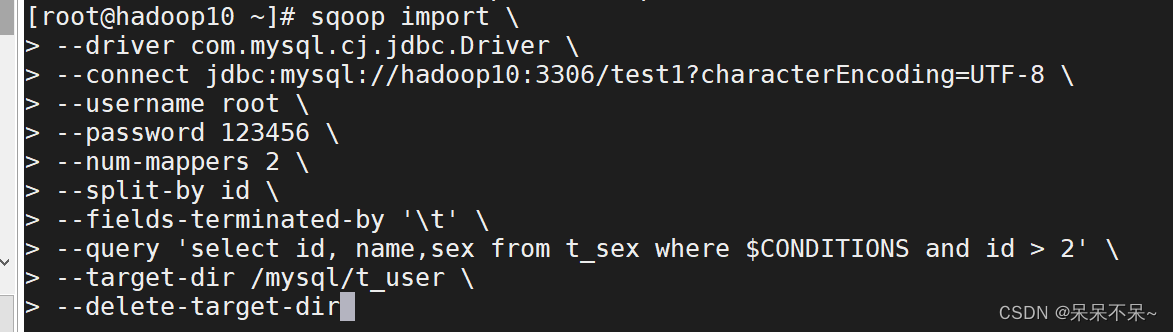
sqoop import \
--driver com.mysql.cj.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--num-mappers 2 \
--split-by id \
--fields-terminated-by '\t' \
--query 'select id, name,sex from t_sex where $CONDITIONS and id > 2' \
--target-dir /mysql/t_user \
--delete-target-dir参数 作用
--split-by 根据指定字段进行拆分,相当于datax的splitPK。根据这一列的值把数据分成几部分
--num-mappers 指定并行度,简写-m
--query 查询语句。$CONDITIONS相当于占位符,写where条件必须有写这个
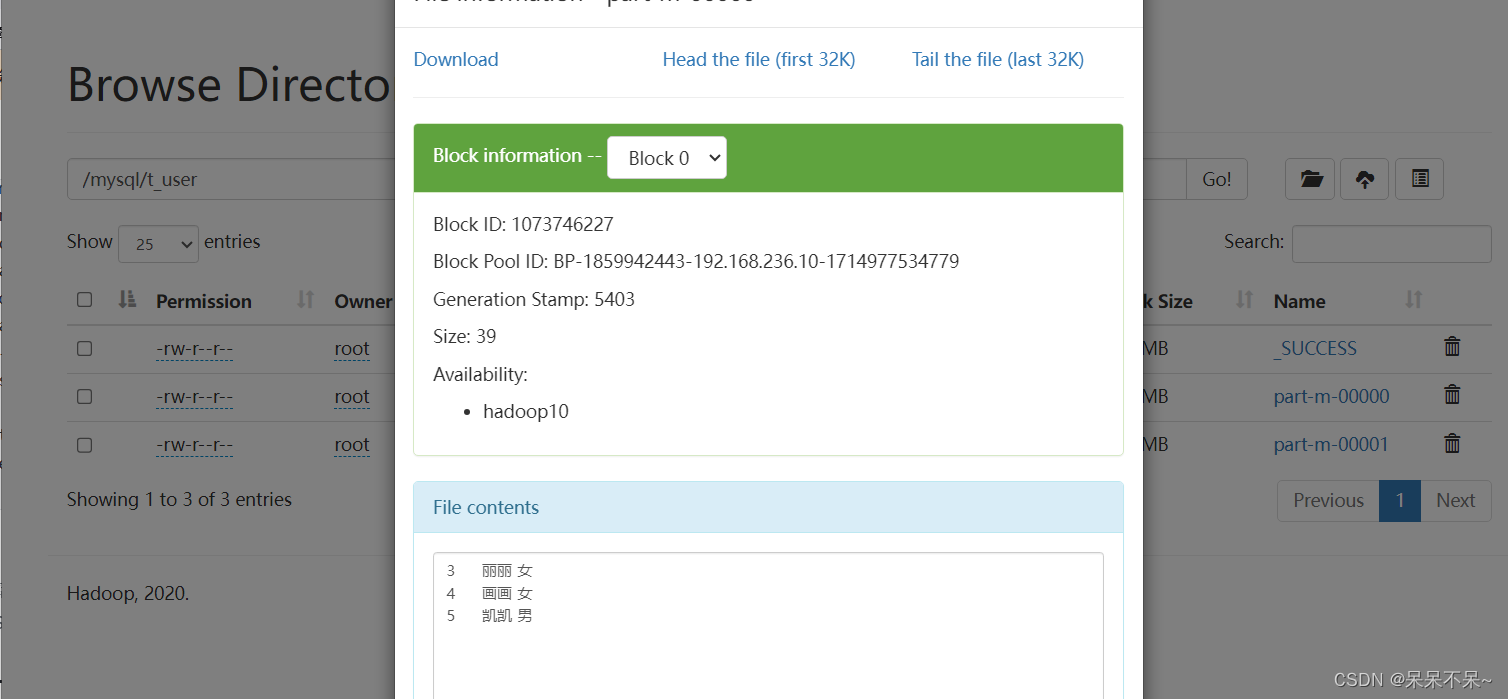
查看hdfs:

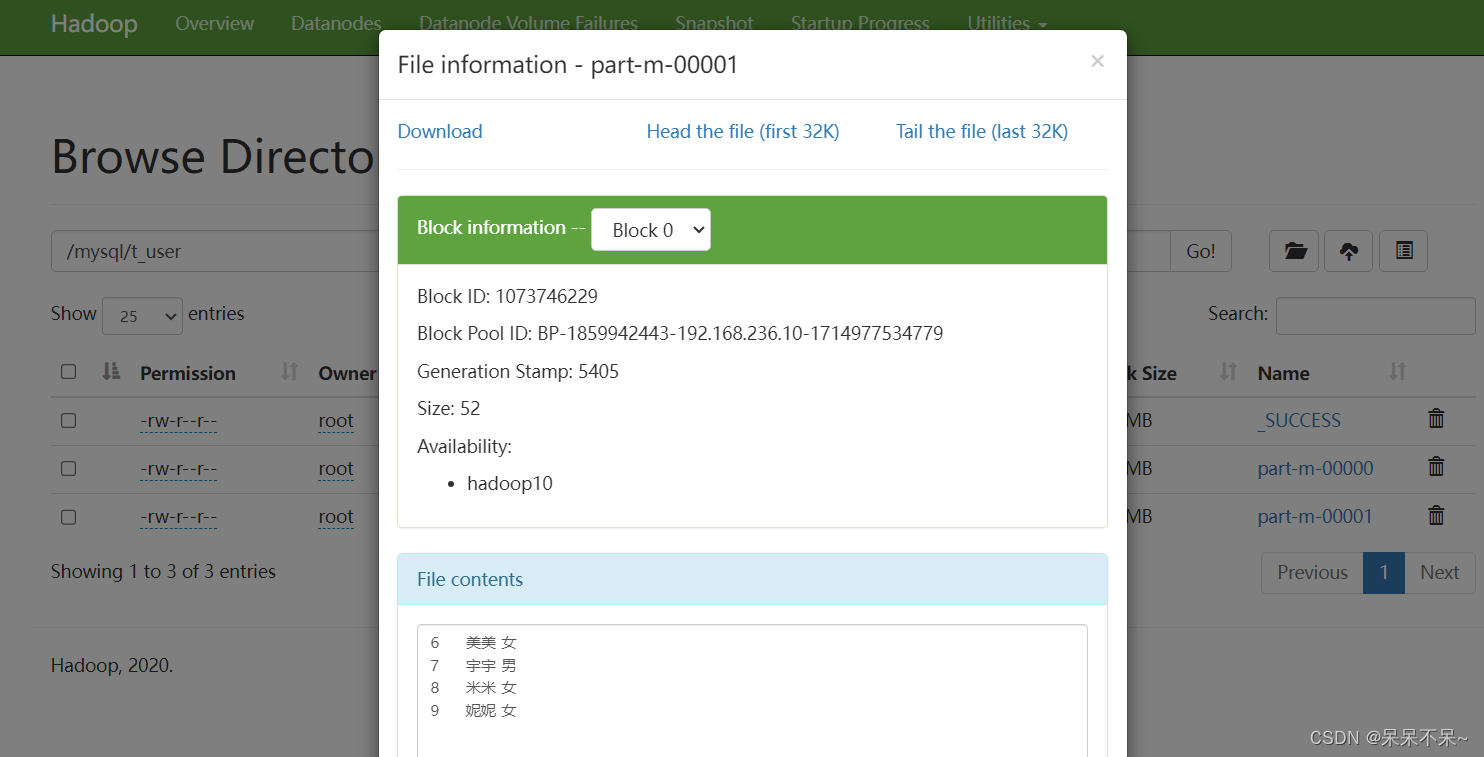
2). RDBMS -> Hive
运行:
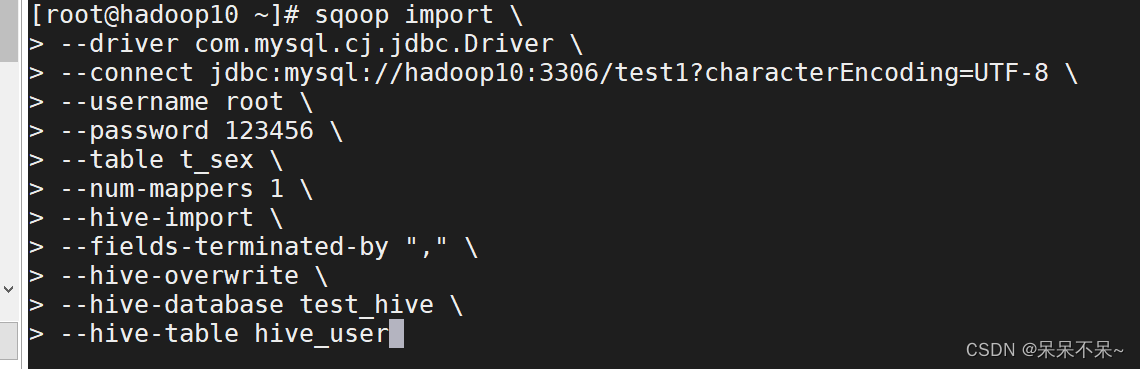
sqoop import \
