什么是LLaMA Factory
LLaMA Factory 是一个围绕 Meta 的 LLaMA(Large Language Model Meta AI)模型设计的工具或代码结构,主要用于简化模型的创建、管理和部署。以下是其关键点解析:
1. 核心概念
- LLaMA 模型:Meta 开发的开源大型语言模型,提供 7B、13B、70B 等参数规模,适用于自然语言处理任务。
- 工厂模式:一种设计模式,通过封装对象创建逻辑,提升代码灵活性和可维护性。LLaMA Factory 可能采用此模式,动态生成不同配置的模型实例。
2. 主要功能
- 模型实例化:根据参数(如模型规模、硬件配置)自动加载对应版本的 LLaMA,简化用户操作。
- 资源管理:优化 GPU/CPU 资源分配,支持分布式训练或混合精度训练,适应不同硬件环境。
- 扩展性:便于集成微调、推理等功能,可能支持与其他工具链(如 Hugging Face Transformers)的兼容。
3. 潜在应用场景
- 研究与开发:研究人员可通过工厂快速切换模型规模,测试不同任务效果。
- 工业部署:企业利用工厂模式封装部署细节,降低运维复杂度,支持弹性扩展。
- 社区项目:开源社区可能基于 LLaMA 构建工厂工具,弥补官方闭源模型的使用门槛。
4. 技术实现推测
- 模块化设计:分离模型加载、数据处理、训练循环等组件,便于定制化。
- 配置驱动:通过 YAML/JSON 文件定义模型参数、训练策略,实现一键复现。
5. 与其他工具对比
- vs Hugging Face Transformers:更专注 LLaMA 生态,可能提供更细粒度的控制(如参数高效微调)。
- vs vLLM/Ray:侧重模型工厂化,而非分布式推理或资源调度。
一、部署 LLaMA Factory
安装(Linux环境下)
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e ".[torch,metrics]"
于解决包冲突。
pip install --no-deps -e
数据准备
请参考 data/README.md 查看数据集文件格式的详细信息。您可以在 HuggingFace / ModelScope / Modelers Hub 上使用数据集,将数据集加载到本地磁盘中,或指定 s3/gcs 云存储的路径。
①注意
更新以使用您的自定义数据集。data/dataset_ info. json
您还可以使用 Easy Dataset 创建合成数据以进行微调。
快速入门
使用以下 3 个命令分别运行 Llama3-8B-Instruct 模型的 LoRA 微调、推理和合并。
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml llamafactory-cli chat examples/inference/llama3_lora_sft.yaml llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
建议换其他模型进行使用Llama3-8B-Instruct模型是一个受限制的模型(gated model),须向国外服务器申请制访问,见常见报错1 我们将模型换为下方所示:
llamafactory-cli train examples/train_lora/qwen2vl_lora_dpo.yaml
llamafactory-cli chat examples/inference/qwen2vl_lora_dpo.yaml
llamafactory-cli export examples/merge_lora/qwen2vl_lora_dpo.yaml有关高级用法(包括分布式训练),请参阅 examples/README.md。
提示
用于显示帮助信息。llamafactory-cli help
如果您遇到任何问题,请先阅读常见问题解答。
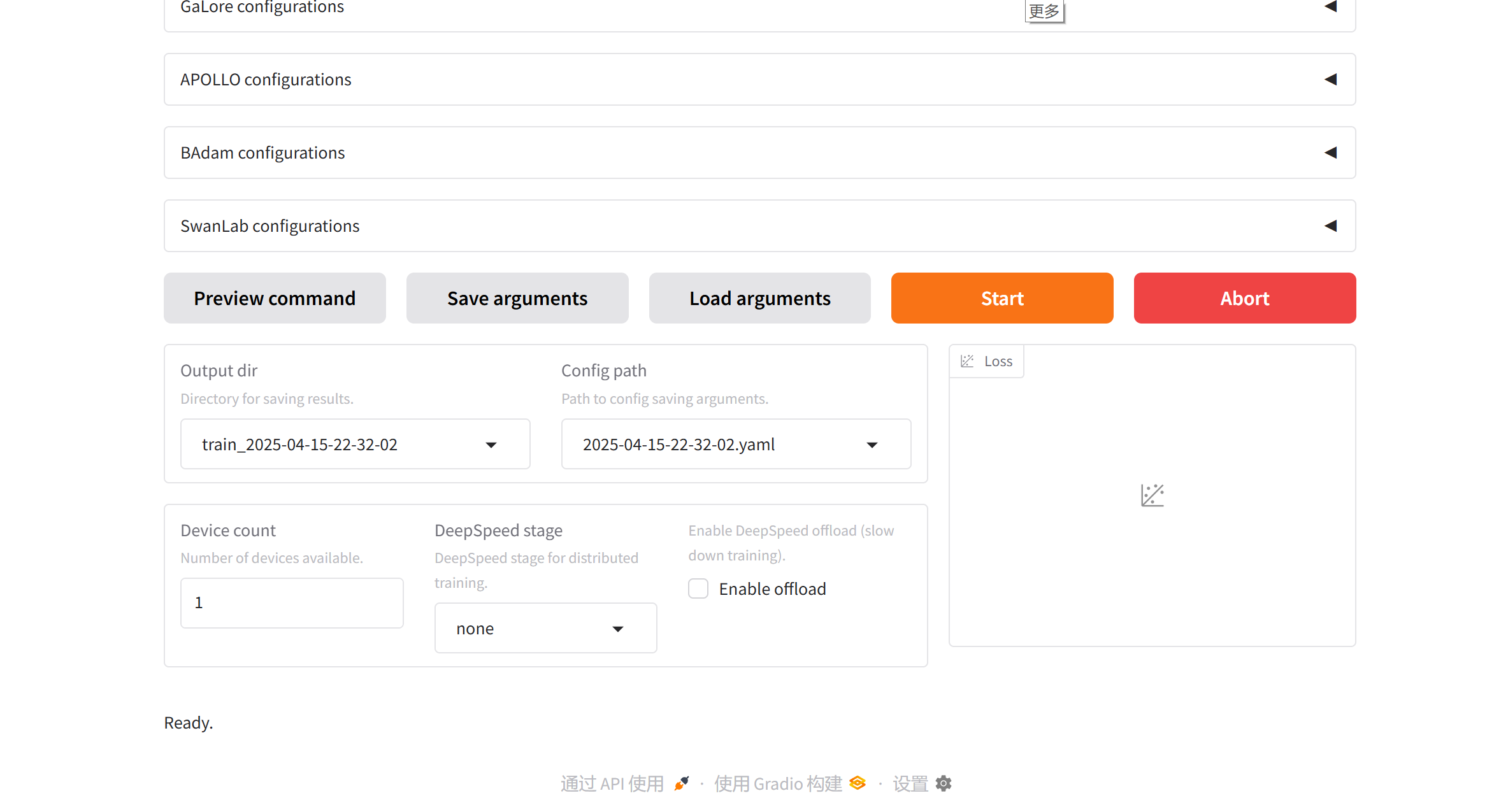
二、使用LLaMA板GUI (由Gradio提供支持)进行微调)
llamafactory-cli webui将在本地产生微调UI界面 ,点击网址进入

常见报错汇总
报错1:
无法访问 Hugging Face 上的 meta-llama/Meta-Llama-3-8B-Instruct 模型,因为这是一个受限制的模型(gated model),需要满足特定条件才能访问。以下是解决这个问题的详细步骤:
1. 确认是否有访问权限
-
检查是否符合访问条件:根据 Hugging Face 的提示,访问此模型需要同意分享你的联系信息,并且可能需要满足其他条件(例如签署许可协议等)。你需要先访问 Meta Llama 3 的 Hugging Face 页面
 https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct,查看是否有相关的访问申请步骤。
https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct,查看是否有相关的访问申请步骤。 -
联系 Meta 或 Hugging Face:如果你认为自己应该有访问权限但仍然无法访问,可以联系 Meta 或 Hugging Face 的支持团队,询问如何申请访问权限。
2. 登录 Hugging Face 并验证身份
-
创建 Hugging Face 账号:如果你还没有 Hugging Face 账号,需要先在 Hugging Face 官网 注册一个账号。
-
登录账号:确保你已经登录到 Hugging Face 账号。如果没有登录,即使你有访问权限,也可能无法下载模型。
-
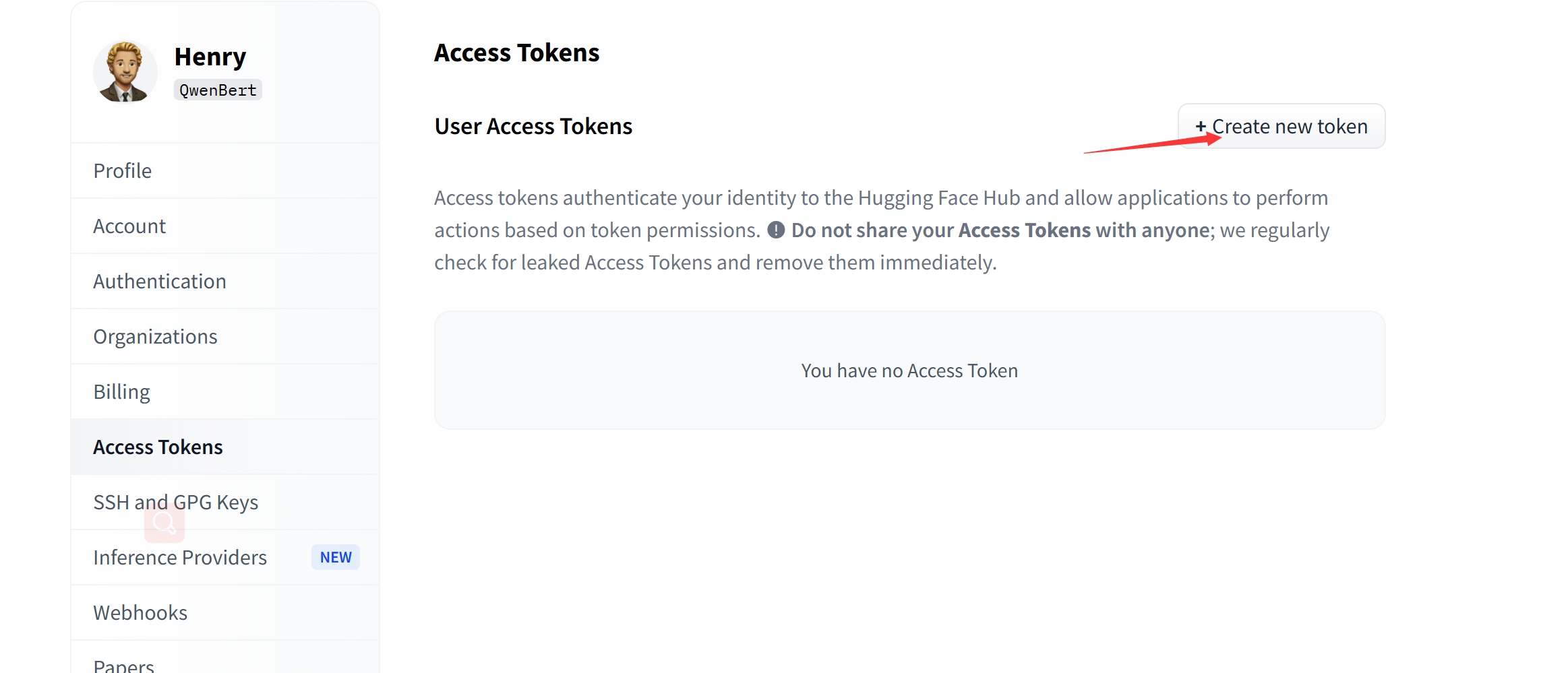
生成 API Token:登录后,进入你的账号设置,生成一个 API Token。这个 Token 将用于在代码中验证你的身份。
如何获取HuggingFace的API Key详细步骤见文章:
如何获取HuggingFace的Access Token;如何获取HuggingFace的API Key_huggingface access token-CSDN博客
创建token前请确保,登录之后已进行邮箱验证,否则token将无法创建
3. 在代码中使用 API Token
-
设置环境变量:将你的 Hugging Face API Token 设置为环境变量。例如,在 Linux 或 macOS 上,可以在终端中运行以下命令:
