序言
在上篇文章学习当中,我们认识了数据库的相关概念,以及MySQL的框架和基本使用等内容,总之对数据库有了一个大致的认识,那么本篇文章将开始关于sql语句的学习,本文主要是关于库的属性和操作的内容,简单可概括为两个属性和六个操作,本文的内容不难,主要涉及一些语法上的部分,话不多说就让我们开始今天的学习吧!
一、编码
我们先要对计算机世界中字符的存储的原理有一定的认识,即在计算机中一切都以二进制的方式进行存储,字符也是如此,那么一个字符也就对应着一串二进制序列,那这个二进制序列该如何规定呢?这就涉及到了编码格式的规定,一般来说常用的有三种编码格式。
- ASCII码
最初发展出来的是一种ASCII码,英文全称为American Standard Code for Information Interchange,翻译过来就是美国信息交换标准代码,一种基于拉丁字母的字符编码。相信各位对此种编码形式并不陌生,在学习C语言的时候是否跟我一样经常翻ASCII表查字符对应的数字呢?
在C语言中char类型就采用此方式的编码,这种编码形式虽然因其简单——只支持128个字符,可移植性好——几乎所有的计算机都支持,但是却具备很强的局限性,那就是只能表示拉丁文和英文,并不支持其它类型的语言。
- GBK编码
再来谈一种gbk编码,即Guo Biao Ku,取拼音中的首字母组成,是中华人民共和国制定的汉字内码扩展规范的简称,简单来说就是汉字的编码规范,其中一个汉字由两个字节表示,属于双字节编码。此编码在中国大陆被广泛的使用,尤其是在传统的软件系统和一些特定领域。不过同样也会有不支持国际化字符,因此多语言场景下会出问题。
- UTF-8编码
为了解决以上的多语言的国际化场景,催生出了Unicode,简称万国码,统一码,并由此引出了如今最为常用的UTF-8编码,具备向后兼容,ASCII码直接就能当UTF-8编码;可变长度编码,使用一到四个字节表示一个字符;节省空间,一个英文字符只用一个字节,相对于UTF-16编码(2个字节);全面支持——世界绝大多数的语言,以及表情包和特殊字符;等优点。
我们常见的设备之间发送正常数据双方出现乱码的情况可能就是编码格式不统一导致,因此要根据具体的实际需求采用相应编码格式,除此之外,上面只是介绍了常见的三种编码形式,更多的则要根据实际的场景选取符合需求的编码形式。
