摘要
本文使用动态上采样改进YoloV10,动态上采样是今天最新的上采样改进方法,具有轻量高效的特点,经过验证,在多个场景上均有大幅度的涨点,而且改进方法简单,即插即用!

论文:《DySample:Learning to Upsample by Learning to Sample》
论文:https://arxiv.org/pdf/2308.15085
我们提出了DySample,一个超轻量级且高效的动态上采样器。虽然最近的基于内核的动态上采样器,如CARAFE、FADE和SAPA,取得了令人印象深刻的性能提升,但它们引入了大量的计算量,这主要是由于耗时的动态卷积以及用于生成动态内核的附加子网络。此外,FADE和SAPA对高分辨率特征指导的需求在某种程度上限制了它们的应用场景。为了解决这些问题,我们避开了动态卷积,从点采样的角度构建上采样器,这种方法更加资源高效,并且可以轻松地使用PyTorch中的标准内置函数实现。我们首先展示了一个简单的设计,然后逐步演示如何加强其上采样行为,最终得到我们的新上采样器DySample。与之前的基于内核的动态上采样器相比,DySample无需定制CUDA包,并且具有更少的参数、浮点运算次数、GPU内存和延迟。除了轻量级的特性外,DySample在五个密集预测任务上优于其他上采样器,包括语义分割、目标检测、实例分割、全景分割和单目深度估计。代码可在https://github.com/tiny-smart/dysample获取。
1、引言
特征上采样是密集预测模型中的关键组件,用于逐步恢复特征分辨率。最常用的上采样器是最近邻(NN)和双线性插值,它们遵循固定的规则来插值上采样值。为了增加灵活性,在一些特定任务中引入了可学习的上采样器,例如实例分割中的反卷积[13]和图像超分辨率中的像素洗牌[34][31, 12, 22]。然而,它们要么容易受到棋盘格效应的影响[32],要么似乎并不适用于高级任务。随着动态网络[14]的普及,一些动态上采样器在多个任务上展现了巨大的潜力。CARAFE[37]通过动态卷积生成内容感知的上采样核来对特征进行上采样。随后的工作FADE[29]和SAPA[30]提出结合高分辨率引导特征和低分辨率输入特征来生成动态核,以便上采样过程可以由更高分辨率的结构进行指导。这些动态上采样器通常结构复杂,需要定制的CUDA实现,并且比双线性插值消耗更多的推理时间。特别是对于FADE和SAPA,高分辨率引导特征的引入甚至增加了更多的计算工作量,并限制了它们的应用场景(必须提供高分辨率特征)。与早期的简单网络[27]不同,现代架构中经常使用多尺度特征;因此,将高分辨率特征作为上采样器的输入可能并不是必要的。例如,在特征金字塔网络(FPN)[23]中,高分辨率特征会在上采样后添加到低分辨率特征中。因此,我们认为设计良好的单输入动态上采样器就足够了。
考虑到动态卷积引入的繁重工作量,我们绕过了基于内核的范式,回归到上采样的本质,即点采样,重新定义了上采样过程。具体来说,我们假设输入特征通过双线性插值被插值到一个连续的特征图,然后生成内容感知的采样点来重新采样这个连续的特征图。从这个角度出发,我们首先展示了一个简单的设计,其中逐点偏移量通过线性投影生成,并使用PyTorch中的grid_sample函数重新采样点值。然后,我们展示了如何通过逐步调整来改进它,包括i)控制初始采样位置,ii)调整偏移量的移动范围,以及iii)将上采样过程分为几个独立的组,从而得到我们的新上采样器DySample。在每一步中,我们都会解释为什么需要这个调整,并进行实验来验证性能提升。