export HUGGING_FACE_HUB_TOKEN=your_api_token_here在 Windows 的命令提示符中,可以使用以下命令:
set HUGGING_FACE_HUB_TOKEN=your_api_token_here -
修改代码以使用 API Token:在加载模型或分词器时,确保传递
use_auth_token=True参数。例如from transformers import AutoTokenizer, AutoModelForCausalLMmodel_id = "meta-llama/Meta-Llama-3-8B-Instruct" tokenizer = AutoTokenizer.from_pretrained(model_id, use_auth_token=True) model = AutoModelForCausalLM.from_pretrained(model_id, use_auth_token=True)
4. 检查网络连接
-
确保网络正常:检查你的网络连接是否正常,是否有防火墙或代理设置阻止了对 Hugging Face 的访问。
-
重试请求:有时网络问题可能导致临时的访问失败。稍等片刻后重试,看看问题是否解决。
5. 确认是否满足许可协议
-
阅读许可协议:根据 Meta Llama 3 社区许可协议,你需要同意其中的条款和条件才能访问模型。确保你已经阅读并同意了这些条款。
-
商业用途:如果你的用途涉及超过 7 亿月活跃用户的产品或服务,可能需要向 Meta 申请商业许可。
示例代码(包含身份验证)
以下是一个完整的示例代码,展示如何使用 API Token 加载模型和分词器:
import os
from transformers import AutoTokenizer, AutoModelForCausalLM# 设置你的 Hugging Face API Token
os.environ["HUGGING_FACE_HUB_TOKEN"] = "your_api_token_here"model_id = "meta-llama/Meta-Llama-3-8B-Instruct"# 加载分词器和模型时使用身份验证
tokenizer = AutoTokenizer.from_pretrained(model_id, use_auth_token=True)
model = AutoModelForCausalLM.from_pretrained(model_id, use_auth_token=True)# 示例用法
messages = [{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},{"role": "user", "content": "Who are you?"}
]input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
outputs = model.generate(input_ids, max_new_tokens=256)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)