每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

Ai2,一家非营利性研究机构,发布了一系列名为 Molmo 的开源多模态语言模型,据称其性能与来自 OpenAI、Google 和 Anthropic 的顶级专有模型相当。https://molmo.allenai.org/
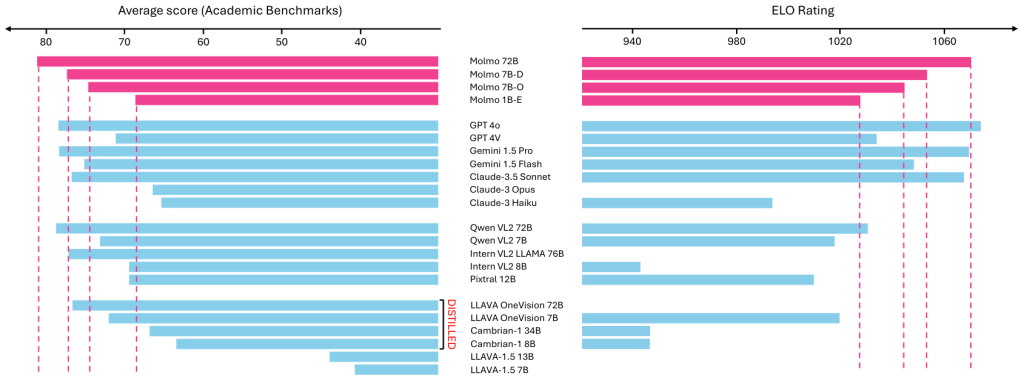
该组织声称,其最大的 Molmo 模型,具有 720 亿个参数,在测试中胜过了 OpenAI 的 GPT-4o(估计具有超过 1 万亿个参数),这些测试衡量了理解图像、图表和文档等方面的能力。
与此同时,Ai2 表示,一个较小的 Molmo 模型,具有 70 亿个参数,在性能上接近 OpenAI 的最先进模型,它将这一成就归功于更高效的数据收集和训练方法。
Ai2 的首席执行官 Ali Farhadi 表示,Molmo 表明开源 AI 开发现在与封闭、专有模型不相上下。开源模型具有显著优势,因为它们的开放性意味着其他人可以在它们的基础上构建应用程序。Molmo 演示可在[链接]上找到,开发者可以在 Hugging Face 网站上对其进行试验。(最强大的 Molmo 模型的某些元素仍然受到保护。)
其他大型多模态语言模型是在包含数十亿个从互联网上收集的图像和文本样本的庞大数据集上训练的,它们可以包含数万亿个参数。这个过程给训练数据带来了大量噪声,以及随之而来的幻觉,Ai2 的高级研究总监 Ani Kembhavi 说。相比之下,Ai2 的 Molmo 模型是在一个明显更小且经过精心挑选的数据集上训练的,该数据集仅包含 60 万张图像,并且它们具有 10 亿到 720 亿个参数。Kembhavi 说,专注于高质量数据而不是不加选择地抓取数据,导致在更少的资源下实现了良好的性能。
研究人员长期以来对什么是开源 AI 存在分歧。一个有影响力的群体提出了一个答案。
Ai2 通过让人类注释者对模型训练数据集中的图像进行极其详细的多页文本描述来实现这一点。他们要求注释者谈论他们所看到的,而不是打字。然后,他们使用 AI 技术将他们的语音转换为数据,这使得训练过程更快,同时减少了所需的计算能力。
Hugging Face 的机器学习和社会负责人 Yacine Jernite(未参与这项研究)表示,这些技术如果我们想要有意义地管理用于 AI 开发的数据,可能会非常有用。斯坦福基础模型研究中心主任 Percy Liang(也未参与这项研究)表示:“通常,在更高质量的数据上训练可以降低计算成本。”
另一个令人印象深刻的能力是该模型可以“指向”事物,这意味着它可以通过识别回答查询的像素来分析图像的元素。
在演示中,Ai2 研究人员拍摄了他们办公室外当地西雅图码头的一张照片,并要求模型识别图像的各种元素,例如躺椅。该模型成功地描述了图像的内容,计算了躺椅的数量,并准确地指向了图像中的其他事物,因为研究人员要求。然而,它并不完美。例如,它无法找到特定的停车场。
Farhadi 说,其他先进的 AI 模型擅长描述场景和图像。但是,当你想要构建能够与世界交互的更复杂的网络代理时,这还不够,例如,预订航班。他表示,指向允许人们与用户界面进行交互。
Jernite 表示,Ai2 的开放程度比我们从其他 AI 公司看到的更高。虽然 Molmo 是一个好的开始,但他表示,它的真正意义在于开发者在其基础上构建的应用程序以及人们改进它的方式。
Farhadi 同意。在过去几年中,AI 公司吸引了巨大的、数万亿美元的投资。但在过去几个月里,投资者对这种投资是否会带来回报表示怀疑。他认为,庞大而昂贵的专有模型无法做到这一点,但开源模型可以。他说,这项工作表明,开源 AI 也可以以一种高效利用资金和时间的方式构建。