那回归到实际的MySQL的操作中,创建数据库时可能要根据需求手动设置编码形式,分为字符集和校验集。
- 字符集,就是上述的字符如何编码成二进制序列,然后存放在磁盘当中便于之后进行读取。
- 校验集,则是从磁盘中以对应的编码形式将字符取出来,然后实行校验和比对。下文会做一个小实验看同一字符集不同校验集的差别。
首先登录MySQL之后使用命令查看系统变量character_set_database以及collation_database,对应着MySQL默认采用的字符集和校验集。
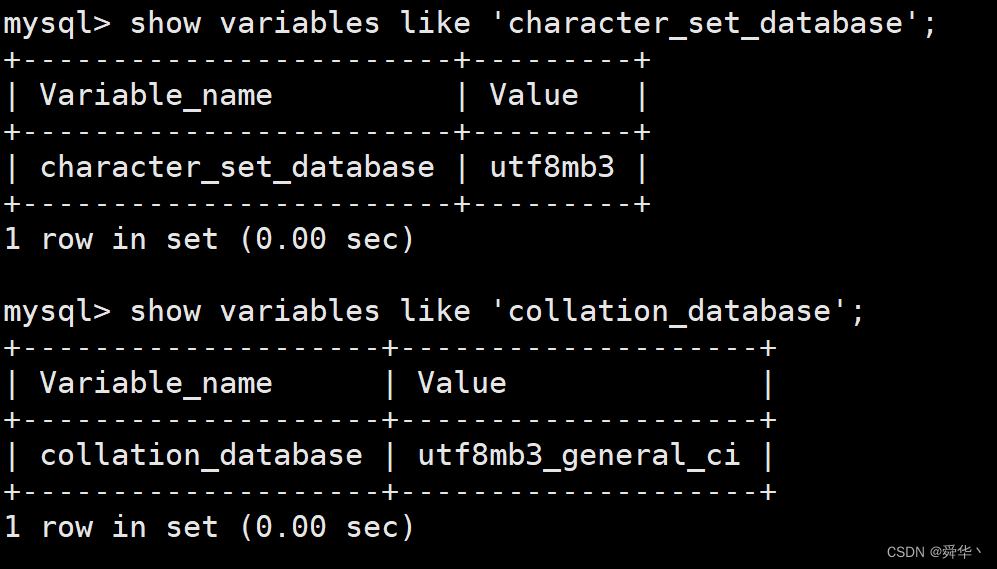
然后使用show命令查看MySQL支持的字符集和校验集,提及一个细节一个字符集可以有多个校验集,而一个校验集只对应一个字符集。
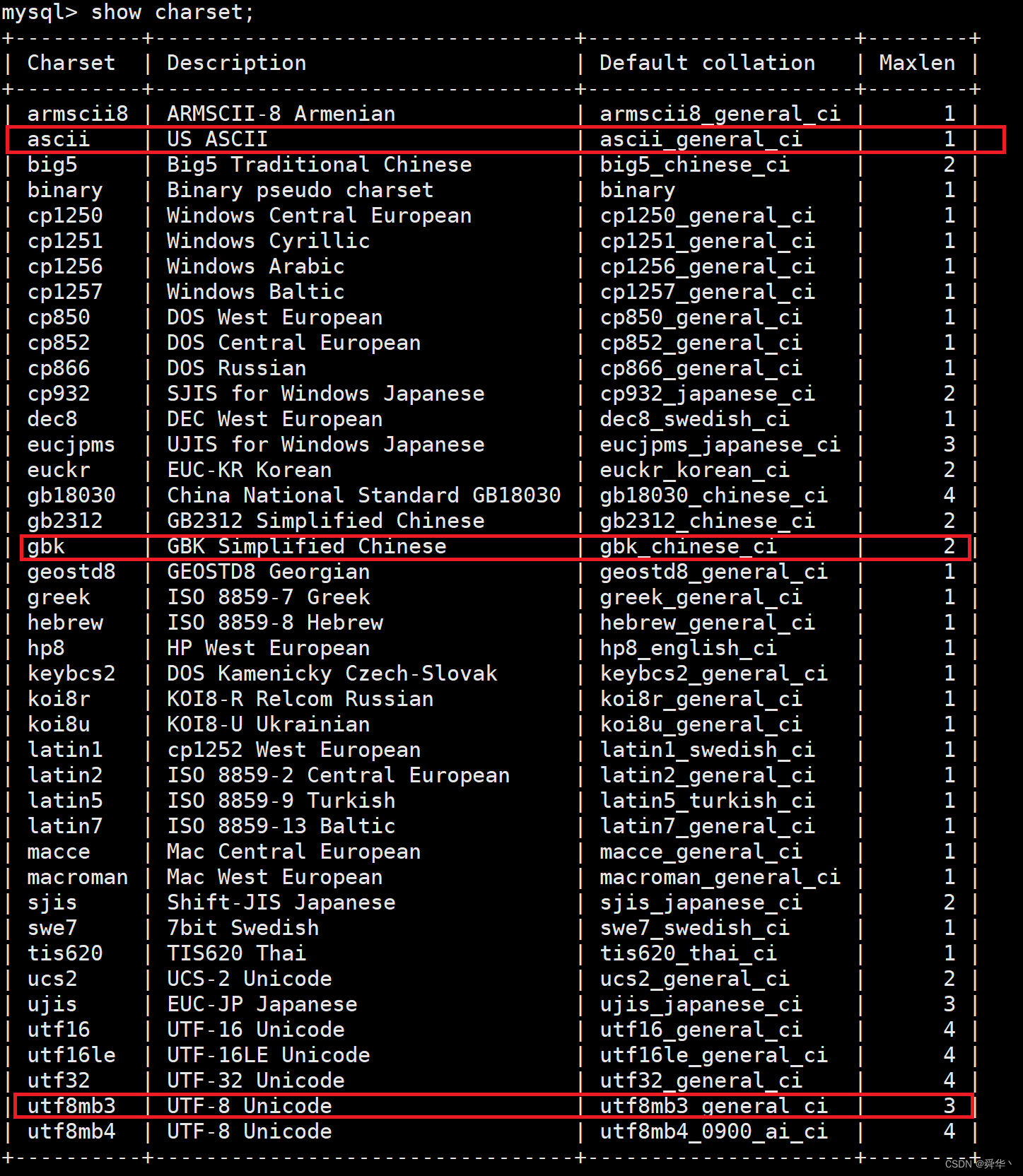
列属性:
- CharSet,所采用的字符集编码规范,这里标出了上述提及的三种编码形式。
