人工智能作业,这几天的任务,下面我进行逐渐学习,记录一些学习中的笔记(通俗易懂的笔记)。
值迭代算法
- 值迭代算法
- 基本概念
- 马尔科夫决策过程(MDP)
- 值迭代算法
- 例子(可以参考)
- 问题设定
- 迷宫环境(Grid World)
- 目标
- 值迭代算法步骤
- 详细计算过程
- 初始价值表(Iteration 0)
- Iteration 1
- Iteration 2
- Iteration 3
- Iteration 4 及收敛
- 推导最优策略
- 关键点总结
- 值迭代方程详解
- 方程完整形式
- 符号解释
- 方程分解解析
- 1. 内部部分:即时奖励加未来价值
- 2. 期望计算:求和部分
- 3. 最大化操作:选择最优动作
- 4. 整体含义
- 工作流程
- 直观理解
- 折扣因子γ的作用
- 与其他算法的关系
值迭代算法
值迭代算法(Value Iteration Algorithm)是解决马尔科夫决策过程(Markov Decision Process,MDP)的经典方法之一。
MDP的经典方法如下:
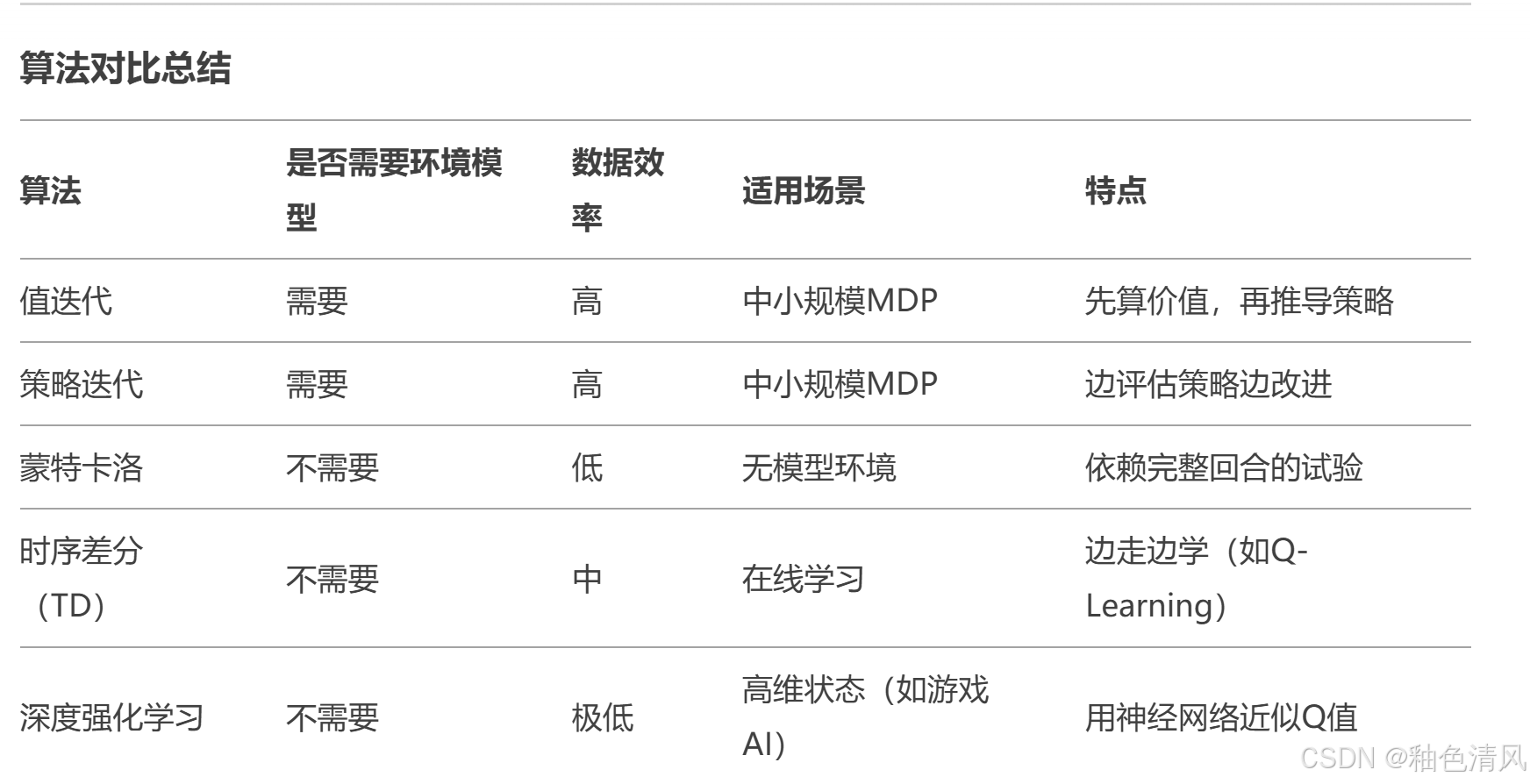
值迭代方法通过迭代更新每个状态的价值,直到到达稳定状态,从而找到最优策略。
基本概念
马尔科夫决策过程(MDP)
MDP是一个用于描述智能体在不确定环境中进行决策的数学模型。
它主要包含以下要素:
- 状态(State):描述系统当前所处的环境。
- 动作(Action):智能体可以采取的行动。
- 策略(Policy):智能体在给定状态下采取的动作。
- 奖励(Reward):智能体采取动作后的获得的奖励。
- 回报(Return):智能体在执行一系列动作后获得的回报。
值迭代算法
值迭代算法通过迭代更新每个状态的价值,直到达到稳定状态。其基本思想是:
- 初始化每个状态的价值为0。
- 对每个状态,根据策略计算其期望回报。
- 更新状态的价值。
- 重复步骤2和3,直到状态的价值不再发生变化。
例子(可以参考)
下面我通过使用deepseek来让他举一个简单的例子,更清楚步骤过程。
(但是我目前认为下面的点不是完全正确的)
①当更新(3,2)点的时候,为什么没有更新(2,3)这个点?这两个点不应该同时变为8的吗?
②在第一轮的时候为什么那两个点没有变成8?
但是对于总结,我认为是正确的,价值传播以及折扣因子。
下面的一步一步只是可以方便理解。
问题设定
迷宫环境(Grid World)
[ 0 ] [ 0 ] [ 0 ]
[ 0 ] [ # ] [ 0 ]
[ 0 ] [ 0 ] [+10]
- 地图:3x3网格,
(x,y)坐标从(1,1)到(3,3),其中:(3,3)是终点,奖励+10(到达后游戏结束)。(2,2)是墙,不可进入。- 其他格子每走一步奖励
-1(表示时间成本)。
- 动作:东(E)、西(W)、南(S)、北(N),如果撞墙则留在原地。
- 折扣因子:
γ=0.9(未来奖励的打折率)。
目标
计算每个格子的最优价值函数 ( V ∗ ( s ) ) ( V^*(s) ) (V∗(s)) ,并推导最优策略。
值迭代算法步骤
-
初始化所有状态价值为0:
- ( V 0 ( s ) = 0 ) ( V_0(s) = 0) (V0(s)=0) 对所有 ( s ) ( s ) (s)(除了终点
(3,3),它的价值固定为+10)。
- ( V 0 ( s ) = 0 ) ( V_0(s) = 0) (V0(s)=0) 对所有 ( s ) ( s ) (s)(除了终点
-
