多任务学习,也就是(Multi-task Learning,MTL),它在计算机视觉和自然语言处理这些领域已经用得很广泛了。在推荐系统这块,用MTL也成了一个热门话题。MTL的方法通过考虑用户行为的多个方面,能提供更个性化、更贴切的推荐。这篇文章就是来聊聊推荐系统里的MTL是怎么一回事,还会好好回顾一下现在有哪些方法能让我们构建出更牛的MTL推荐系统。
咱们平时看到的推荐系统,大多数就只干一件事,比如预测个评分或者点击啥的。这些系统没有好好利用不同任务之间的共同点,而且如果训练数据不够多,它们的表现就可能不太好。但是,有了MTL,推荐模型就能在一个模型里头同时学好几个相关任务,这样就能更好地用上它们之间的共同知识,相互之间还能有所提高。
真实世界里头,用户对不同的内容或者项目会有很多不同的反应。比如在YouTube、抖音这样的视频平台上,用户可能通过点击、观看、点赞、分享、评论等等不同的方式来互动。每个用户对这些行为的喜好程度可能都不一样。如果推荐系统只考虑用户的点击行为,可能就抓不住他们真正的喜好。但如果我们再加上点赞、分享和观看时长这些额外的任务,模型就能更精确地预测用户的短期意图和长期兴趣,还有内容的参与情况。
用MTL技术在推荐领域里,能带来好几个好处:
-
提高性能:考虑多个相关因素,比如点击率、完成率、分享、收藏这些,能从多个角度理解用户的兴趣。理想情况下,这些任务之间是相互促进的,这样推荐效果就能更好。
-
促进泛化:MTL的策略,比如学一些辅助任务,能带来正则化的效果。这有助于减少过拟合,让模型在各种情况下都能表现得很稳健,也能适应得更好。
-
减少偏见:一起学多个任务时,那些训练数据多的任务能帮到数据少的任务。这样,训练和实际使用时数据分布的差距就能减小,有效减少样本选择偏见这些问题。
-
处理数据稀疏性:把推荐模型和一些辅助任务一起训练,能帮模型抓到更多有用的特征,解决主要任务的用户行为数据稀疏的问题。
-
缓解冷启动问题:利用相关任务或领域的数据,MTL技术能减轻冷启动的问题。比如,新用户在主要任务上没有购买数据,但通过点击历史、分享或评论这些辅助任务,就可以帮助我们了解他们的偏好。
-
成本效益:MTL框架支持参数共享,还能统一不同任务的数据流程。这样一来,维护成本和计算资源都能大幅减少。
-
可解释性:还有研究人员提出,可以用学习到的不同任务的权重比例来生成推荐解释,这样用户就能明白为什么会得到这样的推荐。
虽然MTL技术有这么多优点,但它也可能面临一些挑战,比如任务关系复杂、数据稀疏,还有用户行为的序列依赖性这些问题。

咱们一块儿在一个网络中同时从多个任务学习,这些任务要是有强相关性,那性能自然就上去了。但要是它们互相之间没啥关系,或者关系太弱,那可能就会拖后腿,这情况咱们叫它“跷跷板现象”。很多MTL的老研究都是基于任务之间有关系这个前提的。可要是一开始咱们就不知道这些任务到底啥关系,那就得找办法自动发现它们之间的关系。所以,咱们给基于MTL的推荐系统分分类,一种方式就是看看这些任务关系是咋建模的。
-
并行任务关系:MTL的一个招儿就是把这些任务分开来,单独建模,不用考虑它们之间是不是有先后顺序的影响。这种模型一般会把目标函数设成损失的加权和,而且这些权重都是固定的。还有些研究用上了注意力机制,来抓取一些可以在不同任务之间共享的特征。这类方法里头,有几个挺有代表性的,像是Rank and Rate (RnR)、Multi-Task Explainable Recommendation (MTER)、Co-Attentive Multi-Task Learning (CAML)、Deep Item Network for Online Promotions (DINOP)、Deep User Perception Network (DUPN)、Multiple Relational Attention Network (MRAN)。