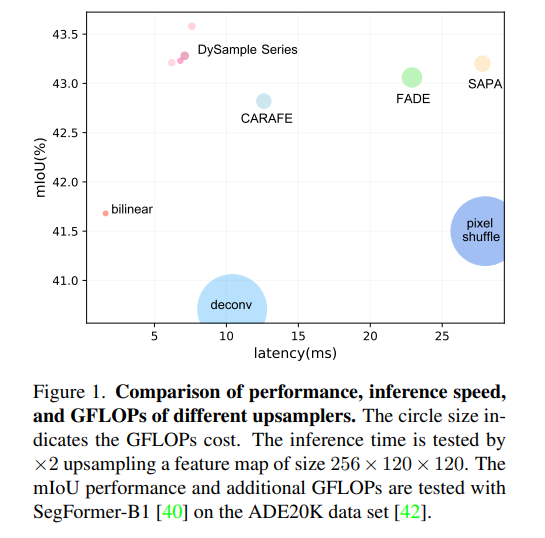
与其他动态上采样器相比,DySample具有以下优势:i) 不需要高分辨率引导特征作为输入;ii) 除了PyTorch之外,不需要任何额外的CUDA包;特别地,iii) 具有更低的推理延迟、内存占用、浮点运算次数和参数数量,如图1和图8所示。例如,在以MaskFormer-SwinB[8]为基准的语义分割任务中,DySample比CARAFE多带来了46%的性能提升,但仅需CARAFE的3%的参数数量和20%的浮点运算次数。由于高度优化的PyTorch内置函数,DySample的推理时间也接近双线性插值(当对256×120×120的特征图进行上采样时,分别为6.2ms和1.6ms)。除了这些引人注目的轻量级特性外,DySample还在五个密集预测任务(包括语义分割、目标检测、实例分割、全景分割和单目深度估计)中报告了比其他上采样器更好的性能。
综上所述,考虑到有效性和效率,我们认为DySample可以安全地替代现有密集预测模型中的最近邻/双线性插值。
2、相关工作
我们回顾了密集预测任务、特征上采样算子和深度学习中的动态采样。
密集预测任务。密集预测是指需要逐点标签预测的一类任务,如语义/实例/全景分割[2,39,40,8,7,13,11,16,19]、目标检测[33,4,24,36]和单目深度估计[38,18,3,21]。不同的任务往往具有不同的特点和难点。例如,在语义分割中,同时预测平滑的内部区域和锐利的边缘是困难的,在实例感知任务中区分不同的对象也是具有挑战性的。在深度估计中,具有相同语义意义的像素可能具有完全不同的深度,反之亦然。因此,人们通常需要为不同的任务定制不同的架构。
尽管模型结构各异,但上采样算子在密集预测模型中都是必不可少的组成部分。由于骨干网络通常输出多尺度特征,因此需要将低分辨率特征上采样到更高分辨率。因此,一个轻量级、有效的上采样器将有利于许多密集预测模型。我们将展示我们新的上采样器设计在SegFormer[40]和MaskFormer[8]上的语义分割、Faster R-CNN[33]上的目标检测、Mask R-CNN[13]上的实例分割、Panoptic FPN[16]上的全景分割以及DepthFormer[21]上的单目深度估计方面带来了一致的性能提升,同时引入了可忽略的工作量。
总之,我们的DySample上采样器在多个密集预测任务中均表现出色,其高效和轻量级的特性使其成为现有密集预测模型中最近邻/双线性插值的安全替代品。通过优化PyTorch内置函数,DySample在保持高性能的同时,还降低了推理延迟和内存占用,使得它在实时应用和资源受限的环境中具有更大的优势。此外,DySample的灵活性和通用性也使其能够适应不同任务和模型的需求,为深度学习领域的进一步发展提供了有力支持。
特征上采样。常用的特征上采样器包括最近邻插值(NN)和双线性插值。它们应用固定的规则对低分辨率特征进行插值,忽略了特征图中的语义信息。SegNet[2]在语义分割中采用了最大反池化(Max Unpooling)来保留边缘信息,但噪声和零填充的引入破坏了平滑区域的语义一致性。与卷积类似,一些可学习的上采样器在上采样过程中引入了可学习的参数。例如,反卷积(Deconvolution)以卷积的反向方式对特征进行上采样。Pixel Shuffle[34]首先使用卷积增加通道数,然后重塑特征图以提高分辨率。