“我们很高兴能够帮助他人并看到其他人会用它来构建什么,”Farhadi 说。
一直以来,大家普遍认为只有像谷歌、OpenAI、Anthropic这些拥有无尽资金和数百名顶级研究人员的公司,才能打造出最先进的基础模型。然而,就连他们自己也承认,所谓的技术“护城河”并不存在。今天,Ai2(Allen Institute for AI)通过发布Molmo这一多模态AI模型,再次证明了这一点。Molmo不仅能媲美这些巨头的产品,而且体积小、完全免费,真正实现了开源。
需要明确的是,Molmo(多模态开放语言模型)是一种视觉理解引擎,而非像ChatGPT那样的全功能聊天机器人。它没有API接口,不支持企业集成,也不会自动搜索互联网内容。更准确地说,Molmo是那些AI模型中负责“看图说话”的部分,它能识别图像、理解其中的内容并回答相关问题。
Molmo分为72B、7B和1B参数三种版本,和其他多模态模型一样,它能回答关于日常情境和物品的问题。例如:如何操作这台咖啡机?这张照片中有多少只狗伸出舌头?菜单上哪些选项是素食?这些视觉理解任务多年来已经以不同成功率和延迟性展示过了。
但真正让Molmo脱颖而出的,不仅仅是其功能,而是它实现这些功能的方式。
视觉理解本身涵盖广泛的领域,从数羊到猜测人的情绪状态,再到总结菜单内容,范围很难用简单的定量测试描述。不过,Ai2的CEO Ali Farhadi在其位于西雅图的研究所演示会上解释说,至少可以通过展示两种模型在能力上的相似性来证明它们的效果。
“我们今天要展示的是,‘开源’等于‘闭源’,‘小’等于‘大’。”他说(他特别强调,这里的等号代表的是‘等效性’,而非‘同一性’,这是个有趣的细微差别)。
AI发展中的一条不变定律是“越大越好”:更多的训练数据、更复杂的模型、更强大的计算力。然而,模型变大终究会遇到瓶颈:没有足够的数据、计算成本过高,最终变得事倍功半。这时,如何用更少的资源做到更多,才是关键。
Farhadi解释道,虽然Molmo与GPT-4、Gemini 1.5 Pro和Claude-3.5 Sonnet等模型的表现不相上下,但其体积只有它们的十分之一左右。通过小型化模型,Molmo实现了几乎相同的能力。
他还提到,虽然AI领域有很多不同的评估基准,他并不太喜欢这种“数字游戏”。但为了给大家展示成果,必须提供一些数据:“我们最大的模型是72B参数,但它在那些基准测试中表现优于GPT、Claude和Gemini。我们不确定这是否意味着Molmo真的比它们更好,但至少它在同一个领域内竞争。”
如果你有兴趣挑战Molmo,欢迎使用其公开演示版(甚至可以在手机上测试)。演示中的一个新功能是,它能精准“指出”图片中的相关部分。比如,问它一张照片里有几只狗,它会在每只狗脸上打个点;问它照片里有多少只狗伸出舌头,它会在每只舌头上标注。这种具体化的识别使得Molmo可以在没有预先训练的情况下完成各种任务。
最重要的是,Molmo完全免费且开源,体积小到可以在本地运行。不需要API、不需要订阅服务,甚至不需要一台高端GPU服务器。Ai2的目标是让开发者能够轻松创建AI应用,而不必依赖那些大型科技公司。
Farhadi补充道,Ai2已经公开了所有相关的数据、清理方法、注释、训练代码、模型检查点和评估标准,完全开放给任何人使用。他预计,开发者们会马上开始使用这些资源,包括那些资金雄厚的竞争对手。
随着AI领域日新月异地发展,各大公司正逐渐陷入价格战的漩涡,纷纷将价格压到最低。既然开源模型能提供类似的能力,那么这些公司提供的服务价值还能有多高呢?至少,Molmo证明了,即使巨头的“帝王新衣”问题仍悬而未决,他们的“护城河”确实已经消失了。