- Description,字符集的基本的描述。
- Default Collation,默认采用的校验集,因为一个字符集对应多个校验集,所以给出默认的。
- Maxlen,一个字符所能占用的最大字节数,这也是utf8mb
4和utfmb3的区别。
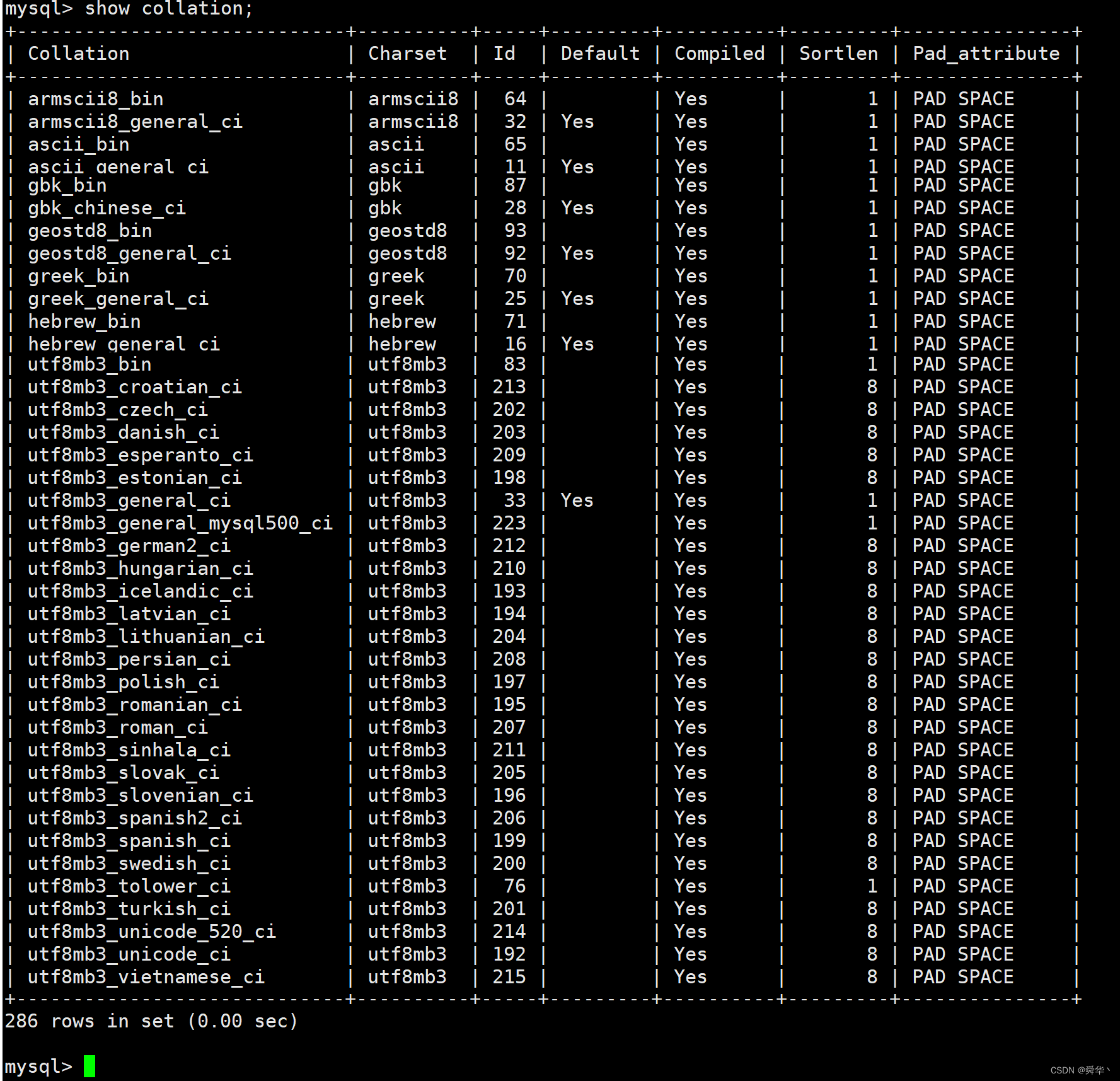
说明:博主所在版本MySQL总共支持有286种校验集,图中是我截出来拼凑出来的几种校验和,并没有列全,hhh,我不说你可能都看不出来吧,开个玩笑,相信细心的你当然能察觉出这一点。
列属性:
- Collation,采用的校验集,上述总共两百多种,且一个字符集大概都会有多个校验集。
- CharSet,校验集所对应的字符集,注意不能采用非对应的字符集,否则可能会出现乱码或者结果不符合预期的现象。
- ID,标识ID,每个校验集都对应唯一一个ID,方便在表中根据ID进行查找。
- Default,表明该校验集是否是默认支持的,可与上面的字符集的图进行对应进行验证。
- Compiled,是否已编译,将默认的校对的信息提前准备好,可以提高排序的性能。
