
(名著中的名著《代码大全》)
为什么我们总是听到“模块化”很重要这样的话?
然而,那些没有真正理解模块化核心的人常常会这样说:
“把代码分开就好。”
但奇怪的是,即使把代码分得更细,却常常变得更复杂了。
举个例子,虽然明确地按照领域划分了服务类,但一个数据流经过多个类时,反而变得更加碎片化,难以追踪。
这篇文章就是关于为什么会发生这种情况的讨论。

(1974年Yourdon & Constantine的结构化设计论文)
结构化设计(Structured Design)是一套通过降低复杂性,使编码、调试和修改工作更简单、更快、更经济的一般程序设计原则和方法的集合。
这些主要思想是康斯坦丁先生(Mr. Constantine)近十年研究的成果。
本文介绍了这些结果,但并未涉及理论及其推导过程。
这些思想也被迈尔斯先生(Mr. Myers)称为复合设计(Composite Design)。
作者们认为,这种程序设计技术与HIPO6的文档技术及结构化编程的编码技术兼容且相辅相成。
这些成本节约型设计技术必须始终与系统的其他约束条件保持平衡。
然而,随着程序员的时间成本不断上升,编写简单且易于修改的程序的能力将变得越来越重要。
——1974年Yourdon & Constantine的结构化设计论文
什么是耦合度和内聚度?它们是如何开始的?
在20世纪60年代到70年代初,关于模块化(Modularity)的讨论已经存在。
从历史上看,迪杰斯特拉(Dijkstra)主张结构化编程,并强调了模块化设计的重要性,他的论文中也对此有所阐述。
此外,1968年大卫·帕纳斯(David Parnas)发表了一篇具有里程碑意义的论文《On the Criteria To Be Used in Decomposing Systems into Modules》(1972),提出了信息隐藏和模块边界设计的概念。
也就是说,随着程序员进入构建大型系统的初期阶段,模块化显然将成为这一工具。

1971年,尼古拉斯·沃思(Niklaus Wirth)将模块化解释为逐步细化(Stepwise Refinement)的过程。
那么,什么是逐步细化(Stepwise Refinement)?
这是一个通过自顶向下设计(Top-Down Design)来解决复杂问题的过程。
-
从抽象层次开始 :首先在非常高的层次上定义需要解决的问题,即描绘出问题的全局图景。
-
开始逐步具体化 。
-
随后添加问题的细节 。
-
反复实现 。
沃思表示,这一过程自然会引向模块化。
在每个细化阶段得出的子问题最终会成为独立的功能单元——“模块”。
-
模块将解决特定的子问题。
-
模块之间的接口由每个阶段定义的数据和控制流决定。
因此,从高层次的抽象到具体实现的过程本身,就是一种将系统构建成具有明确职责和接口的独立模块的方法。
那么,既然我们已经理解了模块边界设计和模块化设计的重要性,
接下来我们自然会面临一个问题:
如何评估模块化的质量?
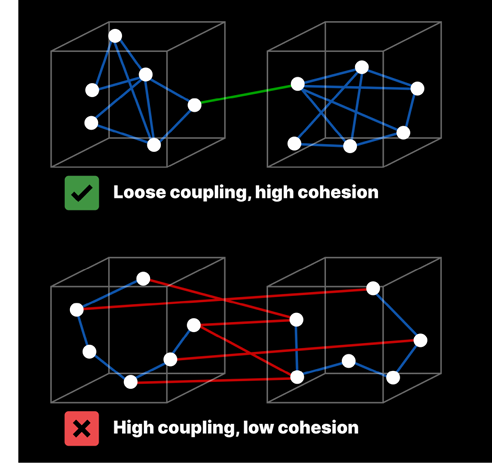
而在1974年,Yourdon & Constantine的结构化设计论文中,制定了对其进行定量评估的标准。
这些标准就是:
内聚度(Cohesion)
耦合度(Coupling)
基于这些标准,“模块化”不再仅仅是简单的代码分割,而是成为管理系统复杂性的一种核心工具。
以此为基础,艾伦·凯(Alan Kay)提出了面向对象编程(OOP),并在IEEE标准和SEI-CMMI中进一步具体化。
最终,在经典著作《代码大全》(Code Complete)中,这些概念得到了阐释,并被普及给普通程序员。
那么,什么是内聚度和耦合度?