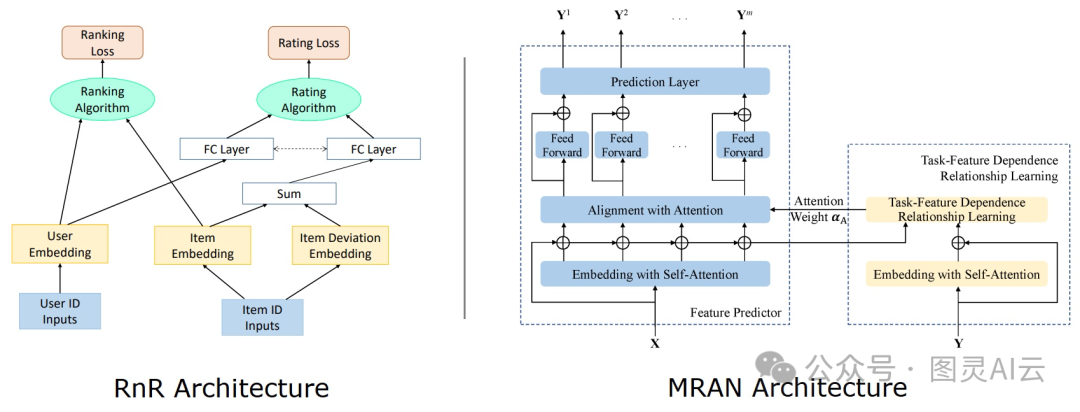
并行任务关系:示例架构
-
级联任务关系:还有些MTL的技术,它们会考虑任务之间是有先后顺序的,就像是多米诺骨牌一样,一个任务的结果会影响下一个任务。这种模型在电商、广告和金融这些领域挺常见的,它们通常会根据用户的行为模式来设定一个序列,比如“先展示商品,然后用户点击,最后购买”。在这个类别里,有几个做得不错的,比如Adaptive Pattern Extraction Multi-task (APEM)、Adaptive Information Transfer Multi-task (AITM)和Entire Space Multi-task Model (ESMM)。
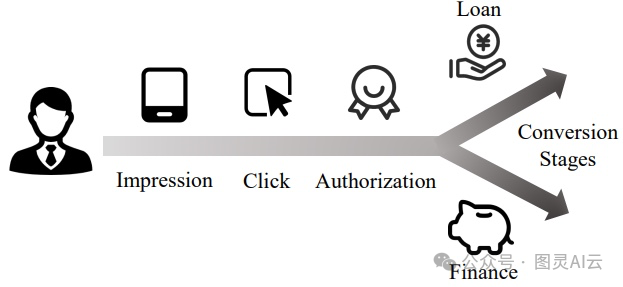
级联任务关系:金融领域中的一个序列依赖性示例
-
辅助任务学习:这种MTL技术里,咱们挑一个任务当主角,其他的都算是配角,它们存在的意义就是帮主角提升表现。在好几个任务一起优化的时候,很难做到每个任务都获益。所以,有的MTL技术就是以提高主要任务的性能为目标,哪怕牺牲一些辅助任务的性能。用上整个空间的辅助任务,能在预测主要任务的时候提供更丰富的背景信息。这个领域的研究包括了Multi-gate Mixture-of-Experts (MMoE)、Progressive Layered Extraction (PLE)、Multi-task Inverse Propensity Weighting estimator (Multi-IPW)、Multi-task Doubly Robust estimator (Multi-DR)、Distillation based Multi-task Learning (DMTL)、Multi-task framework for Recommendation over HIN (MTRec)、Cross-Task Knowledge Distillation (Cross-Distill)和Contrastive Sharing Recommendation model in MTL learning (CSRec)这些。
再来看看MTL技术的另一种分类方法,就是根据这些年来咱们开发的各种网络架构和学习策略。接下来,咱们要回顾三类MTL研究。注意,这不是绝对的分类,有的模型可能属于多个类别。
MTL的一个常见策略是在底层或者塔层共享参数。咱们对这种参数共享的方式分了下面几类:
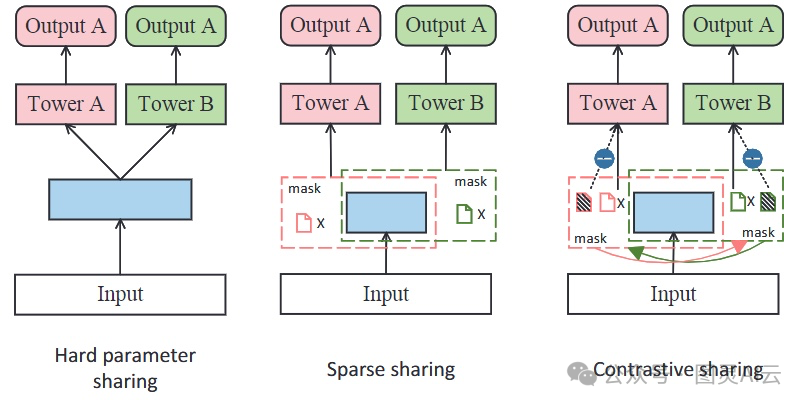
参数共享范式。蓝色代表共享参数,粉色和绿色代表任务特定参数
-
硬共享:硬共享就是让不同的任务用同一套底层来提取信息,然后再用各自特有的层去抓取不同的特征。这种模型算起来快,能防止模型学得太死板,而且在任务之间关系紧密的时候效果特别好。但是,如果任务之间关系没那么紧密或者有点乱,性能可能就没那么理想了。Meta AI的MetaBalance、腾讯的多面层次MTL模型(MFH)和任务自适应学习(AdaTask)都是这种硬共享的例子。
-
稀疏共享:稀疏共享算是硬共享的一个特殊情况,它解决了计算和内存不够用的问题,还能灵活应对那些关系不是很强的任务。这个方法用独立的参数掩码把不同的子网络连到共享的参数空间里。用上网络剪枝的技术,每个任务都能从自己的子网络里提取有用的知识,避免参数太多太杂。蚂蚁集团的多级稀疏共享模型(MSSM)就是用这种稀疏共享技术的。
-
对比共享:有时候,用稀疏共享的方法还是可能会遇到负迁移的问题,就是共享参数的时候不小心把一些噪声也带进来了,导致某些任务的性能下降。为了解决这个问题,有人提出了对比共享的方法,比如对比共享推荐模型(CSRec),它只更新那些对特定任务影响比较大的参数。这个方法跟稀疏共享类似,也是用独立的参数掩码去学习每个任务,但是它会特别设计一个对比掩码,来评估每个参数对特定任务的贡献有多大。