最近,一些动态上采样算子进行了内容感知的上采样。CARAFE[37]使用子网络生成内容感知的动态卷积核来重新组合输入特征。FADE[29]提出结合高分辨率和低分辨率特征来生成动态核,以便利用高分辨率结构。SAPA[30]进一步引入了点的归属概念,并计算高分辨率和低分辨率特征之间的相似性感知核。作为模型插件,这些动态上采样器增加了比预期更多的复杂性,尤其是FADE和SAPA需要高分辨率特征输入。因此,我们的目标是贡献一个简单、快速、低成本且通用的上采样器,同时保留动态上采样的有效性。
我们的DySample上采样器正是基于这样的需求而设计的。它结合了动态上采样的优点,同时避免了复杂性和高成本。DySample采用一种简单而高效的方法来生成内容感知的上采样结果,无需额外的高分辨率特征输入。这使得DySample在保持高性能的同时,降低了模型的复杂性和计算成本。此外,DySample还具有通用性,可以适应不同的任务和模型架构。通过与其他上采样器的对比实验,我们证明了DySample在多个密集预测任务中的优越性,为深度学习领域的发展提供了新的可能性。
动态采样。上采样是对几何信息进行建模。一系列的工作也通过动态地对图像或特征图进行采样来建模几何信息,作为标准网格采样的替代方案。Dai等人[9]和Zhu等人[43]提出了可变形卷积网络,其中标准卷积中的矩形窗口采样被替换为偏移点采样。Deformable DETR [44]遵循这种方式,并相对于某个查询采样关键点以进行可变形注意力。当图像被下采样为低分辨率图像以进行内容感知的图像调整大小(也称为接缝雕刻[1])时,也采取了类似的做法。例如,Zhang等人[41]提出学习用显著性指导对图像进行下采样,以保留更多原始图像的信息,Jin等人[15]也设置了一个可学习的变形模块来对图像进行下采样。
与最近的基于核的上采样器不同,我们将上采样的本质解释为点重采样。因此,在特征上采样中,我们倾向于遵循上述工作的相同精神,并使用简单的设计来实现强大且高效的动态上采样器。
3. 学习采样和上采样
在本节中,我们将详细阐述DySample及其变体的设计。首先,我们给出一个简单的实现,然后逐步展示如何对其进行改进。
3.1、初步介绍
我们再次回到上采样的本质,即点采样,来建模几何信息。在PyTorch的内置函数的基础上,我们首先提供一个简单的实现,以证明基于采样的动态上采样的可行性(图2(a))。
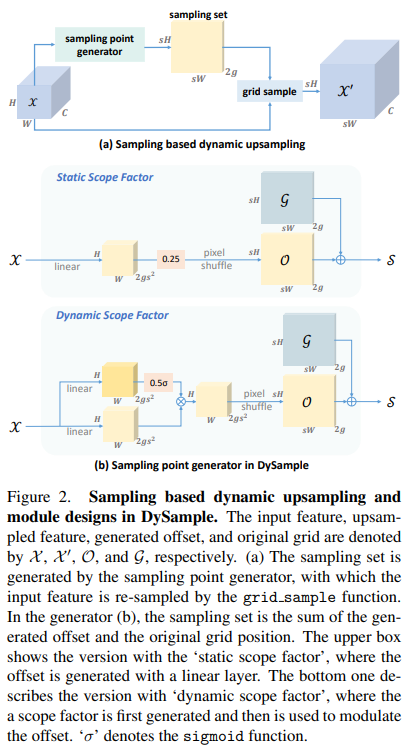
网格采样。给定一个大小为 C × H 1 × W 1 C \times H_{1} \times W_{1} C×H1×W1的特征图 X \mathcal{X} X,以及一个大小为 2 × H 2 × W 2 2 \times H_{2} \times W_{2} 2×H2×W2的采样集 S \mathcal{S} S,其中第一维的2表示 x x x和 y y y坐标。grid_sample函数使用 S \mathcal{S} S中的位置对假设的双线性插值 X \mathcal{X} X进行重新采样,生成大小为 C × H 2 × W 2 C \times H_{2} \times W_{2} C×H2×W2的 X ′ \mathcal{X}^{\prime} X′。这个过程定义为:
X ′ = gridsample ( X , S ) . \mathcal{X}^{\prime}=\text{gridsample}(\mathcal{X}, \mathcal{S})\text{.} X′=gridsample(X,S).
