目录
一、理论知识
(1)什么是哈希表?
(2)哈希函数
(3)哈希碰撞
(4)三种常见的哈希结构🧐
二、基础题目
(1)242. 有效的字母异位词 - 力扣
(2)349. 两个数组的交集 - 力扣
(3)202. 快乐数 - 力扣(LeetCode)
(4)1. 两数之和 - 力扣(LeetCode)
(5)1207. 独一无二的出现次数 - 力扣(LeetCode)
(6)AcWing 840. 模拟散列表 - AcWing
一种数据结构,能够快速地通过“键”找到对应的“值”。
一、理论知识
(1)什么是哈希表?
哈希表是根据关键码的值而直接进行访问的数据结构,比如数组,其实就是一张哈希表,哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素,如下图所示:
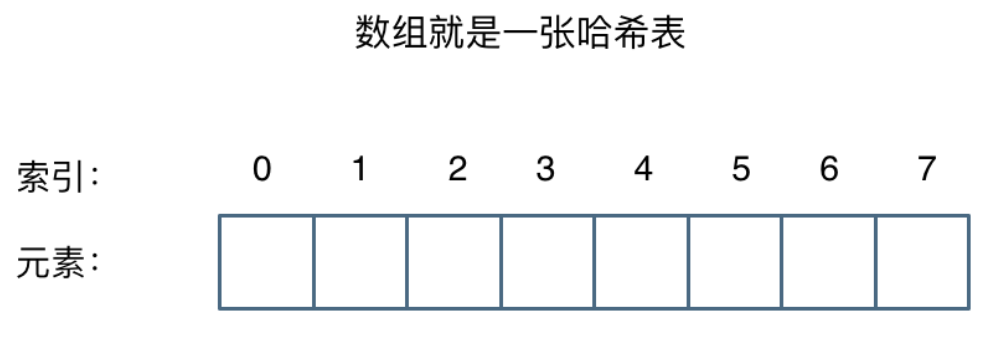
一般哈希表都是用来快速判断一个元素是否出现集合里。
(2)哈希函数
哈希函数,例如把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下标快速知道这位同学是否在这所学校里了。
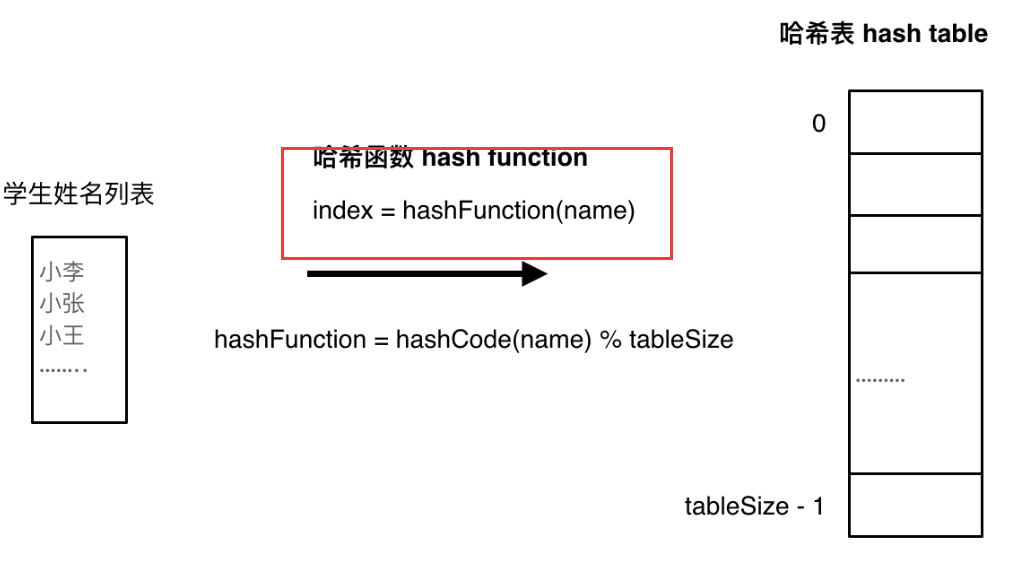
如果hashCode得到的数值大于 哈希表的大小了,也就是大于tableSize了,怎么办呢?