--driver com.mysql.cj.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_sex \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "," \
--hive-overwrite \
--hive-database test_hive \
--hive-table hive_user--hive-import 代表将数据导入hive
--fields-terminated-by 导入hive后,存储在HDFS上文件的分隔符
--hive-database hive的数据库
--hive-table 上边指定库下的表,可以不存在,会自动创建
--hive-overwrite 将表中数据覆盖
查看hive:
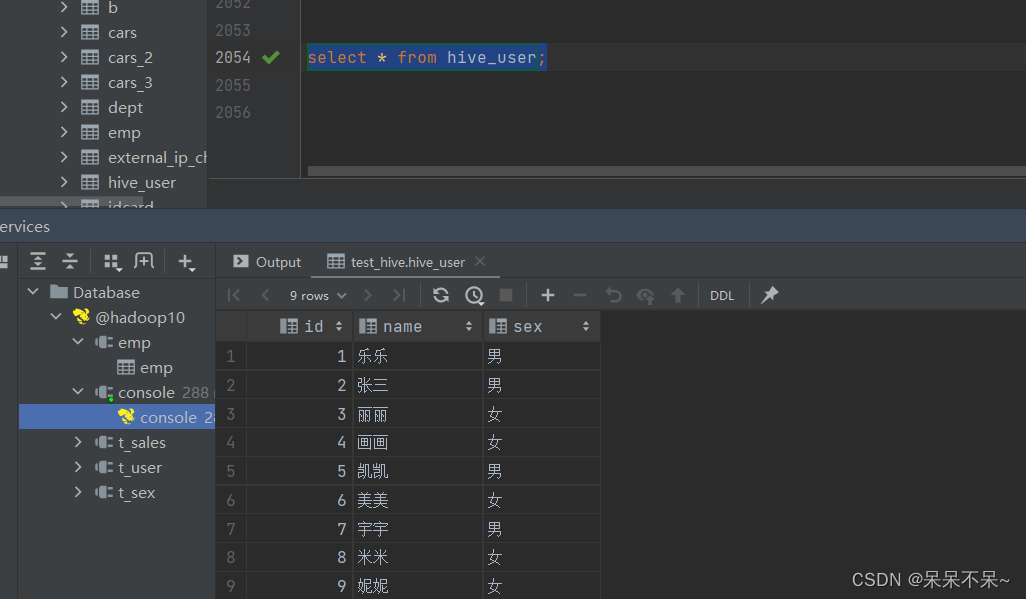
四、sqoop-export
在Sqoop中,“导出”概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群(RDBMS关系型数据库)中传输数据,叫做:导出,即使用export关键字。
1). HDFS|hive -> RDBMS
① 准备数据,上传hdfs的sqoop目录下
vi a.txt
# 在文件中添加如下内容
1 zhangsan true 20 2020-01-11
2 lisi false 25 2020-01-10
3 wangwu true 36 2020-01-17
4 zhaoliu false 50 1990-02-08