简单实现。给定一个上采样尺度因子 s s s和一个大小为 C × H × W C \times H \times W C×H×W的特征图 X \mathcal{X} X,我们使用一个线性层,其输入和输出通道数分别为 C C C和 2 s 2 2s^{2} 2s2,来生成大小为 2 s 2 × H × W 2s^{2} \times H \times W 2s2×H×W的偏移量 O \mathcal{O} O。然后,通过像素洗牌(Pixel Shuffling)[34]将其重塑为 2 × s H × s W 2 \times sH \times sW 2×sH×sW。接着,采样集 S \mathcal{S} S是偏移量 O \mathcal{O} O和原始采样网格 G \mathcal{G} G的和,即:
O = linear ( X ) , \mathcal{O}=\text{linear}(\mathcal{X}), O=linear(X),
S = G + O , \mathcal{S}=\mathcal{G}+\mathcal{O}, S=G+O,
其中省略了重塑操作。最后,通过grid_sample和采样集 S \mathcal{S} S,可以生成大小为 C × s H × s W C \times sH \times sW C×sH×sW的上采样特征图 X ′ \mathcal{X}^{\prime} X′,如等式(1)所示。
这个初步设计在对象检测[25]上使用Faster RCNN[33]获得了37.9 AP,在语义分割[42]上使用SegFormer-B1[40]获得了41.9 mIoU(与CARAFE相比:38.6 AP和42.8 mIoU)。接下来,我们将在这个简单实现的基础上介绍DySample。
3.2、DySample:通过动态采样进行上采样
通过研究这个简单实现,我们观察到 s 2 s^{2} s2个上采样点之间共享的初始偏移位置忽略了位置关系,而且偏移量的无约束移动范围可能导致采样点的无序。我们首先讨论这两个问题。我们还将研究实现细节,如特征组和动态偏移范围。

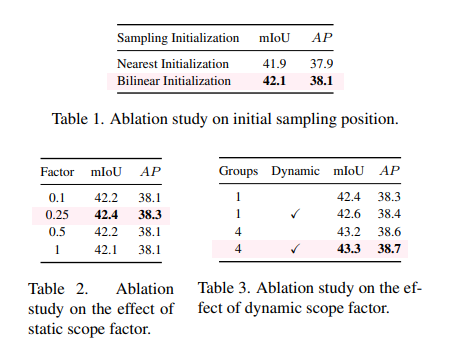
初始采样位置。在初步版本中,对于 X \mathcal{X} X中的一个点,其 s 2 s^{2} s2个采样位置都固定在相同的初始位置(即 X \mathcal{X} X中的标准网格点),如图3(a)所示。这种做法忽略了 s 2 s^{2} s2个邻近点之间的位置关系,导致初始采样位置分布不均匀。如果生成的偏移量都是零,则上采样特征相当于最近邻插值得到的特征。因此,这种初步初始化可以称为“最近邻初始化”。针对这个问题,我们将初始位置更改为图3(b)中的“双线性初始化”,其中零偏移量将带来双线性插值的特征图。
更改初始采样位置后,性能提升至38.1(+0.2)AP和42.1(+0.2)mIoU,如表1所示。
偏移范围。由于归一化层的存在,某一输出特征的值通常位于[-1,1]范围内,以0为中心。因此,局部 s 2 s^{2} s2个采样位置的移动范围可能会显著重叠,如图4(a)所示。这种重叠很容易影响边界附近的预测(图4(b)),并且此类错误会逐阶段传播并导致输出伪影(图4©)。为了缓解这个问题,我们将偏移量乘以0.25的因子,这正好满足重叠与非重叠之间的理论边界条件。这个因子被称为“静态范围因子”,它使得采样位置的移动范围在局部受到约束,如图3©所示。这里我们重写等式(2)为:
O = 0.25 linear ( X ) \mathcal{O}=0.25 \text{ linear }(\mathcal{X}) O=0.25 linear (X)
通过设置范围因子为0.25,性能提升至38.3(+0.2)AP和42.4(+0.3)mIoU。我们还测试了其他可能的因子,如表2所示。