为了保证映射出来的索引数值都落在哈希表上,我们会在再次对数值做一个取模的操作,这样我们就保证了学生姓名一定可以映射到哈希表上了。
如果学生的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表 同一个索引下标的位置?见下节哈希碰撞
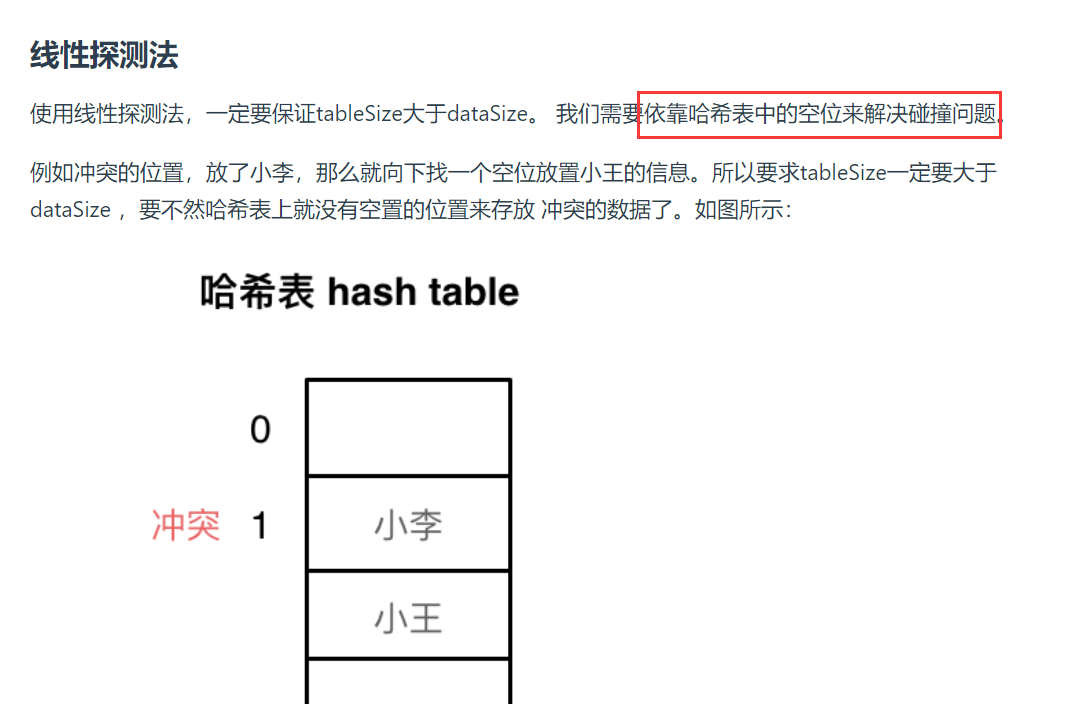
(3)哈希碰撞
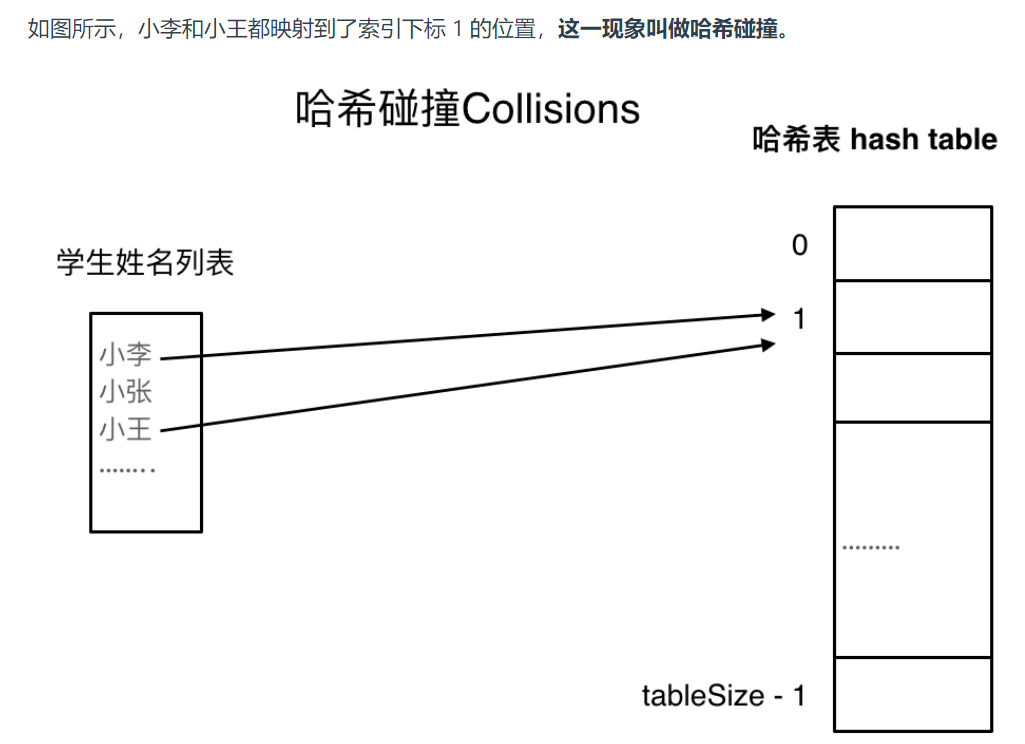
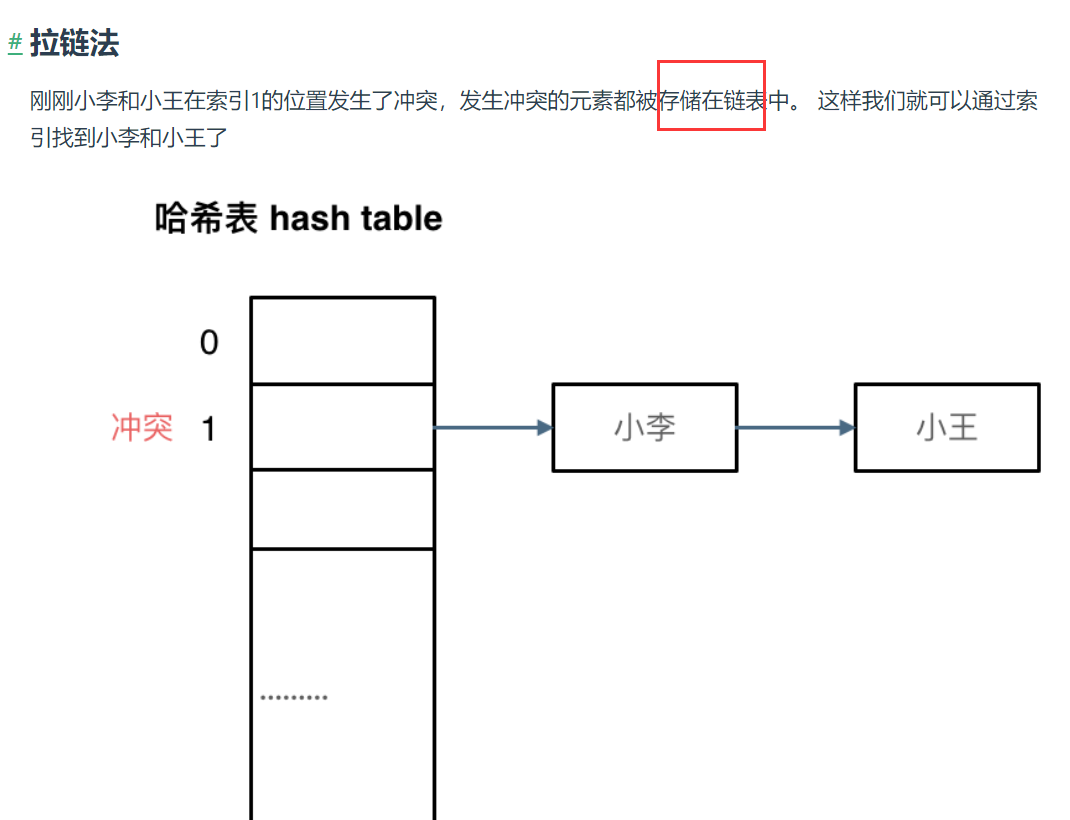
一般哈希碰撞有两种解决方法, 拉链法和线性探测法。
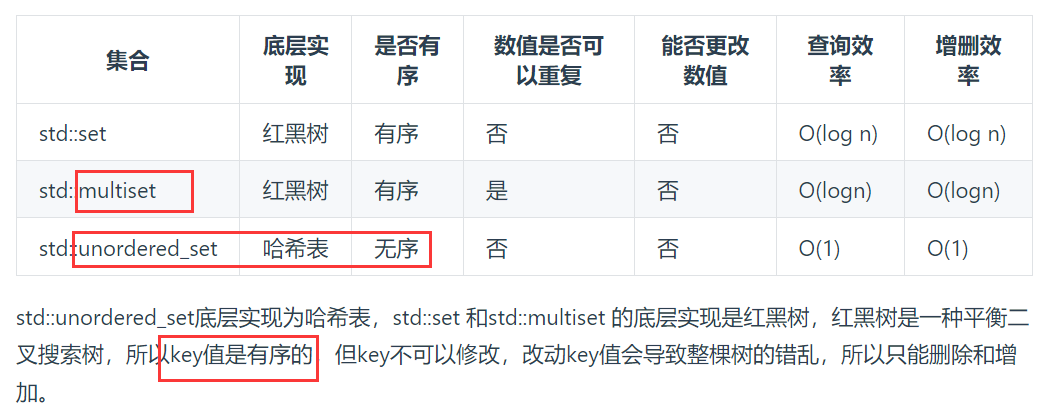
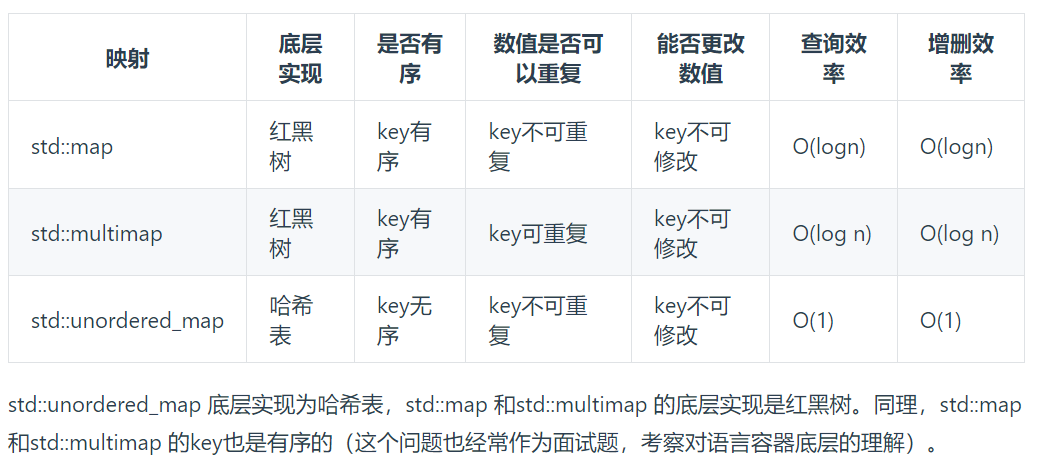
(4)三种常见的哈希结构🧐
- 数组(大小受限制)
- set (集合,只能放一个元素)
- map(映射)
 当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法,但是哈希法也是牺牲了空间换取了时间。
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法,但是哈希法也是牺牲了空间换取了时间。