- Sortlen,排序时截取的字节数,方便按字节进行比较大小进行排序。
- Pad_attribute,表明是否处理字符串末尾的空字符,
PAD SPACE表示处理有效字符,NO PAD,表示忽略字符。
二、操作
1.创建
create database (if not exists) [库名] (charset=[字符集] collate=[校验集]);
- 括号内部的可省略,请注意创建时只有if not exist 没有 if exist。
- 不设置字符集和校验集,使用MySQL默认的。
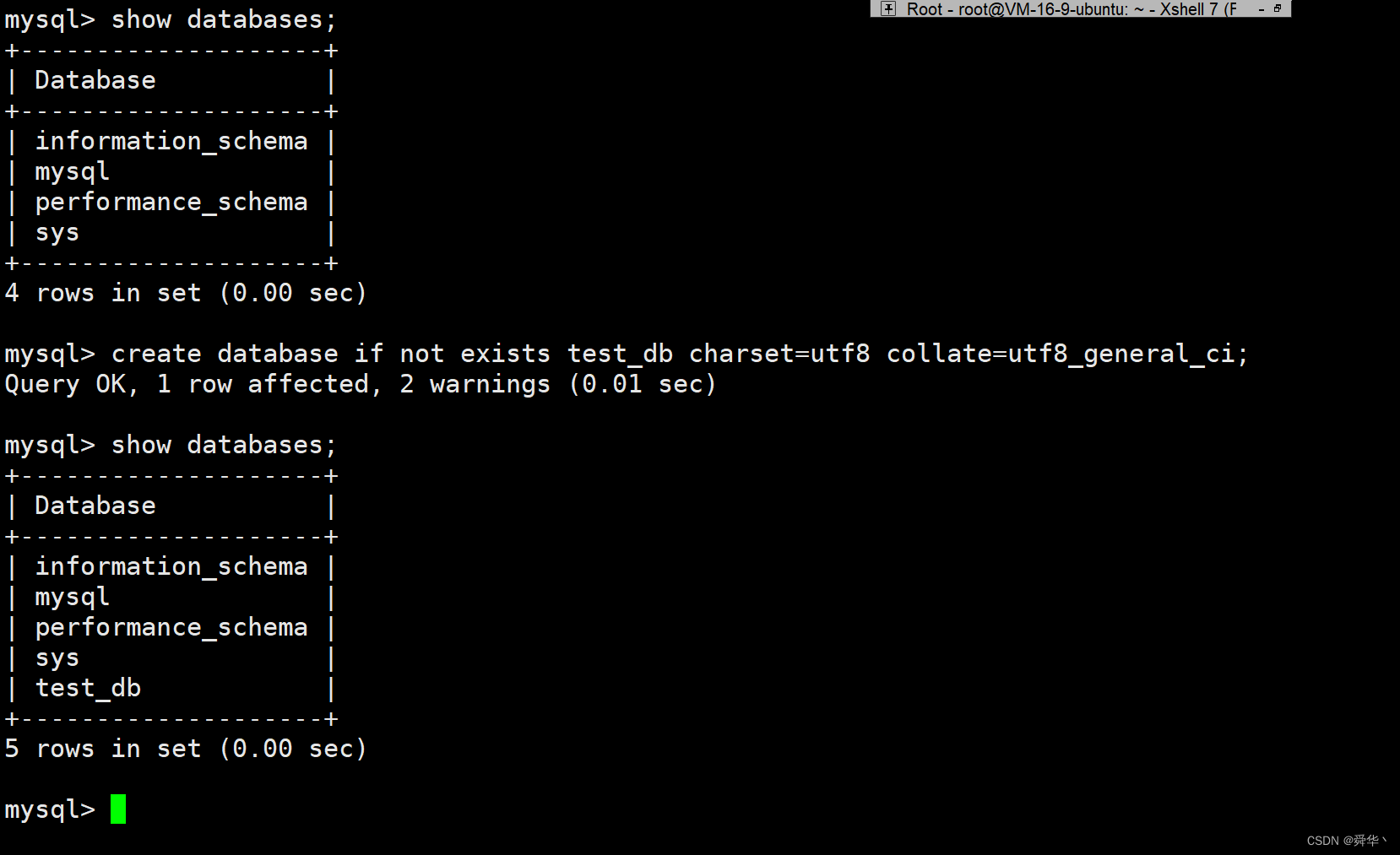
说明:此处采用的是utf8_general_ci的校验集,不区分大小写,还有一个utf8_bin,区分大小写。此处稍微铺垫一下,稍后的小实验中要用。
2.显示创建语句
show create database [数据库];

说明:
- SQL语句不区分大小写,但个人建议是小写的好阅读,所以一般用的SQL语句都是小写的。
