我们支持GPU做AI成了王者,除了多核就是因为它的GEMM做的好,换句话说矩阵乘各种优化
那NPU和TPU也是主要因为这个原因被创造出来的
CPU基本支持矩阵就比较难受,因为天生做流水线的,架构决定的,对矩阵乘的优化,也主要是算法优化,比如intel的AMX指令优化,但是还是有限
Llama.cpp呢,它用C写能有很大优势,这是一方面,然后它也可以调度各种cpu的向量化引擎,一定程度上在cpu上可以玩一玩,还有就是量化能力,可是还是不够
CPU做GEMM肯定啥也不是了
那如果是查表呢,就是说有没有一种可能,做深度学习AI这块,Acativation的 矩阵A和权重矩阵W相点乘,就不要硬去大维度乘大维度,而是拆成小的东西互相计算再加呗,反正也能得到最终的矩阵
这个想法肯定是可行的,那就实现它
MS 就把这个东西做出来了,虽然现在是试行版,论文也过了eursys了,被入选了
论文地址:
T-MAC: CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge (arxiv.org)
刚才说了Llama.cpp是挺成功的项目了,量化可以让它在多种非GPU平台上跑,但是其实量化机制,其实对资源占用是部分友好,在低精度到高精度匹配这块,也就是mpGEMM,即multi-presion混合精度,来回转精度的时候,还是挺占资源的
先看一个普通的量化推理是咋做的
加入你有2个32位浮点数表示的权重矩阵W和activation的矩阵A,它俩一起乘太大了,显存装不进去,算起来也费事
W(权重矩阵): | 0.25 | -0.75 | 1.50 | | 1.00 | 2.00 | -1.00 | | 0.00 | 0.50 | -0.50 | A(输入激活矩阵): | 1.00 | 0.25 | | -1.50 | 1.00 | | 0.75 | -1.25 |
你需要先量化了,比如int8方式量化
![]()
假设你的缩放因子0.25,然后我们给他int了
W(权重矩阵,int8): | 1 | -3 | 6 | | 4 | 8 | -4 | | 0 | 2 | -2 | A(输入激活矩阵,int8): | 4 | 1 | | -6 | 4 | | 3 | -5 |
这样两个8位整数的矩阵相乘不就省算力又省显存了吗
低精度计算:Y (int8): | (1*4) + (-3*(-6)) + (6*3) | (1*1) + (-3*4) + (6*(-5)) | | (4*4) + (8*(-6)) + (-4*3) | (4*1) + (8*4) + (-4*(-5)) | | (0*4) + (2*(-6)) + (-2*3) | (0*1) + (2*4) + (-2*(-5)) | 结果: |-4 + 18 + 18 = 40 | 1 - 12 - 30 = -41 | | 16 -48 - 12 = -44 | 4 + 32 + 20 = 56 | | 0 - 12 - 6 = -18 | 0 + 8 + 10 = 18 |
但是你算这个东西对我来说没有用啊,我还得高精度表示,就是弄个逆向
(FP32,浮点数结果): | 40 * 0.25 = 10.0 | -41 * 0.25 = -10.25 | |-44 * 0.25 = -11.0 | 56 * 0.25 = 14.0 | |-18 * 0.25 = -4.5 | 18 * 0.25 = 4.5 |
这一来一回实际上就会丢失了好多的细节和造成的来回的误差,那么实际输入的时候是int8,其实算的时候W和A已经是float16或者int32了,这样你得到的值是相对精确的,这块好理解把,但是占地方。
MS的这个T-MAC,就是想了另一个套路,就是大的算着费劲,那我先把这些矩阵都给缩小,然后小矩阵之间的矩阵乘,我都给算出来值来,然后你要大矩阵之间的点乘,我提前知道大矩阵包含的小矩阵有哪些,然后查出来值再做一次结合就能算出来(矩阵计算基操)
这样虽然说我看似这个与计算挺麻烦但是我后面都查表了,查表的速度那比在线计算可是要快多了的
看一下它的设计思路

它也是分离线和在线,离线主要是要形成你的表
1-bit的串行分解
这一步啥意思呢?我们还是举例子
比如你有个包含以下值的权重矩阵W=[7,5,3.....] 我们就看到753这块
7 (0b111), 5 (0b101), 3 (0b011) -> 分解为 1 位形式:
1BIT INDICES = [111
101
011 ]
对吧,格式先凑合看把,公众号这个编辑真的难受
Tiling and Permutation
就是先把之前的矩阵打散,然后再给化成小的矩阵,比如都化成2*2的小矩阵,这样容易提升查找的命中率,然后为了优化内存的存储方式,再做一个permutation,最后可能就这样(随便举个例子)
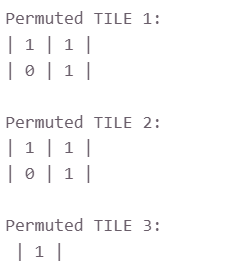
离线的部分就整完了,现在是在线部分了
这个时候激活矩阵A,也就是Activation过来了,它要和W来计算呢
但是不同于以前它要和另外一个大矩阵W做点乘,它现在就可以和这些特别小的矩阵,来进行与计算了,算完了就存储在查找表里,后面具体算哪块
我不是把W矩阵给拆成1-bit的0,1了吗(uint,全是正好,没有负号)
那A过来也得给它拆了
比如 A = [136, 72, 34]

拆完了就和之前我们的那个表(LUT)来做与或计算就完了,相当于查表

查完了之后你多个结果还有bit 串行聚合,比如查完了3个值都是1,那就得3呗,其实思想就这么简单
看一个论文里的例子

左边是LUT 也就是T-MAC的工作方式,这里叫TBL,也就是查表
右边是标准的llama.cpp的量化Inference
左边我们的方式就是拆比如说一个int8的16个元素的矩阵,我当然可以拆成uint4的32个
然后upack的时候,我会给它全是整数的uint8来做,为了match现在的硬件架构么
通过查表,我能直接得出来来int8的结果,也就是我几乎没什么计算量(当然查表也算计算)
在给反量化成要的值比如float16
右边就是传统的了
int8,想保精度来算点乘,就先给转成int32的矩阵了,然后最后int32转float16,想想这边的资源都占的会更多
因为几乎不需要什么矩阵计算,所以cpu上会有一定的优势,但是GPU上,T-MAC就还是算了,毕竟GPU-NPU就是玩矩阵的

如上图所示,在高通骁龙8gen3上测试,4bit的llama2-7b量化,能力基本上可以等同于NPU的能力(骁龙模组带的)
每秒10个token其实也很接近于人最舒服的阅读方式了(15个)
llamacpp一直都很稳定,基本8个吧
总结:
CPU上可以玩,但是现在坦率说刚出来模型支持有限,工具链和生态也没起来,愿意玩的可以自己琢磨
另外GPU和NPU上就算了,它不但没什么提升,而且它查表就要频繁访问内存,由于片载内存sram啥的太小了,不太可能存它,所以放在外面的内存显存上,其实这个还是很影响延迟的
GPU NPU就老实的玩GEMM就可以了