5 win7 true 20 1991-02-08#在hdfs上创建sqoop目录(目录名称随意,不过需要和后边对应),将文件上传到sqoop目录下
hdfs dfs -mkdir /sqoop
hdfs dfs -put a.txt /sqoop② 在mysql中创建表
注意:导出并不会自动创建对应的表,需要提前自己创建
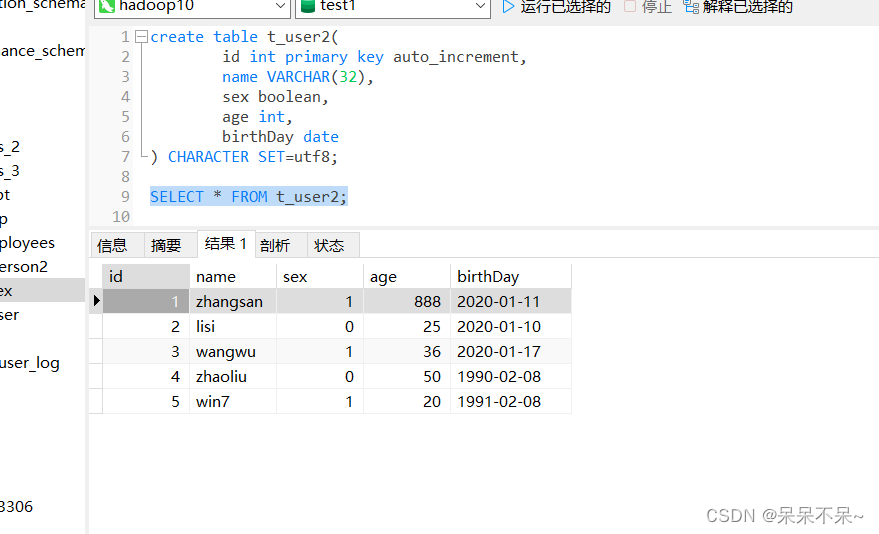
create table t_user2(id int primary key auto_increment,name VARCHAR(32),sex boolean,age int,birthDay date
) CHARACTER SET=utf8;③ 将hdfs上的数据导入mysql表中
sqoop export \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--export-dir /sqoop \
--input-fields-terminated-by ' ' \
--columns "id,name,sex,age,birthDay" \
--table t_user2 \
--update-key id \
--update-mode allowinsert--export-dir 指定导出数据的目录
--table mysql中的表名
--columns 字段名
--update-mode 如果是allowinsert,则允许不但能够导入新数据的时候,还可以更新之前的数据