二、基础题目
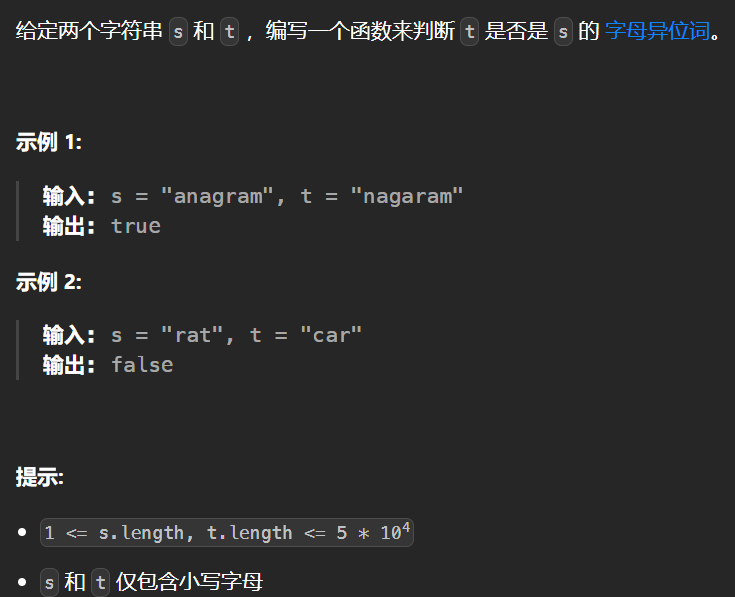
(1)242. 有效的字母异位词 - 力扣
class Solution {
public:bool isAnagram(string s, string t) {map<char,int> mp;for(auto it:s){mp[it]++;}for(auto it:t){mp[it]--;}for(auto it:mp){if(it.second!=0) return false;}return true;}
};或者直接用数组,会快一点:
class Solution {
public:bool isAnagram(string s, string t) {int record[26] = {0};for (int i = 0; i < s.size(); i++) {// 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了record[s[i] - 'a']++;}Qfor (int i = 0; i < t.size(); i++) {record[t[i] - 'a']--;}for (int i = 0; i < 26; i++) {if (record[i] != 0) {// record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。