与耦合度一起,内聚性(Cohesion)作为结构化设计的一部分,通常在同一背景下被讨论。
内聚性表示类中的所有例程或例程中的所有代码在多大程度上支持其核心目标,即类的集中程度。
包含高度相关功能的类被称为具有强内聚性,经验上的目标是尽可能提高内聚性。
内聚性是管理复杂性的有用工具,因为类中的代码越能支持其核心目标,大脑就越容易记住该代码的所有操作。在例程级别上对内聚性的思考方法在数十年间一直是一种有效的经验法则,并且至今仍然适用。在类级别上,内聚性的经验法则已被更广泛的、定义良好的抽象化方法所涵盖,这些内容在本章前面和第6章中有所讨论。
抽象化在例程级别上也很有用,但在更细节的层面上,它与内聚性处于同等重要的位置。
——《代码大全》第二版,"追求强内聚性"部分
总结一下:
- 内聚性应高。
- 耦合度应低。
内聚度(Cohesion):
- 模块内部元素之间的功能性关联的分层分类。
耦合度(Coupling):
- 模块之间的依赖强度。
接下来,我们将基于《代码大全》和 Yourdon & Constantine 的论文来了解如何评估内聚度和耦合度的指标。


传统内聚度分类(Yourdon & Constantine,1974)
| 内聚度类型 | 说明 |
|---|---|
| 偶然内聚 (Coincidental Cohesion) | 模块内的任务彼此完全无关,只是物理上被捆绑在一起。这是最差的内聚形式。 示例:在Utils.cs中包含了日志记录、日期解析和数据库连接等功能。 |
| 逻辑内聚 (Logical Cohesion) | 任务之间有关联,但通过选择性执行操作完成,通常由分支(switch/case)决定行为。 示例:像HandleCommand(CommandType type)这样的方法。 |
| 时间内聚 (Temporal Cohesion) | 将在相同时间执行的任务组合在一起。 示例:InitAll()、ShutdownAll() 等程序启动或关闭时的操作集合。 |
| 过程内聚 (Procedural Cohesion) | 模块内的任务以特定顺序执行,但彼此之间没有直接关联。 示例:打开文件、记录日志、关闭UI等按顺序执行的情况。 |
| 通信内聚 (Communicational Cohesion) | 模块内的所有任务使用相同的数据结构。 虽然相关性明确,但处理任务可能多样化。<br>示例:一个模块包含对同一张表的查询、修改和删除功能。 |
| 顺序内聚 (Sequential Cohesion) | 一个任务的输出成为下一个任务的输入。 示例:读取数据 → 处理数据 → 存储数据的流水线操作。 |
| 功能内聚 (Functional Cohesion) | 模块仅执行一个明确的功能,内部元素都为该功能服务。这是最理想的内聚形式。 示例:CalculateTax()、GenerateReport() 等函数。 |
在《代码大全》中,内聚度是针对模块或例程讨论的,其中“例程”指的是:
- 执行特定任务的独立代码块 。
内聚度 ——表示类或例程中的元素彼此之间的协调程度。
在评估模块和例程时:
- 偶然内聚受到最多批评。
- 越接近功能性内聚,越被认为是理想状态。
功能性内聚被认为是最理想的,并且:
- 一般允许部分逻辑内聚。
- 对于通信内聚,虽然可以接受,但仍需警惕目标分散的问题。
- 时间内聚及以下则被认为是重构的目标,同时受到批判。
《代码大全》将功能性内聚作为理想标准,指出:
- 当一个例程只执行“一项”任务时,调试会变得更容易。
- 如果例程名称中包含“and”或“or”,或者有过多的参数或复杂的控制流,则可能是内聚度下降的迹象。
根据《代码大全》,良好的内聚度会带来以下好处:
- 代码专注于单一任务 。
- 例程名称足以解释其功能 。
- 修改局限于局部范围 。
- 例程内的代码行具有高度的上下文连贯性 。
接下来,我们将探讨耦合度。

(《结构化设计》1979年书)

传统耦合度分类
| 耦合度类型 | 说明 |
|---|---|
| 内容耦合 (Content Coupling) | 一个模块直接访问另一个模块的内部实现细节。具有非常强的依赖性,修改时会直接影响外部模块。 示例:函数A直接操作函数B的局部变量或私有函数。 |
| 公共耦合 (Common Coupling) | 多个模块共享全局数据。难以追踪谁在何时修改了全局状态,副作用会导致调试困难。 示例:多个模块同时引用和修改全局变量globalConfig。 |
| 外部耦合 (External Coupling) | 模块依赖于外部系统、格式、设备或通信协议。外部系统的变更可能影响内部操作。 示例:与文件格式、数据库模式或硬件协议紧密绑定的代码。 |
| 控制耦合 (Control Coupling) | 一个模块通过传递控制标志(条件)间接指示另一个模块的内部逻辑流程。这可能是语义耦合的前兆。 示例:Process(flag)中调用者指定内部条件分支。 |
| 标记耦合 (Stamp Coupling) | 传递整个数据结构(如结构体、类),但只使用部分字段。传递了不必要的信息,增加了耦合度和误解的可能性。 示例:在Process(User user)中仅使用user.name。 |
| 数据耦合 (Data Coupling) | 只传递必要的数据作为参数。这是最理想的耦合形式,模块间的依赖最小化且接口清晰。 示例:CalculateTax(income, regionCode)只传递必要的值。 |
| 无耦合 (No Coupling) | 完全独立的模块,彼此之间不共享任何信息。通常在系统设计中不存在,但在测试模块等情况下是可能的。 示例:独立运行的工具函数。 |
基于《代码大全》的耦合度分类总结
| 耦合度类型 | 说明 |
|---|---|
| 简单数据耦合 (Simple-data-parameter Coupling) | 模块间传递的数据都是基本类型(primitive),且通过参数(parameter)传递。通常是最理想的耦合形式。 |
| 简单对象耦合 (Simple-object Coupling) | 一个模块简单地实例化或直接使用另一个对象。由于不依赖内部操作,因此被认为是安全的耦合。 |
| 对象参数耦合 (Object-parameter Coupling) | 一个对象通过另一个对象接收第三方对象的传递。中间对象需要了解传递对象的存在和意义,因此耦合更加紧密。 |
| 语义耦合 (Semantic Coupling) | 一个模块隐含地理解另一个模块的操作方式或内部逻辑。如果没有对内部操作的先验知识,就无法正确使用,这是最危险的耦合形式。 |
(《代码大全》中的耦合度)
耦合度 ——表示模块之间的依赖强度。
然而,耦合度并未出现在1974年的《结构化设计》论文或1979年的《结构化设计》书中。
为什么?因为耦合度并非来自论文,而是在后续研究中完善了分类体系。
此外,《代码大全》对耦合度的讨论有所不同。
为什么?
因为《代码大全》撰写的时代正值面向对象编程(OOP)成为主流,因此:
- 基于上下文(Context)的耦合被认为更现实。
- 引入了新的耦合形式,例如对象协作和接口滥用。
由于这些差异,耦合度的分类方法被调整为更贴近实战。
如果说传统耦合度是设计的理论尺度,那么McConnell的耦合度分类更能反映实际OOP开发中代码之间的错误交互。
内聚度与耦合度相互作用,成为理解我们代码质量的工具。
例如,具有逻辑内聚的模块更容易引发控制耦合(Control Coupling)。它们彼此互补,提供了更全面的设计视角。

“程序员如同诗人一般,在纯粹思想的材料旁工作。
程序员凭借想象力的力量,在虚空中建造城堡。”——弗雷德里克·P·布鲁克斯(Frederick P. Brooks Jr.),《人月神话:软件工程随笔》
结尾总结
软件设计的历史可以说是模块化原则的演变史。
1974年,Yourdon & Constantine 提出的内聚度和耦合度不仅是简单的理论,更是开启大型系统时代的工程师们用汗水换来的洞察。
分解代码并不是单纯的拆分(decomposition),而是创造新的抽象层次的行为。
正如《代码大全》所强调的,模块化的成败可以归结为两个现实问题:
-> “一个函数是否可以用一句话描述?”(功能性内聚力)
-> “修改时需要改动多少文件?”(低耦合度)
这些概念深深影响了许多领域,甚至渗透到微服务架构和容器技术(如Docker)中,无处不在。
70年代先驱者留下的遗产从未改变。
模块化仍然是软件设计中最强大的工具,
我们继承了前辈程序员的智慧,从而能够处理当时看来庞大的架构。
作为一名程序员,我想在前辈程序员的一句话后加上一句短语:
我们在虚空中构建代码。但那虚空,必须是他人能够理解的。
![]()