备注。乘以因子是问题的软解决方案,不能完全解决它。我们也尝试使用tanh函数严格约束偏移范围在[-0.25,0.25]内,但效果更差。可能是明确的约束限制了表示能力,例如,明确约束的版本无法处理某些位置期望的偏移量大于0.25的情况。
分组。在这里,我们研究分组上采样,其中每个组中的特征共享相同的采样集。具体来说,可以将特征图沿通道维度划分为g个组,并生成g组偏移量。
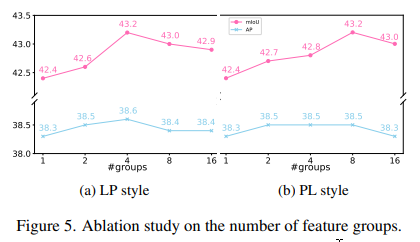
根据图5,分组是有效的。当g=4时,性能达到38.6(+0.3)AP和43.2(+0.8)mIoU。

动态范围因子。为了增加偏移量的灵活性,我们进一步通过线性投影输入特征来生成逐点的“动态范围因子”。通过使用sigmoid函数和0.5的静态因子,动态范围的值在[0,0.5]范围内,以0.25为中心,与静态范围相同。动态范围操作可以参考图2(b)。这里我们重写等式(4)为:
O = 0.5 sigmoid ( linear 1 ( X ) ) ⋅ linear 2 ( X ) \mathcal{O}=0.5 \text{ sigmoid }\left(\text{linear}_{1}(\mathcal{X})\right) \cdot \text{linear}_{2}(\mathcal{X}) O=0.5 sigmoid (linear1(X))⋅linear2(X)
根据表3,动态范围因子进一步将性能提升至38.7(+0.1)AP和43.3(+0.1)mIoU。
偏移生成方式。在上面的设计中,首先使用线性投影来生成 s 2 s^{2} s2个偏移集合。然后,将这些集合重新塑形以满足空间大小。我们称这个过程为“线性+像素洗牌”(LP)。为了节省参数和GFLOPs,我们可以在前面执行重新塑形操作,即首先将特征 X \mathcal{X} X重塑为 C s 2 × s H × s W \frac{\mathrm{C}}{\mathrm{s}^{2}} \times s \mathrm{H} \times \mathrm{sW} s2C×sH×sW的大小,然后线性投影到 2 g × s H × s W 2 g \times s H \times s W 2g×sH×sW。类似地,我们称这个过程为“像素洗牌+线性”(PL)。在其他超参数固定的情况下,PL设置下的参数数量可以减少到 1 / s 4 1 / s^{4} 1/s4。通过实验,我们根据图5的经验,将LP和PL版本的组数分别设置为4和8。此外,我们发现PL版本在SegFormer(表4)和MaskFormer(表5)上比LP版本表现更好,但在其他测试模型上略差。
DySample系列。根据范围因子(静态/动态)和偏移生成方式(LP/PL)的形式,我们研究了四个变体:
i) DySample:使用静态范围因子的LP风格;
ii) DySample+:使用动态范围因子的LP风格;
iii) DySample-S:使用静态范围因子的PL风格;
iv) DySample-S+:使用动态范围因子的PL风格。
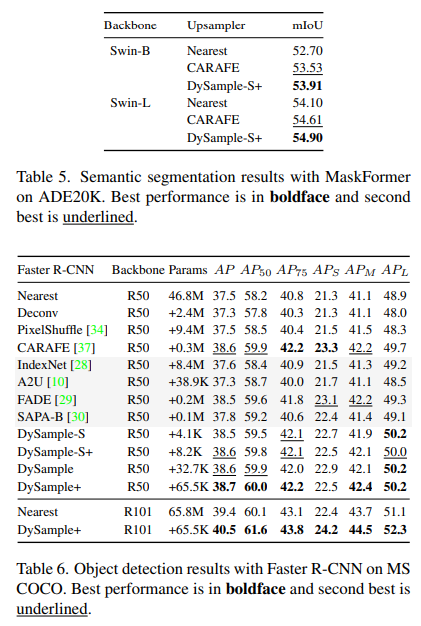
3.3、DySample如何工作
DySample的采样过程在图9中进行了可视化。我们高亮一个(红色框)局部区域来展示DySample如何将边缘上的一个点分成四个点,以使边缘更清晰。对于黄色框中的点,它生成四个偏移量,指向双线性插值意义上的四个上采样点。在这个例子中,左上方的点被分到“天空”(较亮),而其他三个点被分到“房子”(较暗)。最右边的子图指示了右下角上采样点是如何形成的。
3.4、复杂度分析
我们使用大小为 256 × 120 × 120 256 \times 120 \times 120 256×120×120的随机特征图(如果需要,还包括大小为 256 × 240 × 240 256 \times 240 \times 240 256×240×240的引导图)作为输入来测试推理延迟。我们使用SegFormerB1来比较当双线性插值(默认)被其他上采样器替换时的性能、训练内存、训练时间、GFLOPs和参数数量。