return false;}}// record数组所有元素都为零0,说明字符串s和t是字母异位词return true;}
};(2)349. 两个数组的交集 - 力扣
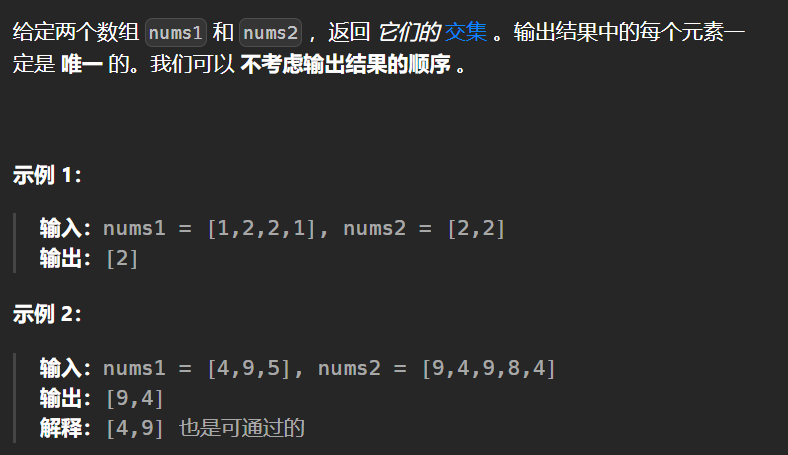
这道题目,主要要学会使用一种哈希数据结构:unordered_set,这个数据结构可以解决很多类似的问题。
注意题目特意说明:输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> re;//存放结果,之所以用set是为了给结果集去重int has[1005]={0};// 哈希表for(auto n1:nums1){has[n1]++;}for(auto n2:nums2){if(has[n2]!=0)//说明是交集中的元素re.insert(n2);//存入结果}return vector<int>(re.begin(),re.end());}
};也可以这样写:
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> s1(nums1.begin(),nums1.end());// 给s1去重vector<int> res;//存放最终结果for(auto it:nums2){if(s1.count(it)){res.push_back(it);s1.erase(it); // 从集合中移除,避免重复添加}}return res;}
};(3)202. 快乐数 - 力扣(LeetCode)


class Solution {
public:int getsum(int n)//计算各位平方之和{int sum=0;while(n){sum+=(n%10)*(n%10);n=n/10;}return sum;}bool isHappy(int n) {//判断是否重复出现summultiset<int> set;while(1){int sum=getsum(n);if(sum==1) return true;if(set.find(sum)!=set.end()){//出现过,开始陷入无限循环了return false;}else set.insert(sum);n=sum;}}
};学会使用set//mutilset判断一个数是否重复出现
(4)1. 两数之和 - 力扣(LeetCode)
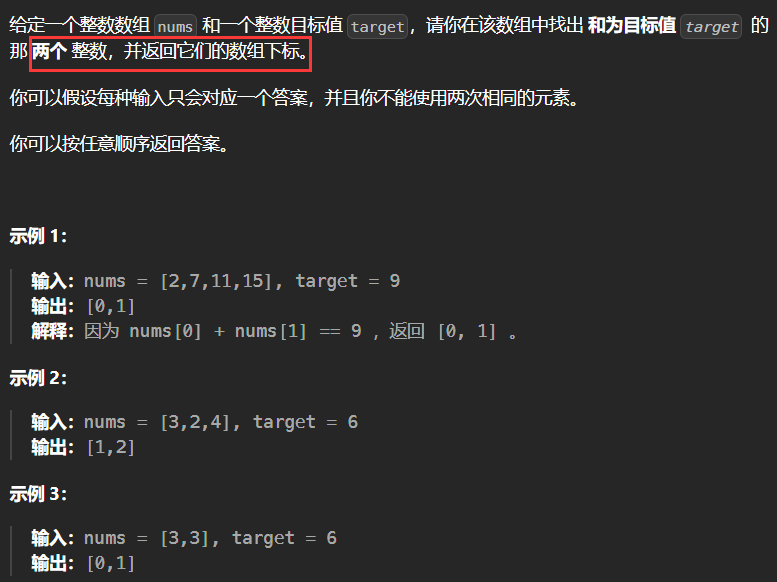