迭代更新公式:
- 对每个状态 ( s ),计算:
V k + 1 ( s ) = max a [ R ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V k ( s ′ ) ] V_{k+1}(s) = \max_a \left[ R(s,a) + \gamma \sum_{s'} P(s'|s,a) V_k(s') \right] Vk+1(s)=amax[R(s,a)+γs′∑P(s′∣s,a)Vk(s′)]- ( R ( s , a ) ) ( R(s,a) ) (R(s,a)):执行动作 ( a ) ( a ) (a) 后的即时奖励。
- ( P ( s ′ ∣ s , a ) ) ( P(s'|s,a) ) (P(s′∣s,a)):从 ( s ) ( s ) (s) 执行 ( a ) ( a ) (a) 后转移到 ( s ′ ) ( s' ) (s′) 的概率(这里假设确定性环境,即 ( P=1 ))。
- 对每个状态 ( s ),计算:
-
重复迭代 直到价值函数收敛(前后两次变化很小)。
详细计算过程
初始价值表(Iteration 0)
| y=1 | y=2 | y=3 | |
|---|---|---|---|
| x=1 | 0 | 0 | 0 |
| x=2 | 0 | # | 0 |
| x=3 | 0 | 0 | 10 |
Iteration 1
更新所有非终点的格子(按公式计算):
-
状态 (1,1):
- 可能的动作:东(E) → (1,2),南(S) → (2,1)。
- 计算:
- 东(E): ( R = − 1 ) ( R = -1 ) (R=−1), 下一状态 (1,2) 的价值 ( V 0 ( 1 , 2 ) = 0 ) ( V_0(1,2)=0 ) (V0(1,2)=0)
( Q = − 1 + 0.9 × 0 = − 1 ) ( Q = -1 + 0.9 \times 0 = -1 ) (Q=−1+0.9×0=−1) - 南(S): ( R = − 1 ) ( R = -1 ) (R=−1), 下一状态 (2,1) 的价值 ( V 0 ( 2 , 1 ) = 0 ) ( V_0(2,1)=0 ) (V0(2,1)=0)
( Q = − 1 + 0.9 × 0 = − 1 ) ( Q = -1 + 0.9 \times 0 = -1 ) (Q=−1+0.9×0=−1)
- 东(E): ( R = − 1 ) ( R = -1 ) (R=−1), 下一状态 (1,2) 的价值 ( V 0 ( 1 , 2 ) = 0 ) ( V_0(1,2)=0 ) (V0(1,2)=0)
- 取最大值: ( V 1 ( 1 , 1 ) = max ( − 1 , − 1 ) = − 1 ) ( V_1(1,1) = \max(-1, -1) = -1 ) (V1(1,1)=max(−1,−1)=−1)
-
状态 (1,2):
- 动作:东(E)→(1,3),西(W)→(1,1),南(S)→(2,2)(撞墙,留在原地)。
- 计算:
- 东(E): ( − 1 + 0.9 × 0 = − 1 ) ( -1 + 0.9 \times 0 = -1 ) (−1+0.9×0=−1)
- 西(W): ( − 1 + 0.9 × ( − 1 ) = − 1.9 ) ( -1 + 0.9 \times (-1) = -1.9 ) (−1+0.9×(−1)=−1.9)