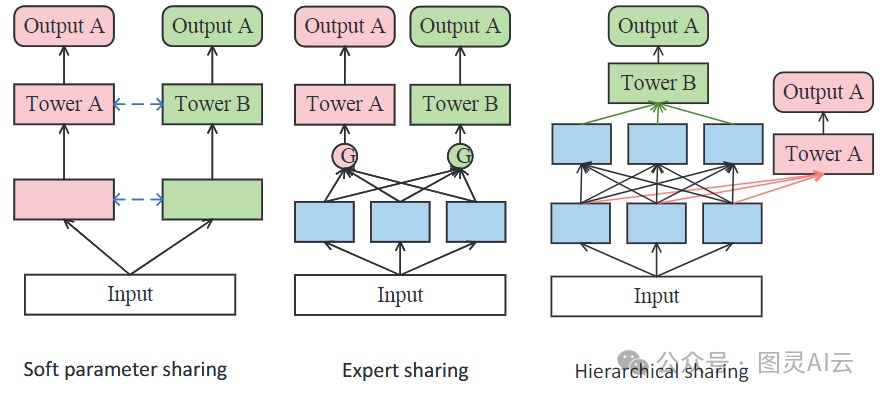
参数共享范式。蓝色代表共享参数,粉色和绿色代表任务特定参数
-
软共享:软共享的方法给每个任务都单独建模,然后用权重或者注意力机制来把信息融合起来共享。这种方式比硬共享更灵活,但计算起来可能更费事儿。用这种架构的模型有Deep Item Network for Online Promotions (DINOP)、Gating-enhanced Multi-task Neural Networks (GemNN)、Co-Attentive Multi-Task Learning (CAML)、Causal Feature Selection Mechanism for Multi-task Learning (CFS-MTL)和Multi-objective Risk-aware Route Recommendation (MARRS)这些。
-
专家共享:专家共享是软共享的一种特殊情况,它用任务特定的权重把专家们的知识结合起来。就是先让好几个专家网络从共享的底层提取知识,然后把这些知识送到任务特定的模块里去学习有用的信息,最后把整合好的信息送到任务特定的塔里去。Multi-gate Mixture-of-Experts (MMoE)和Progressive Layered Extraction (PLE)就是这种架构的流行例子。其他的例子还有Distillation based Multi-task Learning (DMTL)、Meta Hybrid Experts and Critics (MetaHeac)、Prototype Feature Extraction (PFE)、Mixture of Virtual-Kernel Experts (MVKE)、Mixture of Sequential Experts (MoSE)、Deep Multifaceted Transformers (DMT)和Elaborated Entire Space Supervised Multi-task Model (ESM2^2)。
-
层次共享:为了应对不同类型的任务,层次共享架构把不同的任务放在不同的层级上,让它们共享网络的一部分。设计一个好的层次共享架构可能挺费时间的。这个类别里的代表性研究有多面层次MTL模型(MFH)和层次多任务图循环网络(HMT-GRN)。
大多数基于MTL的推荐系统都按照上面说的那些参数共享架构来设计。不过,也有一些其他的架构,比如对抗性学习。像CnGAN和CLOVER这样的模型就用到了基于MTL技术的生成对抗网络(GAN)来做推荐。还有的是基于强化学习(RL)的MTL模型,比如基于批量强化学习的多任务融合框架(BatchRL-MTF),也被提出来构建推荐系统。
在一块儿优化的时候,任务之间传递了不该传递的信息,也可能导致性能下降或者跷跷板现象。就是说,一个或者几个任务的性能提高了,但是别的任务就受到了影响。负迁移的一个常见表现就是梯度冲突,也就是不同任务的梯度方向夹角大于90度。有些方法比如投影冲突梯度(PCGrad)和冲突规避梯度下降(CAGrad)就是为了解决这个问题提出来的。像Progressive Layered Extraction (PLE)和对比共享推荐模型在MTL学习(CSRec)这样的模型也提出了自己的解决方案。不同任务的梯度大小差异太大,也可能导致性能下降。梯度归一化(GradNorm)和MetaBalance这样的方法就有助于控制梯度的大小。任务自适应学习(AdaTask)模型也提出了自己的自适应学习解决方案。
跟负迁移类似,另一个多目标的问题是调整损失权重。通常的MTL策略是把多个任务的损失值通过加权和的方式结合起来。通过改变对应任务的损失权重,就能调整特定任务在所有任务中的重要性。设计一个自动化的任务平衡机制来权衡任务损失,这可能是个挺有挑战性的任务。