题目中并不需要key有序,选择std::unordered_map 效率更高
map用来存放我们访问过的元素,因为遍历数组的时候,需要记录我们之前遍历过哪些元素和对应的下标,这样才能找到与当前元素相匹配的(也就是相加等于target)
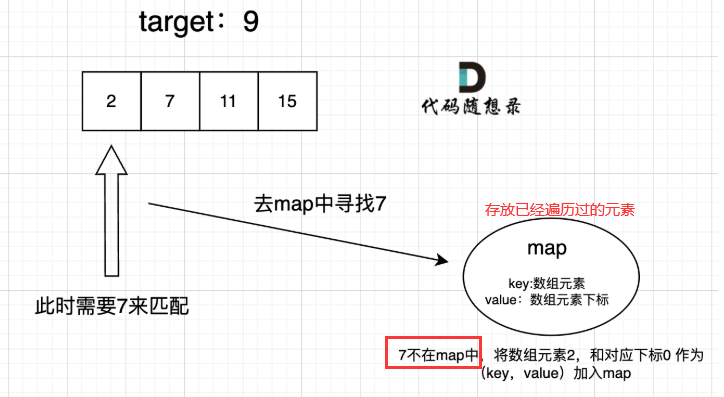
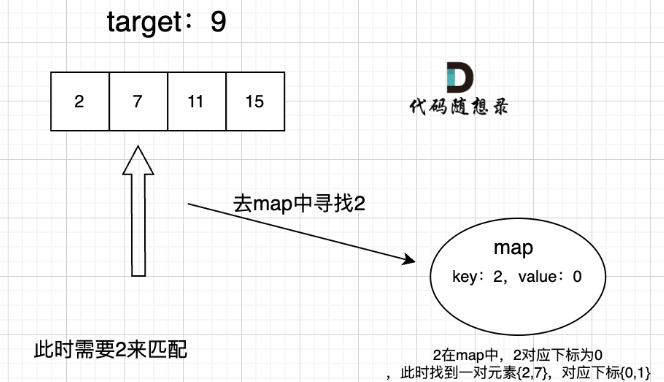
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {unordered_map<int,int> s;vector<int> res;for(int i=0;i<nums.size();i++){int c=target-nums[i];if(s.find(c)!=s.end()) return {s[c],i};else{s.insert({nums[i],i});//注意map insert时是pair类型}}return res;}
};
- 为什么会想到用哈希表
- 哈希表为什么用map
- 本题map是用来存什么的
- map中的key和value用来存什么的
(5)1207. 独一无二的出现次数 - 力扣(LeetCode)
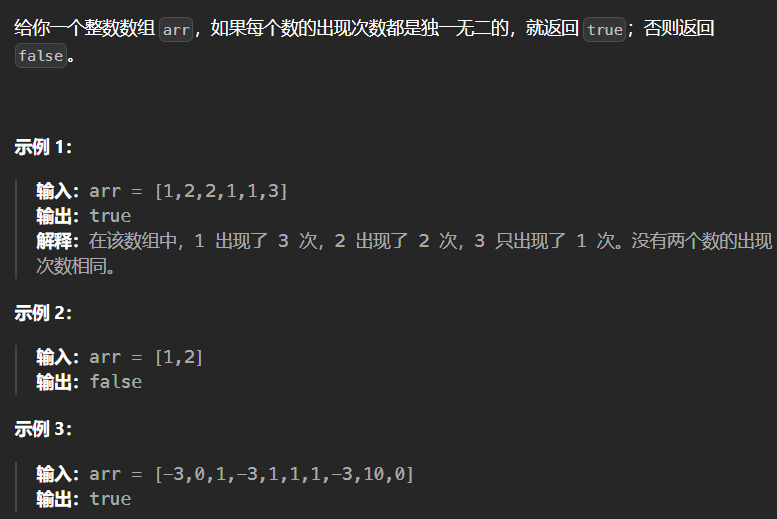