- 南(S):撞墙, ( − 1 + 0.9 × 0 = − 1 ) ( -1 + 0.9 \times 0 = -1 ) (−1+0.9×0=−1)
- ( V 1 ( 1 , 2 ) ( V_1(1,2) (V1(1,2) = m a x ( − 1 , − 1.9 , − 1 ) = − 1 ) max(-1, -1.9, -1) = -1 ) max(−1,−1.9,−1)=−1)
-
其他状态类似计算,结果如下:
| y=1 | y=2 | y=3 | |
|---|---|---|---|
| x=1 | -1 | -1 | -1 |
| x=2 | -1 | # | -1 |
| x=3 | -1 | -1 | 10 |
Iteration 2
继续用 ( V 1 ) ( V_1 ) (V1) 更新 ( V 2 ) ( V_2 ) (V2):
-
状态 (1,1):
- 东(E)→(1,2): ( − 1 + 0.9 × ( − 1 ) = − 1.9 ) ( -1 + 0.9 \times (-1) = -1.9 ) (−1+0.9×(−1)=−1.9)
- 南(S)→(2,1): ( − 1 + 0.9 × ( − 1 ) = − 1.9 ) ( -1 + 0.9 \times (-1) = -1.9 ) (−1+0.9×(−1)=−1.9)
- ( V 2 ( 1 , 1 ) ( V_2(1,1) (V2(1,1) = m a x ( − 1.9 , − 1.9 ) = − 1.9 ) max(-1.9, -1.9) = -1.9 ) max(−1.9,−1.9)=−1.9)
-
状态 (1,3):
- 南(S)→(2,3): ( − 1 + 0.9 × ( − 1 ) = − 1.9 ) ( -1 + 0.9 \times (-1) = -1.9 ) (−1+0.9×(−1)=−1.9)
- 西(W)→(1,2): ( − 1 + 0.9 × ( − 1 ) = − 1.9 ) ( -1 + 0.9 \times (-1) = -1.9 ) (−1+0.9×(−1)=−1.9)
- ( V 2 ( 1 , 3 ) ( V_2(1,3) (V2(1,3)= m a x ( − 1.9 , − 1.9 ) = − 1.9 ) max(-1.9, -1.9) = -1.9 ) max(−1.9,−1.9)=−1.9)
-
状态 (3,1):
- 东(E)→(3,2): ( − 1 + 0.9 × ( − 1 ) = − 1.9 ) ( -1 + 0.9 \times (-1) = -1.9 ) (−1+0.9×(−1)=−1.9)
- 北(N)→(2,1): ( − 1 + 0.9 × ( − 1 ) = − 1.9 ) ( -1 + 0.9 \times (-1) = -1.9 ) (−1+0.9×(−1)=−1.9)
- ( V 2 ( 3 , 1 ) ( V_2(3,1) (V2(3,1) = m a x ( − 1.9 , − 1.9 ) = − 1.9 ) max(-1.9, -1.9) = -1.9 ) max(−1.9,−1.9)=−1.9)
-
状态 (3,2):
- 东(E)→(3,3): ( − 1 + 0.9 × 10 = 8 ) ( -1 + 0.9 \times 10 = 8 ) (−1+0.9×10=8)
(这是关键!因为靠近终点,价值大幅提升) - ( V 2 ( 3 , 2 ) = 8 ) ( V_2(3,2) = 8 ) (V2(3,2)=8)
- 东(E)→(3,3): ( − 1 + 0.9 × 10 = 8 ) ( -1 + 0.9 \times 10 = 8 ) (−1+0.9×10=8)