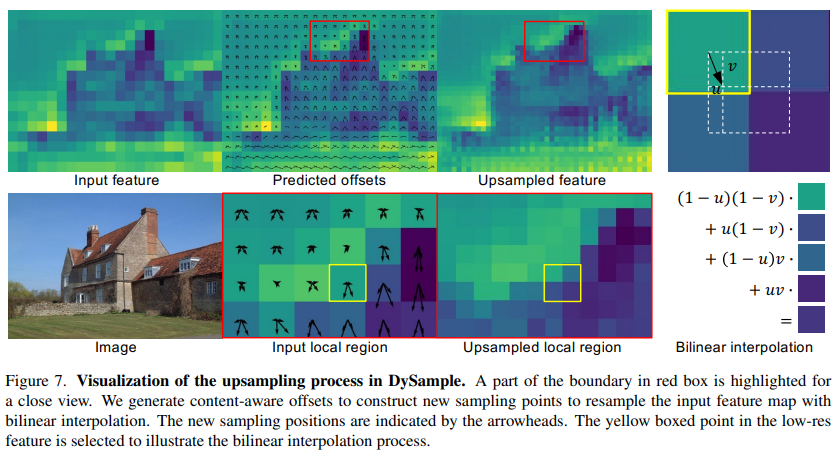
定量结果如图8所示。除了最佳性能外,DySample系列在之前的所有强大动态上采样器中,推理延迟、训练内存、训练时间、GFLOPs和参数数量都是最少的。对于推理时间,DySample系列对 256 × 120 × 120 256 \times 120 \times 120 256×120×120的特征图进行上采样需要 6.2 ∼ 7.6 m s 6.2 \sim 7.6 \mathrm{~ms} 6.2∼7.6 ms,这接近于双线性插值( 1.6 m s 1.6 \mathrm{~ms} 1.6 ms)的时间。特别地,由于使用了高度优化的PyTorch内置函数,DySample的反向传播相当快,增加的训练时间可以忽略不计。
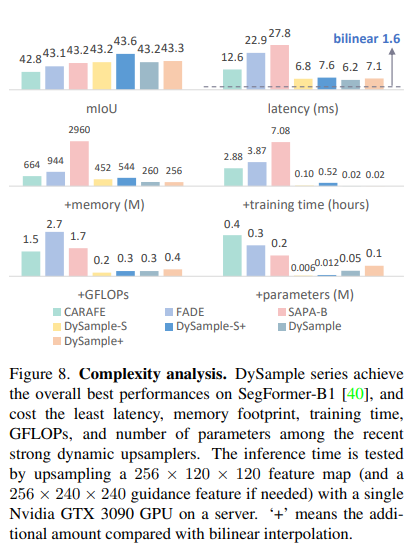
在DySample系列中,‘-S’版本具有更少的参数和GFLOPs,但内存占用和延迟更多,因为PL需要额外的 X \mathcal{X} X存储空间。’+ '版本也引入了更多的计算量。
3.5、相关工作讨论
在这里,我们将DySample与CARAFE[37]、SAPA[30]和可变形注意力[44]进行比较。
与CARAFE的关系。CARAFE生成内容感知的上采样核来重新组合输入特征。在DySample中,我们生成上采样位置而不是核。从基于核的角度看,DySample使用 2 × 2 2 \times 2 2×2的双线性核,而CARAFE使用 5 × 5 5 \times 5 5×5的核。在CARAFE中,如果将核放置在某个点的中心,核的大小至少应为 3 × 3 3 \times 3 3×3,因此GFLOPs至少是DySample的2.25倍。此外,CARAFE中的上采样核权重是学习的,但在DySample中,它们是根据 x x x和 y y y位置来确定的。因此,为了保持单个核,DySample只需要一个2通道的特征图(给定组数 g = 1 g=1 g=1),而CARAFE需要一个 K × K K \times K K×K通道的特征图,这解释了为什么DySample更高效。
与SAPA的关系。SAPA将语义聚类的概念引入到特征上采样中,并将上采样过程视为为每个上采样点找到正确的语义聚类。在DySample中,偏移量的生成也可以看作是为每个点寻找语义相似的区域。然而,DySample不需要引导图,因此更高效且易于使用。
与可变形注意力的关系。可变形注意力[44]主要用于增强特征;它在每个位置采样多个点并将它们聚合起来形成一个新点。但DySample专为上采样而设计;它为每个上采样位置采样一个点,将一个点划分为 s 2 s^{2} s2个上采样点。DySample表明,只要 s 2 s^{2} s2个上采样点可以被动态划分,为每个上采样位置采样一个点就足够了。
4、应用
我们在五个密集预测任务上应用了DySample,包括语义分割、目标检测、实例分割、全景分割和深度估计。在上采样器的比较中,对于双线性插值,我们将缩放因子设置为2,并将“align corners”设置为False。对于反卷积,我们设置核大小为3,步长为2,填充为1,输出填充为1。对于像素洗牌[34],我们首先使用3核大小的卷积将通道数增加到原始通道数的4倍,然后应用“像素洗牌”函数。对于CARAFE[37],我们采用其默认设置。我们使用了IndexNet的“HIN”版本[28]和A2U的“dynamic-cs-d †”版本[10]。我们选择使用没有门控机制的FADE[29]和SAPA-B[30],因为它们在所有密集预测任务中都表现出更稳定的性能。
4.1、语义分割
语义分割是推断每个像素类别标签的任务。在典型的模型中,上采样器通常被多次采用以获得高分辨率的输出。每个像素的精确预测在很大程度上取决于上采样的质量。