'test_db',图中的单引号表示的是数据库名称,这样是为了防止库名是关键字,比如create,show等关键字。/* ... */,部分并不是注释,而是当版本超过4.0100或者8.0016时执行此sql语句。
3.使用和查询
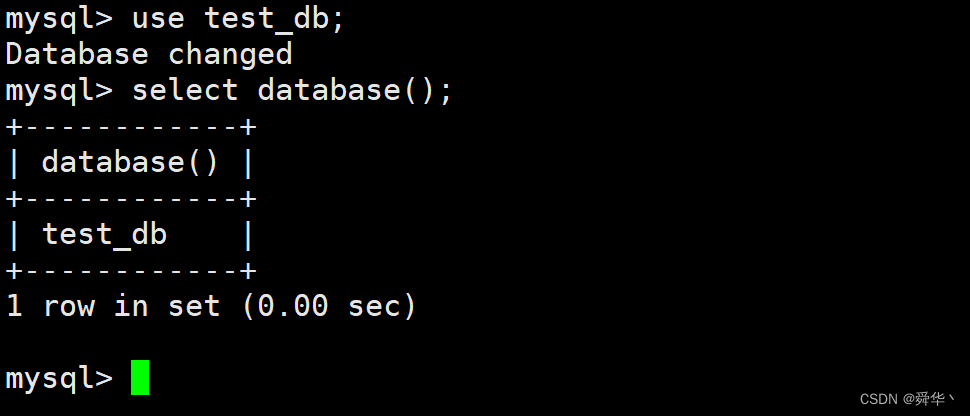
use [库名];
#使用指定的数据库
select database();
#查询当前在哪一个数据库
3.修改属性
alter database [库名] charset=[字符集] collate=[校验集];
此处我们来做一个小实验在使用此语句的同时,同时来看看使用utf8_general_ci和utf8_bin对数据校对产生的影响。
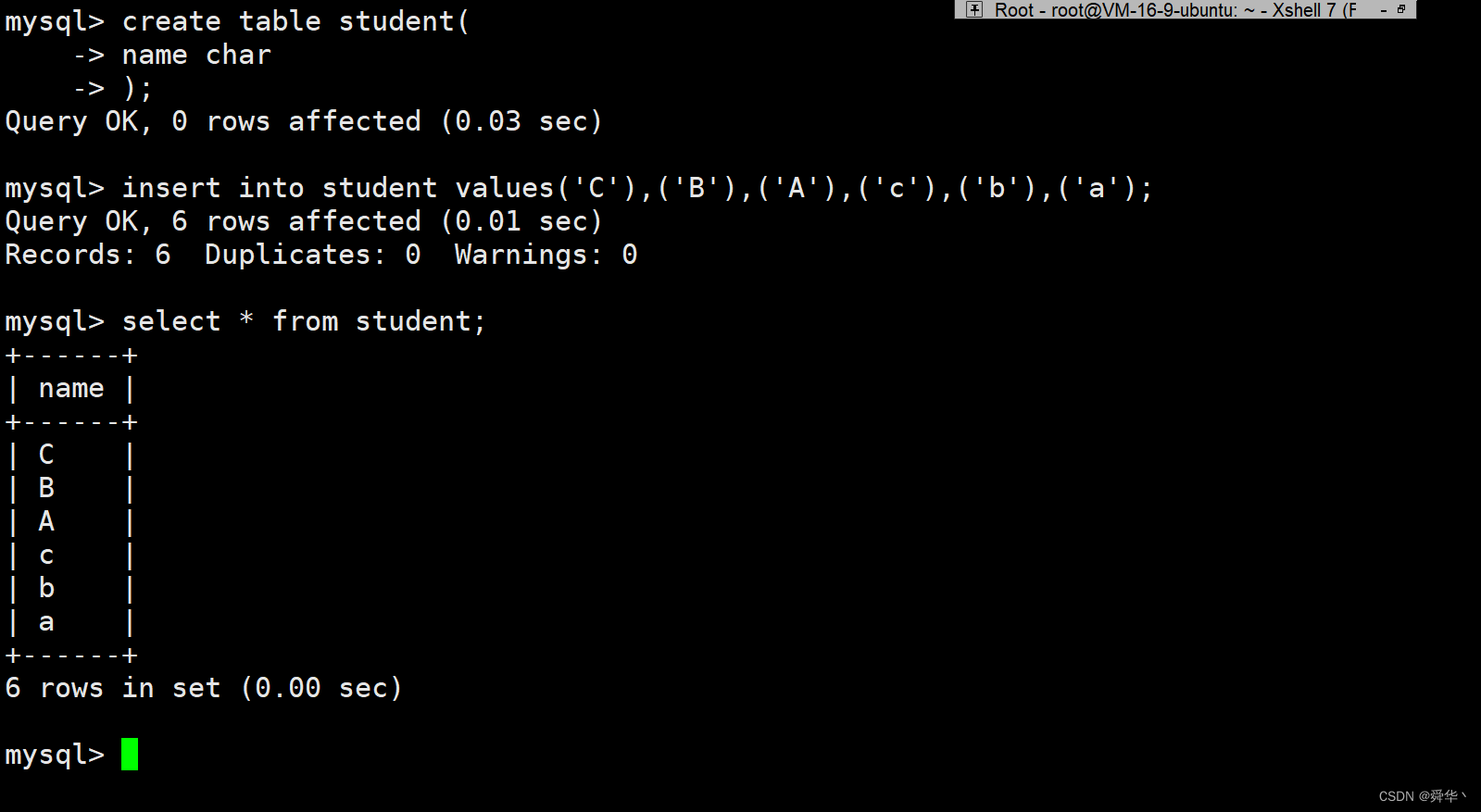
首先,创建一个简单的表结构,并向表里面插入一些数据。
然后,使用select语句对表数据进行排序,查看结果。
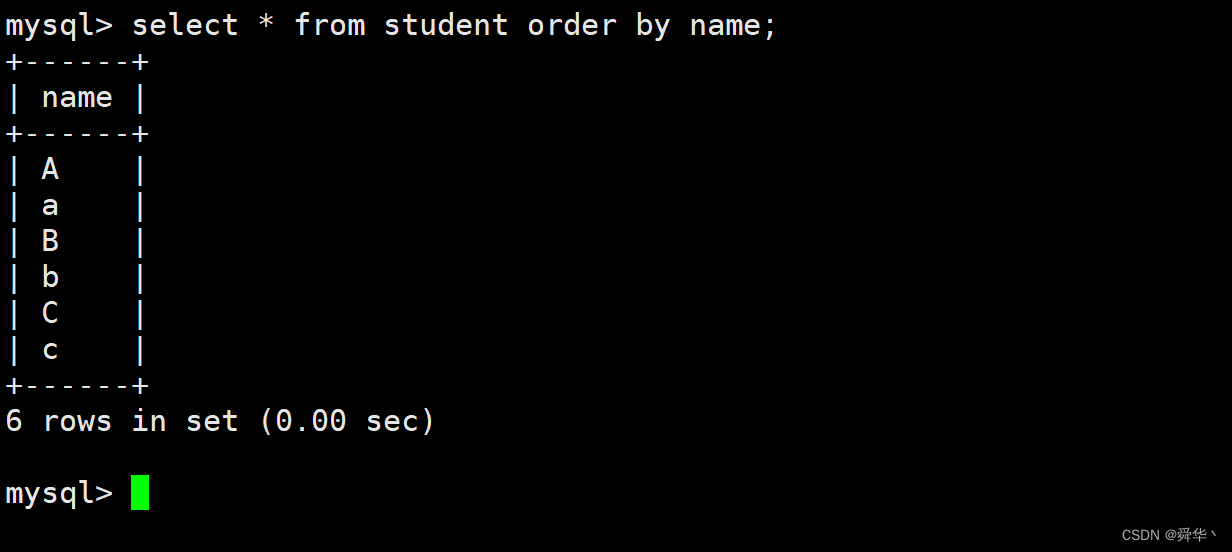
- 可以注意到,在
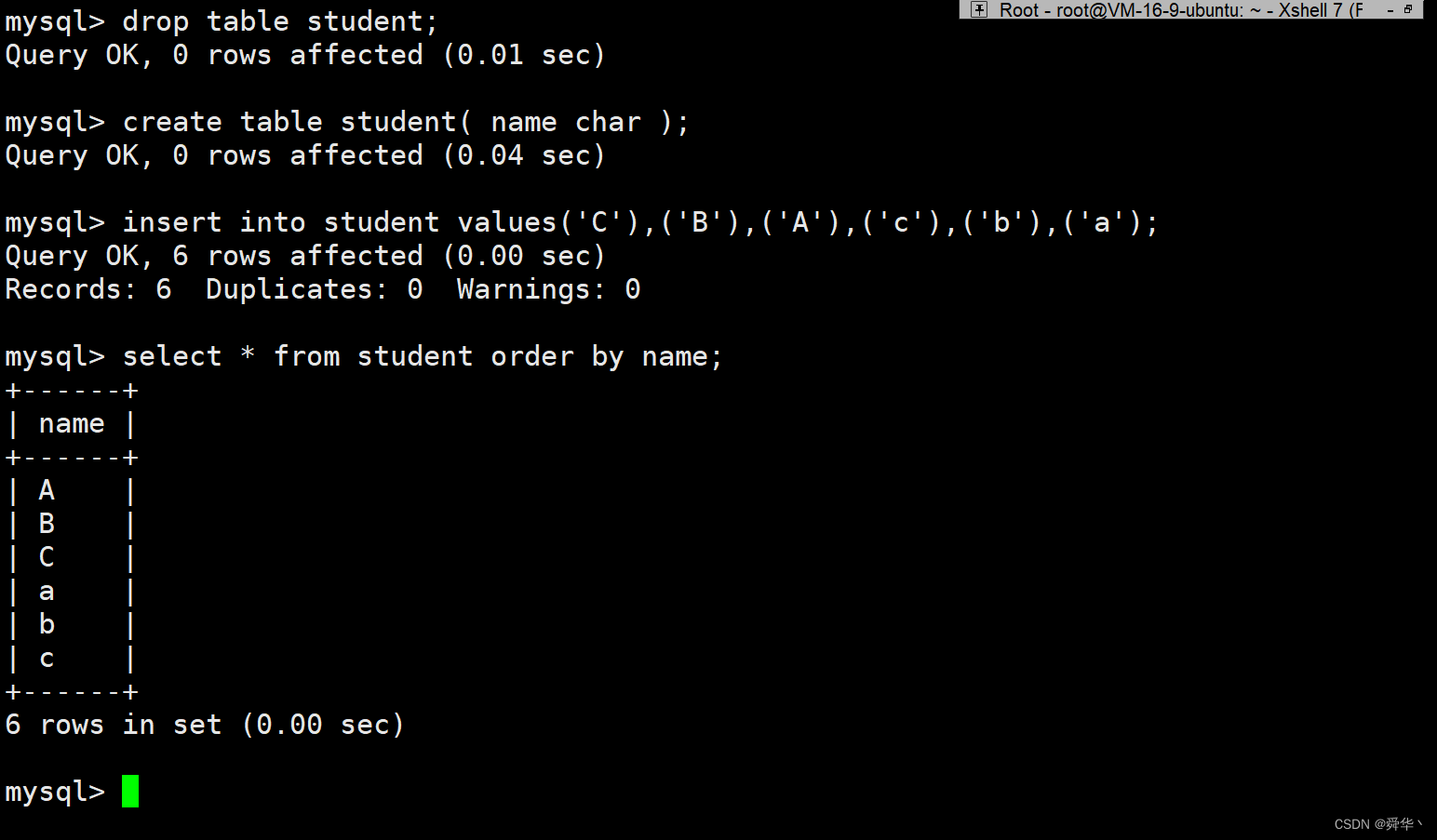
utf8_general_ci的校验集下,A和a等大小写字母是相同的,被排在了一起。这种对于表数据的删改查都有影响,比如让删除’a’时,会连带’A’一块进行删除,该操作也是类似。
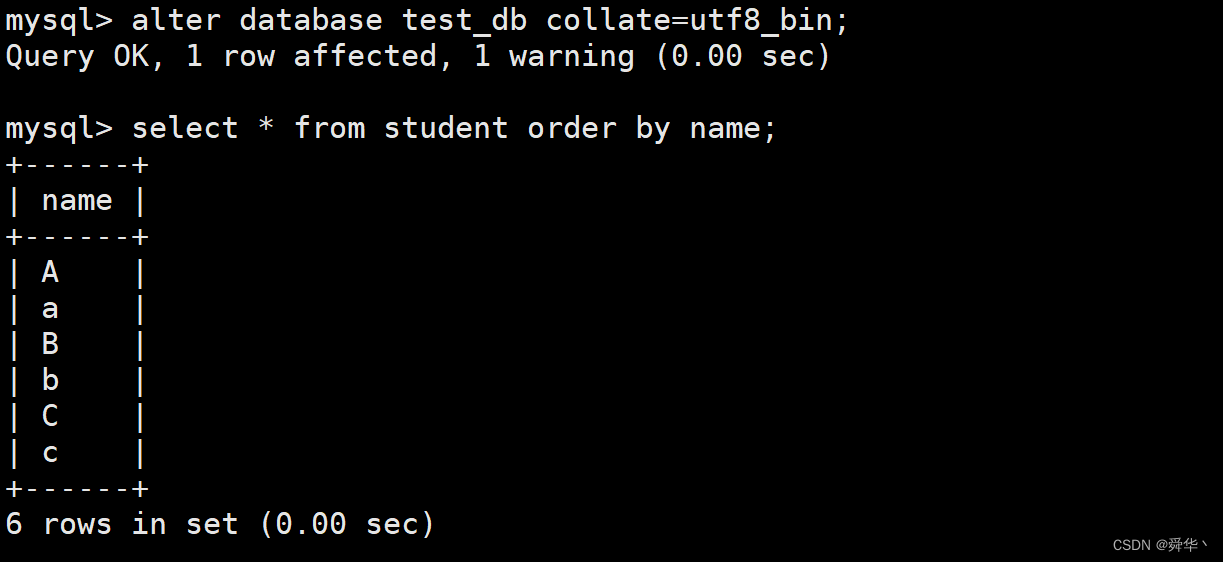
此处使用alter命令,将校验集改为utf8_bin,不过需要注意表的属性和数据库的属性是独立互不影响的,因此只修改数据库的属性是无法看到预期效果的,那表的属性如何修改就先挖一个坑,之后在讲表时会添上,这里为了看到预期效果我们就将表删除再重新建表。
只修改不重新建表的效果:
删表之后再重新建表插入相同数据之后排序效果:
4.备份
mysqldump -P [端口号] -u [用户名] -p [密码] -B [数据库名],[数据库名],... > [文件名].sql;
#系统执行命令,需退出mysql,或者在mysql内执行的话前加上system
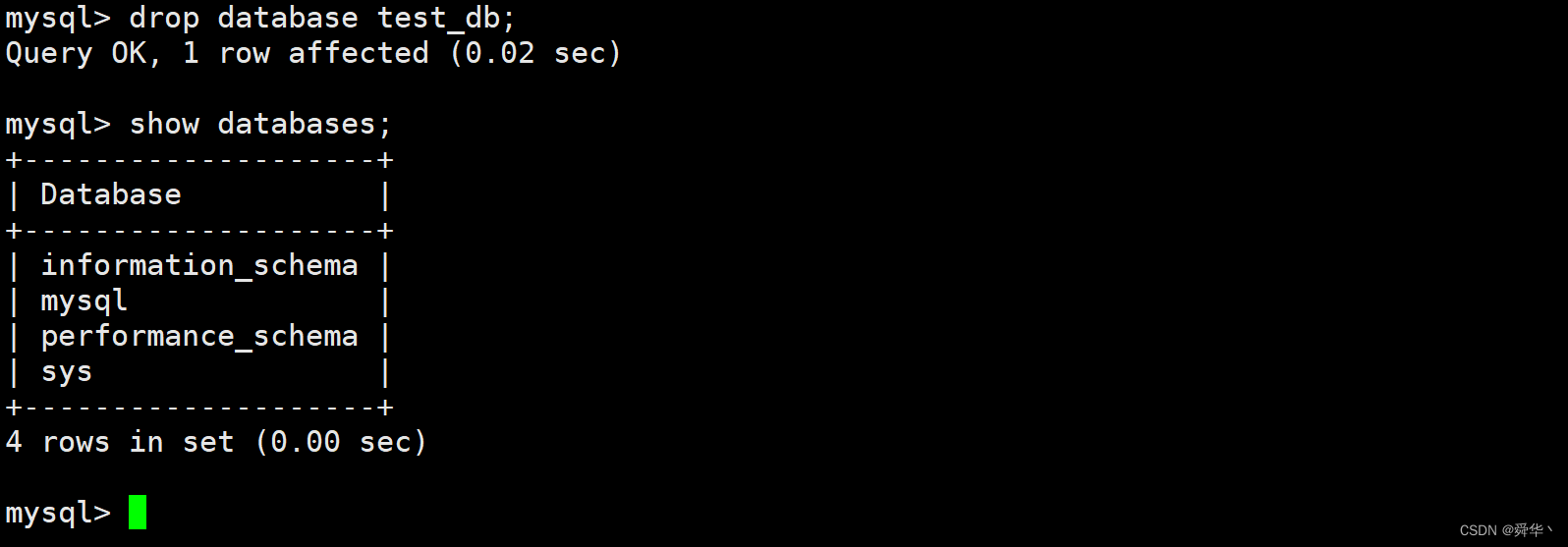
首先将上述的创建的数据库进行备份。

说明:读者如果对备份的文件感兴趣的话,可以自行使用vim或者nano工具查看备份之后的数据库文件,其中大多是一些数据库的注释和表内容的sql语句,这里只简单的点缀一下。
然后删除所在的数据库test_db,便于之后进行恢复。
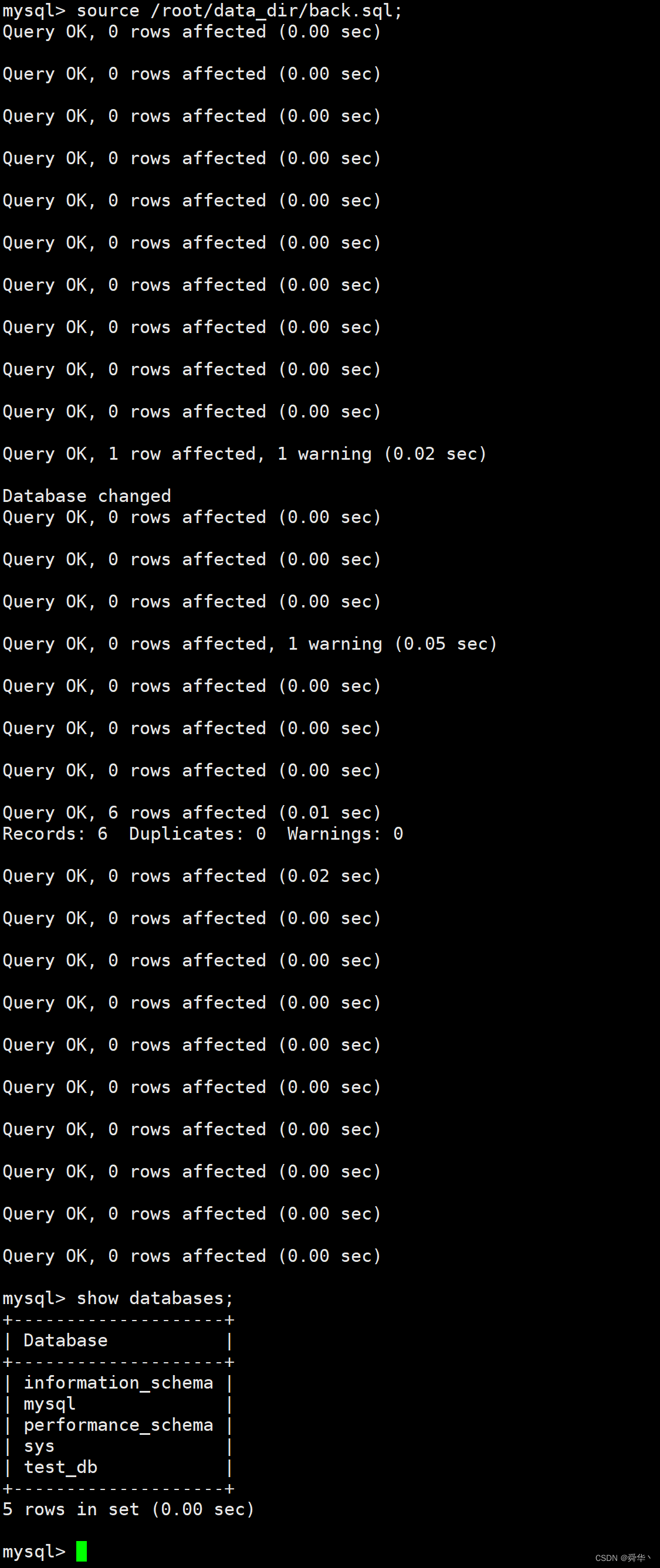
5.恢复
source [指定目录下的备份文件];
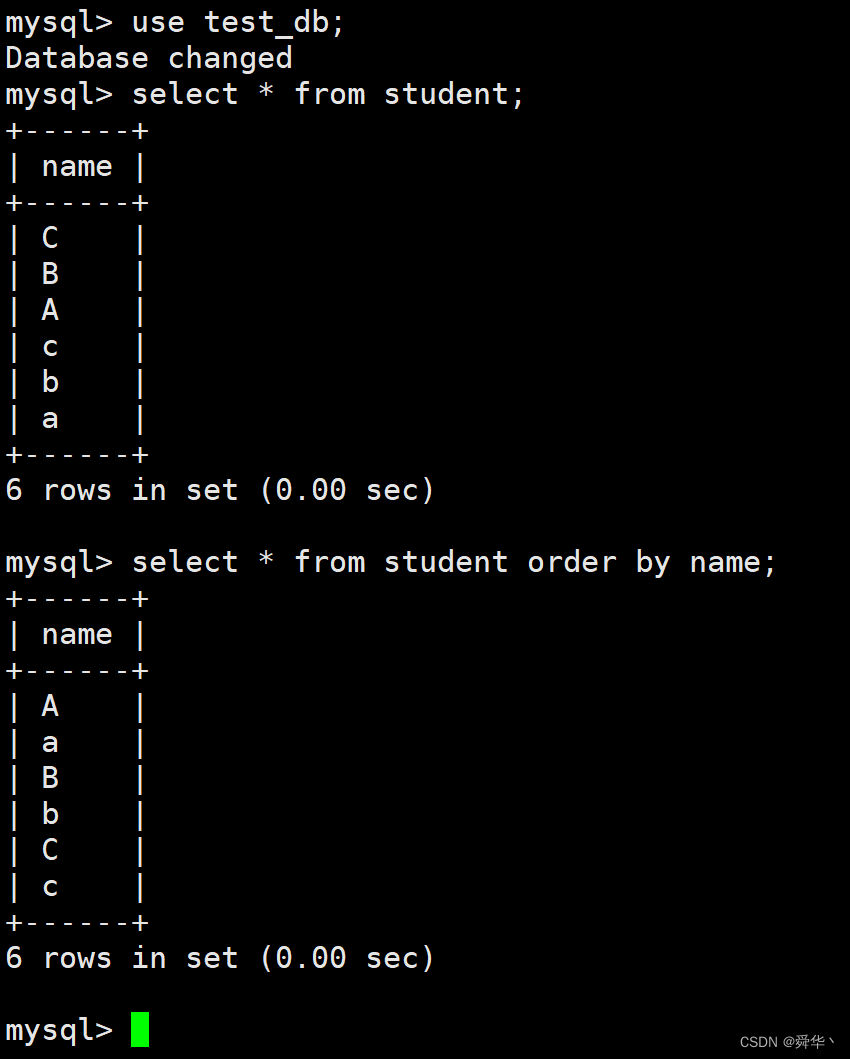
到这里我们再看一下表的内容是否也恢复了,顺便也排序一下看是否跟之前的结果一样。
6.查看库连接
show processlist;
说明:当打MySQL命令比较卡的时候,此命令可以帮助查看哪个连接是异常登录的,如果有则说明MySQL被攻击了,但一般来说MySQL只在内网当中使用,比较安全。
总结
本篇学习了两个属性,即数据库的字符集和校验集,以及六种操作,创建数据库,查看,显示创建信息,修改属性,备份,恢复;总的来说主要是sql语句的内容,需要各位手勤多敲几遍,主打的就是一个熟练度。我是舜华,期待与你的下一次相遇。