| y=1 | y=2 | y=3 | |
|---|---|---|---|
| x=1 | -1.9 | -1 | -1.9 |
| x=2 | -1 | # | -1 |
| x=3 | -1.9 | 8 | 10 |
Iteration 3
观察 ( ( 3 , 2 ) ) ( (3,2) ) ((3,2)) 的价值已变为 8,会影响周围格子:
-
状态 (2,3):
- 南(S)→(3,3): ( − 1 + 0.9 × 10 = 8 ) ( -1 + 0.9 \times 10 = 8 ) (−1+0.9×10=8)
- 西(W)→(2,2): 撞墙, ( − 1 + 0.9 × 0 = − 1 ) ( -1 + 0.9 \times 0 = -1 ) (−1+0.9×0=−1)
- ( V 3 ( 2 , 3 ) ( V_3(2,3) (V3(2,3) = m a x ( 8 , − 1 ) = 8 ) max(8, -1) = 8 ) max(8,−1)=8)
-
状态 (3,1):
- 东(E)→(3,2): ( − 1 + 0.9 × 8 = 6.2 ) ( -1 + 0.9 \times 8 = 6.2 ) (−1+0.9×8=6.2)
- ( V 3 ( 3 , 1 ) = 6.2 ) ( V_3(3,1) = 6.2 ) (V3(3,1)=6.2)
| y=1 | y=2 | y=3 | |
|---|---|---|---|
| x=1 | -1.9 | -1 | -1.9 |
| x=2 | -1 | # | 8 |
| x=3 | 6.2 | 8 | 10 |
Iteration 4 及收敛
- 随着迭代继续,高价值会从终点
(3,3)向周围传播。 - 例如:
(2,1)可以通过(3,1)(价值6.2)更新:
( V 4 ( 2 , 1 ) ( V_4(2,1) (V4(2,1) = − 1 + 0.9 × 6.2 = 4.58 ) -1 + 0.9 \times 6.2 = 4.58 ) −1+0.9×6.2=4.58)
- 最终收敛后的价值函数:
| y=1 | y=2 | y=3 | |
|---|---|---|---|
| x=1 | 4.1 | 5.3 | 4.1 |
| x=2 | 5.3 | # | 8 |
| x=3 | 6.2 | 8 | 10 |
推导最优策略
根据收敛后的 ( V ∗ ) ( V^* ) (V∗),每个格子选择使 ( Q ( s , a ) ) ( Q(s,a) ) (Q(s,a)) 最大的动作:
-
例如 (1,1):
- 东(E)→(1,2): ( − 1 + 0.9 × 5.3 = 3.77 ) ( -1 + 0.9 \times 5.3 = 3.77 ) (−1+0.9×5.3=3.77)
- 南(S)→(2,1): ( − 1 + 0.9 × 5.3 = 3.77 ) ( -1 + 0.9 \times 5.3 = 3.77 ) (−1+0.9×5.3=3.77)
- 任意选一个(比如东)。
-
策略结果:
- 从
(1,1)出发的最优路径:东→东→南→东(或类似路径)。
- 从
关键点总结
- 价值传播:高价值从终点逐步“扩散”到其他格子。
- 折扣因子:( \gamma=0.9 ) 使得离终点越远,未来奖励打折越多。
- 收敛条件:当所有 ( ∣ V k + 1 ( s ) − V k ( s ) ∣ < ϵ ) ( |V_{k+1}(s) - V_k(s)| < \epsilon ) (∣Vk+1(s)−Vk(s)∣<ϵ)(比如0.001)时停止。