如果是updateonly,则只会更新以前的数据,不添加新数据
--update-key 如果指定列的值已经存在,则会触发修改操作,否则添加,一般指定主键列
查看mysql:
五、sqoop应用问题汇总
1.sqoop在导入或者导出的时候,空值问题处理。
注意:不用直接通过工具界面修改表中的数据,制造空数据,需要重新添加一条
Hive 中的 Null 在底层是以“\N”来存储,而 MySQL 中的 Null 在底层就是 Null,为了保证数据两端的一致性。导入数据时采用--null-string 和--null-non-string。
导出数据时采用--input-null-string 和--input-null-non-string 两个参数。--null-string含义是 string类型的字段,当Value是NULL,替换成指定的字符
--null-string '\\N' 替换为 \N导入(mysql-->hive):
sqoop import \
--driver com.mysql.cj.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_user \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "," \
--hive-overwrite \
--hive-database test_hive \
--hive-table hive_user \
--null-non-string '\\N' \
--null-string '\\N'mysql表中有空数据:
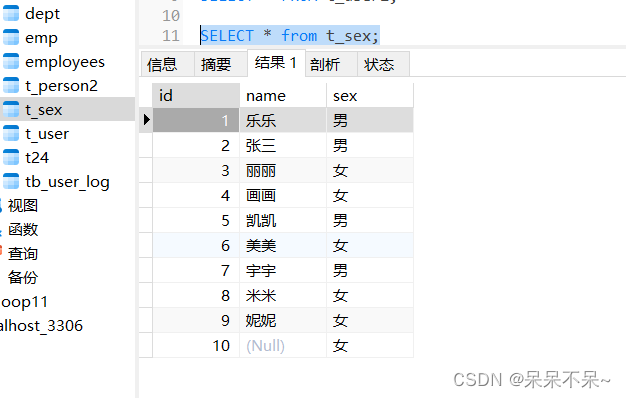
查看hive表:
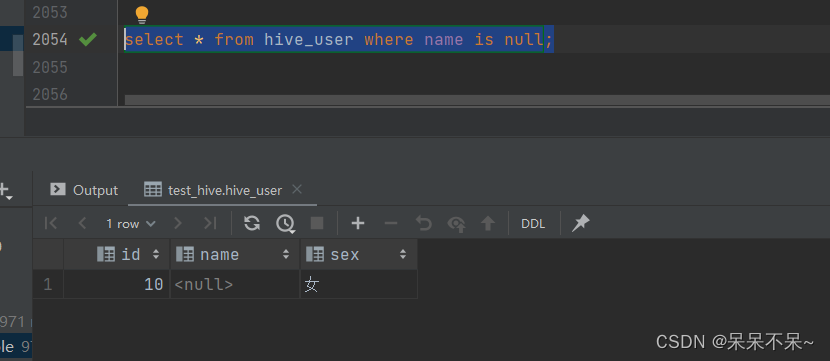
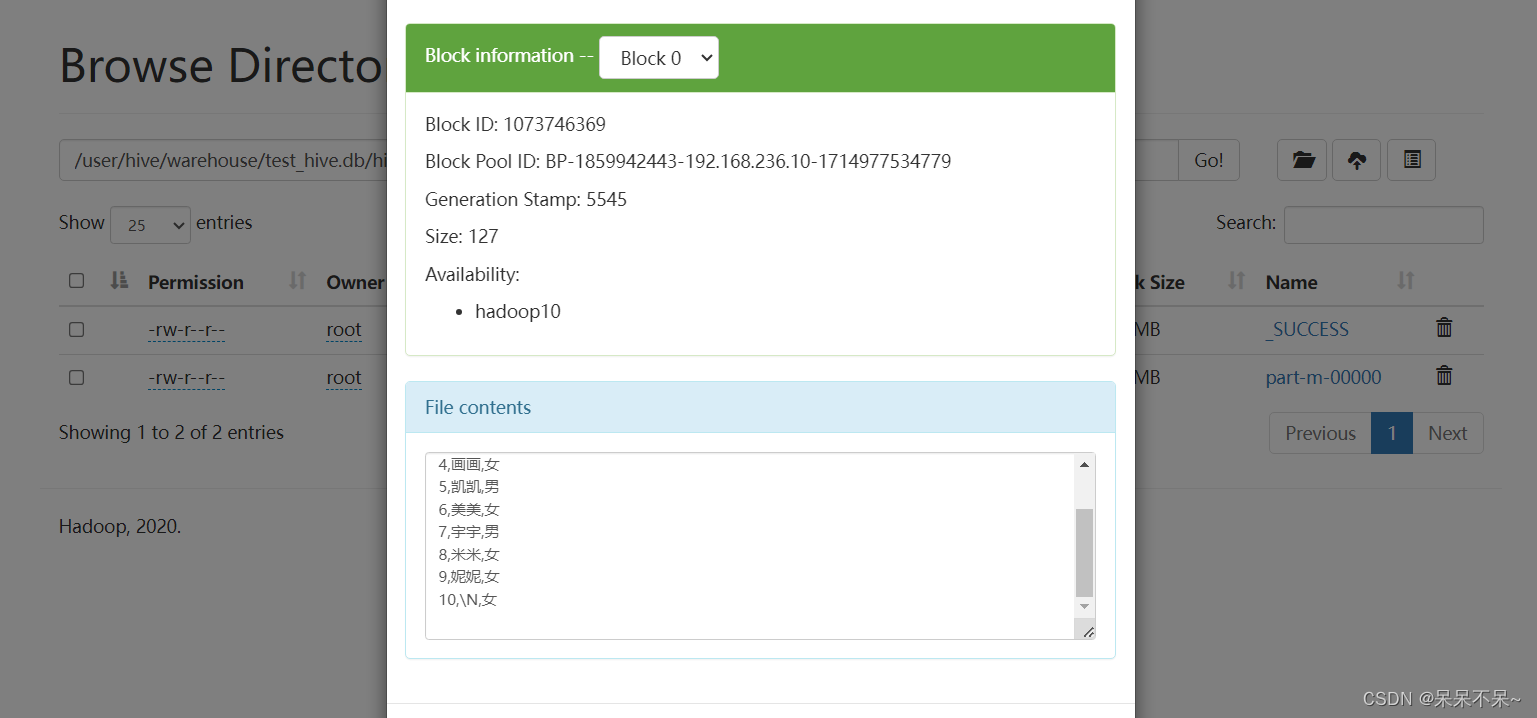
导出(hive-->mysql):
sqoop export \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--export-dir /user/hive/warehouse/test_hive.db/dept \
--input-fields-terminated-by '\t' \
--columns "deptno,dname,loc" \
--table dept \
--update-key deptno \
--update-mode allowinsert \
--input-null-non-string '\\N' \
--input-null-string '\\N'在hive表中插入空值数据:

在mysql查看表:
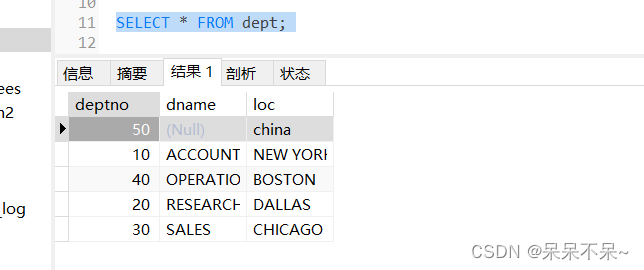
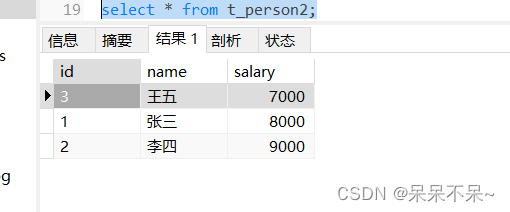
2.将mysql数据导入到hive分区表中
sqoop import \
--driver com.mysql.cj.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_person2 \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "," \
--hive-overwrite \
--hive-database test_hive \
--hive-table t_person2 \
--null-non-string '\\N' \
--null-string '\\N' \
--hive-partition-key dt \
--hive-partition-value 20231220查看mysql表:

查看hive表:

3.将hive分区表导出到mysql
在mysql建表:

sqoop export \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--export-dir /user/hive/warehouse/test_hive.db/t_person2/dt=20231220 \
--input-fields-terminated-by ',' \
--table t_person2 \
--update-key dt \
--update-mode allowinsert \
--input-null-non-string '\\N' \
--input-null-string '\\N'查看表: