目录
前言
一、本节目标
二、准备工作
三、抓取分析
四、抓取首页
五、正则提取
六、写入文件
七、整合代码
八、分页爬取
九、运行结果
十、总结
前言
这一节,咱们要抓取猫眼电影TOP100的相关信息,会用到requests库和正则表达式。requests库用起来比urllib更方便,而且到现在我们还没系统学习过HTML解析库,所以就决定用正则表达式来做解析工具 。
一、本节目标
这一节,咱们要从猫眼电影TOP100的榜单里,把电影名字、上映时间、评分、图片这些信息都给找出来。要提取信息的网站是http://maoyan.com/board/4 。最后把提取到的信息,都保存成文件。
二、准备工作
在开始这部分内容之前,得先检查一下requests库是不是已经正确安装好了。要是还没安装,那就按照第1章给出的安装说明去操作就行。
三、抓取分析
咱们要抓取的网站是http://maoyan.com/board/4 ,打开这个网站,就能看到电影的榜单信息,就跟下面的图差不多。
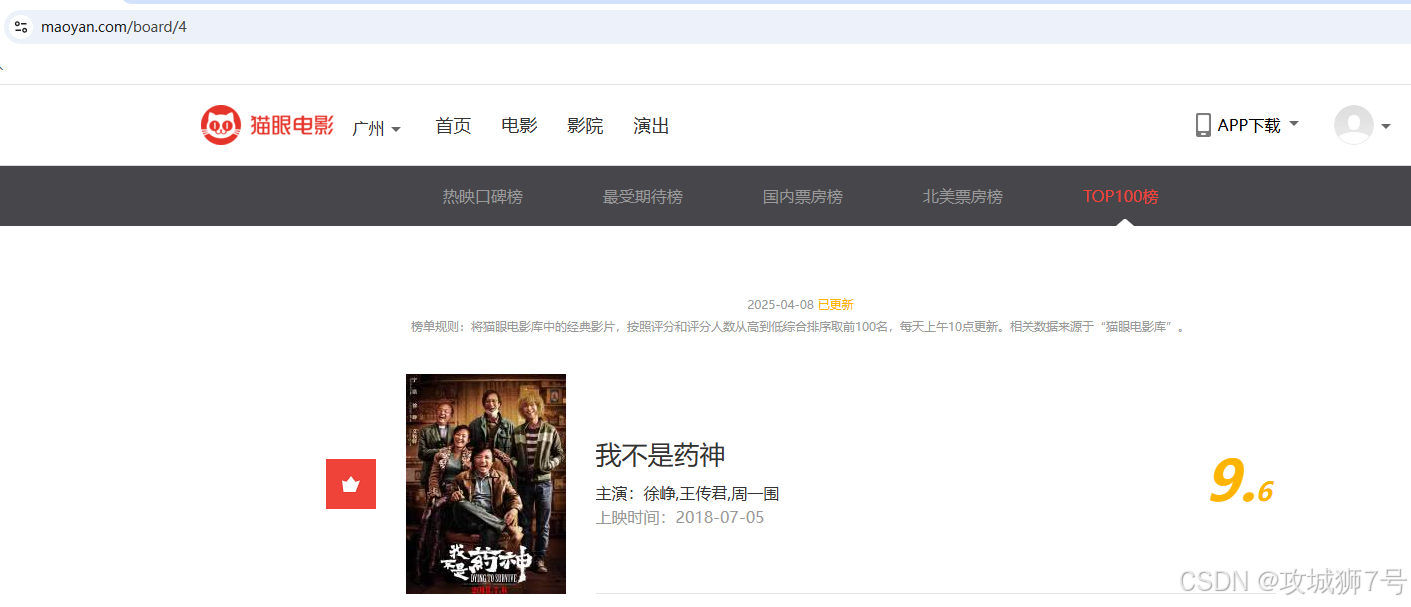
你看,排在第一名的电影是《我不是药神》,在这个页面上,能看到电影的名字、主演、上映时间、上映地区、评分,还有图片这些有用的信息。
当你把网页拉到最底部,会看到分页列表。你点一下第2页,看看页面的网址和内容有啥变化,就像下图那样。
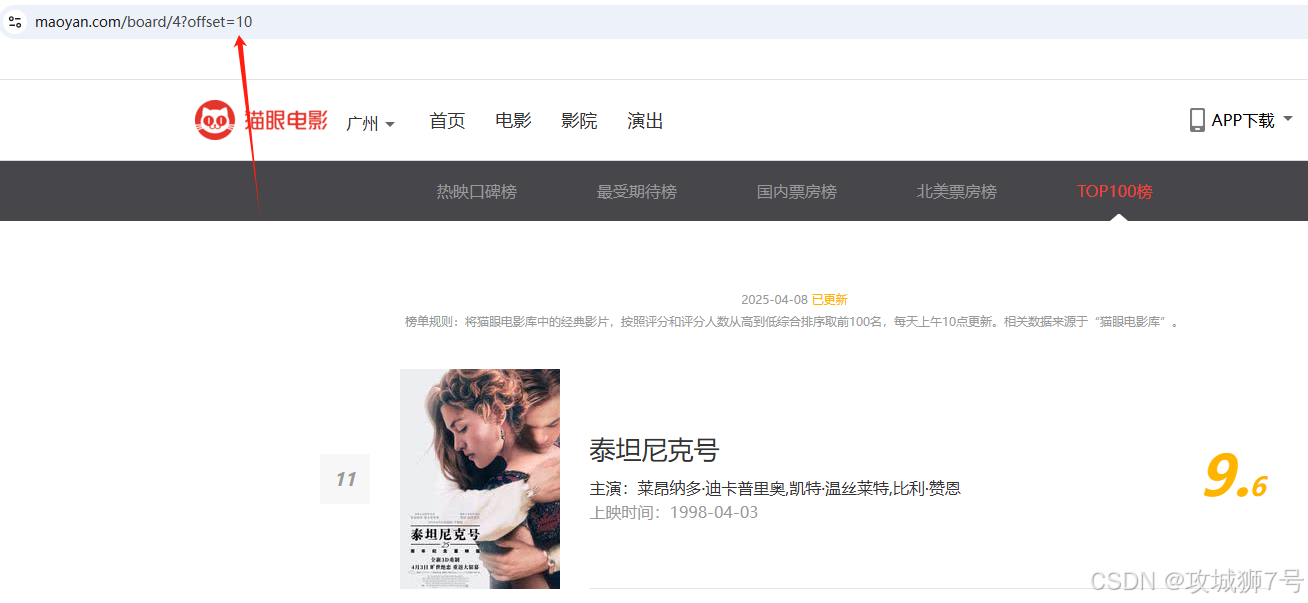
这时候你会发现,网址变成了http://maoyan.com/board/4?ofset=10 ,比原来多了个参数,就是offset=10 ,而且现在显示的电影是排名11到20的。我们初步判断,这个offset应该是个控制偏移量的参数。你再点下一页,网址又变了,成了http://maoyan.com/board/4?ofset=20 ,offset参数变成了20,页面上显示的就是排名21到30的电影。
这么一来,我们就能总结出规律了:offset就是偏移量值。要是偏移量是n,那这一页显示的电影序号就是从n + 1到n + 10,也就是说,每页会显示10部电影。所以啊,要是我们想获取TOP100的所有电影信息,只要分10次去请求网站就行,每次请求的时候,把offset参数分别设成0、10、20,一直到90。等拿到不同页面的内容后,再用正则表达式把我们需要的信息提取出来,这样就能得到TOP100所有电影的信息啦。
四、抓取首页
接下来,我们用代码来实现这个抓取过程。首先,我们要抓取第一页的内容。为此,我们写了一个叫getonepage()的方法,给这个方法传入一个url参数,它就能返回抓取到的页面内容。之后,我们通过main()方法来调用getonepage()方法。下面是初步的代码:
import requestsdef get_one_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac 0s X1013 3)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/65.0.3325.162 Safari/537.36'}response = requests.get(url, headers = headers)if response.status_code == 200:return response.textreturn Nonedef main():url = 'http://maoyan.com/board/4'html = get_one_page(url)print(html)main()按照上面的代码运行后,就能顺利得到首页的源代码。拿到源代码之后,接下来就得对页面进行解析,把我们需要的那些信息给提取出来 。
五、正则提取
接下来,我们要回到网页,去查看页面的真实源代码。查看的方式是在开发者模式下,从Network监听或Sources组件里找源代码,就像下图展示的那样。
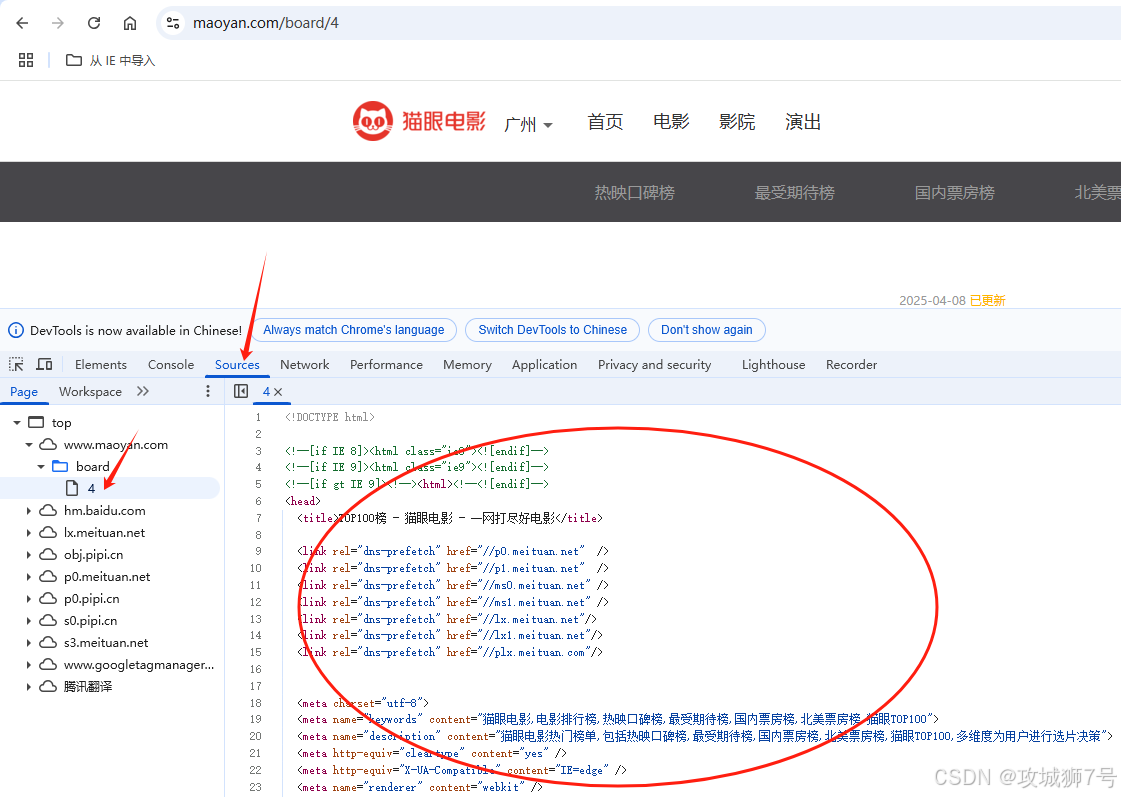
这里要注意,千万别在Elements选项卡直接看源码,因为那里的源码可能经过JavaScript处理,和我们原始请求得到的不一样了。我们得从Network选项卡查看原始请求返回的源码。
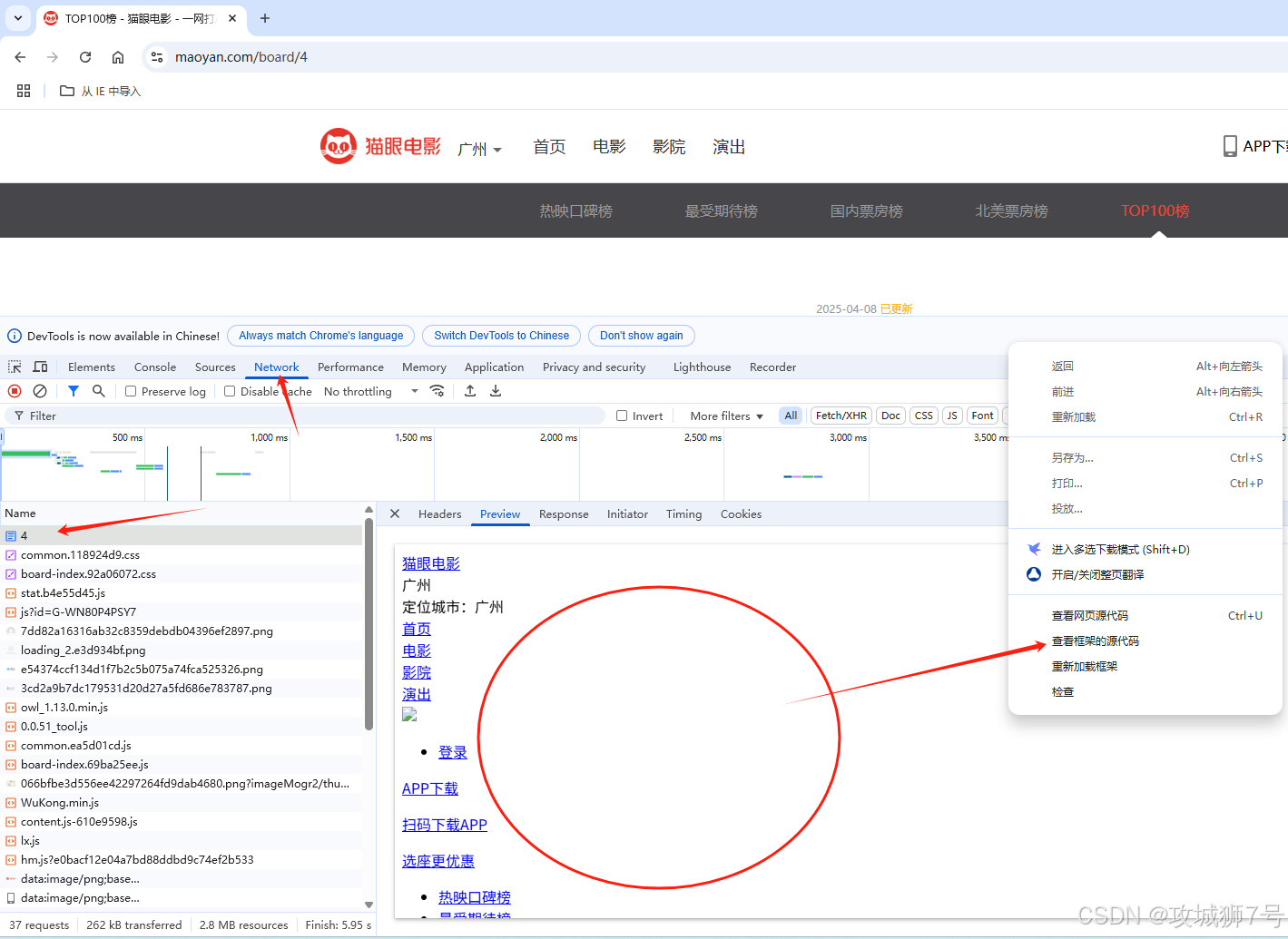
然后看其中一个条目的源代码,如下图所示。我们能看到,一部电影的信息在源代码里对应的是一个dd节点。我们打算用正则表达式从这里面提取一些电影信息。
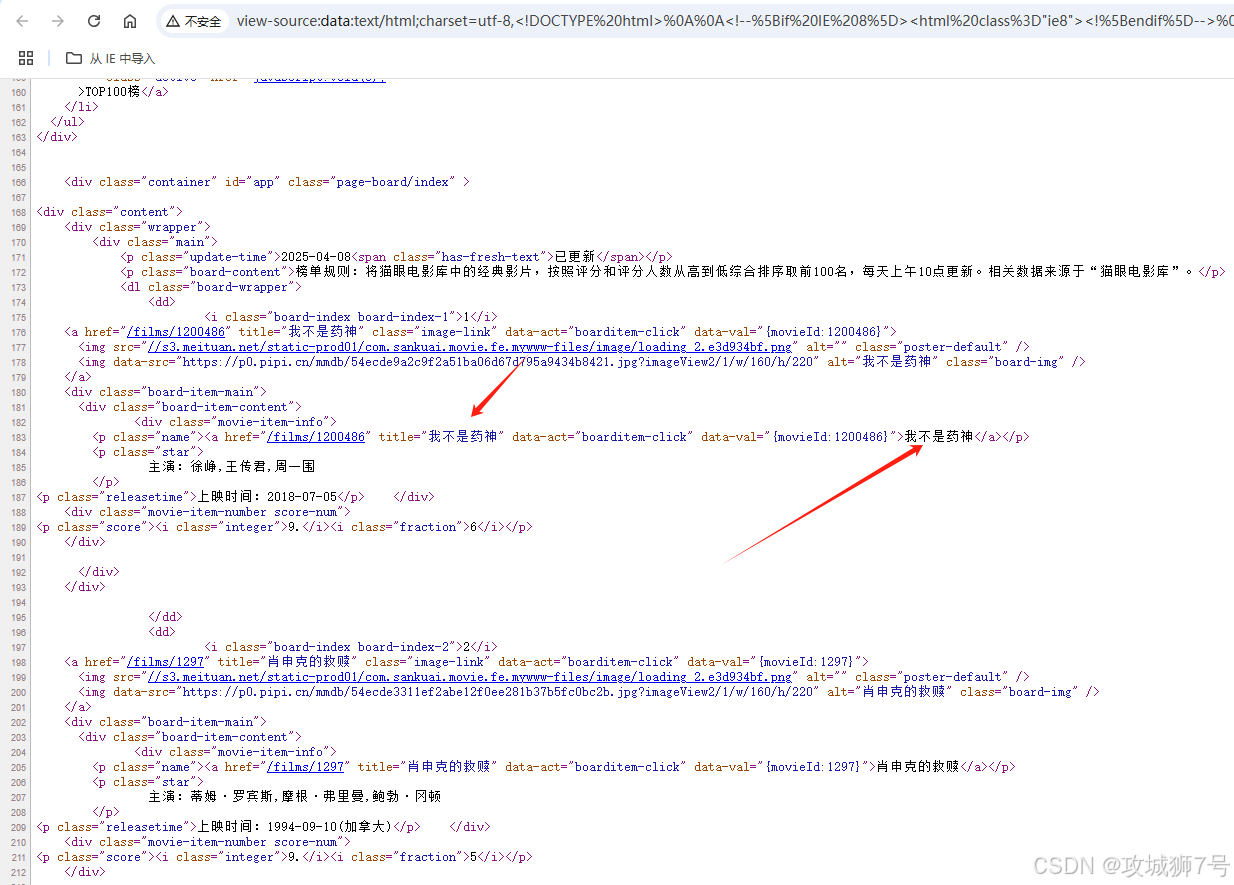
首先是提取电影的排名信息,它在class是board - index的i节点里面。我们用非贪婪匹配的方式,把i节点里的信息提取出来,对应的正则表达式写成这样:
<dd>.*?board-index.*?>(.*?)</i>接着要提取电影图片。在代码里可以看到,后面有个a节点,a节点里面又有两个img节点。仔细检查后发现,第二个img节点的data - src属性存的就是图片的链接。所以,我们把提取第二个img节点data - src属性的正则表达式写成这样:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"再往后,我们要提取电影名称。电影名称在后面的p节点里,这个p节点的class是name。我们就用name作为标志,进一步去提取它里面a节点的正文内容,这时候正则表达式就变成了:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>提取主演、发布时间、评分等其他内容,原理和前面这些是一样的。最后,完整的正则表达式写成这样:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>这样一个正则表达式,就能匹配出一部电影的相关结果,里面一共匹配了7个信息。下一步,我们通过调用findall()方法,把所有符合这个正则表达式的内容都提取出来。
之后,我们定义一个用来解析页面的方法,叫parseonepage()。这个方法主要就是通过刚才写的正则表达式,从页面内容里提取出我们想要的东西。具体的实现代码如下:
def parse_one_page(html):pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>', re.S)items = re.findall(pattern, html)print(items)运行这段代码后,就能成功把一页里的10个电影信息都提取出来,结果是一个列表形式,输出大概像这样:

不过这样提取出来的数据有点杂乱,不太好用。所以我们还要再处理一下这些匹配结果。具体做法是遍历提取到的结果,把它们生成一个个字典。这时候,我们把parseonepage()方法改写如下:
def parse_one_page(html):pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>', re.S)items = re.findall(pattern, html)for item in items:yield {'index': item[0],'image': item[1],'title': item[2].strip(),'actor': item[3].strip()[3:] if len(item[3]) > 3 else '','time': item[4].strip()[5:] if len(item[4]) > 5 else '','score': item[5].strip() + item[6].strip()}经过这样修改后,我们就能成功提取出电影的排名、图片、标题、演员、上映时间、评分等内容,并且把这些内容赋值给一个个字典,让数据变得结构化。运行这个修改后的方法,结果大概是这样:
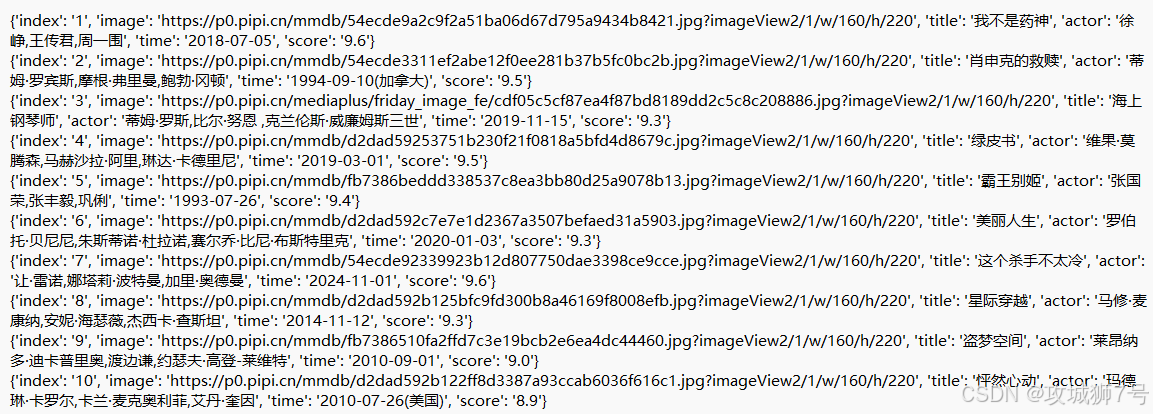
到这一步,我们就成功地提取出了单页的电影信息。因为之前的代码运行多次,可以被反爬限制,所以添加了更完整的请求头,模拟真实浏览器,也添加了基本的 cookie,如下代码:
import requests
import redef get_one_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','Connection': 'keep-alive','Upgrade-Insecure-Requests': '1','Cache-Control': 'max-age=0','Cookie': '__mta=2147483647.1597139561718.1597139561718.1597139561718.1' # 添加一个基本的cookie}try:response = requests.get(url, headers=headers, timeout=10)if response.status_code == 200:return response.textprint(f"请求失败,状态码:{response.status_code}")return Noneexcept Exception as e:print(f"请求发生错误:{str(e)}")return Nonedef parse_one_page(html):pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)items = re.findall(pattern, html)for item in items:yield {'index': item[0],'image': item[1],'title': item[2],'actor': item[3].strip()[3:],'time': item[4].strip()[5:],'score': item[5] + item[6]}def main():url = 'http://maoyan.com/board/4'html = get_one_page(url)# print(html)for item in parse_one_page(html):print(item)main()六、写入文件
接下来,我们要把提取到的那些电影信息结果存到文件里,这次我们直接存到一个文本文件中。在存的时候,我们会用JSON库的dumps()方法,把字典形式的数据变成可以存储的格式。这里要特别设置一下ensure_ascii这个参数,把它设成False ,这样存储的结果就会是我们能看懂的中文,而不是那种Unicode编码形式。下面就是具体的代码:
def write_to_file(content):with open('result.txt', 'a', encoding='utf-8') as f:print(type(json.dumps(content)))f.write(json.dumps(content, ensure_ascii = False) + '\n')调用write_to_file()方法,就能把字典写到文本文件里。这里的content参数,就是一部电影提取出来的信息,它是个字典。
七、整合代码
最后,我们实现一个main()方法,用它来调用前面写好的那些方法,把单页电影的提取结果写入文件。相关代码如下:
def main():url = 'http://maoyan.com/board/4'html = get_one_page(url)for item in parse_one_page(html):write_to_file(item)到这里,我们就完成了单页电影信息的提取工作,也就是把首页的10部电影信息成功提取出来,并且保存到文本文件里了。
八、分页爬取
咱们要抓取的可是TOP100电影,现在只弄了首页10部,所以还得接着干。得做个遍历操作,往链接里传入offset参数,用这个办法把剩下那90部电影也抓取下来。添加下面这样的调用:
if __name__ == '__main__':for i in range(10):main(offset = i * 10)这里我们还得对main()方法做些修改,让它能接收一个offset值当作偏移量。之后,根据这个偏移量来构造URL,接着用构造好的URL去进行数据爬取。实现代码如下:
def main(offset):url = 'http://maoyan.com/board/4?offset=' + str(offset)html = get_one_page(url)for item in parse_one_page(html):print(item)write_to_file(item)现在猫眼有了反爬虫手段,要是我们爬虫运行得太快,猫眼那边就不给回应了。所以,我们在代码里额外加了个延时等待的设置 。 到这儿,咱们这个用来抓取猫眼电影TOP100信息的爬虫就全部弄好了。稍微归拢归拢,完整的代码在下面:
import json
import requests
import re
import time
def get_one_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','Connection': 'keep-alive','Upgrade-Insecure-Requests': '1','Cache-Control': 'max-age=0','Cookie': '__mta=2147483647.1597139561718.1597139561718.1597139561718.1' # 添加一个基本的cookie}try:response = requests.get(url, headers=headers, timeout=10)if response.status_code == 200:return response.textprint(f"请求失败,状态码:{response.status_code}")return Noneexcept Exception as e:print(f"请求发生错误:{str(e)}")return Nonedef parse_one_page(html):pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)items = re.findall(pattern, html)for item in items:yield {'index': item[0],'image': item[1],'title': item[2],'actor': item[3].strip()[3:],'time': item[4].strip()[5:],'score': item[5] + item[6]}def write_to_file(content):with open('result.txt', 'a', encoding='utf-8') as f:f.write(json.dumps(content, ensure_ascii=False) + '\n')def main(offset):url = 