class Solution {
public:bool uniqueOccurrences(vector<int>& arr) {// 使用哈希表统计每个元素的出现次数unordered_map<int,int> fre;//set存储每个元素出现的次数set<int> cnt;for(auto it:arr){fre[it]++;}for(auto it:fre){cnt.insert(it.second);}return fre.size()==cnt.size();}
};set去重 +map实现哈希
(6)AcWing 840. 模拟散列表 - AcWing
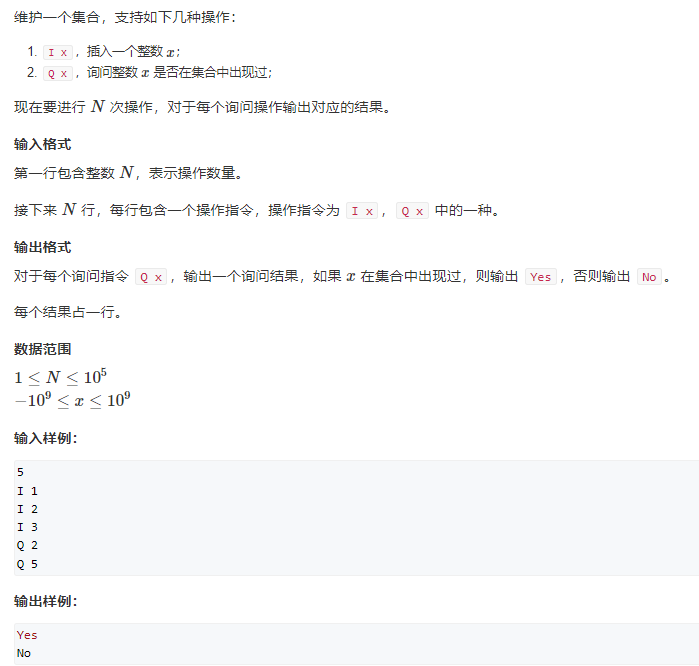
#include<bits/stdc++.h>
using namespace std;
int main()
{int n;cin>>n;map<int,int>mp;while(n--){char op;cin>>op;if(op=='I') {int x;cin>>x;mp[x]++;}else{int x;cin>>x;if(mp.find(x)==mp.end()) cout<<"No"<<endl;else cout<<"Yes"<<endl;}}return 0;
}