值迭代方程详解
方程完整形式
[ V k + 1 ( s ) ← max a ∑ s ′ T ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ V k ( s ′ ) ] ] [ V_{k+1}(s) \leftarrow \max_a \sum_{s'} T(s, a, s') [R(s, a, s') + \gamma V_k(s')] ] [Vk+1(s)←maxa∑s′T(s,a,s′)[R(s,a,s′)+γVk(s′)]]
符号解释
- V(s):状态s的价值函数(Value Function),表示从状态s开始,遵循最优策略能获得的预期回报。
- k和k+1:迭代的步数,表示价值函数的当前估计和下一次更新。
- a:动作(Action),智能体可以采取的行为。
- s’:下一个状态(State prime),执行动作a后可能转移到的状态。
- T(s, a, s’):转移概率(Transition Probability),表示在状态s采取动作a后转移到状态s’的概率。
- R(s, a, s’):奖励函数(Reward),表示在状态s采取动作a后转移到状态s’获得的即时奖励。
- γ:折扣因子(Discount Factor,0 ≤ γ ≤ 1),用于平衡即时奖励和未来奖励的重要性。
方程分解解析
1. 内部部分:即时奖励加未来价值
[ R ( s , a , s ′ ) + γ V k ( s ′ ) ] [ R(s, a, s') + \gamma V_k(s') ] [R(s,a,s′)+γVk(s′)]
这部分计算的是:
- R(s, a, s’):从s到s’的即时奖励
- γVₖ(s’):下一个状态s’的折扣价值(未来奖励)
2. 期望计算:求和部分
[ ∑ s ′ T ( s , a , s ′ ) [ ⋅ ] ] [ \sum_{s'} T(s, a, s') [\cdot] ] [∑s′T(s,a,s′)[⋅]]
这是对所有可能的下一个状态s’求期望值(加权平均),权重是转移概率T(s, a, s’)。
3. 最大化操作:选择最优动作
[ max a ] [ \max_a ] [maxa]
对所有可能的动作a,选择能使期望回报最大的那个动作。
4. 整体含义
整个方程的意思是:状态s的新价值Vₖ₊₁(s)更新为所有可能动作中,能够获得最大期望回报的那个动作对应的回报值。
工作流程
- 初始化所有状态的价值V₀(s)(通常设为0或随机小值)
- 对于每个状态s,计算所有可能动作a的期望回报
- 选择使期望回报最大的动作对应的值作为Vₖ₊₁(s)
- 对所有状态重复上述过程
- 当V值变化很小时(收敛),停止迭代
直观理解
想象你在一个迷宫中,V(s)表示从当前位置s到出口的最优路径的"好坏程度"。每次更新时:
- 你考虑所有可能的移动方向(动作a)
- 对每个方向,考虑可能到达的新位置(s’)及其概率
- 计算走这个方向的平均回报(即时奖励+新位置的未来价值)
- 选择最好的那个方向对应的值作为当前位置的新价值
折扣因子γ的作用
- γ=0:只考虑即时奖励,忽略未来
- γ接近1:更重视长期回报
- 通常设为0.9-0.99之间的值
与其他算法的关系
这个更新方程是动态规划在强化学习中的应用,与策略迭代不同,值迭代直接迭代价值函数而不显式维护策略。
这个方程体现了贝尔曼最优方程的思想,通过不断迭代最终会收敛到最优价值函数V*。