'http://maoyan.com/board/4?offset=' + str(offset)html = get_one_page(url)for item in parse_one_page(html):print(item)write_to_file(item)if __name__ == '__main__':for i in range(10):main(offset=i * 10)time.sleep(1)
九、运行结果
最后,我们运行一下写好的代码,得到的输出结果和保存的那个文本文件对比,结果就跟下图展示的一样。但是我们发现只爬取了20条数据,就被发爬虫限制了。

后面我们应该如何绕过限制呢?一般有如下方法,至于怎么实践我们后续再研究讲解。
针对反爬虫,我们一般有以下几种解决方法:
1. 请求头伪装:
- 使用真实的 User-Agent
- 添加 Referer、Accept-Language 等头部
- 随机切换不同的 User-Agent
2. IP 代理池:
- 使用代理服务器轮换 IP
- 可以使用付费代理服务或自建代理池
3. 请求频率控制:
- 添加随机延时
- 控制并发数量
4. Cookie 处理:
- 维护 Cookie 池
- 定期更新 Cookie
5. 如果有验证码:
- 使用 OCR 识别简单验证码
- 使用打码平台处理复杂验证码
- 人工处理验证码并保存 Cookie
6. 使用浏览器自动化工具:
- Selenium
- Playwright
- Puppeteer
7. 分布式爬虫:
- 使用多台机器分散请求
- 使用消息队列协调任务
8. 模拟登录:
- 分析登录流程
- 模拟表单提交
- 保存登录状态
9. 使用 API:
- 寻找官方 API
- 分析移动端 API
- 使用第三方 API 服务
10. 其他技巧:
- 使用无头浏览器
- 模拟鼠标移动
- 处理 JavaScript 渲染
- 使用 WebSocket
- 分析 AJAX 请求
建议:
1. 根据目标网站的反爬策略选择合适的方案
2. 多种方法组合使用效果更好
3. 遵守网站的 robots.txt 规则
4. 控制爬取频率,避免对目标网站造成压力
5. 做好异常处理和重试机制
十、总结
这一节,我们通过抓取猫眼TOP100电影的信息,实际操作练习了requests库和正则表达式的使用方法。这只是一个非常基础的例子,我们借助这个例子,对怎么实现爬虫有个初步的概念,同时对这两个库的使用有更透彻的理解。 但是怎么对抗反爬虫,我们后续继续跟进。