实验协议。我们使用ADE20K[42]数据集。除了常用的mIoU指标外,我们还报告了bIoU[6]指标以评估边界质量。我们首先使用轻量级的基线SegFormer-B1[40],其中涉及6个上采样阶段(3+2+1),然后在更强的基线MaskFormer[8]上测试DySample,以Swin-B[26]和Swin-L作为骨干网络,其中FPN涉及3个上采样阶段。我们使用作者提供的官方代码库,并遵循所有训练设置,但仅修改上采样阶段。

语义分割结果。定量结果如表4和表5所示。我们可以看到,DySample在SegFormer-B1上实现了最佳的mIoU指标43.58,但bIoU指标低于有指导的上采样器,如FADE和SAPA。因此,我们可以推断,DySample的性能提升主要来自内部区域,而有指导的上采样器主要提升了边界质量。如图9第一行所示,DySample的输出与CARAFE相似,但在边界附近更具区分度;有指导的上采样器预测出更清晰的边界,但在内部区域有错误的预测。对于更强的基线MaskFormer,DySample也将mIoU指标从52.70提升到了53.91(+1.21)使用Swin-B,以及从54.10提升到了54.90(+0.80)使用Swin-L。
4.2、目标检测与实例分割
目标检测是实例级别的任务,旨在定位和分类目标,而实例分割则需要进一步分割目标。上采样特征的质量对分类、定位和分割的准确性有很大影响。
实验协议。我们使用MS COCO[25]数据集。报告了AP系列指标。我们选择Faster RCNN[33]和Mask R-CNN[13]作为基线。我们修改了FPN架构中的上采样器以进行性能比较。Faster R-CNN的FPN中有四个上采样阶段,而Mask R-CNN的FPN中有三个上采样阶段。我们使用mmdetection[5]提供的代码,并遵循1×训练设置。
目标检测与实例分割结果。定量结果如表6和表7所示。结果表明,DySample在所有比较的上采样器中表现最佳。使用R50时,DySample在所有测试的上采样器中取得了最佳性能。当使用更强的骨干网络时,也可以观察到显著的改进(在Faster R-CNN上R50 +1.2 vs. R101 +1.1 box AP,以及在Mask R-CNN上R50 +1.0 vs. R101 +0.8 mask AP)。
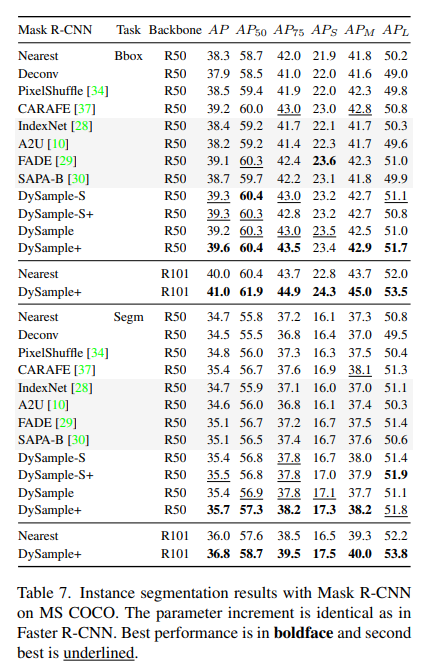
4.3、全景分割
全景分割是语义分割和实例分割的联合任务。在这种情况下,上采样器面临区分实例边界的困难,这对上采样器的良好语义感知和判别能力提出了高要求。
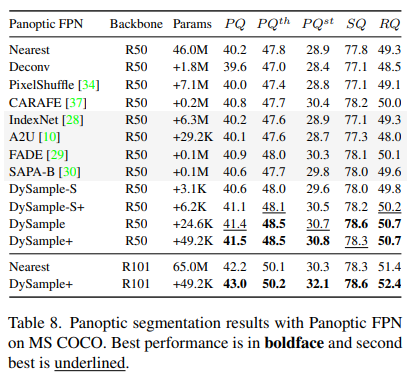
实验协议。我们也在MS COCO[25]数据集上进行了实验,并报告了PQ、SQ和RQ指标[17]。我们采用Panoptic FPN[16]作为基线,并使用mmdetection作为我们的代码库。为确保公平比较,我们使用了默认的训练设置。我们只修改了FPN中的三个上采样阶段。
全景分割结果。表8中的定量结果表明,DySample带来了一致的性能提升,即对于R50和R101骨干网络,PQ分别提高了1.2和0.8。
4.4、单目深度估计
单目深度估计要求模型从单个图像中估计每个像素的深度图。用于深度估计的高质量上采样器应同时恢复细节,保持平坦区域中深度值的一致性,并处理逐渐变化的深度值。
实验协议。我们在NYU Depth V2数据集[35]上进行实验,并报告了 δ < 1.25 \delta<1.25 δ<1.25、 δ < 1.2 5 2 \delta<1.25^2 δ<1.252和 δ < 1.2 5 3 \delta<1.25^3 δ<1.253精度、绝对相对误差(Abs Rel)、均方根误差(RMS)及其对数版本( R M S ( log ) \mathrm{RMS}(\log) RMS(log))、平均 log 10 \log 10 log10误差( log 10 \log 10 log10)和平方相对误差(Sq Rel)。我们采用DepthFormer-SwinT[21]作为基线,其中包括融合模块中的四个上采样阶段。为确保可重复性,我们使用单目深度估计工具箱[20]提供的代码库,并遵循其推荐的训练设置,同时仅修改上采样器。
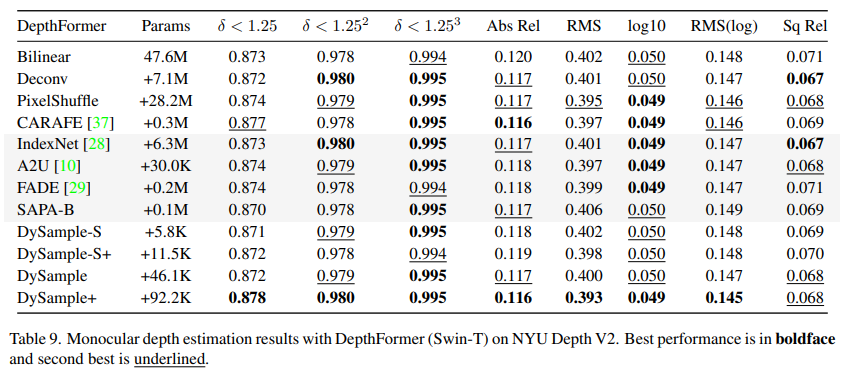
单目深度估计结果。定量结果如表9所示。在所有上采样器中,DySample+取得了最佳性能,与双线性上采样相比, δ < 1.25 \delta<1.25 δ<1.25精度提高了0.05,绝对相对误差(Abs Rel)降低了0.04,均方根误差(RMS)降低了0.09。此外,图9第5行的定性比较也验证了DySample的优越性,例如椅子的准确、一致的深度图。
5、结论
我们提出了DySample,一种快速、有效且通用的动态上采样器。与常见的基于核的动态上采样不同,DySample是从点采样的角度设计的。我们从一个朴素的设计开始,并展示了如何根据我们对上采样的深入理解逐步提高其性能。与其他动态上采样器相比,DySample不仅报告了最佳性能,而且摆脱了定制的CUDA包,并消耗最少的计算资源,在延迟、训练内存、训练时间、GFLOPs和参数数量方面均表现出优越性。对于未来的工作,我们计划将DySample应用于低级任务,并研究上采样和下采样的联合建模。
致谢。这项工作得到了中国国家自然科学基金(编号:62106080)的资助。
测试结果
YOLOv10l summary (fused): 463 layers, 25798544 parameters, 0 gradients, 126.6 GFLOPsClass Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 15/15 [00:02<00:00, 5.14it/s]all 230 1412 0.938 0.917 0.983 0.72c17 230 131 0.953 0.977 0.991 0.803c5 230 68 0.984 0.897 0.983 0.797helicopter 230 43 0.971 0.93 0.954 0.561c130 230 85 0.988 0.974 0.994 0.643f16 230 57 0.929 0.93 0.94 0.629b2 230 2 1 0.808 0.995 0.895other 230 86 0.939 0.953 0.962 0.522b52 230 70 0.971 0.947 0.973 0.794kc10 230 62 1 0.935 0.985 0.803command 230 40 0.948 1 0.992 0.777f15 230 123 1 0.937 0.993 0.67kc135 230 91 0.966 0.978 0.983 0.657a10 230 27 0.96 0.894 0.956 0.45b1 230 20 0.949 0.935 0.969 0.686aew 230 25 0.954 1 0.983 0.764f22 230 17 0.907 1 0.995 0.729p3 230 105 1 0.962 0.994 0.776p8 230 1 0.701 1 0.995 0.697f35 230 32 0.961 0.771 0.96 0.512f18 230 125 0.961 0.979 0.986 0.803v22 230 41 1 0.975 0.995 0.685su-27 230 31 0.956 1 0.995 0.82il-38 230 27 1 0.996 0.995 0.797tu-134 230 1 0.494 1 0.995 0.895su-33 230 2 1 0 0.995 0.796an-70 230 2 0.862 1 0.995 0.697tu-22 230 98 0.968 0.99 0.994 0.784